来源: AINLPer微信公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2022-10-23
引言
讽刺是一种语言表达方式,即其字面意义和隐含意图之间存在差异。由于其复杂的性质,通常很难从文本本身进行检测。因此,多模态讽刺检测在学术界和业界都受到了越来越多的关注。今天给大家分享的这篇文章,从多模态角度出发,通过对基于多头交叉注意机制的原子级一致性和基于图神经网络的成分级一致性进行研究,提出了一种新的基于层次结构的讽刺语检测框架。

EMNLP2022接受论文,第三波增量更新,关注 AINLPer公众号,回复:历年EMNLP
背景介绍
讽刺指的是讽刺或讽刺的语句,文字的字面意思与说话者的真实意图相反,以侮辱某人或幽默地批评某事。讽刺检测已经得到了相当多的批评关注,因为讽刺话语在今天的社交媒体平台上无处不在,如Twitter、weibo和Reddit。然而,根据迄今为止讽刺帖子的高度比喻性和复杂的语言同义性,区分它们是一项具有挑战性的任务

早期的讽刺检测方法主要依赖于固定的文本模式,例如词汇指示符、语法规则、特定的标签和表情符号,但由于以上方法未能利用上下文信息,通常效果性能和泛化能力较差。为了解决这个问题,有研究人员将讽刺语境或讽刺制造者的情绪作为建模的出发点,并获得到了不错的效果。然而,纯基于文本模态的讽刺检测方法可能无法区分某些讽刺话语,如上图所示。在没有恶劣天气预报图像的情况下,很难识别文本的真实情感。随着当前社交平台中文本-图像对的普遍存在,多模态方法通过获取文本和视觉模态之间的一致性信息,使得讽刺预测变得更加有效。
然而,大多数现有的多模态技术仅考考虑每个token和image-patch之间的一致性,而忽略了多粒度(例如对象等粒度和对象之间的关系)对齐的重要性,如跨模态检索和图像-句子匹配。 事实上,文本和图像的层次结构都提倡除了单个标记或图像块之外的组合建模。通过探索讽刺检测的合成语义,它有助于识别更复杂的不一致,例如,一对相关实体和一组图像补丁之间的不一致。
此外,由于讽刺话语中固有的具象化和微妙性可能会给讽刺识别带来负面影响,有研究发现,讽刺识别还依赖于输入文本和图像之外的外部世界知识作为新的上下文信息。事实上,一些研究从图像中提取图像属性或形容词-名词对(anp)作为视觉语义信息,以弥合文本和图像之间的差距。然而,受限于有限的训练数据,这些外部知识可能不足以充分或准确地表示图像,这可能会给讽刺检测带来负面影响。因此,如何选择和利用外部知识进行讽刺检测也值得研究。
模型介绍
为了解决上述限制,在这项工作中,我们提出了一种新的用于讽刺检测的分层框架,如下图所示。该方法既考虑了独立图像对象和标记之间的原子级一致性,又考虑了对象关系和语义依赖关系的组合级一致性,以促进多模态讽刺识别。

其中:
- 获得原子级的一致性:首先采用多头交叉注意机制将来自不同模态的特征投影到同一空间中,然后通过内积计算每个标记-对象对的相似度得分。
- 获得组合级一致性:根据上一步中获得的文本模态和视觉模态的输出特征获得。具体来说,我们分别使用单词之间的语义依赖关系和对象区域之间的空间依赖关系来构建文本图和视觉图,以使用图注意力网络捕获每种模态的组合级特征。本文模型连接了原子级和组合级的一致性特征,其中共同考虑了不同级别的文本和图像之间的语义不匹配。
其中本文所使用的术语:一致性是指图像与文本之间的语义一致性。如果图像和文本对的意义是矛盾的,那么这对图像和文本对的一致性就会降低。原子介于标记和图像补丁之间,组合介于一组标记(短语)和一组补丁(可视对象)之间。
除此之外,本文指出采用预训练的可迁移基础模型从视觉模态中提取文本信息作为外部知识来辅助讽刺检测。应用可迁移基础模型的合理性在于它们在基于零样本设置的一组综合任务(例如描述性和客观的字幕生成任务)上的有效性。因此,提取的文本包含丰富的图像信息,可用于构建用于讽刺检测的附加判别特征。与原始文本输入类似,生成的外部知识还包含用于讽刺检测的分层信息,这些信息可以一致地合并到我们提出的框架中,以计算针对原始文本输入的多粒度一致性。
实验结果
1、通过与下表展示基线模型比较来评估本文框架的有效性。讽刺检测的比较结果显示:本文模型最优。(其中:† 表示以ResNet主干,‡表示以ViT主干。)
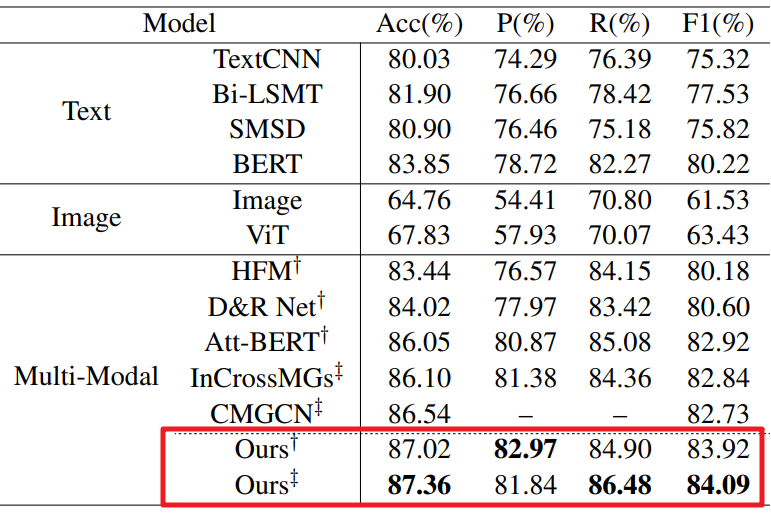
2、通过考虑外部知识来评估本文模型的有效性。下表3报告了我们提出的通过考虑不同类型的知识增强的讽刺检测方法的准确性和f1得分。通过加入图像标题,与原始模型(无外部知识)相比,性能进一步提高。

3、如下表所示,本文模型在组合所有这些组件时实现了最佳性能。

推荐阅读
[1] EMNLP2022 | 带有实体内存(Entity Memory)的统一编解码框架 (美国圣母大学)
[2] NeurIPS2022 | 训练缺少数据?你还有“零样本学习(zero-shot Learning)”(香槟分校)