吴恩达yolo算法
滑动窗口检测

使用不同大小的窗口滑动检测,但 速度慢
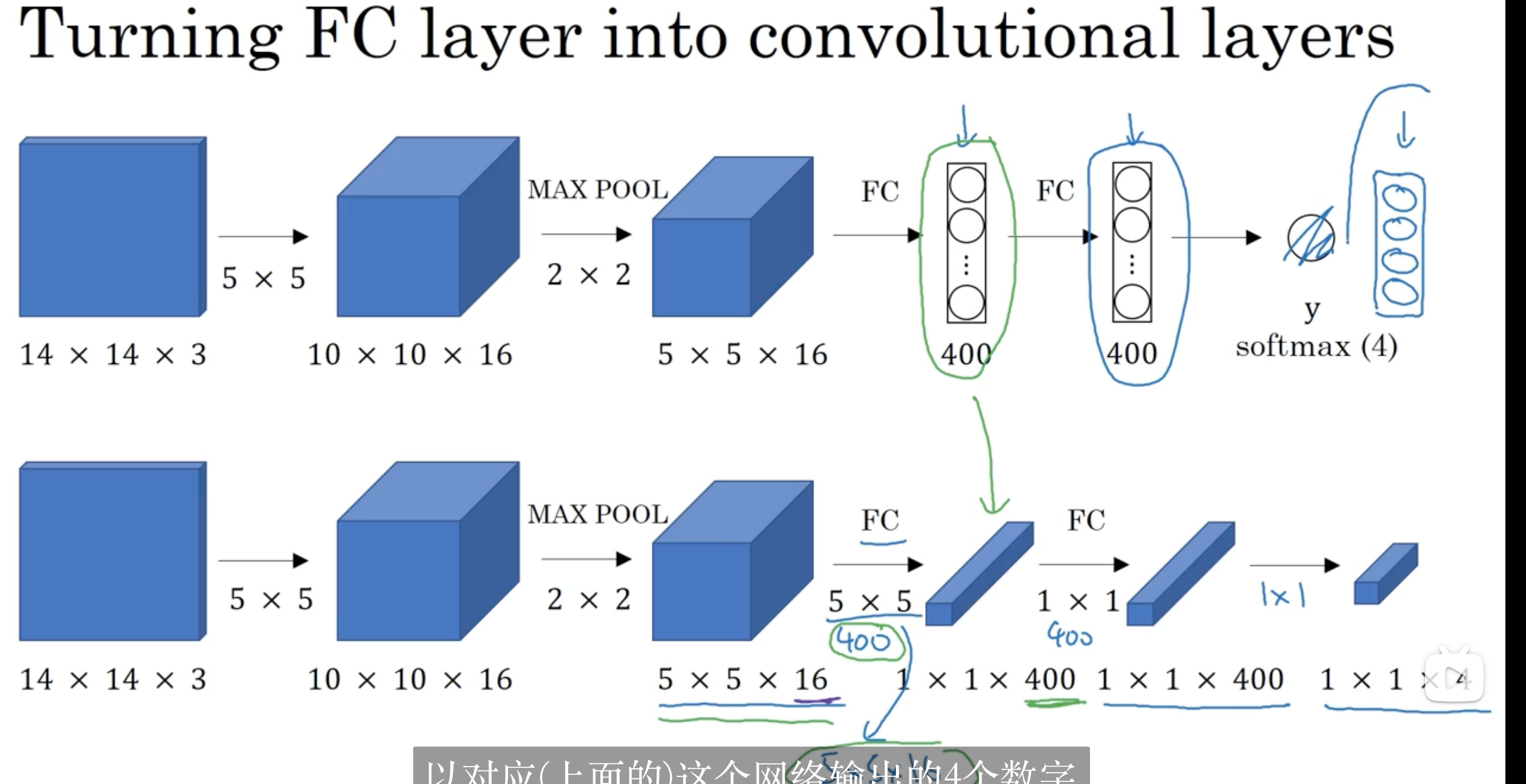
用卷积的方法实现滑动窗口检测
边界框的检测
当滑动窗口检测没有符合的窗口时,YOLO成为解决该问题的好方法
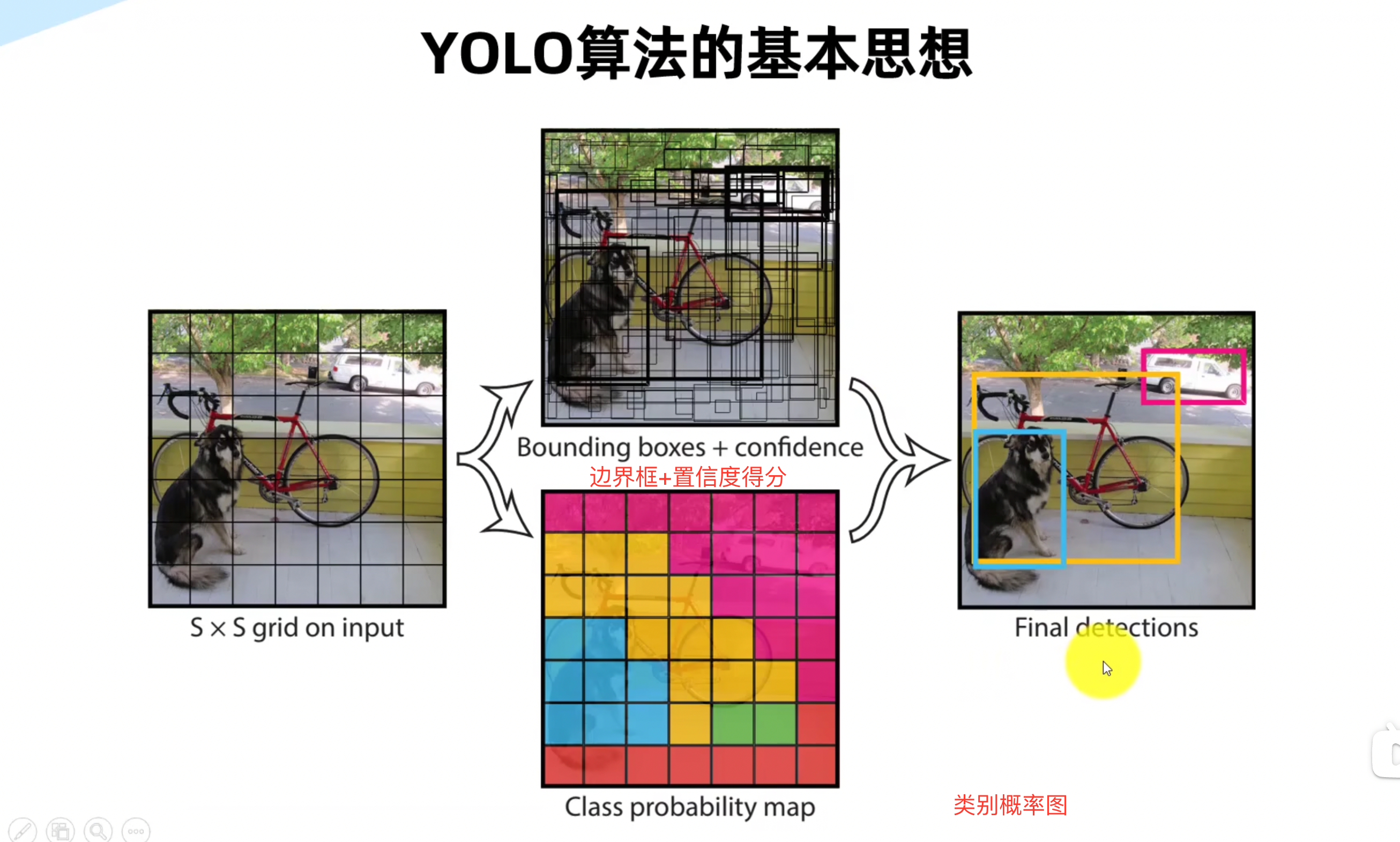
YOLO方法的步骤:
将整张图划分为若干网格图,例如可以分成九宫格
每个格子对应一个标签,标签一般是一个m维向量(图内是否包含要检测的物体,框的中心点横坐标,框的中心点纵坐标,框的宽,框的高,是否含有类A,是否含有类B……)YOLO算法就是把目标分配到所在网格处 ,因此输出向量的大小是3*3*m
因此,我们要做的仅仅是有一个类似100*100*3的图x,输出一个类似上述3*3*m的结果y,然后反向传播训练神经网络, 这个算法的好处是,映射 过程中的计算被共享,
值得一提的是,关于框的中心点横坐标,框的中心点纵坐标,框的宽,框的高都是相对于划分的单个网格而言,框的宽,框的高都可以大于1
交并比——检测目标检测算法
lou函数计算了结果框与实际框的交集/并集的值
非最大值抑制

锚框——一个网格多个检测目标
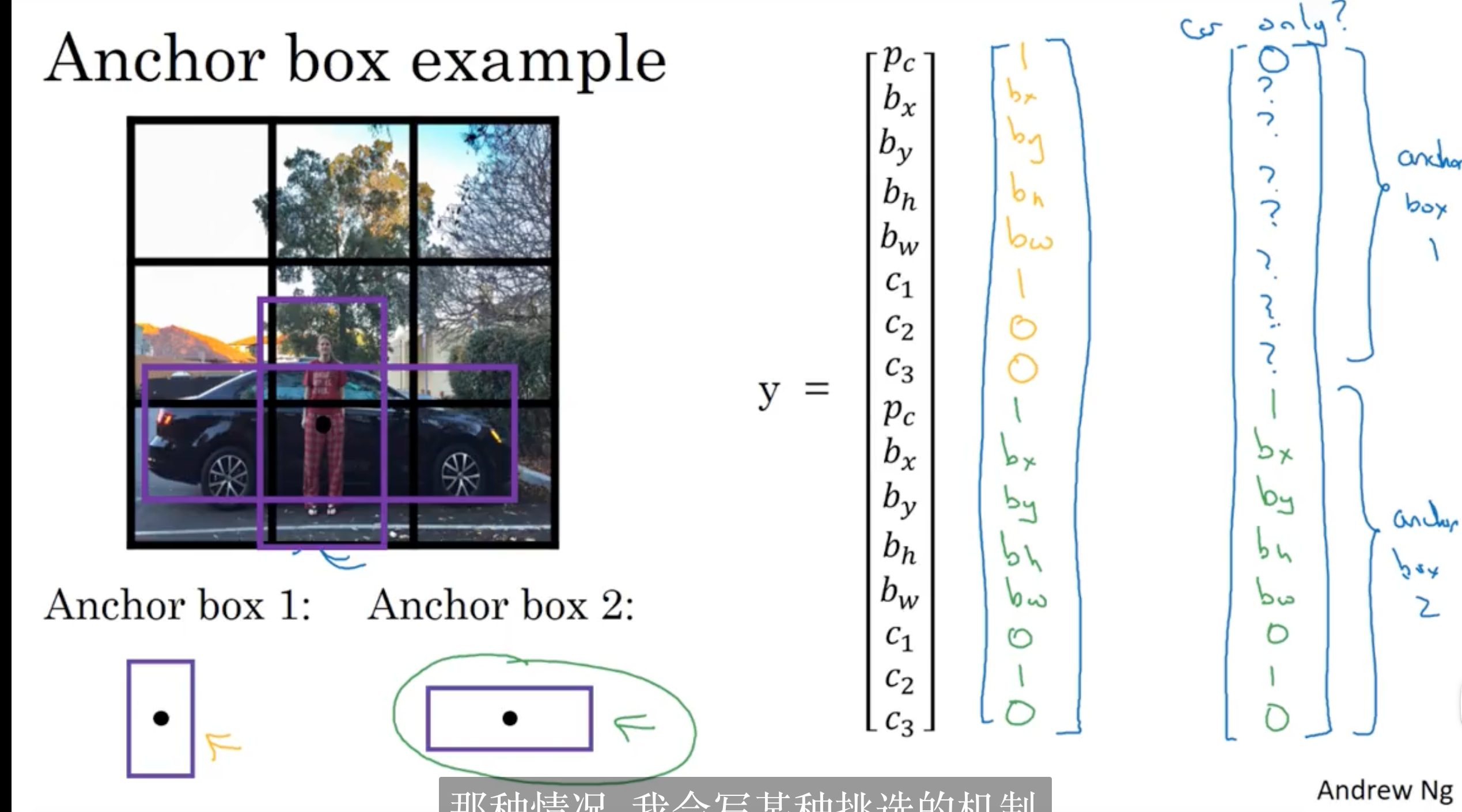
要求不同目标对应的框大小应该有差别
R-CNN
在 R-CNN 中,分隔思想是指先将图像分成多个候选区域(即候选目标),然后对每个候选区域进行分类和定位,以确定图像中的目标位置和类别。具体来说,R-CNN 首先通过一个选择性搜索算法或其他区域提取方法生成一些候选区域,然后对每个候选区域进行特征提取和分类,最后进行目标位置的精确定位。这种分隔思想的优点是可以有效地减少网络处理的区域数量,从而提高了检测速度和精度。
U-net图像分割
基于知乎专栏作者Kissrabbit的yolo入门讲解的笔记

Backbone network:从原图提取特征
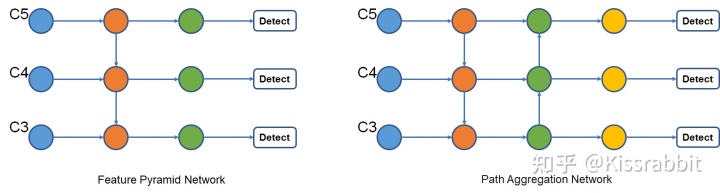
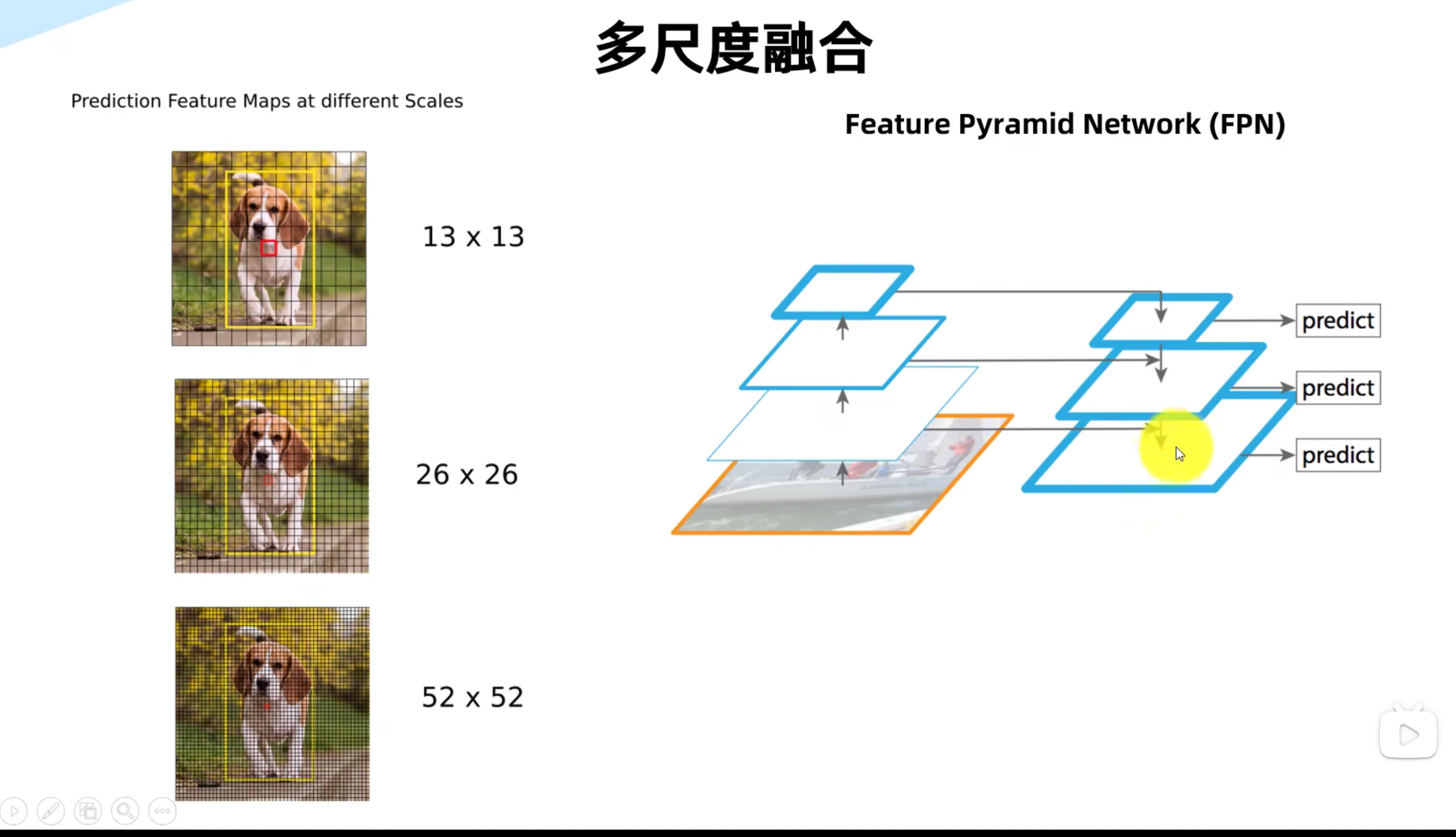
Neck network:对特征进行整合,FPN
Detection head:由得到的特征进行预测(解码器 decoder)
Backbone network-提取图像中有用的信息
站在前人的肩膀上,使用已经存在的网络
大型网络:
VGG网络
ResNet网络
ResNeXT网络
.ResNet+DCN网络
DarkNet网络
CSPResNet网络
轻量型网络
MobileNet
ShuffleNet
NECK-更好地利用网络所提取的特征信息
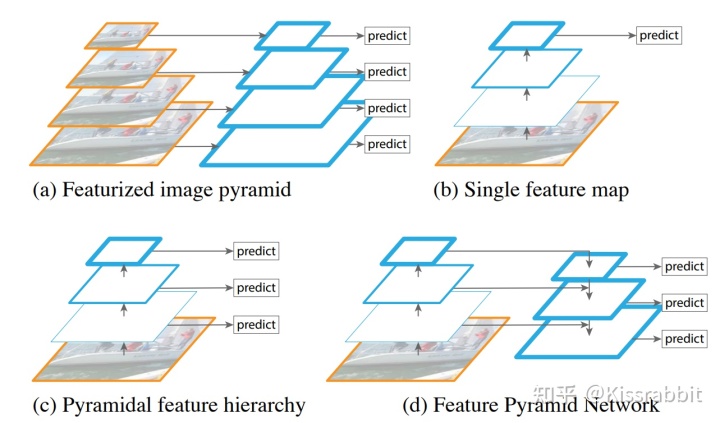
感受野
输出图的一个像素能代表原图的多少个像素
经过backbone后,会失去部分图像信息,高层特征图包含的语义信息较丰富,但空间分辨率较低,而低层特征图的空间分辨率较高,但语义信息较简单。
FPN
自底向上:在这个过程中,每一层的特征图都与它下一层的高分辨率特征图进行上采样和融合,得到更高级别和更具语义的特征图。这个过程可以一直重复,直到最高层的特征图被生成
自顶向下:FPN 在生成特征金字塔的同时,使用一个附加的网络来生成自顶向下的辅助特征图。这个辅助特征图通过反卷积操作从高层特征图开始,逐步上采样并与下一层特征图进行融合,生成一系列具有不同分辨率和语义信息的特征图。这些特征图与自底向上生成的特征金字塔进行融合,从而得到更加完整和多样化的特征图集合
SPP结构
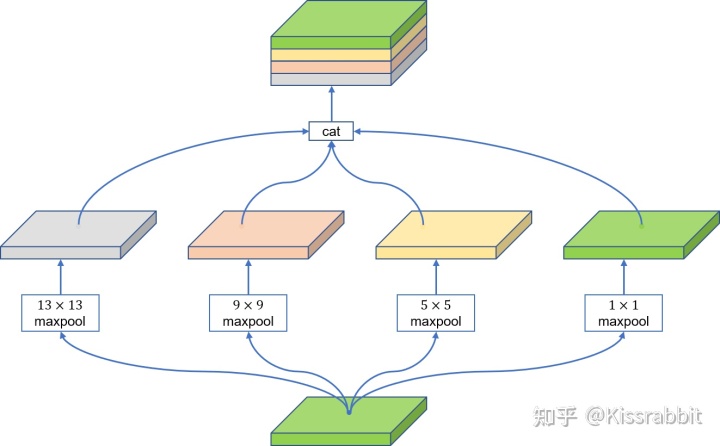
通过不同大小的maxpooling核来丰富特征图的感受野
以及:RFB, ASPP,SAM,PAN
Detection head

Class Subnet:预测目标类别
Box Subnet:预测目标框的位置
yolov1的浅析
仅使用一个卷积神经网络端到端地实现检测物体的目的
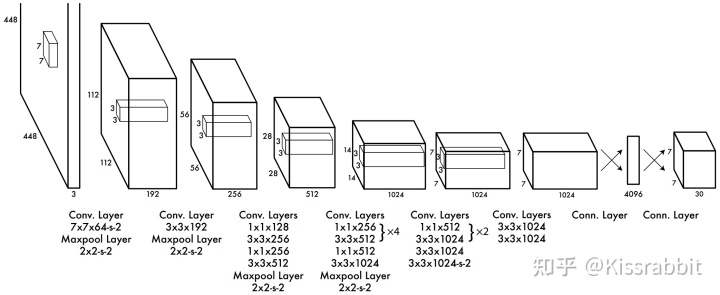
在那个年代,图像分类任务中,网络最后会将卷积输出的特征图拉平(flatten),得到一个一维向量,然后再接若干全连接层做预测——flatten方式会破坏特征的空间结构信息
原理
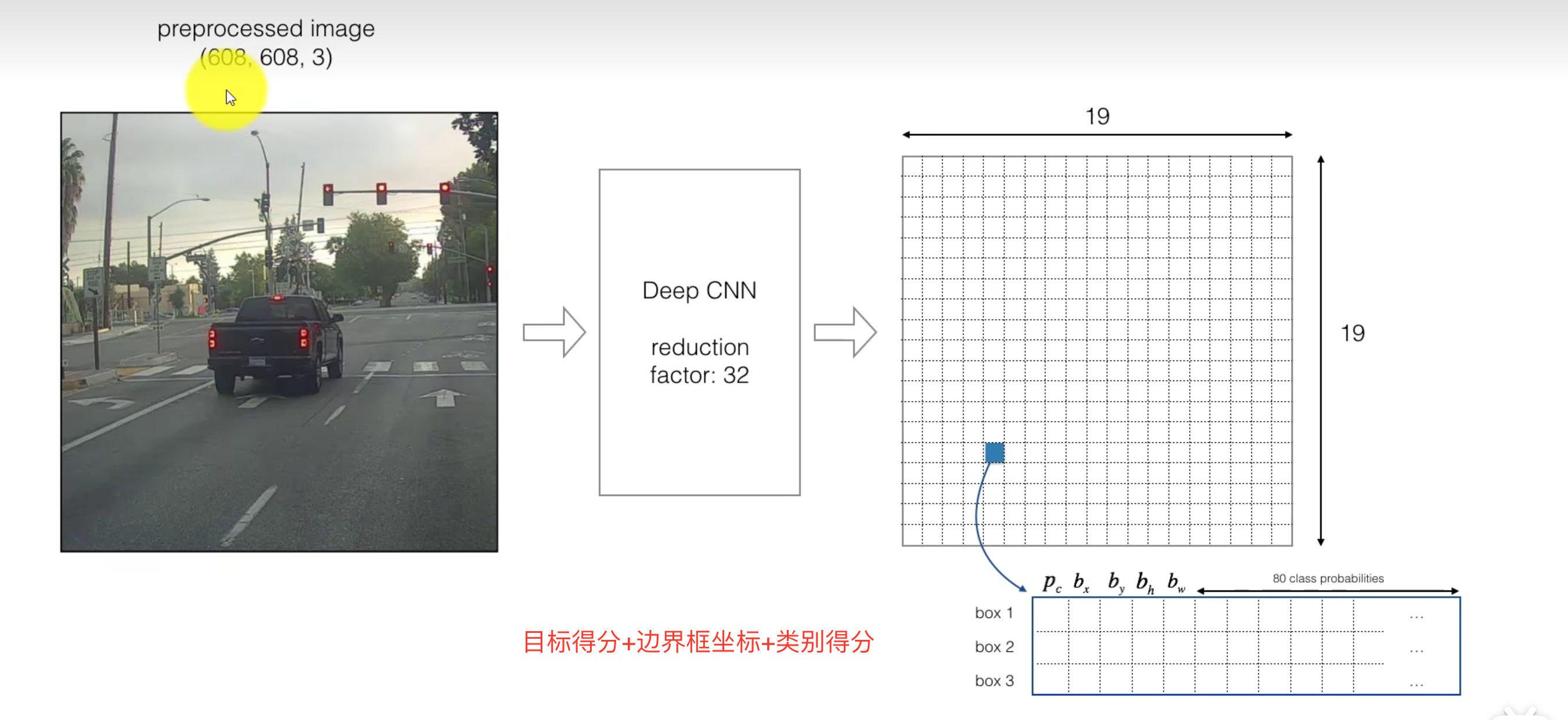
如上述最终得到的是7*7*30的特征图
特征图的每个位置 (grid_x,grid_y) 预测两个bounding box(预测框),而每个预测框包含五个输出参数:置信度CC ,矩形框参数(c_x,c_y,w,h) ,共10个参数,再加上20个类别,一共就是30了。置信度C的作用是判断此处是否有目标的中心点
上述参数数量可以用——5*B+C来表示,B是预测框的数量,C是类别的数量
逐网格找东西
每个网格都会给出预测参数量是5*B+C
因此,网络最后输出的预测参数数量是

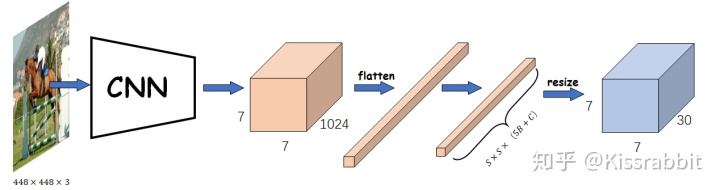
只有正样本候选区域中的预测框才有可能会被训练,也就是Pr(objectness)=1的地方,注意

训练
第1步:YOLOv1网络输出B个预测框;
第2步:计算这B个bbox与此处的真实bbox(也就是标签)之间的交并比(Intersection over Union,IoU),得到B个IoU值;
交并比(Intersection over Union,IoU)
第3步:选择IoU值最大的预测框作为正样本,分别去计算置信度损失、类别损失和边界框回归损失,其中置信度损失的标签就是该IoU值。
第4步:对于剩下的没被选中的B-1个预测框,它们都被标记为负样本,即只计算置信度损失,且置信度标签都为0,这是显然的。这些负样本不计算类别损失和边界框回归损失。同时,对于那些处在正样本候选区域之外的预测,都标记为该标签的负样本,也只计算置信度损失。

损失函数
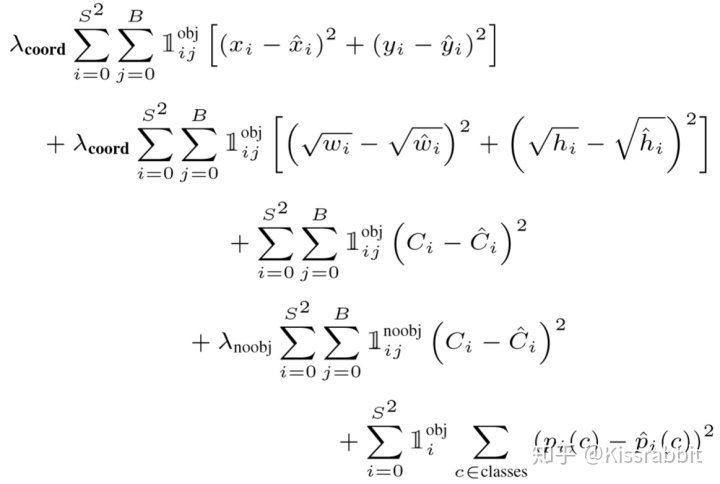
只有正样本才会计算bbox 的损失和class损失,负样本用于置信度损失中
测试

Objectness预测分支才是YOLO的灵魂!如果没有这个分支,那和SSD、RetinaNet也就没差别了
yolov1的改进
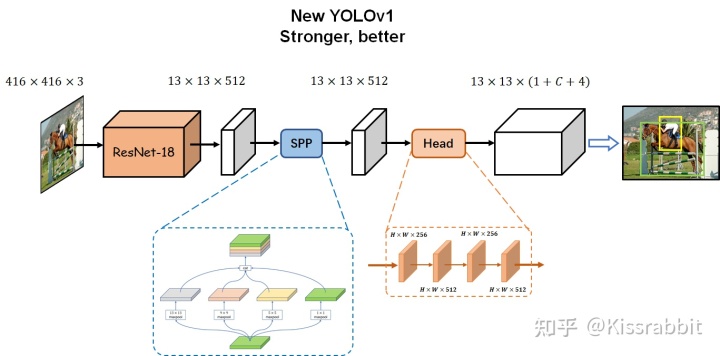
改进Backbone
使用ResNet-18神经网络

增加一个NECK
SPP结构
改进Detection head
抛掉flatten操作,而是在SPP输出的13x13x512的特征图上使用若干层卷积来处理
改进prediction层
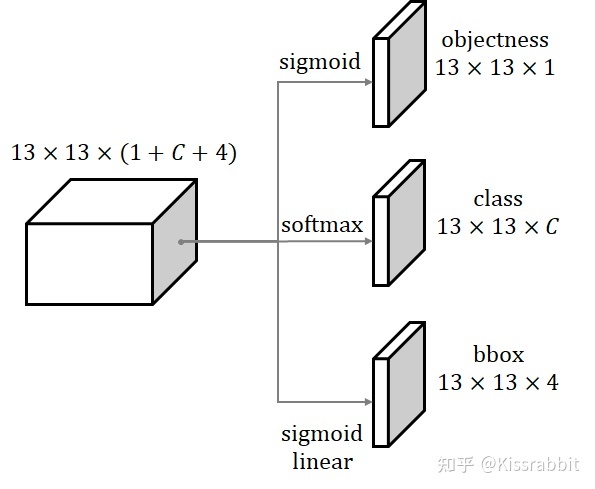
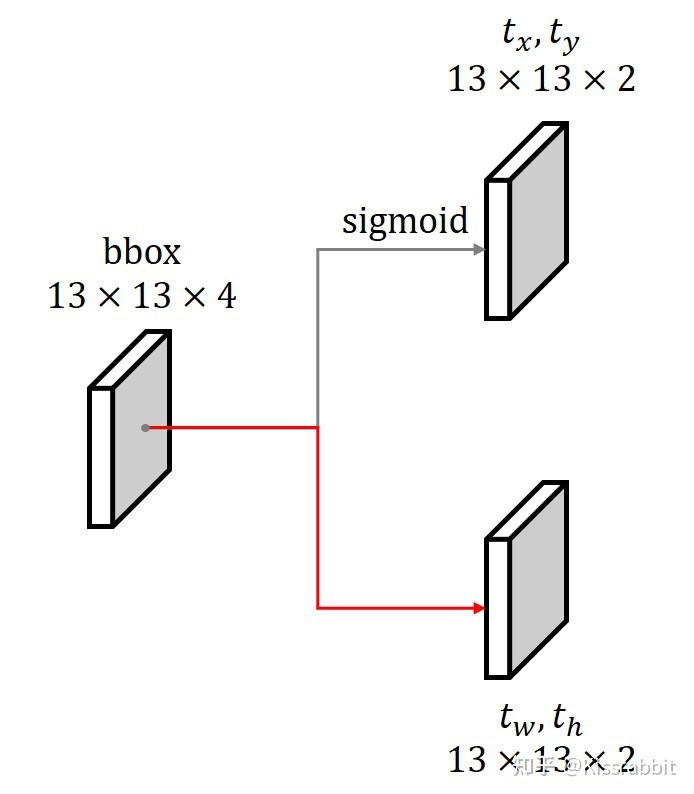
其中,tx=sigmoid(x),ty=sigmoid(y),tw=log(w),th=log(h)
损失函数

尝试搭建yolov1
浅析yolov2

Anchor-based
先验框的作用就是提供边界框的尺寸先验信息,让网络只需学习偏移量来调整先验框去获得最终的边界框,相较于YOLOv1的直接回归边界框的宽高,基于先验框的方法表现得往往更好
详细分析YOLOV4
将输入特征的通常拆成两份,一份交给诸Residual Block或者Dense Block去处理,另一部分直接skip connection就行
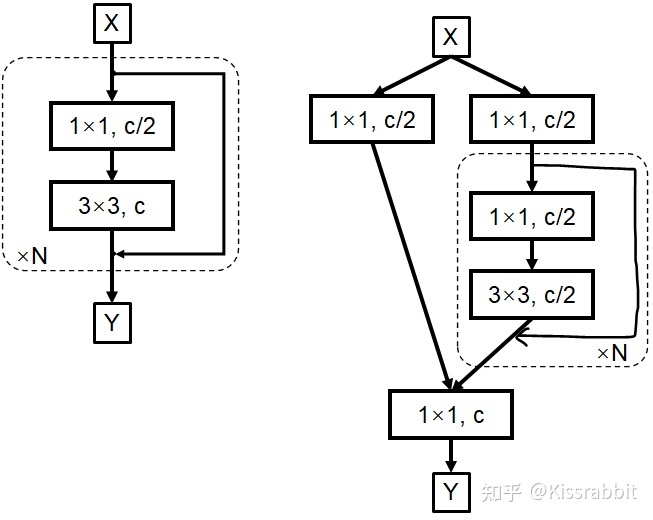
“分而治之”方法的内核不是FPN,而是多级检测。FPN不过是锦上添花,即使我们不做特征融合,依旧可以做多级检测,如SSD。只是,使用特征融合手段,可以让检测的效果更好罢了
yolo将特征图划分为s*s的小格子,每个格子负责对落入其中的目标进行检测,一次性预测所以各自包括目标的边界框,定位置信度以及所有类别概率向量。
网络结构可视化
python export.py --weights yolov5s.pt --include onnxyolov5s的基本结构
经典的one-stage结构,分为输入端、Backbone、Neck和Prediction四个部分

Backbone
是指深度卷积神经网络(CNN)中的一部分,它负责从输入图像中提取特征,通常采用预训练的卷积神经网络作为Backbone。预训练的卷积神经网络通常是在大规模图像分类数据集上进行训练的,如ImageNet,因此具有较强的特征提取能力。在one-stage算法中,Backbone一般会输出一系列的特征图,这些特征图具有不同的尺度和语义信息,可以帮助模型检测不同大小和类别的物体
Neck
是指Backbone和物体检测头(Detection Head)之间的中间层,它的作用是对Backbone输出的特征图进行特征融合和特征增强。Neck的设计可以增强模型对于不同尺度的物体的感知能力,提高模型的检测精度。常用的Neck结构包括FPN(Feature Pyramid Network)、PAN(Path Aggregation Network)等,它们的设计思想是在不同的特征图之间进行信息传递和融合,从而使得模型能够更好地处理不同大小的物体
CBL:网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深
Res unit 中将每一层的输入和输出进行相加,并通过激活函数处理后输出到下一层,从而保留了输入层的信息,同时使得梯度能够更好地传递
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小
每个ResX中包含1+2*X个卷积层
Concat:张量拼接,会扩充两个张量的维度,例如26*26*256和26*26*512两个张量拼接,结果是26*26*768。Concat和cfg文件中的route功能一样
BN:通过在每个mini-batch中标准化输入数据,使得每层的输入分布更加稳定,从而提高模型的训练效率和性
计算mini-batch中每个特征的均值和方差;
对每个特征进行中心化(减去均值)和缩放(除以方差);
使用学习到的标量参数(scale和shift)对标准化后的特征进行线性变换和平移。
add:张量相加,张量直接相加,不会扩充维度,例如104*104*128和104*104*128相加,结果还是104*104*128。add和cfg文件中的shortcut功能一样
Backbone中卷积层的数量:1+(1+2*1)+(1+2*2)+(1+2*8)+(1+2*8)+(1+2*4)+1

自适应锚框计算
通过聚类算法动态地计算出最优的一组锚框,以适应不同图像中物体的大小和形状
选择 K(通常为 9)个初始锚框大小(长宽比),将它们看作 K 个点在二维空间中,即 (w_i,h_i),其中 w_i 和 h_i 分别表示第 $i$ 个锚框的宽度和高度。
对于每个训练图像,通过遍历所有的真实边界框,计算每个真实边界框与 K 个锚框的 IoU(交并比),并将其与最接近的锚框进行匹配。然后,将匹配到的锚框的宽度和高度值与真实边界框的宽度和高度值进行对应,得到新的锚框大小。这里使用的是 K-means 算法。
对于所有训练图像,将所有新的锚框的大小进行平均,得到新的锚框大小作为最终的锚框大小。在测试过程中,使用这些锚框进行预测。
十三种数据增强
rectangular:
同个batch里做rectangle的等高等比变换
Mosaic数据增强
将四张随机选取的图像合并为一张新的图像,并将它们的标注框也合并为一个标注框
从训练集中随机选取四张图像,并将它们分别命名为 $A, B, C$ 和 $D$。
随机选择一个起始点,将四张图像拼接在一起,形成一张新的图像。具体来说,可以将 $A$ 放置在左上角,$B$ 放置在右上角,$C$ 放置在左下角,$D$ 放置在右下角,形成一张 $2H\times 2W$ 的图像。
将四张图像对应的标注框进行转换,并将它们合并为一个标注框。具体来说,对于每个标注框,首先计算它在新图像中的相对位置和大小,然后将它合并到一个新的标注框中。
对于新的图像和标注框进行数据增强。具体来说,可以对它们进行随机裁剪、缩放、平移、旋转等操
作,得到多个带有不同变换的训练样本。
mosaic_tg = []
for i in range(4):
img_i, target_i = img_lists[i], tg_lists[i]
target_i = np.array(target_i)
h0, w0, _ = img_i.shape#h0 和 w0 分别代表了 img_i 的高度和宽度
# 将图片resize固定的尺寸
scale_range = np.arange(50, 210, 10)
s = np.random.choice(scale_range) / 100. # 尺度缩放系数,随机将图片缩放0.5-2.0倍
if np.random.randint(2):#生成一个值为0或1的随机整数
# 保留长宽比
r = self.img_size / max(h0, w0)#根据最大边的大小来计算缩放比例
if r != 1:
img_i = cv2.resize(img_i, (int(w0 * r * s), int(h0 * r * s)))
else:
# 不保留长宽比
img_i = cv2.resize(img_i, (int(self.img_size * s), int(self.img_size * s)))
h, w, _ = img_i.shape
# 围绕确定好的马赛克中心点来拼接四张图片
if i == 0: # top left
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, self.img_size * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(self.img_size * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, self.img_size * 2), min(self.img_size * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
mosaic_img[y1a:y2a, x1a:x2a] = img_i[y1b:y2b, x1b:x2b]
padw = x1a - x1b
padh = y1a - y1b
# 调整标签信息
target_i_ = target_i.copy()
if len(target_i) > 0:
# a valid target, and modify it.
target_i_[:, 0] = (w * (target_i[:, 0]) + padw)
target_i_[:, 1] = (h * (target_i[:, 1]) + padh)
target_i_[:, 2] = (w * (target_i[:, 2]) + padw)
target_i_[:, 3] = (h * (target_i[:, 3]) + padh)
# check boxes
valid_tgt = []
# 我们把太小的边界框删除掉
for tgt in target_i_:
x1, y1, x2, y2, label = tgt
bw, bh = x2 - x1, y2 - y1
if bw > 5. and bh > 5.:
valid_tgt.append([x1, y1, x2, y2, label])
# 检查是否有标签
if len(valid_tgt) == 0:
valid_tgt.append([0., 0., 0., 0., 0.])
mosaic_tg.append(target_i_)
# check target
if len(mosaic_tg) == 0:
mosaic_tg = np.zeros([1, 5])
else:
mosaic_tg = np.concatenate(mosaic_tg, axis=0)
# Cutout/Clip targets
np.clip(mosaic_tg[:, :4], 0, 2 * self.img_size, out=mosaic_tg[:, :4])
# normalize
mosaic_tg[:, :4] /= (self.img_size * 2)