KafkaAPI实现生产者与消费者自定义Partition,奇数、偶数数据分在不同的Partition.
思路
创建三个类,包括Consumer、Producer、Partition在Producer端产生消息,Consumer端接收消息,Partition实现分区规则。Producer根据随机函数随机产生十个数据,其中包括奇数和偶数。因为是将奇数和偶数划分到不同的partition当中去,所以在实现的分区的时候使用的是取模的方法。
- 设置producer的配置信息
public Producer(String topic) {
Properties props = new Properties();
props.put("bootstrap.servers", "172.17.11.182:9092,172.17.11.183:9092");
props.put("client.id", "DemoProducer");
props.put("batch.size", 16384);//16M
props.put("linger.ms", 1000);
props.put("buffer.memory", 33554432);//32M
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("partitioner.class", "com.horizon.kafka.v010.SimplePartitioner");
producer = new KafkaProducer<>(props);
this.topic = topic;
}
- 发送消息队列,使用循环的方法,后面的number和runtime是键值对的形式
public void producerMsg() throws InterruptedException{
Random rnd = new Random();
int events = 10;
for (long nEvents = 0; nEvents < events; nEvents++) {
long runtime = new Date().getTime();
String number = String.valueOf(rnd.nextInt(255));
try {
producer.send(new ProducerRecord<>(topic, number, String.valueOf(runtime)));
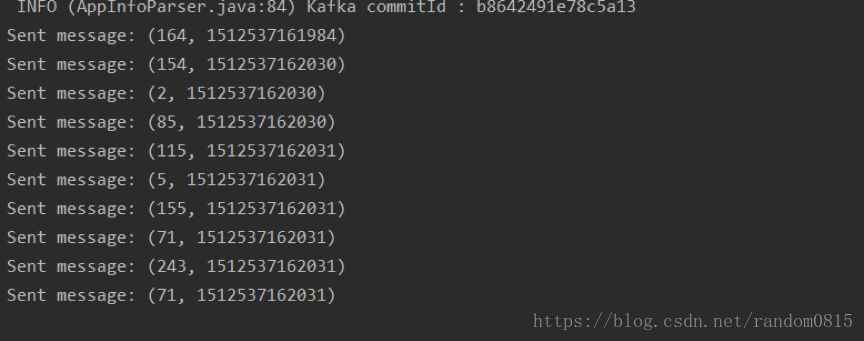
System.out.println("Sent message: (" + number + ", " +runtime+ ")");
} catch (Exception e) {
e.printStackTrace();
}
}
Thread.sleep(10000);
}- Consumer读取信息,同样使用循环将key和value以及分区全部打印出来
public void consumerMsg(){
try {
consumer.subscribe(Collections.singletonList(this.topic));
while(true){
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
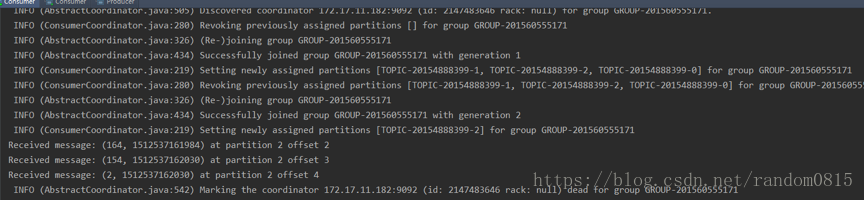
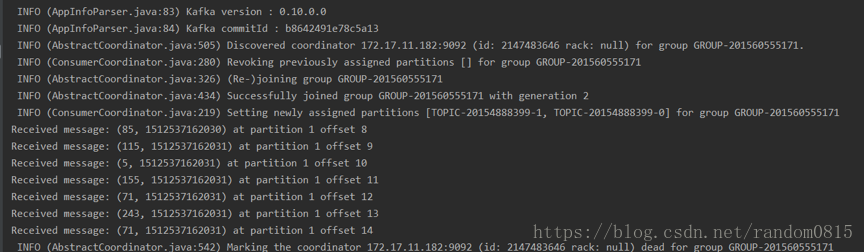
System.out.println("Received message: (" + record.key() + ", " + record.value() + ") at partition "+record.partition()+" offset " + record.offset());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}- 分区规则的创建
public class SimplePartitioner implements Partitioner {
public SimplePartitioner() {
}
@Override
public void configure(Map<String, ?> configs) {
}
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String k = (String) key;
if(Integer.parseInt(k) % 2 == 0)
return 0;
else
return 1;
// return Integer.parseInt(k)%2;
}
@Override
public void close() {
}
}在创建分区的时候,如果不创建分区0,系统也会自动创建出0,在下面的程序中创建的分区是1和2,但是也会自动创建0分区,即一共会有三个分区。
- 结果
producer端产生的消息
两个consumer分别接收到的消息
偶数
奇数
遇到的问题
1) 在使用单机模式,即Kafka的服务器只有一个的时候,在Producer端产生消息的速率特别慢,然后在consumer端接收不到消息,放到前端去跑,会发现报错。
kafka.admin.AdminOperationException: replication factor: 1 larger than available brokers: 0
解决办法: 复制kafka/config路径下的server.properties文件为:server-1.properties和server-2.properties
并修改这两个文件的配置项:
server-1.properties
broker.id=1
port=9093
log.dir=/tmp/kafka-logs-1
host.name=localhost
server-2.properties
broker.id=2
port=9094
log.dir=/tmp/kafka-logs-2
host.name=localhost
然后重新启动。就可以了
2) 在解决第一个问题之后,使用分区的时候还是出现问题,最后采用集群的模式,但是在控制台端运行的时候,先运行consumer,在运行producer发现consumer端并没有分区划分log日志如下

解决方法:在运行的时候先运行producer、在同时运行两个consumer、运行producer观察开启的consumer接收到的实时消息。具体原因是为什么也没有找到,不过感觉可能是,如果先启动consumer的话可能预先还没有创建分区也就是没有执行producer,所以找不到对应的分区信息,所以先创建分区,第二次是用来传递消息。
全部代码待我上传到github上在发出来,如果现在需要直接私信我就好