前言
要求:将课本上分散的MPI梯形积分法的算法实现为完整的MPI程序,并在分布式环境下编译、排错、调试、运行、优化。然后总结学习心得,撰写实验报告。
提示:MPI程序启动时,程序可执行文件会在每个节点启动运行,因此程序中所有的变量都是本地的私有变量;进程之间进行通信时,必须收发一一对应,有发无收和有收无发都会导致程序卡死。
一、实验代码
代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <mpi.h>
double Trap(double left_endpt, double right_endpt, double trap_count, double base_len);
double f(double x);
void Get_data(int my_rank,int comm_sz,double* a,double* b,int* n);
int main(void)
{
int my_rank = 0, comm_sz = 0, n, local_n = 0;
double a , b , h , local_a = 0, local_b = 0;
double local_int = 0, total_int = 0;
int source;
MPI_Init(NULL,NULL);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
Get_data(my_rank,comm_sz,&a,&b,&n);
h = (b - a) / n;
local_n = n / comm_sz;
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
local_int = Trap(local_a, local_b, local_n, h);
if (my_rank != 0)
{
MPI_Send(&local_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
else
{
total_int = local_int;
for (source = 1; source < comm_sz; source++)
{
MPI_Recv(&local_int, 1, MPI_DOUBLE, source, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
total_int += local_int;
}
}
if (my_rank == 0)
{
printf("With n = %d trapezoids, our estimate\n", n);
printf("of the integral from %f to %f = %.15e\n", a, b, total_int);
}
MPI_Finalize();
return 0;
}
double Trap(double left_endpt, double right_endpt, double trap_count, double base_len)
{
double estimate = 0, x = 0;
int i;
estimate = (f(left_endpt) + f(right_endpt)) / 2.0;
for (i = 1; i <= trap_count - 1; i++)
{
x = left_endpt + i*base_len;
estimate += f(x);
}
estimate = estimate*base_len;
return estimate;
}
double f(double x)
{
return x;
}
void Get_data(int my_rank,int comm_sz,double* a,double* b,int* n)
{
if (my_rank == 0) {
printf("Enter a, b, and n \n");
scanf("%lf %lf %d", a, b, n);
for (int i = 1; i < comm_sz; i++) {
MPI_Send(a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
MPI_Send(b, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
MPI_Send(n, 1, MPI_INT, i, 0, MPI_COMM_WORLD);
}
}
else {
MPI_Recv(a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUSES_IGNORE);
MPI_Recv(b, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, MPI_STATUSES_IGNORE);
MPI_Recv(n, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUSES_IGNORE);
}
}
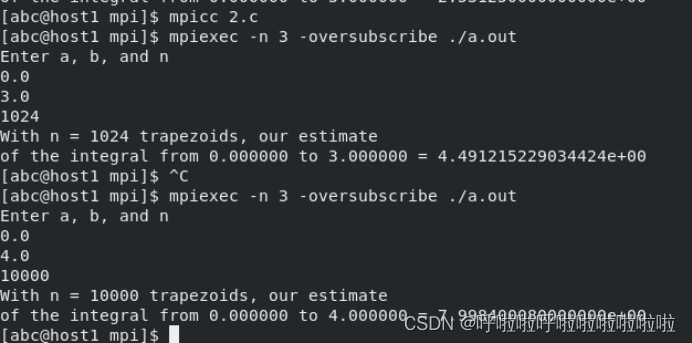
二、实验运行效果
三、问题以及思考
问题1:输入函数频繁报错。
解决方法:传过去的参数经过检验是不对的,改变传过去的参数的类型,同时也改变MPI_Send和MPI_Rev的函数的定义。
问题2:求梯形积分的函数返回值存在错误。
解决方法:设置函数类型为double型,接受返回的值为double
实现一一对应。
问题3:还有继续优化的空间。
解决方法:接下来将用广播的方法来实现输入的数传到各个核中去。
问题4:实验结果并不准确当n的值比较小时。
解决方法:与其算法思路有关改变n的值,就会使其更接近正确值,但是n的值较大时,结果又会不够准确,这和浮点数计算精度有关。(这个避免不了和浮点数计算精度有关,当时想了好久,没想到是本身自己思考的问题,还得细致点,不过现在已经好久没接触分布式了,怀念o(╥﹏╥)o)
总结
本次实验,体验了并行程序中平均分配任务,由各个核分别执行再由一个指定核输出的思想,每个核都独立承担一部分任务,再将计算的结果进行汇总,同时每个核计算时要考虑任务量大小进行分配(梯形积分法由于计算量相近所以可以直接平均分配),并行程序相比普通串行构想思路更难实现更难,但由于其极大地提升了机器的性能,具有极大的学习意义,尤其是对梯形积分法的实现过程无不体现这一思想。

学累了快来吃一口O(∩_∩)O哈哈~