1 Pair RDD
键值对RDD是Spark中许多操作所需要的常见数据类型。spark为包含键值对类型的RDD提供了一些专有的操作,这些RDD被称为pair RDD。比如,pair RDD提供reduceByKey()方法,可以分别归约每个键对应的数据。
在spark中有很多种创建pair RDD的方式,比如很多存储键值对的数据格式会在读取时直接返回由其健值对数据组成的pair RDD。此外,当需要把一个普通的RDD转为pair RDD时,可以调用map()函数来实现,传递的函数需要返回键值对。
2 创建Pair RDD
在python中,为了让提取键之后的数据能够在函数中使用,需要返回一个由二元组组成的RDD。如下是用第一个单词作为键创建出一个pair RDD
pairs = lines.map(lambda x: (x.split()[0], x))
3 Pair RDD的转化操作
如下总结的是对pair RDD的一些转化操作:
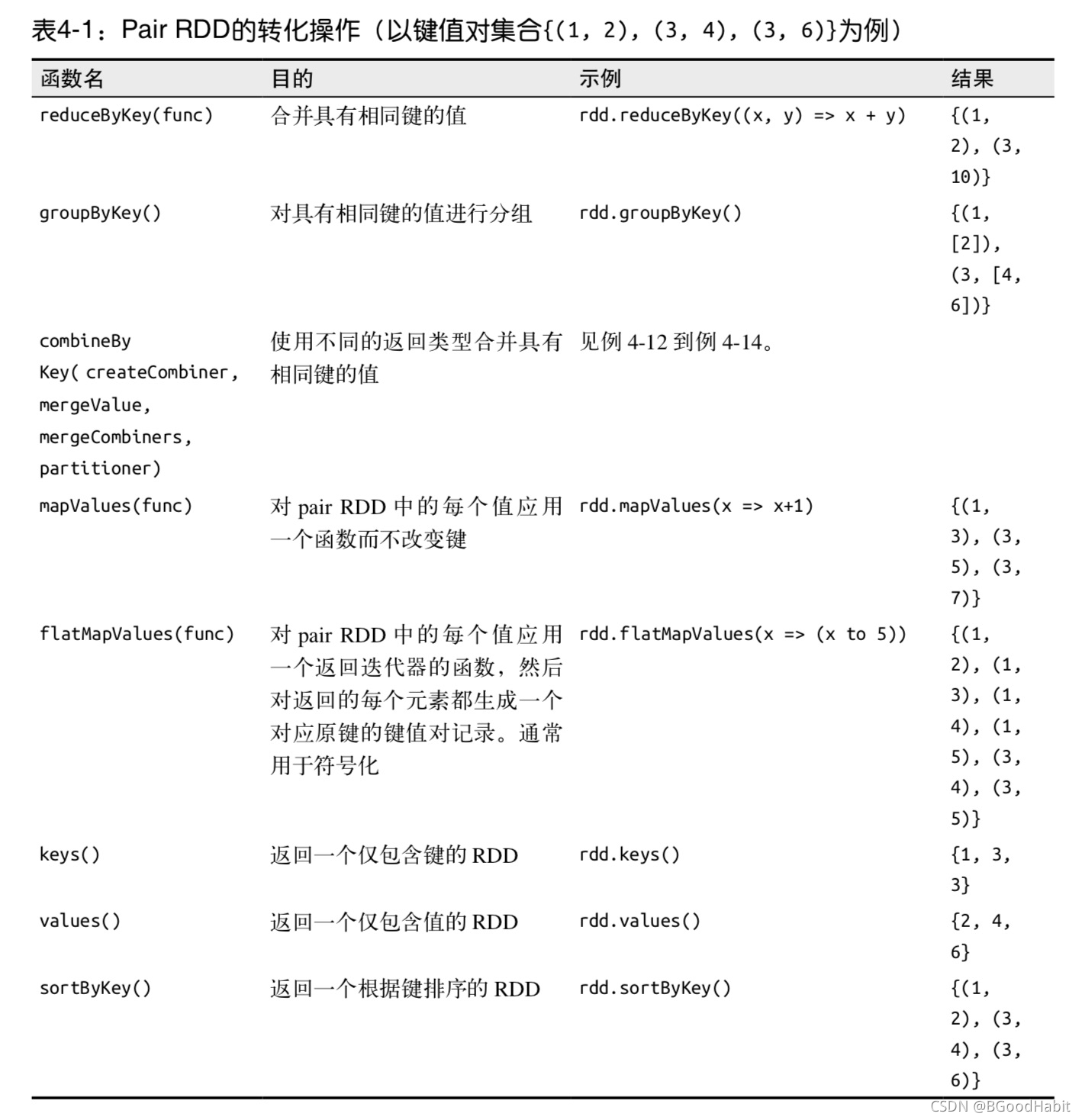
针对两个pair RDD的转化操作 (rdd={(1,2), (3,4), (3, 6)} other={(3,9)})


Pair RDD也还是RDD (元素为Python中的元组),因此同样支持RDD所支持的函数。例如,我们可以对pair RDD对长度超过20个字符的行进行筛选:
result = pairs.filter(lambda keyValue: len(keyValue[1] <20)
3.1 聚合操作
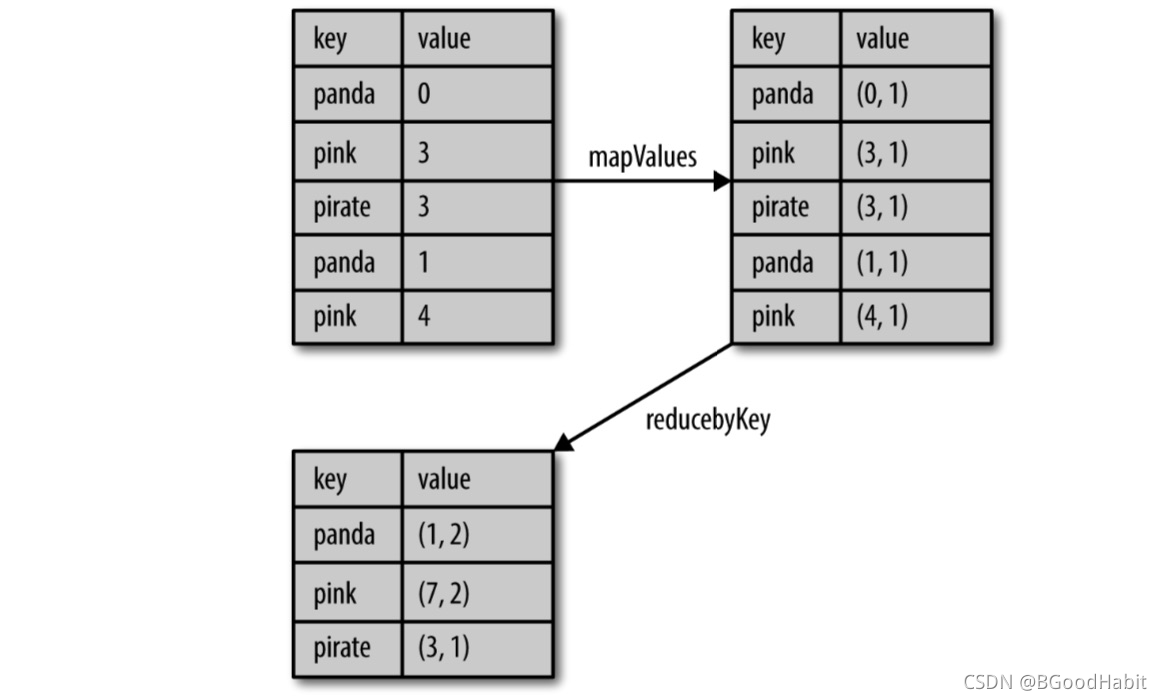
当数据集以键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。pair RDD则则有相应的针对键的转化操作。spark有一组类似的操作,可以组合具有相同键的值,这些操作返回RDD,因此它们是转化操作而不是行动操作。reduceByKey()会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。如下是在Python中使用reduceByKey()和mapValues()计算每个键对应的平均值:
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0]+y[0], x[1]+y[1]))
对应的结果如下图所示:
combineByKey()是最常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的,combineByKye()可以让用户返回与输入数据的类型不同的返回值。要理解combineByKey(),要先理解它在处理数据时是如何处理每个元素的。数据处理流程图如下:

并行度调优: 每个RDD都有固定的数目的分区,分区数决定了在RDD上执行操作时的并行度。 Spark提供了repartition()函数,它会把数据通过网络进行混洗,并创建出新的分区集合。但对数据进行重新分区是代价相对较大的操作,在python中我们可以通过rdd.getNumPartitions查看RDD的分区数。
3.2 数据分组
如果数据已经以预期的方式提取了键,groupByKey()就会使用RDD中的键来对数据进行分组。对于一个由类型K的键和类型V的值组成的RDD,所得到的结果RDD类型会是[K, Iterable[V]]。而groupBy()可以用于未成对的数据上,也可以根据除键相同以为的条件进行分组。
3.3 连接
连接方式多种多样:右外连接 ( rightOuterJoin(other) ),左外连接( leftOuterJoin(other) ),交叉连接以及内连接 (join),普通的join操作符表示内连接。在python中,如果一个值不存在,则使用None来表示。
3.4 数据排序
如果键有已定义的顺序,就可以对这种键值对RDD进行排序,当把数据排序后,后续对数据进行collect()或save()等操作都会得到有序的数据。我们可以用sortByKey()函数进行排序,如下是将整数转为字符串,然后使用字符串比较函数来对RDD进行排序:
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc=lambda x: str(x))
4 Pari RDD的行动操作
和转化操作一样,所有基础RDD支持的传统行动操作也都在pair RDD上可用。Pair RDD提供了一些额外的行动操作,可以让我们充分利用数据的键值对特性。如下所示:
