来源: AINLPer微信公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-10-10
引言
关于EMNLP2022,最近有作者开始收到论文接受的通知。因此本文为大家整理了一波EMNLP2022接收论文供大家下载阅读。其中共计26篇,整理24篇,主要涉及:多模态讽刺检测、PLMs事实知识校准、分类中的长尾问题、关联知识学习、域适应增强Prompt调优、开放领域QA阅读器性能增强、生成实体类型(GET)新范式、多向可控文本生成、多文档格式文献理解、摘要提取评价新方法、表格数据编码模型、Text-to-SQL语义理解提升、强化学习的离散prompt优化、元嵌入研究、零样本链接预测 (HNZSLP)、知识密集型语言任务的集成框架、Fast-R2D2语法归纳和文本表示、跨模态预训练等。
关注 AINLPer公众号,回复:历年EMNLP 获取论文下载列表
1、实体内存编解码框架(EDMem)
Paper:A Unified Encoder-Decoder Framework with Entity Memory
实体作为现实世界知识的重要载体,在许多NLP任务中发挥着关键作用。本文将实体知识合并到编码器-解码器框架中,以生成信息文本。而现有方法主要依据索引、检索和读取外部文档,并且需要巨大计算开销。本文提出的加入实体内存的编码器-解码器框架(EDMem)如下图所示,它将实体知识作为潜在表示存储在内存中,并且该内存连同编码器-解码器参数一起在Wikipedia上进行预训练。EDMem是一个统一的框架,可以用于各种实体密集型的问题回答和生成任务。大量的实验结果表明,EDMem优于基于内存的自动编码器模型和非内存编码器模型。

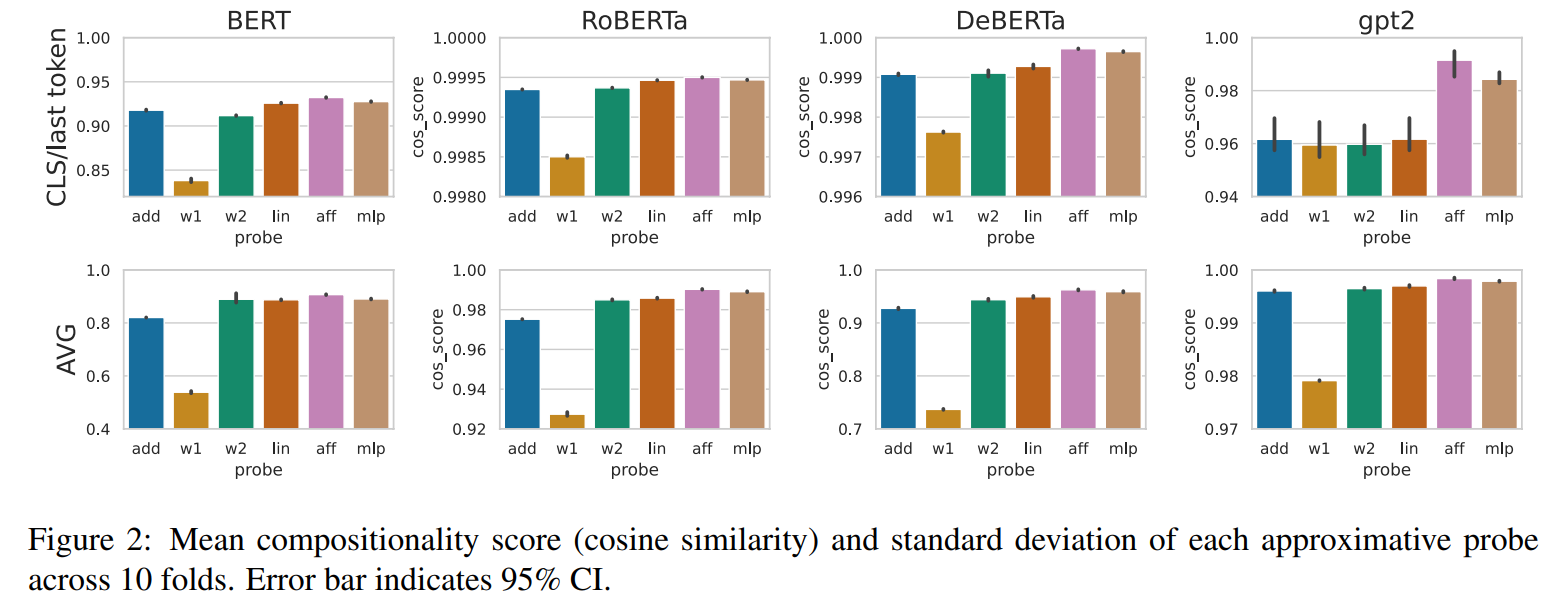
2、关于区分组合短语的讨论
Are Representations Built from the Ground Up? An Empirical Examination of Local Composition in Language Models
合成性,即一个短语的意思可以从它的组成部分推导出来,它是人类语言的一个标志。与此同时,许多短语是非构成的,它们所承载的意义超出了单个部分的意义。表示这两种类型的短语对于语言理解是至关重要的,但现代语言模型(LM)能否学会这两种类型的表示是个问题。为此本文首先提出了一个预测长短语的LM内部表示的问题。我们发现,给定子短语的仿射变换,一个父短语的表示预测具有一定的准确性。虽然我们希望预测的准确性与人类对语义组合性的判断相关联,但我们发现这在很大程度上并非如此,这表明LM可能不能准确地区分组合短语和非组合短语。我们执行了各种各样的分析,阐明了不同种类的LM何时生成和不生成组合表示,并讨论了对未来建模工作的影响。
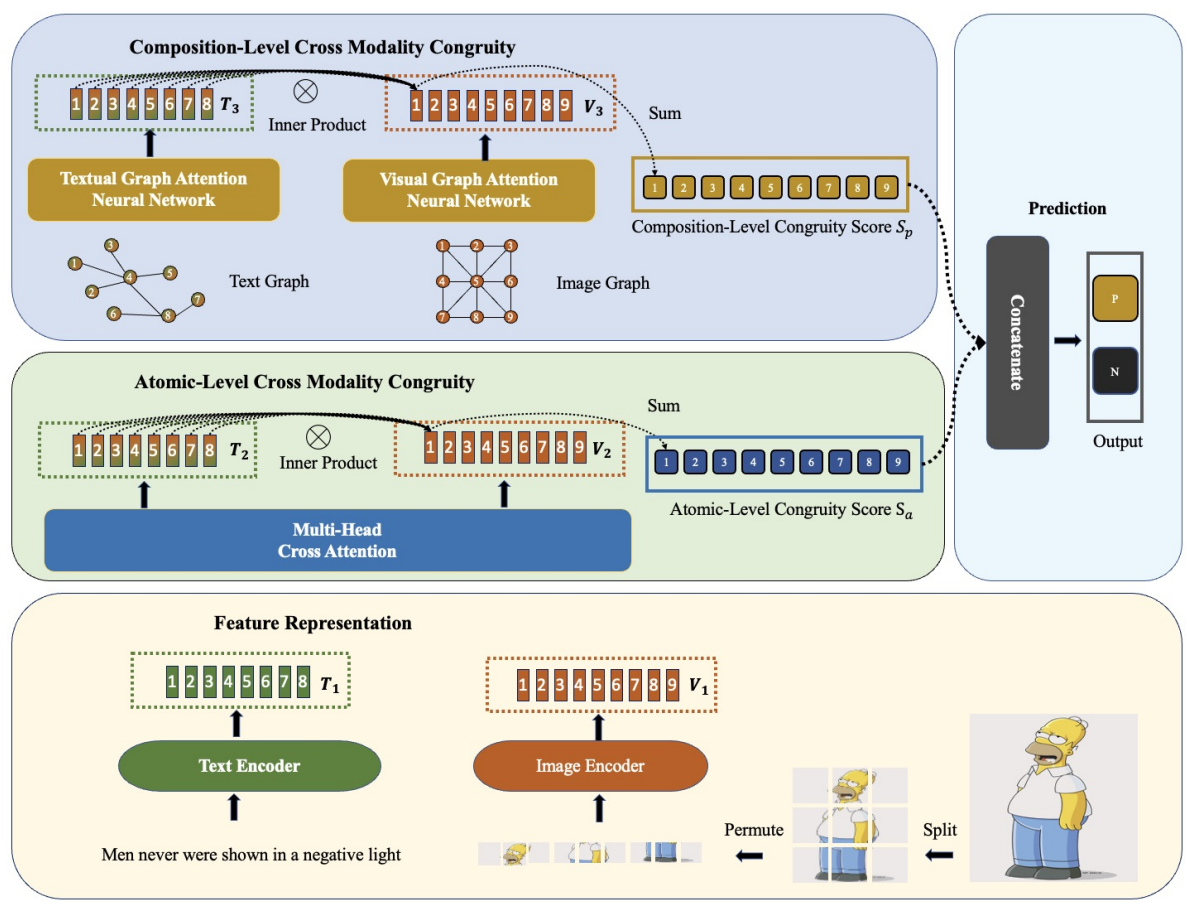
3、多模态讽刺检测
Towards Multi-Modal Sarcasm Detection via Hierarchical Congruity Modeling with Knowledge Enhancement
讽刺是一种语言现象,其字面意义和隐含意图之间是存在差异的。由于其复杂的性质,通常很难从文本本身进行检测。因此,多模态讽刺检测在学术界和业界都受到了越来越多的关注。然而,大多数现有的技术只模拟了文本输入和伴随图像之间原子级的不一致,忽略了两种形式更复杂的组成。此外,他们忽视了外部知识所包含的丰富信息。本文通过对基于多头交叉注意机制的原子级一致性和基于图神经网络的成分级一致性进行研究,提出了一种新的基于层次结构的讽刺语检测框架(如下图所示),将一致性较低的帖子识别为讽刺语。此外,我们利用各种知识资源的作用进行讽刺检测。在基于Twitter的公共多模态讽刺检测数据集上的评价结果表明了该模型的优越性。
4、PLMs事实知识校准
Calibrating Factual Knowledge in Pretrained Language Models
先前的文献证明了预训练语言模型(PLMs)可以存储事实知识。然而,我们发现存储在plm中的事实并不总是正确的。它激励我们探索一个基本问题:我们如何在plm中校准事实知识,而不从头开始重新训练?为此,本文提出了一个简单和轻量级的方法CaliNet来实现这一目标。其中,首先通过正确和错误事实的对比得分来检测plm是否能够学习正确的事实。如果没有,我们将使用轻量级方法为特定的事实文本添加和调整新的参数。通过对知识探究任务的实验,验证了该方法的有效性和有效性。此外,通过闭卷答题,我们发现校正后的PLM经过微调后具有知识泛化能力。

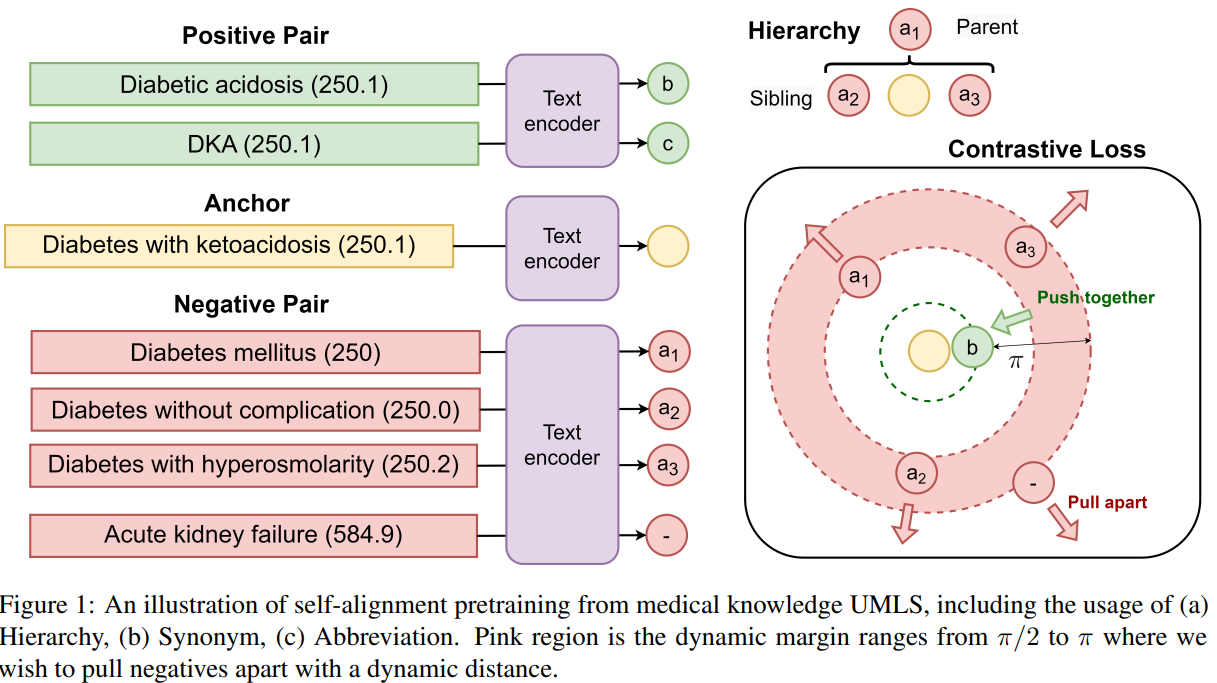
5、解决分类中的长尾问题
Knowledge Injected Prompt Based Fine-tuning for Multi-label Few-shot ICD Coding
国际疾病自动分类(ICD)编码的目标是将多个ICD编码分配给平均长度为3000多个标记的医疗记录。由于多标签分配的高维空间(数以万计的ICD编码)和长尾问题:只有少数编码(常见疾病)频繁分配,而大多数编码(罕见疾病)不频繁分配,这一任务具有挑战性。本研究采用基于提示的标签语义微调技术来解决长尾问题,该技术已被证明在小样本设置下有效。为了进一步提高在医疗领域的性能,我们提出了一个知识增强的longformer,通过注入三个领域特定的知识:层次、同义词和缩写,并使用对比学习进行额外的预训练。具体架构图如下:
6、关联知识学习(Rainier)
Rainier: Reinforced Knowledge Introspector for Commonsense Question Answering
知识是推理的基础。最近的研究表明,当相关知识作为常识性问答(QA)的附加内容提供时,即使在最先进的模型算法上,它也可以很好的提升其效果。但根本的挑战是在哪里以及如何找到高质量和与问题相关的知识,其中从知识库检索到的知识是不完整的,从语言模型生成的知识是不一致的。为此本文提出了提出了 Rainier(Reinforced Knowledge Introspector),它学习生成与给定问题相关的知识。本文的方法从模仿 GPT-3 生成的知识开始,然后通过强化学习学习生成自己的知识,其中奖励是基于所产生的问题回答的性能提高而形成的。其中模型结构图如下所示:

7、域适应增强Prompt调优
Improving the Sample Efficiency of Prompt Tuning with Domain Adaptation
提示调优,或使用从数据中学习到的软提示对预训练语言模型 (PLM) 进行调节,在大量NLP任务中显示出了比较强悍的性能。然而,快速调优需要一个大的训练数据集才能有效,并且在数据稀缺的情况下通过微调整个PLM来获得更好的性能。以前的工作提出将在源域上预训练的软提示转移到目标域。在本文中,我们探索了用于提示调优的域自适应,这是一个问题设置,其中目标域的未标记数据在训练前可用。本文提出使用域适应(OPTIMA)增强提示调优,它对决策边界进行正则化,使源数据和目标数据分布相似的区域周围的决策边界更加平滑。
8、开放领域QA阅读器性能增强
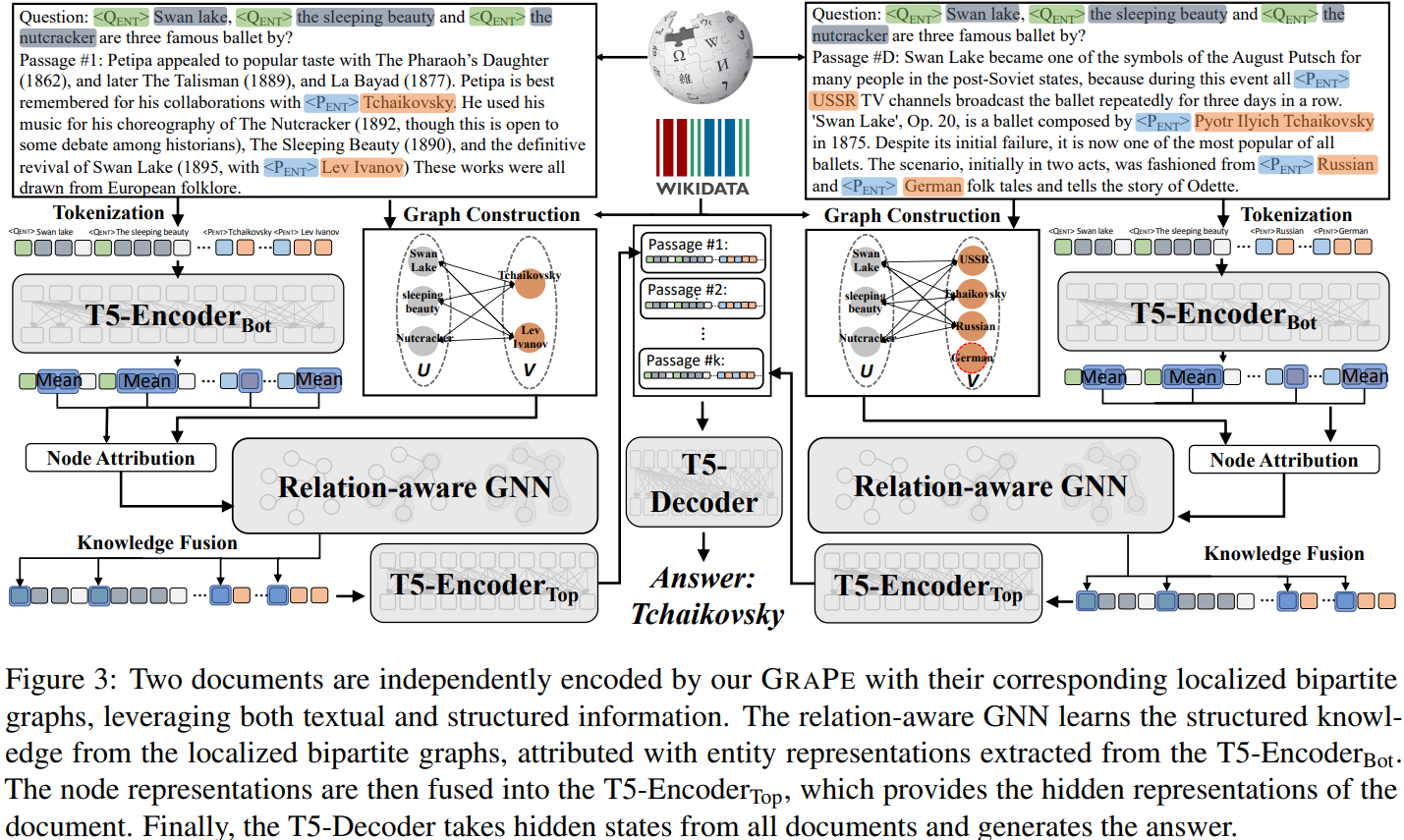
Grape: Knowledge Graph Enhanced Passage Reader for Open-domain Question Answering
开放领域问题回答(QA)模型的一个常见流程是使用检索器-阅读器管道,它首先从维基百科检索少量相关段落,然后仔细阅读这些段落以生成答案。然而,即使是最先进的阅读器也无法捕捉问题中出现的实体和检索到的文章之间的复杂关系,导致答案与事实相矛盾。为此,本文提出了一种新的知识图谱增强通道阅读器Grape,以提高面向开放领域QA的阅读器性能。其中模型结构图如下所示:
9、多模态检索增强转换器(MuRAG)
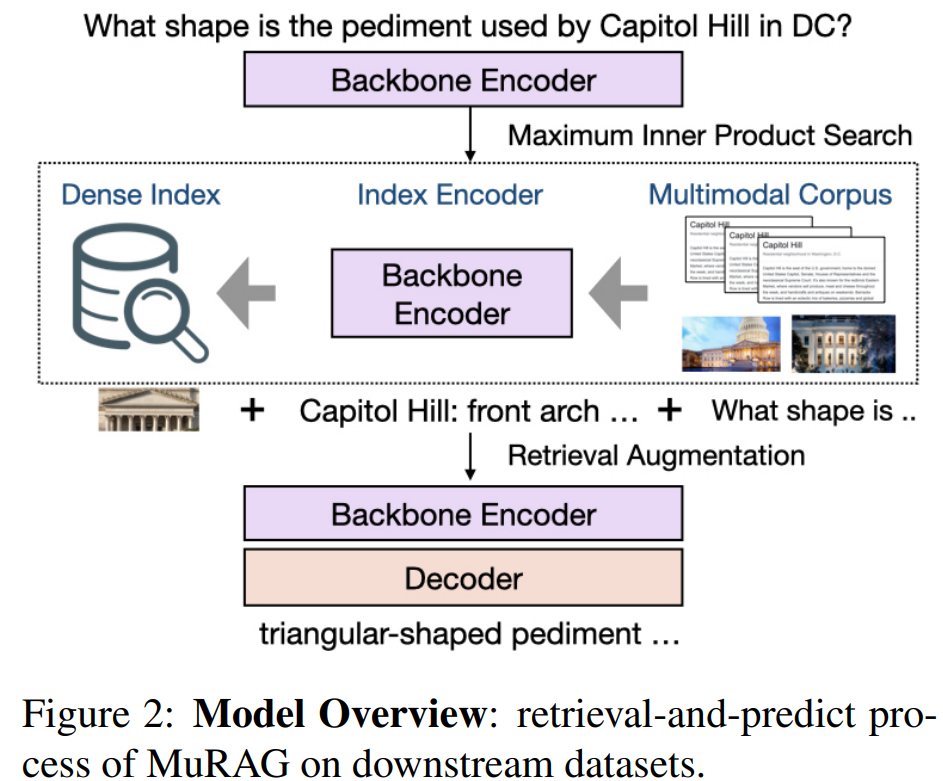
MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text
虽然语言模型在其参数中隐式地存储了大量知识,但即使是非常大的模型也常常无法编码关于罕见实体和事件的信息,同时产生巨大的计算成本。最近,检索增强模型(如REALM、RAG和RETRO)通过利用外部非参数索引将世界知识合并到语言生成中,并在模型大小受限的情况下展示了令人印象深刻的性能。然而,这些方法仅限于检索文本知识,忽略了图像等其他形式中无处不在的知识量——其中许多包含任何文本都无法覆盖的信息。为了解决这一限制,我们提出了第一个多模态检索增强转换器(MuRAG),它访问一个外部非参数多模态存储器来增强语言生成。MuRAG使用混合的大规模图像-文本和纯文本语料库,使用联合对比和生成损失进行预训练。其中模型结构图如下所示:
10、生成实体类型(GET)新范式
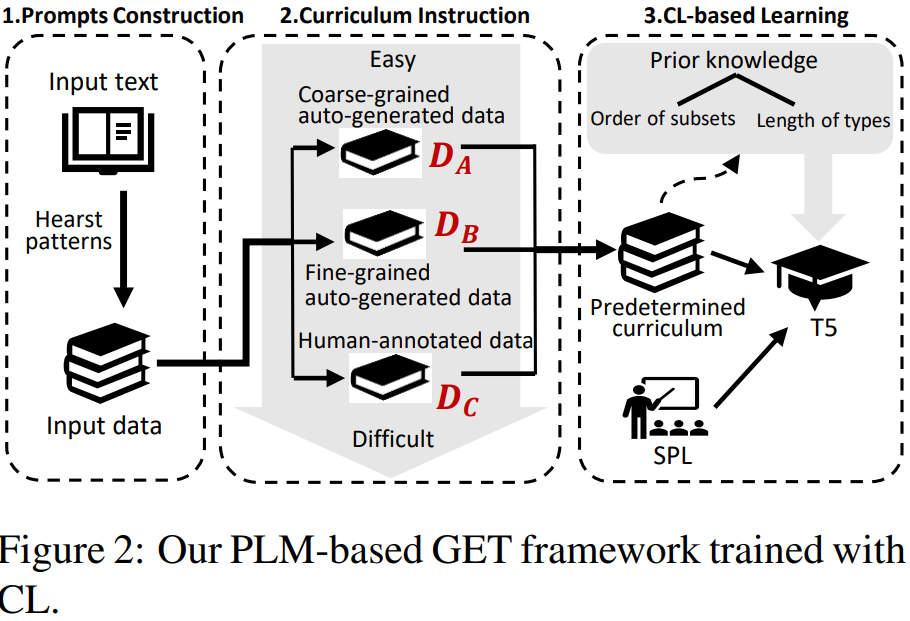
Generative Entity Typing with Curriculum Learning
实体类型化的目的是为给定文本中提到的实体指定类型。传统的基于分类的实体类型范式有两个不可忽视的缺点:1)它不能将实体分配给预定义类型集以外的类型;2)它很难处理许多长尾类型只有很少甚至没有训练实例的少发和零发情况。为了克服这些缺点,本文提出了一种新的生成实体类型(GET)范式:给定一个提到实体的文本,实体在文本中所扮演的角色的多个类型通过预先训练的语言模型(PLM)生成。然而,plm倾向于在对实体类型数据集进行微调后生成粗粒度的类型。此外,我们只有由一小部分人工注释数据和大量自动生成但质量较低的数据组成的异构训练数据。为了解决这些问题,采用课程学习(CL)对异构数据进行训练,根据课程对类型粒度和数据异质性的理解,使用自节奏学习对GET模型进行自调整。我们在不同语言和下游任务的数据集上的大量实验证明了GET模型比最先进的实体类型模型的优越性。其中模型结构图如下所示:
11、多向可控文本生成
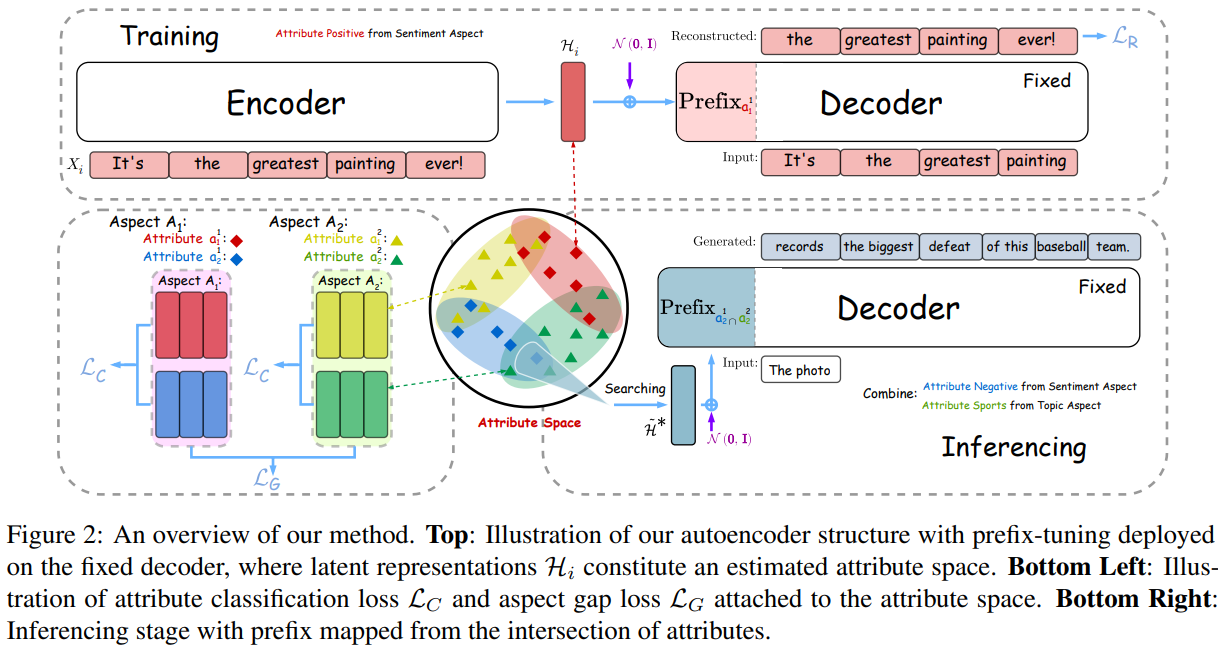
A Distributional Lens for Multi-Aspect Controllable Text Generation
多向可控文本生成是一项比单向控制更具挑战性和实用性的任务。现有方法通过融合从单一方面学习到的多个控制器来实现复杂的多方面控制,但由于各控制器之间的相互干扰,导致属性退化。为了解决这个问题,我们从分布的角度对属性融合进行了观察,并提出直接搜索多个属性分布的交集区域作为它们的组合进行生成。我们的方法首先用自编码器结构估计属性空间。之后,我们通过联合最小化到表示不同属性的点的距离来迭代地接近交点。最后,我们使用基于前缀调优的解码器将它们映射到与属性相关的句子。其中模型结构图如下所示:
12、多文档格式文献理解
XDoc: Unified Pre-training for Cross-Format Document Understanding
近年来随着文献理解预训练的兴起,文献理解也得到了快速发展。预训练和微调框架已有效地用于处理各种格式的文本,包括纯文本、文档文本和web文本。尽管取得了良好的性能,但现有的预训练模型通常一次只针对一种特定的文档格式,这使得结合来自多种文档格式的知识变得困难。为了解决这个问题,本文提出了XDoc,这是一个统一的预训练模型,它在一个模型中处理不同的文档格式。为了提高参数效率,我们共享了不同格式的骨干参数,例如单词嵌入层和Transformer层。同时,我们引入了具有轻量级参数的自适应层,以增强不同格式之间的区别。其中模型结构图如下所示:

13、摘要提取评价新方法(ClozE)
Just ClozE! A Fast and Simple Method for Evaluating the Factual Consistency in Abstractive Summarization
摘要中的事实一致性问题近年来备受关注,摘要与文献的事实一致性评价已成为一项重要而紧迫的任务。目前的评价指标大多采用问答(QA)。然而,基于质量的度量方法在实际应用中非常耗时,严重延长了摘要提取研究的迭代周期。本文提出了一种基于掩码语言模型(MLM)实例化的基于完形词模型的事实一致性评价新方法——完形词模型(ClozE),具有较强的解释性和较高的速度。其中模型结构图如下所示:

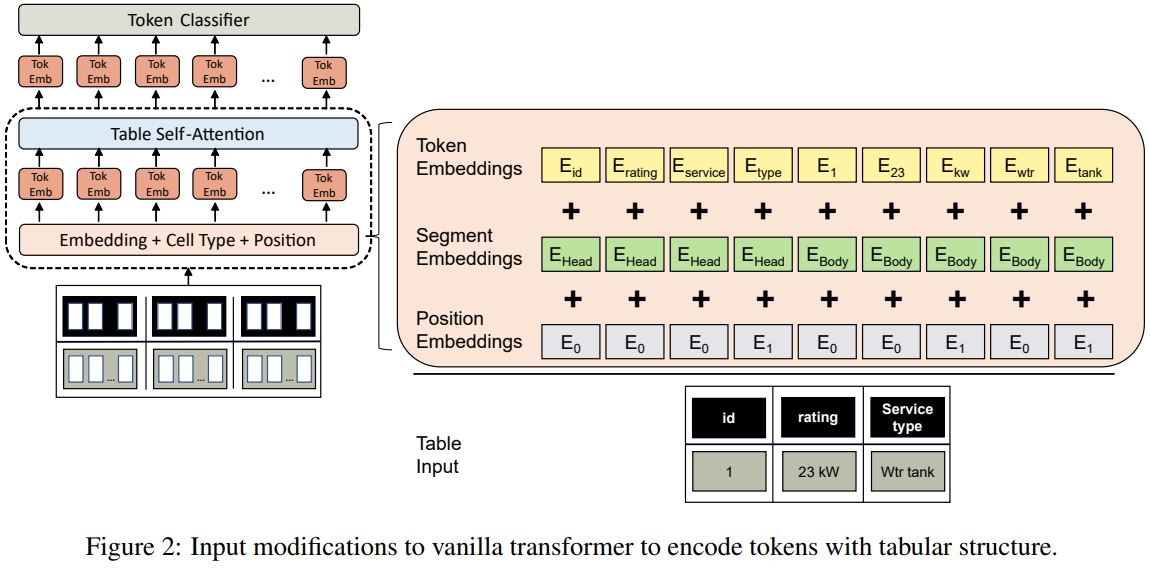
14、表格数据编码模型
Named Entity Recognition in Industrial Tables using Tabular Language Models
基于Transformer的表格数据编码模型已引起学术界的兴趣。虽然表格数据在工业中无所不在,但表格Transformer的应用仍然缺乏。在本文中,研究了如何将这些模型应用于工业命名实体识别(NER)问题,其中实体是在表格结构电子表格中提到的。电子表格的高度技术性以及缺乏标签数据为微调基于Transformer的模型提出了主要挑战。因此,我们基于可用的特定于领域的知识图开发了一个专用的表数据增强策略。我们展示了这在低资源场景中大大提高了性能。其中模型结构图如下所示:
15、Text-to-SQL语义理解提升
Improving Text-to-SQL Semantic Parsing with Fine-grained Query Understanding
关于文本到sql语义解析的研究大多依靠解析器本身或简单的基于启发式的方法来理解自然语言查询(NLQ)。当合成一个SQL查询时,解析器没有NLQ的显式语义信息,这会降低泛化性。此外,在没有词汇级细粒度查询理解的情况下,查询与数据库之间的链接只能依靠模糊字符串匹配,导致在实际应用中性能不佳。鉴于此,在本文中,提出了一个基于令牌级细粒度查询理解的通用模块化神经语义解析框架。我们的框架由三个模块组成:命名实体识别器(NER)、神经实体链接器(NEL)和神经语义解析器(NSP) 。NER模型通过对查询和数据库的联合建模,分析用户意图并识别查询中的实体。NEL模型将类型化实体链接到数据库中的模式和单元格值。解析器模型利用可用的语义信息和链接结果,并基于动态生成的语法合成树状SQL查询。其中模型结构图如下所示:

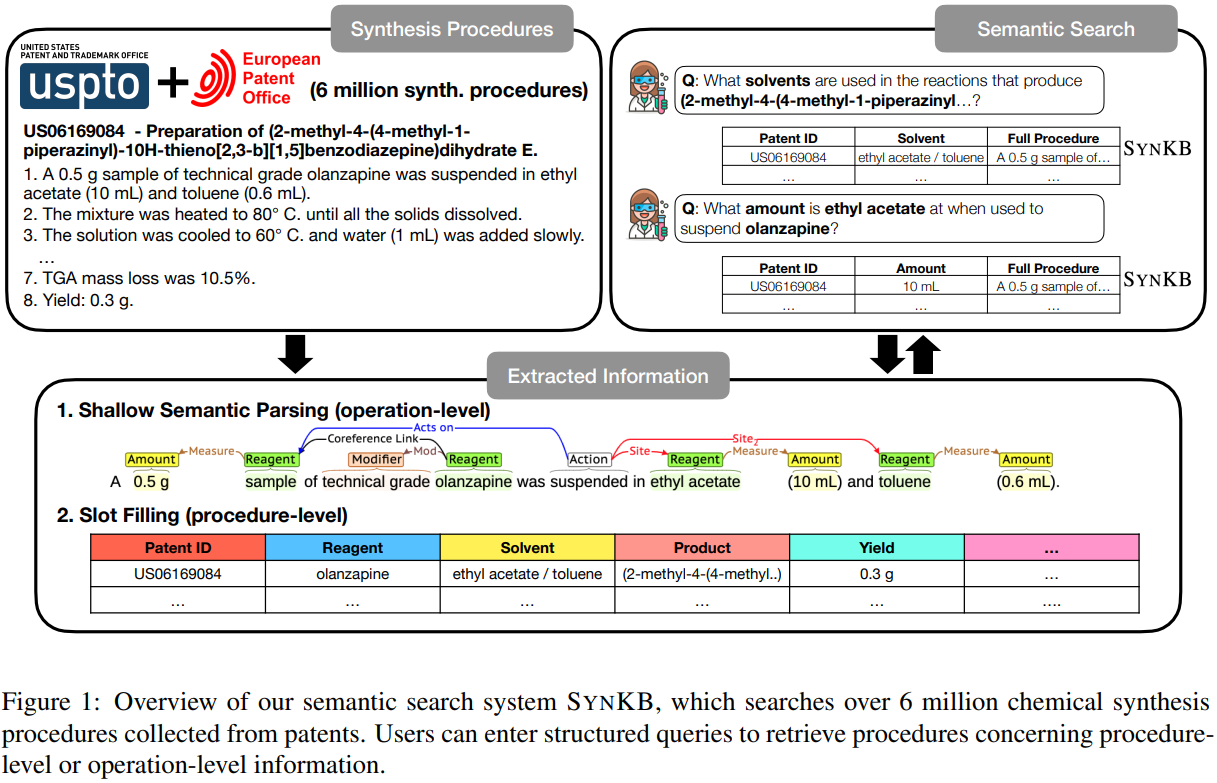
16、化学合成协议知识库SynKB
SynKB: Semantic Search for Synthetic Procedures
本文介绍了一个开源的、自动提取的化学合成协议知识库SynKB。与Reaxsys等专有化学数据库类似,SynKB允许化学家检索合成过程的结构化知识。通过利用程序性文本的自然语言处理的最新进展,SynKB支持对反应条件的更灵活的查询,因此有可能帮助化学家在设计新的合成路线时搜索相关反应条件的文献。使用定制的Transformer模型从美国和欧盟专利中描述的600万个合成过程中自动提取信息,我们表明,对于许多查询,SynKB比Reaxsys具有更高的召回率,同时保持较高的精度。我们计划将SynKB作为开源工具提供;相比之下,专有化学数据库需要昂贵的订阅。语义搜索系统SYNKB如下图所示:
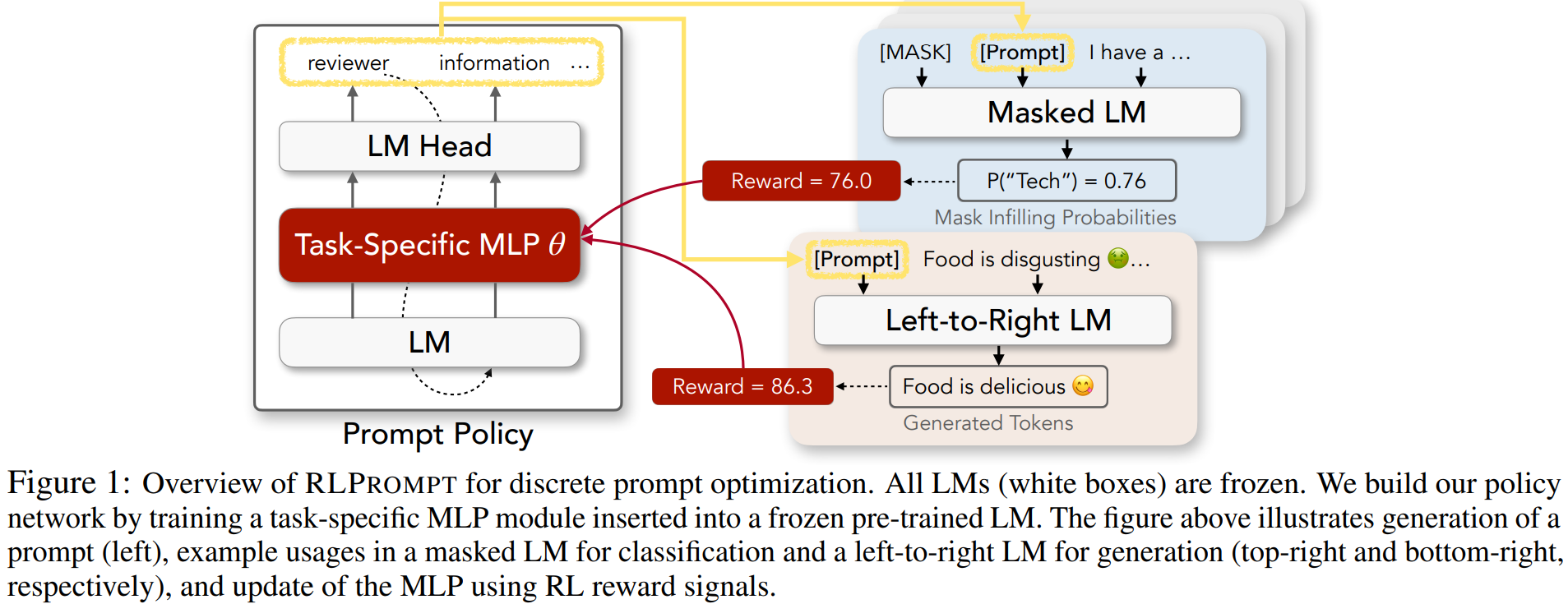
17、强化学习的离散prompt优化
RLPrompt: Optimizing Discrete Text Prompts with Reinforcement Learning
提示在使大型预训练语言模型(lm)执行不同的NLP任务方面取得了很好的成绩,特别是在只有少量下游数据可用的情况下。然而,为每个任务自动找到最佳提示符是一项挑战。大多数现有工作诉诸于调优软提示(例如,嵌入),这缺乏可解释性、跨lm的可重用性,以及在梯度不可访问时的适用性。另一方面,离散提示很难优化,通常是由“枚举(例如,释义)-然后选择”的启发式创建的,这种启发式没有系统地探索提示空间。本文提出了一种基于强化学习(RL)的离散提示优化方法RLPrompt。RLPrompt制定了一个参数高效的策略网络,在有奖励的训练后生成所需的离散提示。为了克服大型LM环境中奖励信号的复杂性和随机性,我们引入了有效的奖励稳定性,大大提高了训练效率。对于分类和生成任务,RLPrompt灵活地适用于不同类型的lm,例如掩码(例如BERT)和从左到右的模型(例如GPTs)。对小样本分类和无监督文本样式转移的实验表明,该方法的性能优于现有的一系列微调或提示方法。其中模型结构图如下所示:
18、元嵌入研究
Gender Bias in Meta-Embeddings
人们提出了不同的方法来从一组给定的源嵌入开发元嵌入。然而,源嵌入可能包含不公平的性别相关偏见,而这些偏见如何影响元嵌入尚未得到研究。我们研究了在三种不同设置下创建的元嵌入中的性别偏见:(1)不进行任何去偏的多源元嵌入(Multi-Source no - debias),(2)单一方法去偏的多源元嵌入(Multi-Source single - debias),以及(3)不同方法去偏的单一源元嵌入(single - source multi - debias)。我们的实验结果表明,与输入源嵌入相比,元嵌入放大了性别偏见。我们发现,要减轻这些偏见,不仅需要消除信息源的偏见,还需要消除它们的元嵌入。此外,我们提出了一种新的基于元嵌入学习的去偏方法,即对单个源嵌入使用多个去偏方法,然后创建单个无偏元嵌入。三种不同元嵌入如下图所示:

19、零样本链接预测 (HNZSLP)
A Hierarchical N-Gram Framework for Zero-Shot Link Prediction
由于知识图(KGs)的不完备性,而零样本链接预测(ZSLP)又可以预测知识图中未观察到的关系,这引起了研究人员的关注。一种常见的解决方案是使用关系的文本特征(例如,表面名称或文本描述)作为辅助信息,以弥合可见关系和不可见关系之间的差距。目前的方法学习对文本中的每个单词标记进行嵌入。由于存在词汇表不足(OOV)的问题,这些方法缺乏鲁棒性。同时,基于字符n-grams的模型具有生成OOV词表达表示的能力。因此,在本文中,提出了一种用于零样本链接预测 (HNZSLP) 的分层 N-Gram 框架,该框架考虑了 ZSLP 关系表面名称的字符 n-gram 之间的依赖关系。我们的方法首先在表面名称上构建一个分层的 n-gram 图,以对导致表面名称的 n-gram 的组织结构进行建模。然后提出基于 Transformer 的 GramTransformer 来对分层 n-gram 图进行建模,以构建 ZSLP 的关系嵌入。其中模型结构图如下所示:

20、知识密集型语言任务的集成框架
KGI: An Integrated Framework for Knowledge Intensive Language Tasks
本文提出了一个系统,以展示最新的最先进的检索增强生成模型的能力训练的知识密集型语言任务,如插槽填充,开放领域的问题回答,对话,和事实核查。此外,给出一个用户查询,我们将展示如何将这些不同模型的输出组合起来,以交叉检查彼此的输出。特别是,展示了如何使用问题回答模型来提高对话的准确性。其中模型结构图如下所示:

21、Fast-R2D2语法归纳和文本表示
Fast-R2D2: A Pretrained Recursive Neural Network based on Pruned CKY for Grammar Induction and Text Representation
最近,基于CKY的模型在无监督语法归纳方面显示出了巨大的潜力,这得益于其类似人类的编码范式,它以递归和分层方式运行,但需要 O ( n 3 ) O(n^3) O(n3)的时间复杂度。基于可微分树(R2D2)的递归转换器通过引入启发式修剪方法,使复杂树编码器也能扩展到大型语言模型的预训练。然而,基于规则的修剪方法存在局部最优和推理速度慢的问题。本文以统一的方法对这些问题进行了解决。我们提出使用自顶向下解析器作为基于模型的修剪方法,这也支持在推理期间进行并行编码。通常,我们的解析器将解析转换为拆分点评分任务,它首先为给定句子的所有拆分点评分,然后通过选择当前范围中得分最高的拆分点,递归地将跨度分为两个。在R2D2编码器中,分裂的反向顺序被认为是剪枝的顺序。除了双向语言模型损失,我们还通过最小化解析器和R2D2树概率之间的KL距离来优化解析器。实验表明,我们的Fast-R2D2算法在语法归纳方面有明显的提高,在下游分类任务中也取得了较好的成绩。
22、DP-SGD在NLP中的效率研究
One size does not fit all: Investigating strategies for differentially-private learning across NLP tasks
在当代 NLP 模型中保护隐私使我们能够处理敏感数据,但不幸的是要付出代价。我们知道,差分私有随机梯度下降 (DP-SGD) 中更严格的隐私保证通常会降低模型性能。然而,先前关于DP-SGD在NLP中的效率的研究尚无定论,甚至违反直觉。 在这篇简短的论文中,我们使用基于BERT和XtremeDistil架构的现代神经模型,对五个不同“典型”NLP 任务中七个下游数据集的不同隐私保护策略进行了广泛的分析,这些任务具有不同的复杂性。。我们表明,与解决NLP任务的标准非私有方法(通常越大越好)不同,隐私保护策略没有显示出获胜模式,并且每个任务和隐私机制都需要特殊处理才能获得足够的性能。
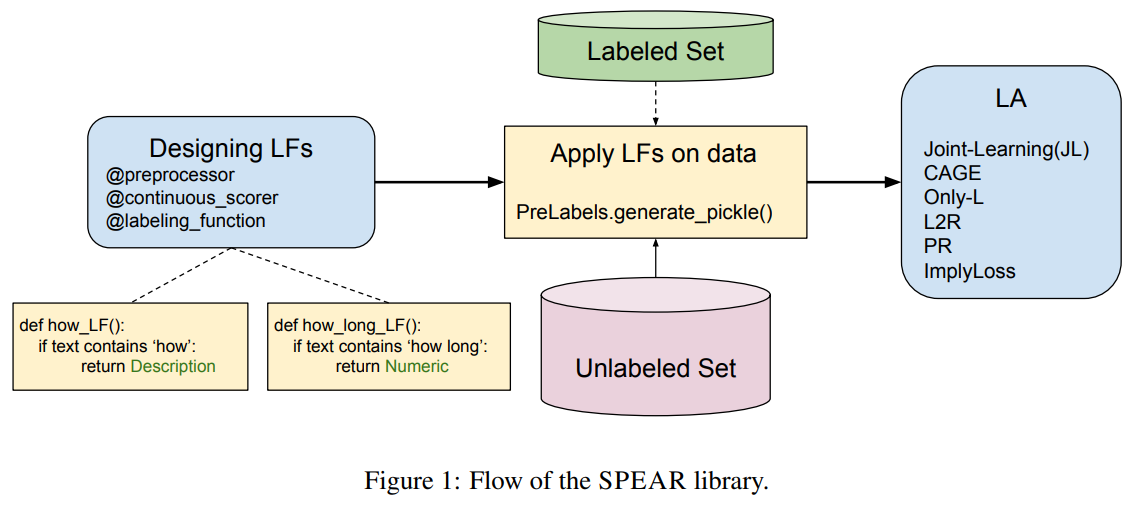
23、半监督数据编程python库
SPEAR : Semi-supervised Data Programming in Python
本文提出了SPEAR,一个用于半监督数据编程的开源python库。该包实现了几种最新的数据编程方法,包括以编程方式标记和构建训练数据的功能。SPEAR以启发式(或规则)的形式促进弱监督,并将噪声标签与训练数据集关联。这些噪声标签被聚合,以便为下游任务的未标记数据分配标签。我们实现了几种标签聚合方法来聚合噪声标签,然后以级联的方式使用噪声标记集进行训练。我们的实现还包括为文本分类任务联合聚合和训练模型的其他方法。因此,在我们的python包中,我们集成了几种级联和联合数据编程方法,同时还允许用户定义标记函数或规则,从而提供数据编程的便利。其中结构如下:
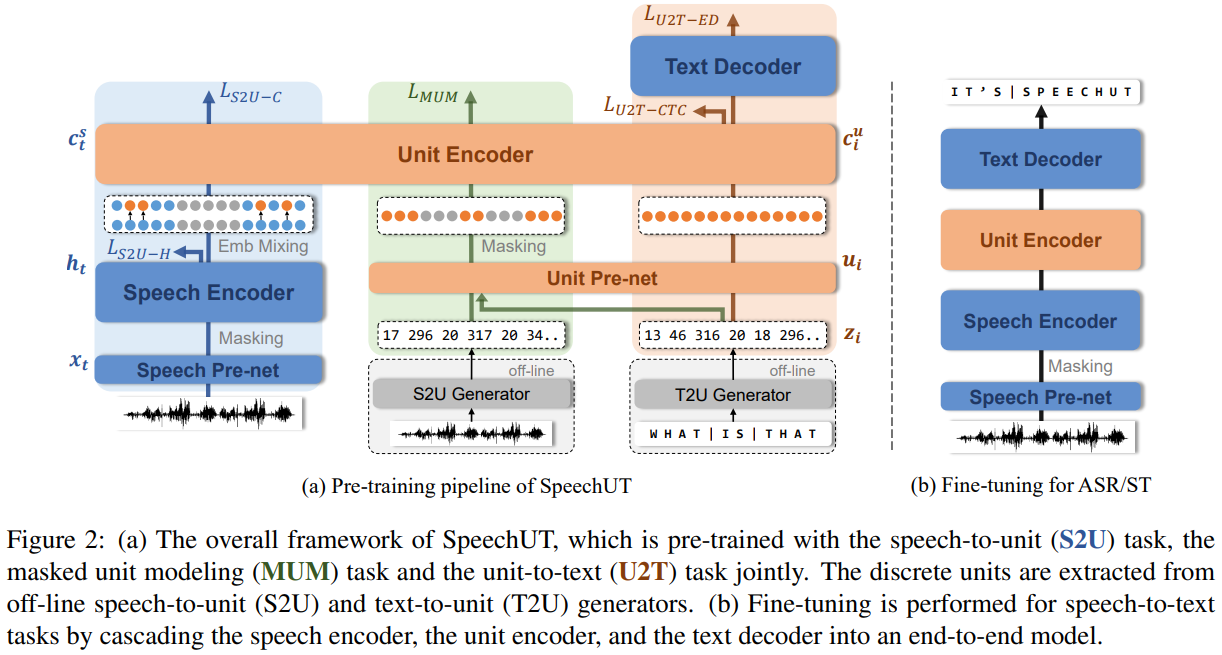
24、跨模态预训练
SpeechUT: Bridging Speech and Text with Hidden-Unit for Encoder-Decoder Based Speech-Text Pre-training
单模态预训练的快速发展使得跨模态预训练方法越来越受到研究者的重视。在本文提出了一种统一模式的语音单元文本预训练模型 SpeechUT,以将语音编码器和文本解码器的表示与共享单元编码器连接起来。 利用隐藏单元作为对齐语音和文本的接口,我们可以将语音到文本模型分解为语音到单元模型和单元到文本模型,可以与未配对语音联合预训练和文本数据。其中模型算法结构如下: