实训目的
- 从daily_stocks.csv
- 文件导入股票交易数据
- 对数据进行分组
- 计算股票的价格,包括平均最高最低价格,平均开盘收盘价格
- 将计算的数据导出
实训内容
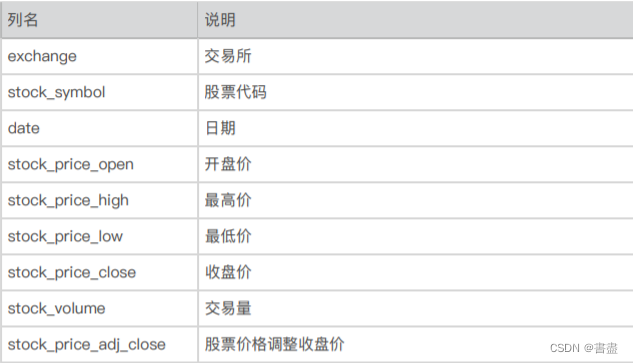
1. 认识数据
- 文件daily_stocks.csv文件中保存的是65020条股票交易数据,各列说明如下。
2. 环境准备
- 安装pig
教程推荐 https://blog.csdn.net/qq_42881421/article/details/84331794
- 启动hadoop环境
- 启动grunt shell。
pig
3. 数据上传
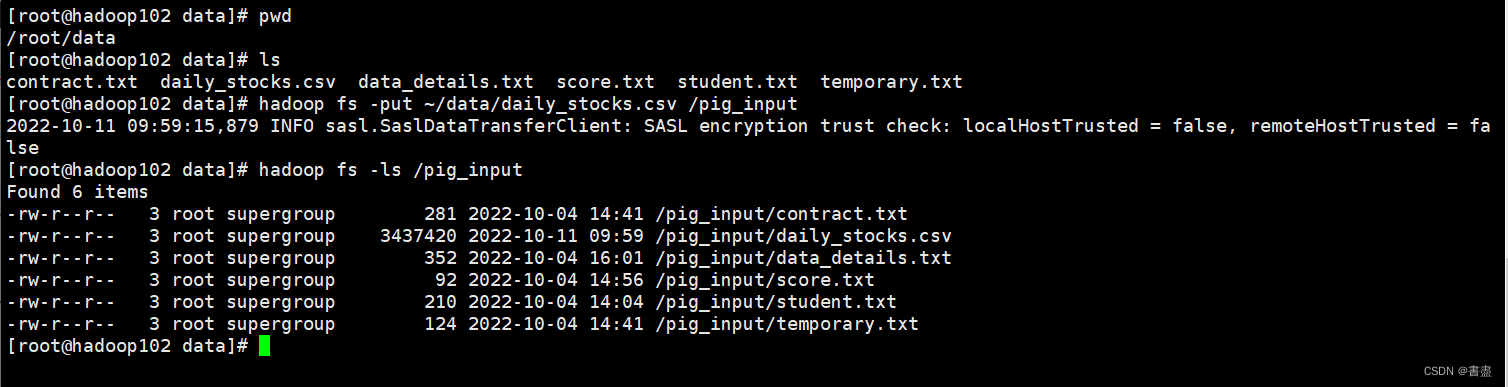
- 将数据文件daily_stocks.csv上传到HDFS的/pig_input目录下,并查看是否上传成功。
hadoop fs -put ~/data/daily_stocks.csv /pig_input
hadoop fs -ls /pig_input
4. 加载数据
- 将daily_stocks.csv中的数据加载到名为stock的关系中,
- 在grunt shell中输入如下命令:
#注意自己设置的端口
stock = LOAD 'hdfs://hadoop102:8020/pig_input/daily_stocks.csv' USING PigStorage(',') as (exchange:chararray,symbol:chararray,date:chararray,stock_price_open:double,stock_price_high:double,stock_price_low:double,stock_price_close:double,stock_volume:double,stock_price_adj_close:double);

- 并查看数据的前十行:

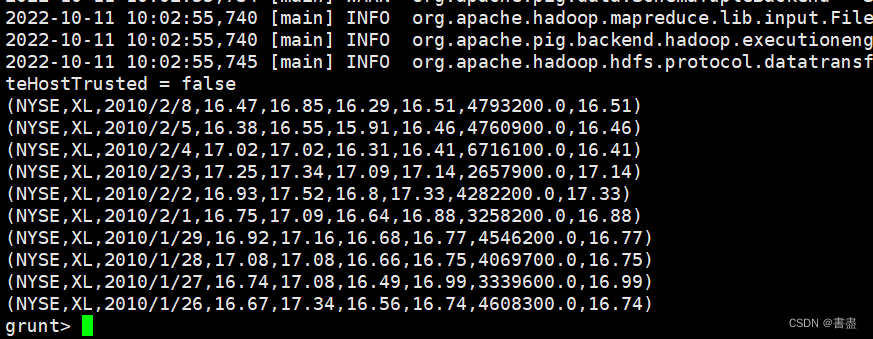
5. 数据分组
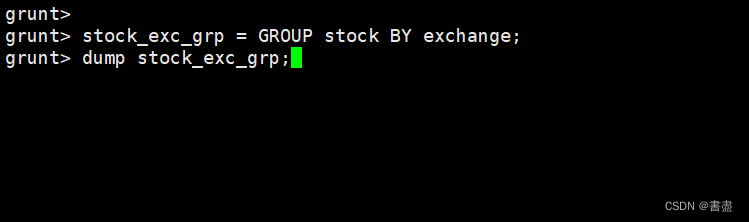
- 按交易所(exchange)进行分组,将结果保存到名为stock_exc_grp的关系中并检查分组结果:
stock_exc_grp = GROUP stock BY exchange;
dump stock_exc_grp;

6. 统计交易所数量
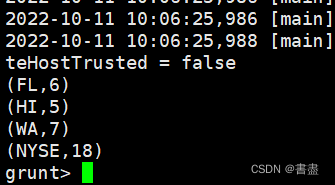
- 根据分组后的数据,统计出每只股票有几家交易所可进行交易:
unique_symbols = FOREACH stock_exc_grp {symbols = stock.symbol;unique_symbol = DISTINCT symbols;GENERATE group, COUNT(unique_symbol);};
- 显示结果
dump unique_symbols;
7. 统计平均开盘收盘价
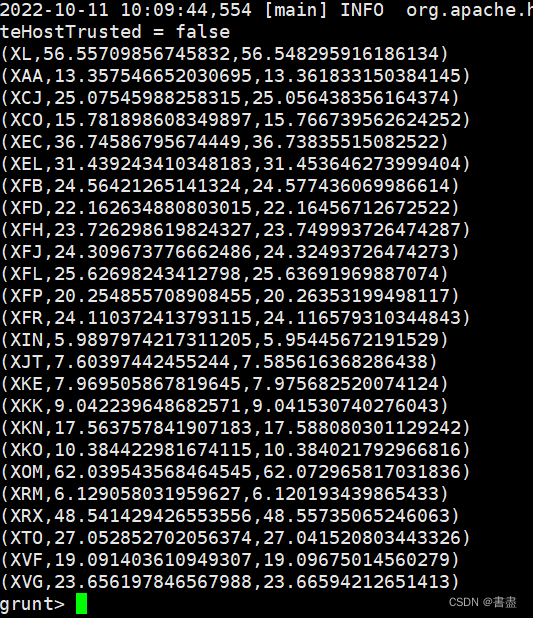
- 将stock关系按照股票代码(symbol)进行分组,并统计每只股票的平均开盘与收盘价格:
stock_symbol_grp = GROUP stock BY symbol;
avg_stock_price_opens_closes = FOREACH stock_symbol_grp {stock_price_open = stock.stock_price_open;stock_price_close = stock.stock_price_close;GENERATE group, AVG(stock_price_open),AVG(stock_price_close); };
dump avg_stock_price_opens_closes;

8. 统计平均最高最低价
- 统计每只股票的平均最高和最低价格
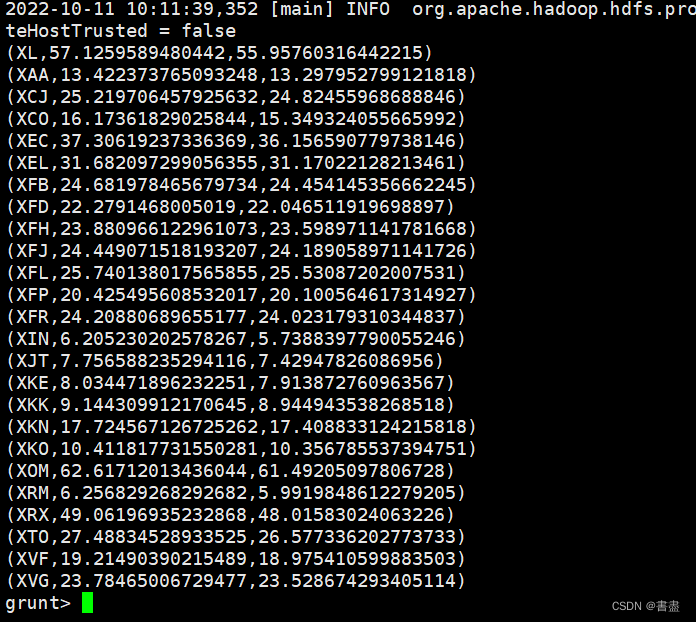
avg_stock_price_high_low = FOREACH stock_symbol_grp {stock_price_high = stock.stock_price_high;stock_price_low = stock.stock_price_low;GENERATE group, AVG(stock_price_high),AVG(stock_price_low);};
dump avg_stock_price_high_low;

扫描二维码关注公众号,回复:
14951720 查看本文章

9. 导出数据
- 将avg_stock_price_high_low, avg_stock_price_opens_closes 和 unique_symbols导出HDFS
文件系统中
store unique_symbols into 'unique_symbols' using PigStorage(',');
store avg_stock_price_opens_closes into 'avg_stock_price_opens_colses' using PigStorage(',');
store avg_stock_price_high_low into 'avg_stock_price_high_low' using PigStorage(',');
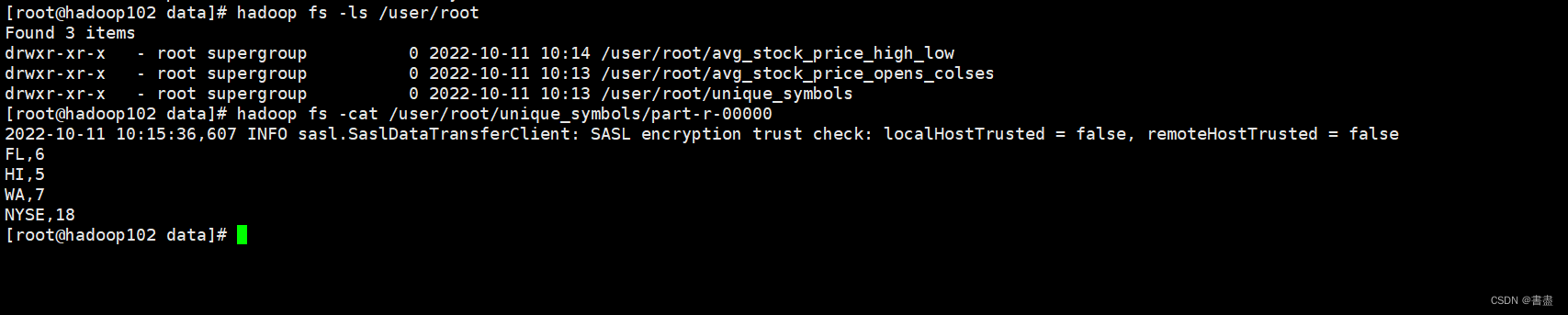
- 查看导出的数据
hadoop fs -ls /user/root
hadoop fs -cat /user/root/unique_symbols/part-r-00000
实训总结
- Pig包括两部分:用于描述数据流的语言,称为Pig Latin;和用于运行Pig Latin程序的执行环境。
- Pig不适合所有的数据处理任务,和MapReduce一样,它是为数据批处理而设计的。如果只想查询大数据集中的一小部分数据,pig的实现不会很好,因为它要扫描整个数据集或绝大部分。
- Pig Latin 程序有一系列语句构成。操作和命令是大小写无关的,而别名和函数名是大小写敏感的。
- Pig处理多行语句时,在整个程序逻辑计划没有构造完毕前,pig并不处理数据。