一、前期准备工作:
- 虚拟机已安装和基本配置好;
- Zookeeper已安装好;
- Kafka已安装好;
- Hadoop已安装好;
启动之后查看进程是否都起来了:
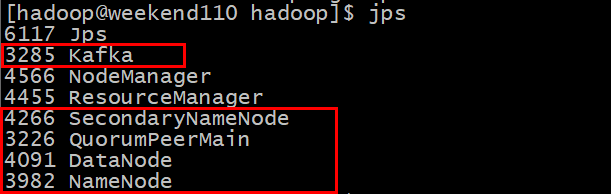
二、编写代码:
1、创建Maven工程并导入相关依赖:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.9.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.9.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.0</version>
</dependency>
2、编写生产者类CustomProducer
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author:xsluo
* @date:2020/7/9
* @aim:生产者:往topic666消息队列写入消息
*/
public class CustomProducer {
private static KafkaProducer<String, String> producer;
private final static String TOPIC = "topic666";
public CustomProducer() {
//定义配置信息
Properties props = new Properties();
// kafka地址,多个地址用逗号分隔
props.put("bootstrap.servers", "weekend110:9092,weekend01:9092,weekend02:9092");
props.put("acks", "all");
props.put("retries", 1);
props.put("batch.size", 16384); //只有在数据积累到batch.size之后,sender才会发送数据。
props.put("linger.ms", 1); //如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
props.put("buffer.memory", 33554432);
//设置序列化类,可以写类的全路径
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
producer = new KafkaProducer<String, String>(props);
}
public void produce(){
//发送消息
try {
for (int i = 0; i < 50; i++) {
String key = String.valueOf(i);
String data = "This is a kafka message: " + key;
producer.send(new ProducerRecord<String, String>(TOPIC,key,data));
System.out.println(data);
Thread.sleep(50);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
producer.close();
}
}
public static void main(String[] args) {
new CustomProducer().produce();
}
}
3、编写消费者类
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author:xsluo
* @date:2020/7/9
* @aim:消费者:读取kafka数据
*/
public class CustomConsumer {
private static KafkaConsumer<String, String> consumer;
private final static String TOPIC = "topic666";
public CustomConsumer(){
Properties props = new Properties();
props.put("bootstrap.servers", "weekend110:9092,weekend01:9092,weekend02:9092");
//每个消费者分配独立的组号
props.put("group.id", "g2");
//如果value合法,则自动提交偏移量
props.put("enable.auto.commit", "true");
//设置多久一次更新被消费消息的偏移量
props.put("auto.commit.interval.ms", "1000");
//设置会话响应的时间,超过这个时间kafka可以选择放弃消费或者消费下一条消息
props.put("session.timeout.ms", "30000");
//自动重置offset
//earliest 在偏移量无效的情况下 消费者将从起始位置读取分区的记录
//latest 在偏移量无效的情况下 消费者将从最新位置读取分区的记录
props.put("auto.offset.reset","earliest");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<String, String>(props);
}
public void consume(HDFSWriter hdfsWriter) throws Exception {
//消费消息
consumer.subscribe(Arrays.asList(TOPIC));
try {
long msgPolled = 0L, msgProcessed = 0L;
int recordsCount = 1;
while (true){
//拉取records
ConsumerRecords<String, String> records = consumer.poll(30000);
recordsCount = (records != null) ? records.count() : 0;
if (recordsCount == 0) break;
msgPolled += recordsCount;
//写入HDFS
msgProcessed += hdfsWriter.write(records);
System.out.print(String.format("**** %d messages polled, %d processed! -----", msgPolled, msgProcessed));
}
} finally {
hdfsWriter.close();
consumer.close();
}
}
public static void main(String[] args) throws Exception {
HDFSWriter hdfsWriter = new HDFSWriter();
new CustomConsumer().consume(hdfsWriter);
}
}
4、编写HDFS的辅助类HDFSWriter
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import java.io.IOException;
import java.net.URI;
/**
* @author:xsluo
* @date:2020/7/9
* @aim:把消费的消息写入HDFS
*/
public class HDFSWriter{
private FileSystem fs;
private FSDataOutputStream fdos;
public HDFSWriter(){
Configuration configuration=new Configuration();
String hdfsPath = "hdfs://weekend110:9000/test/test0709.txt";
try {
fs = FileSystem.get(URI.create(hdfsPath), configuration);
fdos = fs.create(new Path(hdfsPath));//创建一个输出流
} catch (IOException e) {
e.printStackTrace();
}
}
public int write(ConsumerRecords<String, String> records) throws Exception {
int n = records.count();
for ( ConsumerRecord<String, String> record : records ) {
String elements = record.value();
fdos.write(elements.getBytes());
fdos.write("\r\n".getBytes());
}
fdos.flush();
return n;
}
public void close() {
try {
fdos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
5、拷贝Linux上的Hadoop里面的core-site.xml和hdfs-site.xml两个文件放到工程的Resource目录下
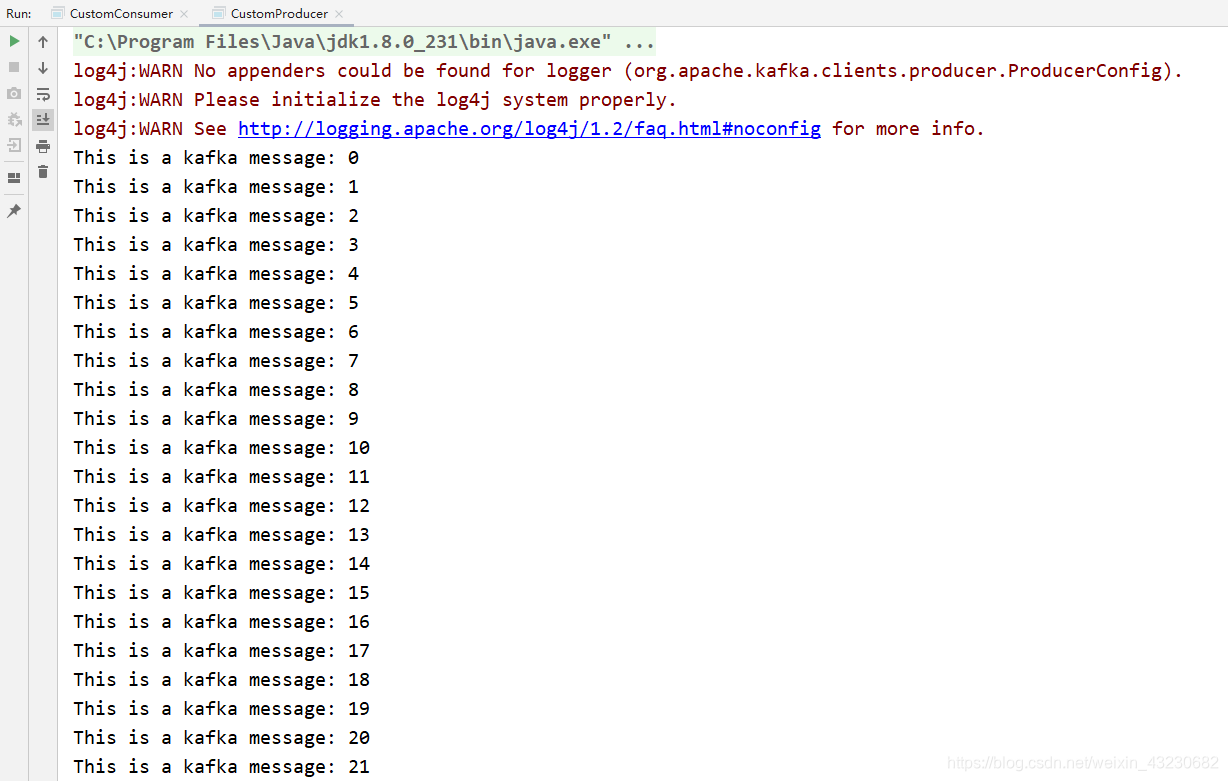
三、分别运行生产者和消费者代码:

四、查看执行的结果:
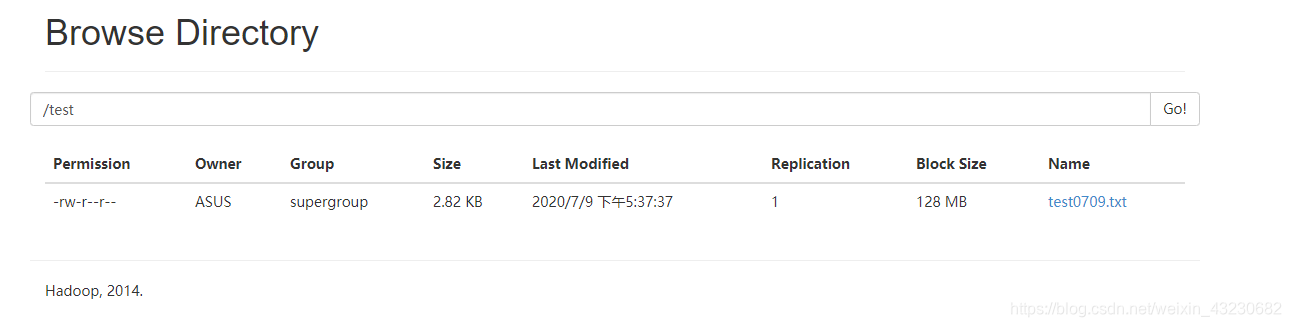
测试完毕。
五、要点总结:
- kafka如果是集群,多个地址用逗号分隔
- kafkaProducer.send(record)可以通过返回的Future来判断是否已经发送到kafka,增强消息的可靠性。同时也可以使用send的第二个参数来回调,通过回调判断是否发送成功。
- props.put(“key.serializer”, “org.apache.kafka.common.serialization.StringSerializer”);设置序列化类,可以写类的全路径
- 消费者订阅消息可以订阅多个主题
- kafka根据分组名称判断是不是同一组消费者,同一组消费者去消费一个主题的数据的时候,数据将在这一组消费者上面轮询。
- 主题涉及到分区的概念,同一组消费者的个数不能大于分区数。因为:一个分区只能被同一群组的一个消费者消费。出现分区小于消费者个数的时候,可以动态增加分区。
- 注意和生产者的对比,Properties中的key和value是反序列化,而生产者是序列化。
- 为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能,本案例采用的就是自动提交。自动提交offset的相关参数:
enable.auto.commit:是否开启自动提交offset功能 auto.commit.interval.ms:自动提交offset的时间间隔 - 另外也可以手动提交offset,方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync会失败重试,一直到提交成功(如果由于不可恢复原因导致,也会提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。