2.2 M-P模型
M-P模型是多个输入对应一个输出的模型,可以实现简单的运算符的逻辑计算,结构如下图所示:
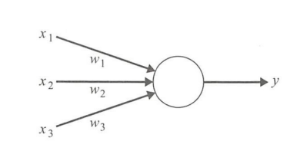
该模型的缺点在于参数需认为确定。
2.3 感知器
感知器的优点在于可以自动确定参数通过训练。
参数的获得是通过调整实际输出和期望输出之差的方式来获得,这叫做误差修正学习。用公式表示:
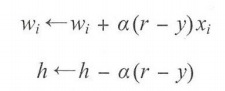
感知器的缺点在于只能解决线性可分问题,不能解决线性不可分的问题。
2.4 多层感知器
为了解决线性不可分问题,于是有了多层感知器。多层感知器的结构如下:
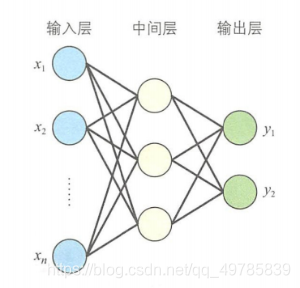
多层感知器通过误差修正学习来确定两层之间的连接权重,但不能跨层调整,因此早期的多层感知器只能对中间层和输出层之间的权重进行修正学习,对于输入层和中间层只能用随机数当权重。这种情况带来的问题在于可能会出现输入不同的输入值但是可以得到相同的输出值,这将无法准确分类。
那么多层感知器应该如何训练连接权重呢?后来人类提出了误差反向传播。
2.5 误差反向传播算法
误差反向传播算法就是通过比较实际输出和期望输出得到误差信号,把误差信号从输出层逐层向前传播得到各层的误差信号,再通过调整各层的连接权重以减小误差。调整的方式是叫做梯度下降算法。
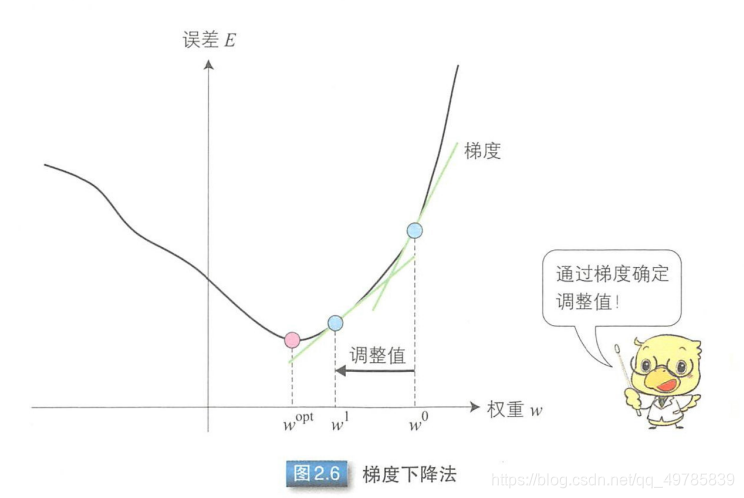
只有一个输出单元的多层感知器权重调整过程如下:
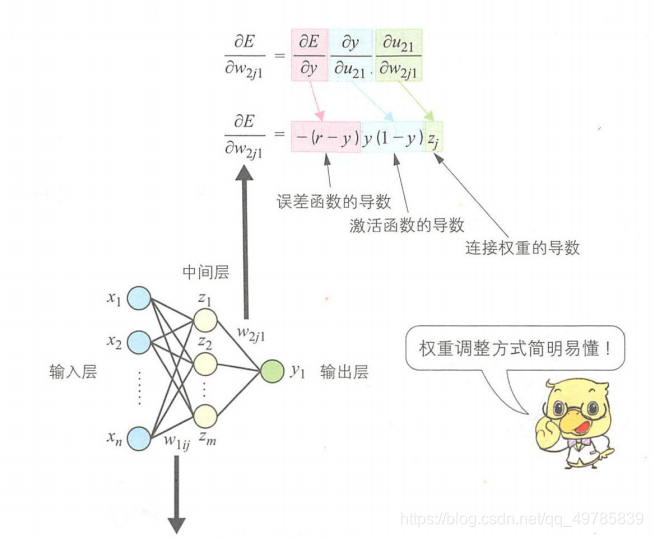

参数调整:

有多个输出单元的多层感知器权重调整过程如下:
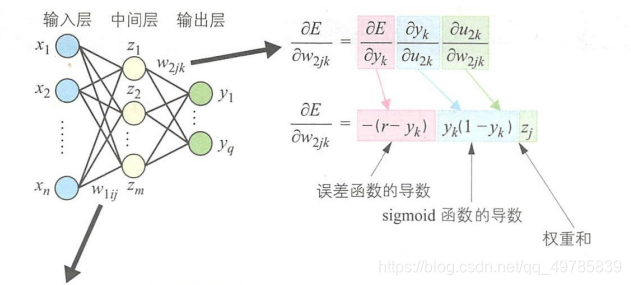
参数调整:
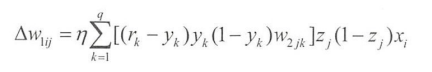
单个输出和多个输出的区别在于输入层和中间层之间的权重调整值是相关单元在中间层与输出层之间的权重调整值得总和。
但是激活函数求导后得到得函数值可能会是0,这种情况就会造成梯度消失导致无法调整权重。对于这个问题,需要在训练过程中调整学习率来防止梯度消失。
当层数较多时有可能产生梯度消失和梯度爆炸得情况。
2.6 误差函数和激活函数
一般情况下,误差函数(损失函数)
多分类用交叉熵代价函数:
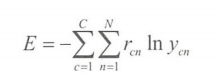
二分类用:
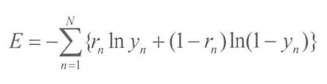
递归问题中用最小二乘误差函数:
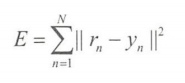
一般情况下激活函数有:
sigmod函数、tanhh函数、ReLU函数等。
2.7 似然函数
似然函数最常见得就是softmax函数。该函数可以解决以下两个问题:一是由于输出层的输出值的范围不确定,我们难以直观上判断这些值的意义。二是,由于真实标签是离散值,这些离散值与不确定范围的输出值之间的误差难以衡量。
2.8 随机梯度下降法
误差反向传播算法有多种,首先是第一种批量学习算法:每次迭代会遍历全部训练样本,该算法能有效一直训练集内噪声,但是训练时间较长。
第二种是在线学习算法,该算法会逐个输入训练样本。因此可能会导致迭代结果出现大幅变动,以至于训练无法收敛。
第三种是小批量随机梯度下降算法,该算法将训练集分成几个子集,每次迭代使用一个子集。全部子集迭代完成后,再次从第一个子集开始迭代调整权重。该方法每次迭代只使用少量样本,相比于批量学习来说能缩短单词训练时间。每次迭代也是使用多个训练样本,相比于在在线学习来说能够减少迭代结果得变动。
2.9 学习率
学习率是用来调整权重连接调整程度的系数。学习率越大步子越大,减少收敛额的时间,但是过大可能会导致无法收敛。而过小可能会收敛很慢。
此外还有一些自适应调整学习率。