DenseNet和ResNet的区别有哪些
| ResNet | DenseNet | ||
|---|---|---|---|
| 1 | 贡献 | 提出残差学习来解决网络加深出现的退化问题 | 提出稠密shortcuts来缓解梯度消失问题,加强特征传播,实现特征重用,大大减少了参数量 |
| 2 | 当前层的输入不同 | ∑ i = 0 l X i \sum_{i=0}^{l}{X_i} ∑i=0lXi(前面所有层输输出相加) | C o n c a t e ( X 0 , X 1 , . . . , X l ) Concate(X_0,X_1,...,X_l) Concate(X0,X1,...,Xl)(通道维度相拼接) |
| 3 | 训练速度 | 较快 | 较慢(因为随着 l l l的增大,每一个卷积层的输入通道数也在不断增大,通常会比ResBet同层的 H l H_l Hl通道数更大,拼接也带来更大的存储消耗) |
| 4 | 参数量 | 相同深度,参数量较多 | 较少,因为整个网络中每一个卷积块的输出通道数都是一个固定的较小值(比如32) |
| 5 | 特征信息传递 | 加和的操作在一定程度上破坏了特征信息流的传递 | 拼接的方式使得DenseNet后面的层能获取更加丰富的输入,加强了特征信息流的传递,实现特征重用 |
区别2详解
参考《ResNet or DenseNet? Introducing Dense Shortcuts to ResNet》
对于标准卷积有:
f l = H l ∗ f l − 1 f_l = H_l*f_{l-1} fl=Hl∗fl−1
f l − 1 f_{l-1} fl−1指的是上一个卷积模块输出的特征图。
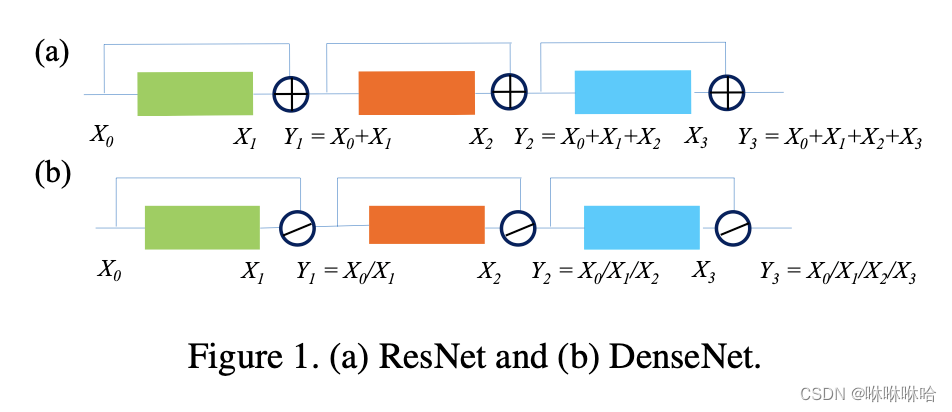
对于DenseNet来说, f l − 1 = Y l = ( X 0 / X 1 / . . . X l ) f_{l-1}=Y_l=(X_0/X_1/...X_l) fl−1=Yl=(X0/X1/...Xl)
对于ResNet来说, f l − 1 = Y l = ( X 0 + X 1 + . . . X l ) f_{l-1}=Y_l=(X_0+X_1+...X_l) fl−1=Yl=(X0+X1+...Xl)
所以有区别2:ResNet处理的是前面所有层输出的加和,DesNet处理的是前面所有层输出的的通道维度上的拼接。
区别3详解
相比于同等深度的ResNet,DenseNet的训练速度更慢,RepVGG: Making VGG-style ConvNets Great Again是因为随着 l l l的增大,每一个卷积层的输入通道数也在不断增大,通常会比ResNet同层的 H l H_l Hl通道数更大,而且每次读取通道数较大的特征也会带来很多IO时间的消耗,所以从总体来看DenseNet的训练速度会更慢。此外为了存储拼接后的特征图,带来的存储峰值也更大,对于考虑Memory-economical的场景则不太适用。
区别5详解
因为每个卷积块的输入分布和输出分布是不同的,而加和操作会把破坏卷积输出的分布,而输出的分布在一定程度上代表了当前卷积块所学习到的特征,所以说会破坏网络中特征信息流的传递。
补充:
在《RepVGG: Making VGG-style ConvNets Great Again》这篇论文里还看到一个有意思的角度,DenseNet和ResNet都属于Multi-branch architecture的网络。
ResNet相当于two-branch,因为每个卷积模块的输出流向有两条分支,对于有 n n n个卷积块的ResNet,可以看作是 2 n 2^n 2n个浅层模型的集成。而DenseNet每个卷积模块的输出流向有多个分支,有着更复杂的拓扑结构,也就相当于是更多浅层模型的集成。所以DenseNet学习到的特征包含的信息更丰富,自然,相较于同等深度的ResNet,分类的检测的效果都有提升。
以上区别也是我在看论文的过程中总结的,如有不当,请指出。
参考链接
关于ResNet,DenseNet,以及梯度消失爆炸的详细解释,大家可以参考以下博文哦
https://zhuanlan.zhihu.com/p/31852747