文章目录
前言
LibriSpeech应该是Kaldi中最完善的一个例子,不同于最开始跑的简单的yesno这个例子。
一、LibriSpeech是什么?
LibriSpeech 语料库是一个大型(1000 小时)英语阅读语音语料库源自 LibriVox 项目中的有声读物,以 16kHz 采样。 这口音多种多样,没有标记,但大多数是美国英语。 这是可在 http://www.openslr.org/12/ 免费下载。 准备好了作为 Vassil Panayotov 的语音识别语料库。
二、执行
1.克隆Kaldi的代码
Kaldi代码地址
https://github.com/kaldi-asr/kaldi
克隆代码
git clone [email protected]:kaldi-asr/kaldi.git
2.运行LibriSpeech
$ cd kaldi/egs/librispeech/s5
$ ./run.sh
1、可能的第一处已报错
此时应该会报错,输出文件不存在
local/download_and_untar.sh: no such directory /export/a15/vpanayotov/data
解决方案:
$ vim run.sh
我们截取run.sh脚本的修改的部分,问题就出在脚本中的data,告诉我们这个路径不存在,Ubuntu中/export/a15/vpanayotov/data第一个/代表根(root)目录,意思就是报错告诉你根目录中这个文件夹不存在,但是我们肯定不想在根目录去创建这个文件夹,我们要做的是在LibriSpeech中创建。
#!/usr/bin/env bash
# Set this to somewhere where you want to put your data, or where
# someone else has already put it. You'll want to change this
# if you're not on the CLSP grid.
# run.sh脚本中本身的路径
# data=/export/a15/vpanayotov/data
# 修改为export/a15/vpanayotov/data,去掉第一个/,此时就是一个相对路径
# 就是在kaldi/egs/librispeech/s5这个目录中在创建export/a15/vpanayotov/data
data=export/a15/vpanayotov/data
# 并且将这个文件夹创建出来,要么修改在脚本中,要么直接在kaldi/egs/librispeech/s5中执行如下命令
# 命令行执行需要将$data修改为实际的文件目录export/a15/vpanayotov/data
mkdir -p $data
然后执行run.sh脚本,就开始执行数据的下载,准备等等
$ ./run.sh
此时脚本就运行起来了,然后就开始下载需要的文件,run.sh部分内容如下
#!/usr/bin/env bash
# Set this to somewhere where you want to put your data, or where
# someone else has already put it. You'll want to change this
# if you're not on the CLSP grid.
# data=/export/a15/vpanayotov/data
data=/home/dinghui/code/kaldi/kaldi/egs/librispeech/s5/data/storage
# base url for downloads.
# 这就是需要准备的数据的下载链接
data_url=www.openslr.org/resources/12
lm_url=www.openslr.org/resources/11
mfccdir=mfcc
stage=1
. ./cmd.sh
. ./path.sh
. parse_options.sh
# you might not want to do this for interactive shells.
set -e
# 此时就开始执行下载,下载data_url=www.openslr.org/resources/12中的数据
if [ $stage -le 1 ]; then
# download the data. Note: we're using the 100 hour setup for
# now; later in the script we'll download more and use it to train neural
# nets.
for part in dev-clean test-clean dev-other test-other train-clean-100; do
# 通过download_and_untar.sh脚本下载文件
# 下载dev-clean test-clean dev-other test-other train-clean-100这几个文件
local/download_and_untar.sh $data $data_url $part
done
# download the LM resources
# 下载lm_url=www.openslr.org/resources/11包含的数据
local/download_lm.sh $lm_url data/local/lm
fi
# 数据已经下载完成,开始整理数据
if [ $stage -le 2 ]; then
# format the data as Kaldi data directories
for part in dev-clean test-clean dev-other test-other train-clean-100; do
# use underscore-separated names in data directories.
local/data_prep.sh $data/LibriSpeech/$part data/$(echo $part | sed s/-/_/g)
done
fi
.......
if [ $stage -le 15 ]; then
# 下载data_url=www.openslr.org/resources/12中的train-clean-360
local/download_and_untar.sh $data $data_url train-clean-360
# now add the "clean-360" subset to the mix ...
local/data_prep.sh \
$data/LibriSpeech/train-clean-360 data/train_clean_360
......
fi
......
if [ $stage -le 17 ]; then
# prepare the remaining 500 hours of data
# 下载data_url=www.openslr.org/resources/12中的train-other-500
local/download_and_untar.sh $data $data_url train-other-500
# prepare the 500 hour subset.
local/data_prep.sh \
$data/LibriSpeech/train-other-500 data/train_other_500
.....
fi
如果下载顺利,上述数据已经通过终端下载完成。
2、可能的第二处已报错
查看我们上述的脚本,在数据下载完成之后会执行data_prep.sh这个脚本,此时可能会报错,告诉你flac没有安装,这个是用来转换音频的,将flac转为Kaldi需要的音频。
解决方案:
$ sudo apt-get update
$ sudo apt-get install flac
如果执行上述命令仍然报错,然后直接把图中圈出来的路径放在浏览器下载,然后手动安装。
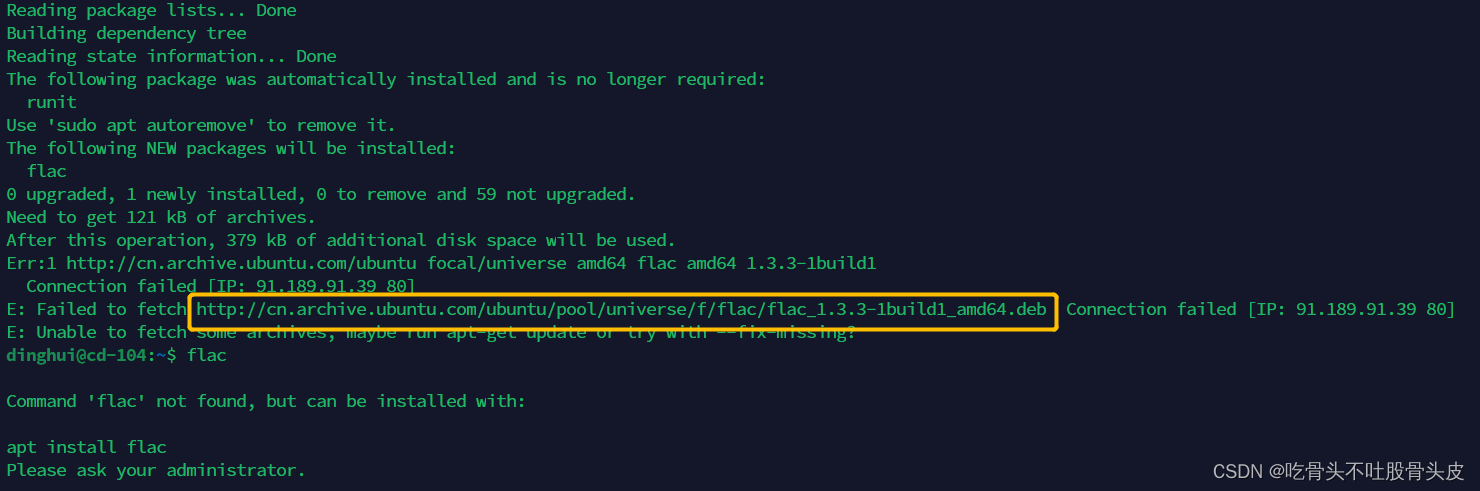
手动下载完成之后,然后执行如下命令进行安装
sudo dpkg -i flac_1.3.3-1build1_amd64.deb
3、可能的第三处已报错
flac安装成功之后,继续执行run.sh脚本,执行到kaldi/egs/librispeech/s5/exp/make_mfcc/dev_clean/q/make_mfcc_dev_clean.sh脚本可能会报错,qsub没有安装。

解决方式:
- 设置 GridEngine 以与 Kaldi 一起使用 ,按照官网文档操作,安装、配置GridEngine
- 直接修改cmd.sh脚本,使用特定脚本进行并行化文档中也有解决方案,直接用run.pl替换queue.pl,这种方式只是备选方案,最好还是老老实实的安装、配置GridEngine
修改cmd.sh
export train_cmd="queue.pl --mem 2G"
export decode_cmd="queue.pl --mem 4G"
export mkgraph_cmd="queue.pl --mem 8G"
# 将脚本中的queue.pl替换为run.pl
export train_cmd="run.pl --mem 2G"
export decode_cmd="run.pl --mem 4G"
export mkgraph_cmd="run.pl --mem 8G"
到此LibriSpeech就应该能够全部执行了,慢慢等待LibriSpeech运行结束。时间很漫长。
3.执行第二步run.sh脚本的时候,可能下载会很漫长或者下载失败,建议手动下载LibriSpeech需要的文件。
1、训练文件地址,就是脚本中data_url下载的文件,下载地址如下,需要下载的文件截图放在下面
https://www.openslr.org/12/
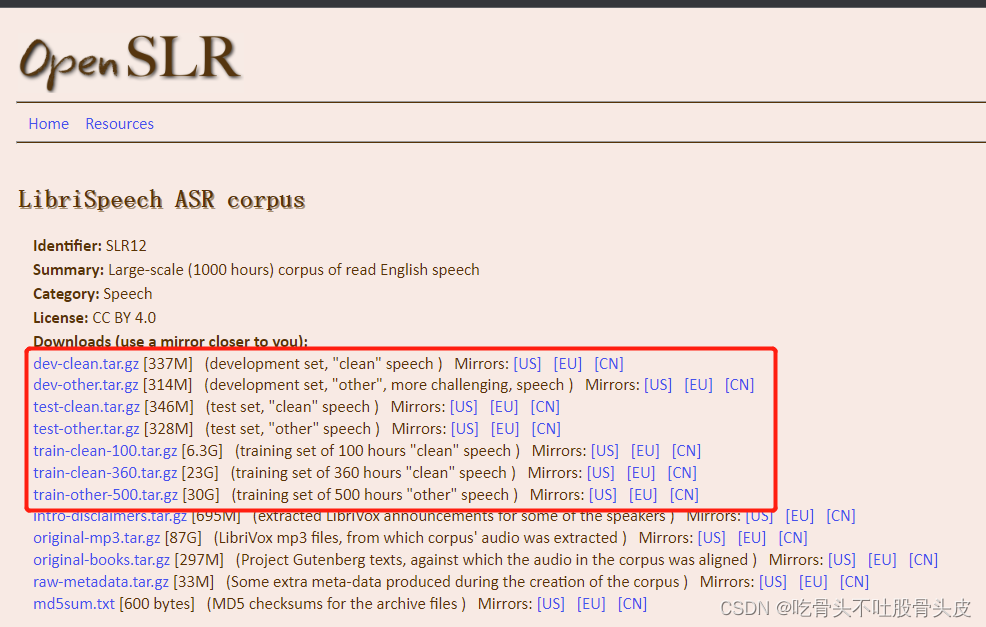
将下载好的文件拷贝到:/kaldi/egs/librispeech/s5/export/a15/vpanayotov/data
2、LM资源下载,脚本中lm_url指定的文件,下载地址如下,需要下载的文件截图,就是全部下载
https://www.openslr.org/11/

将文件拷贝到/kaldi/egs/librispeech/s5/export/a15/vpanayotov/data/local/lm
然后执行run.sh脚本
$ ./run.sh
总结
才接触Kaldi相关的东西,有问题希望大家指正,一起讨论,谢谢。