python3下使用scrapy实现模拟用户登录与cookie存储—— 中级篇(百度云俱乐部)
1. 背景
- 相关基础知识点回顾:
- python3下使用requests模拟用户登录 —— 中级篇(百度云俱乐部):https://blog.csdn.net/zwq912318834/article/details/79665863
- python3下使用scrapy实现模拟用户登录与cookie存储 —— 基础篇(马蜂窝): https://blog.csdn.net/zwq912318834/article/details/79614372
2. 环境
- 系统:win7
- python 3.6.1
- scrapy 1.4.0
- requests 2.14.2 (通过pip list查看)
3. 模拟登录百度云俱乐部
- 关于百度云俱乐部登录的分析过程,可以参考文章:https://blog.csdn.net/zwq912318834/article/details/79665863
3.1. 了解requests库和scrapy框架的区别
- scrapy爬虫和requests爬虫有个很大的区别,就是scrapy是一个异步爬虫框架,特点主要体现在两个方面:
- 第一:异步性。从scrapy框架中发出的request请求之间是没有顺序的,不存在先yield,就一定先请求的。
- 第二:框架性。所有的动作,框架都已经帮忙集成了。比如说到这个cookie,一旦设置好 “COOKIES_ENABLED”: True ,那么所有的Request请求就在同一个cookie下,不需要像使用requests库中的session来保持会话。
- 从以上的信息来看,百度云俱乐部的登录过程唯一要注意好的就是控制好请求信息的顺序性。因为登录参数的获取是有顺序的。像验证码和登录参数之间的联系这些问题,scrapy框架已经完全支持好了。
- 在pyCharm中,启动debug模式,可以看到response对象的全部信息,找到对应的cookie信息。
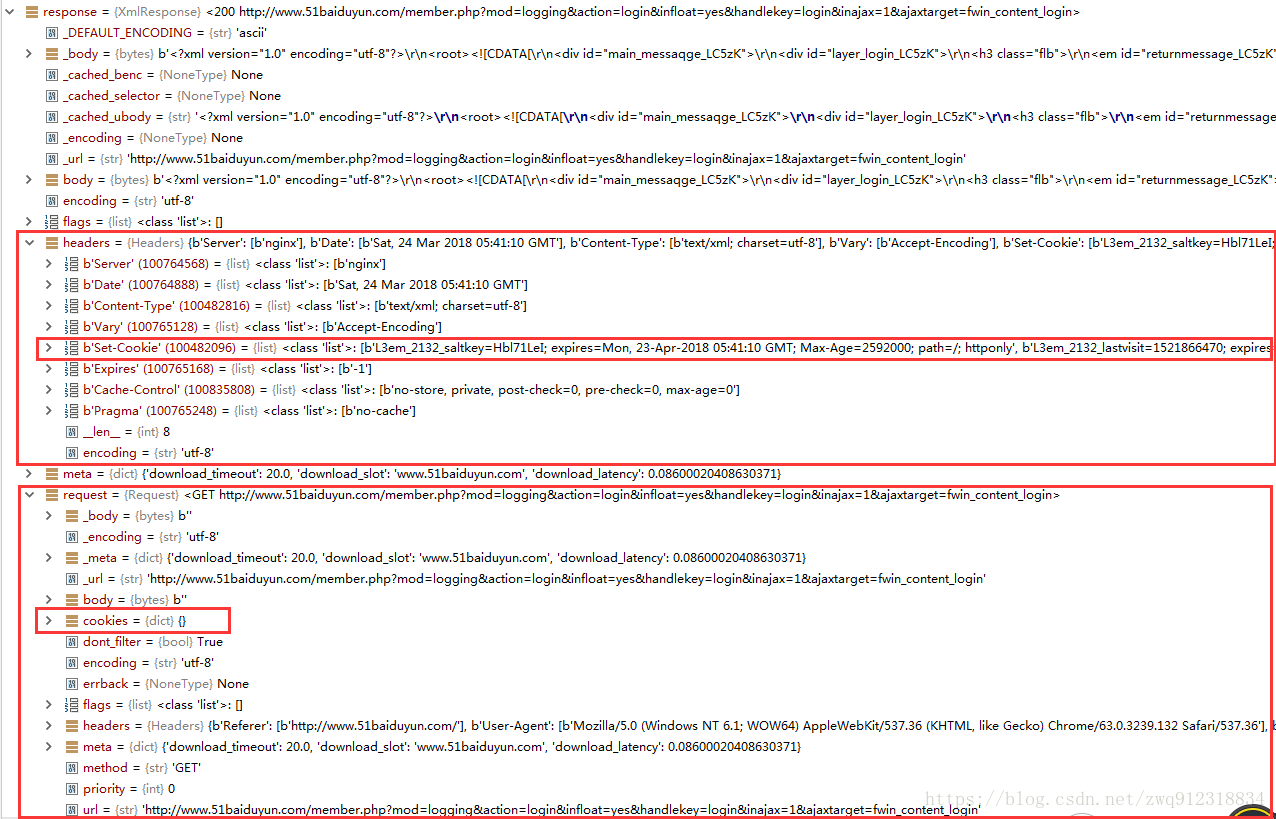
3.2. 代码详细解析
# 文件baiduyunSpider.py
# -*- coding: utf-8 -*-
import scrapy
import datetime
import re
import random
from PIL import Image
# 将cookie保存到文本文件中
def convertResponseCookieFormat(cookieLstInfo, cookieFileName):
'''
Set-Cookie = [b'L3em_2132_saltkey=nMjUM797; expires=Mon, 23-Apr-2018 05:48:42 GMT; Max-Age=2592000; path=/; httponly', b'L3em_2132_lastvisit=1521866922; expires=Mon, 23-Apr-2018 05:48:42 GMT; Max-Age=2592000; path=/', b'L3em_2132_sid=g8DFgE; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/', b'L3em_2132_lastact=1521870522%09member.php%09logging; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/', b'L3em_2132_sid=g8DFgE; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/']
item = b'L3em_2132_saltkey=nMjUM797; expires=Mon, 23-Apr-2018 05:48:42 GMT; Max-Age=2592000; path=/; httponly'
item = b'L3em_2132_lastvisit=1521866922; expires=Mon, 23-Apr-2018 05:48:42 GMT; Max-Age=2592000; path=/'
item = b'L3em_2132_sid=g8DFgE; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/'
item = b'L3em_2132_lastact=1521870522%09member.php%09logging; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/'
item = b'L3em_2132_sid=g8DFgE; expires=Sun, 25-Mar-2018 05:48:42 GMT; Max-Age=86400; path=/'
:param cookieLstInfo:
:return:
'''
cookieLst = []
if len(cookieLstInfo) > 0:
for cookieItem in cookieLstInfo:
cookieItemStr = str(cookieItem, encoding="utf8")
cookieLst.append(cookieItemStr)
# 将cookie写入到文件中,方便后面使用
with open(cookieFileName, 'w') as f:
for cookieValue in cookieLst:
f.write(str(cookieValue) + '\n')
return cookieLst
class baiduyunSpider(scrapy.Spider):
# 定制化设置
custom_settings = {
'LOG_LEVEL': 'DEBUG', # Log等级,默认是最低级别debug
'ROBOTSTXT_OBEY': False, # default Obey robots.txt rules
'DOWNLOAD_DELAY': 2, # 下载延时,默认是0
'COOKIES_ENABLED': True, # 默认enable,爬取登录后的数据时需要启用
# 'COOKIES_DEBUG': True, # 默认值为False,如果启用,Scrapy将记录所有在request(Cookie 请求头)发送的cookies及response接收到的cookies(Set-Cookie 接收头)。
'DOWNLOAD_TIMEOUT': 20, # 下载超时,既可以是爬虫全局统一控制,也可以在具体请求中填入到Request.meta中,Request.meta['download_timeout']
}
name = 'baiduyun'
allowed_domains = ['51baiduyun.com']
host = "http://www.51baiduyun.com/"
account = "13725168940" # 百度云俱乐部帐号
password = "aaa00000000" # 密码
userAgent = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
headerData = {
"Referer": "http://www.51baiduyun.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36",
}
# 爬虫运行的起始位置
def start_requests(self):
print("start baiduyun clawer")
# 马蜂窝登录页面
baiduyunLoginArgsPage = "http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login"
loginArgsIndexReq = scrapy.Request(
url = baiduyunLoginArgsPage,
headers = self.headerData,
callback = self.parseLoginArgsPage,
dont_filter = True, # 防止页面因为重复爬取,被过滤了
)
yield loginArgsIndexReq
# 从网页源码和cookie中拿到登录所需的参数:formdata, referer, seccodehash
def parseLoginArgsPage(self, response):
# 首先第一步,从网页源码中获得 formhash, referer, seccodehash
print(f"parseLoginArgsPage: statusCode = {response.status}, url = {response.url}")
'''
<div class="c cl">
<input type="hidden" name="formhash" value="7736cc00" />
<input type="hidden" name="referer" value="http://www.51baiduyun.com/" />
'''
# formhashRe = re.search('name="formhash" value="(.*?)"', response.text, re.DOTALL)
formhashRe = re.search('name="formhash" value="(\w+?)"', response.text, re.DOTALL)
refererRe = re.search('name="referer" value="(.*?)"', response.text, re.DOTALL)
print(f"formhashRe = {formhashRe}, refererRe = {refererRe}")
if formhashRe:
formhash = formhashRe.group(1)
else:
formhash = ""
if refererRe:
referer = refererRe.group(1)
else:
referer = ""
# 获取请求request中的Cookie,也就是携带给网站的cookie信息
# Cookie = response.request.headers.getlist('Cookie')
# print(f'CookieReq = {Cookie}')
# 获取服务器返回过来的Cookie,也就是网站携带给用户的cookie信息
Cookie = response.headers.getlist('Set-Cookie')
print(f"Set-Cookie = {Cookie}")
cookieFileName = "baiduyunCookies.txt"
'''
cookieInfoLst = ['L3em_2132_saltkey=w0QHA0q5; expires=Mon, 23-Apr-2018 05:59:00 GMT; Max-Age=2592000; path=/; httponly', 'L3em_2132_lastvisit=1521867540; expires=Mon, 23-Apr-2018 05:59:00 GMT; Max-Age=2592000; path=/', 'L3em_2132_sid=mALP7a; expires=Sun, 25-Mar-2018 05:59:00 GMT; Max-Age=86400; path=/', 'L3em_2132_lastact=1521871140%09member.php%09logging; expires=Sun, 25-Mar-2018 05:59:00 GMT; Max-Age=86400; path=/', 'L3em_2132_sid=mALP7a; expires=Sun, 25-Mar-2018 05:59:00 GMT; Max-Age=86400; path=/']
'''
cookieInfoLst = convertResponseCookieFormat(Cookie, cookieFileName)
print(f"cookieInfoLst = {cookieInfoLst}")
sid = ""
for cookieItem in cookieInfoLst:
if cookieItem.find("_sid=") != -1:
sidRe = re.search('_sid=(\w+?);', cookieItem)
if sidRe:
sid = sidRe.group(1)
print(f"sid = {sid}")
seccodehash = 'cSA' + sid
postData = {
"formhash": formhash,
"referer": referer,
"seccodehash": seccodehash,
}
# 接下来需要请求验证码图片,这是请求图片的第一步:获取到update参数:
# 将暂时拿到的postData放到meta信息中,传递下去
# 第一步:发送第一个请求,获取“update” 的参数值
randomFloat = random.uniform(0, 1)
url = f"http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash={seccodehash}&{randomFloat}&modid=undefined"
yield scrapy.Request(
url = url,
headers = self.headerData,
meta = {"postData": postData},
callback = self.parseUpdateForCaptcha,
dont_filter = True, # 防止页面因为重复爬取,被过滤了
)
# 获取请求验证码所需的参数:update
def parseUpdateForCaptcha(self, response):
# 请求验证码的前奏,先拿到update参数的值
print(f"parseUpdateForCaptcha: statusCode = {response.status}, url = {response.url}")
postData = response.meta.get("postData", {})
updateRe = re.search('update=(\d+?)&', response.text, re.DOTALL)
print(f"updateRe = {updateRe}")
if updateRe:
update = int(updateRe.group(1))
else:
update = 0
print(f"update = {update}")
# 拿到update参数之后,接下来根据这些信息,请求验证码图片
# http://www.51baiduyun.com/misc.php?mod=seccode&update=88800&idhash=cSAY3fpK6
seccodehash = postData['seccodehash']
captchaUrl = f"http://www.51baiduyun.com/misc.php?mod=seccode&update={update}&idhash={seccodehash}"
yield scrapy.Request(
url = captchaUrl,
headers = self.headerData,
meta = {"postData": postData}, # 继续传递下去
callback = self.parseCaptcha,
dont_filter = True, # 防止页面因为重复爬取,被过滤了
)
# 获取验证码
def parseCaptcha(self, response):
# 解析出验证码图片
print(f"parseCaptcha: statusCode = {response.status}, url = {response.url}")
postData = response.meta.get("postData", {})
# print(f"t = {response.text}") # 打印结果可以看出是一张图片
with open("captcha51baiduyun.jpg", "wb") as f:
# 这个地方一定注意,是body,而不是text
f.write(response.body)
f.close()
# 在这里,为了让逻辑简单,暂时采用手动输入验证码的方式。
# 如果想让程序自动打码,可以参考文章:https://blog.csdn.net/zwq912318834/article/details/78616462
try:
imObj = Image.open('captcha51baiduyun.jpg')
imObj.show()
imObj.close()
except:
pass
captcha = input("输入验证码\n>").strip()
print(f"input captcha is : {captcha}")
# 最后带着这些参数信息,进行登录操作
# 百度云模仿 登录
print("开始模拟登录百度云俱乐部")
postUrl = "http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1"
'''
formhash:eb6fc0ed
referer:http://www.51baiduyun.com/
loginfield:username
username:aaaaaa
password:abc123456
questionid:0
answer:
seccodehash:cSAY3fpK6
seccodemodid:member::logging
seccodeverify:ejwe
'''
postData["loginfield"] = 'username'
postData["username"] = self.account
postData["password"] = self.password
postData["questionid"] = '0'
postData["answer"] = ''
postData["seccodemodid"] = 'member::logging'
postData["seccodeverify"] = captcha
yield scrapy.FormRequest(
url = postUrl,
method = "POST",
formdata = postData,
callback = self.parseLoginResPage,
dont_filter = True, # 防止页面因为重复爬取,被过滤了
)
# 检查登录结果
def parseLoginResPage(self, response):
# 查看登录结果
print(f"parseLoginResPage: statusCode = {response.status}, url = {response.url}")
print(f"text = {response.text}")
# 正常的分析页面请求
def parse(self, response):
print(f"parse: url = {response.url}, meta = {response.meta}")
# 请求错误处理:可以打印,写文件,或者写到数据库中
def errorHandle(self, failure):
print(f"request error: {failure.value.response}")
# 爬虫运行完毕时的收尾工作,例如:可以打印信息,可以发送邮件
def closed(self, reason):
# 爬取结束的时候可以发送邮件
finishTime = datetime.datetime.now()
subject = f"clawerName had finished, reason = {reason}, finishedTime = {finishTime}"
print(f"subject = {subject}")
3.3. 执行结果
- 登录成功
start baiduyun clawer
2018-03-24 14:25:18 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login> (referer: http://www.51baiduyun.com/)
parseLoginArgsPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login
formhashRe = <_sre.SRE_Match object; span=(650, 682), match='name="formhash" value="74e7159e"'>, refererRe = <_sre.SRE_Match object; span=(708, 757), match='name="referer" value="http://www.51baiduyun.com/">
Set-Cookie = [b'L3em_2132_saltkey=eFHQH69h; expires=Mon, 23-Apr-2018 06:29:56 GMT; Max-Age=2592000; path=/; httponly', b'L3em_2132_lastvisit=1521869396; expires=Mon, 23-Apr-2018 06:29:56 GMT; Max-Age=2592000; path=/', b'L3em_2132_sid=Q37hU7; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/', b'L3em_2132_lastact=1521872996%09member.php%09logging; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/', b'L3em_2132_sid=Q37hU7; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/']
cookieInfoLst = ['L3em_2132_saltkey=eFHQH69h; expires=Mon, 23-Apr-2018 06:29:56 GMT; Max-Age=2592000; path=/; httponly', 'L3em_2132_lastvisit=1521869396; expires=Mon, 23-Apr-2018 06:29:56 GMT; Max-Age=2592000; path=/', 'L3em_2132_sid=Q37hU7; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/', 'L3em_2132_lastact=1521872996%09member.php%09logging; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/', 'L3em_2132_sid=Q37hU7; expires=Sun, 25-Mar-2018 06:29:56 GMT; Max-Age=86400; path=/']
sid = Q37hU7
2018-03-24 14:25:20 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSAQ37hU7&0.47346051143907475&modid=undefined> (referer: http://www.51baiduyun.com/)
parseUpdateForCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSAQ37hU7&0.47346051143907475&modid=undefined
updateRe = <_sre.SRE_Match object; span=(1079, 1092), match='update=26184&'>
update = 26184
2018-03-24 14:25:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&update=26184&idhash=cSAQ37hU7> (referer: http://www.51baiduyun.com/)
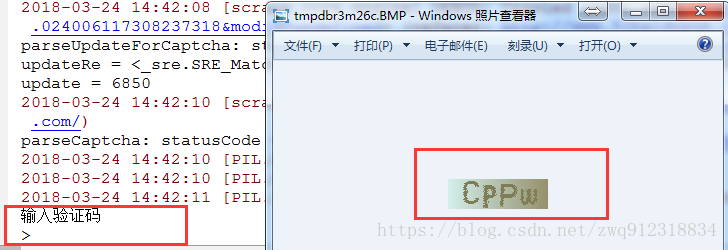
parseCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&update=26184&idhash=cSAQ37hU7
2018-03-24 14:25:23 [PIL.PngImagePlugin] DEBUG: STREAM b'IHDR' 16 13
2018-03-24 14:25:23 [PIL.PngImagePlugin] DEBUG: STREAM b'IDAT' 41 2518
输入验证码
>2018-03-24 14:25:24 [PIL.Image] DEBUG: Error closing: 'NoneType' object has no attribute 'close'
6Y4Q
input captcha is : 6Y4Q
开始模拟登录百度云俱乐部
2018-03-24 14:25:37 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1> (referer: http://www.51baiduyun.com/misc.php?mod=seccode&update=26184&idhash=cSAQ37hU7)
parseLoginResPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1
text = <?xml version="1.0" encoding="utf-8"?>
<root><![CDATA[<script type="text/javascript" reload="1">if(typeof succeedhandle_login=='function') {succeedhandle_login('http://www.51baiduyun.com/', '欢迎您回来,见习会员 13725168940,现在将转入登录前页面', {'username':'13725168940','usergroup':'见习会员','uid':'1315026','groupid':'23','syn':'0'});}hideWindow('login');showDialog('欢迎您回来,见习会员 13725168940,现在将转入登录前页面', 'right', null, function () { window.location.href ='http://www.51baiduyun.com/'; }, 0, null, null, null, null, null, 3);</script>]]></root>
subject = clawerName had finished, reason = finished, finishedTime = 2018-03-24 14:25:37.954602- 登录失败:验证码错误
start baiduyun clawer
2018-03-24 14:38:57 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login> (referer: http://www.51baiduyun.com/)
parseLoginArgsPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login
formhashRe = <_sre.SRE_Match object; span=(650, 682), match='name="formhash" value="177921b6"'>, refererRe = <_sre.SRE_Match object; span=(708, 757), match='name="referer" value="http://www.51baiduyun.com/">
Set-Cookie = [b'L3em_2132_saltkey=Tb0DPHLs; expires=Mon, 23-Apr-2018 06:43:35 GMT; Max-Age=2592000; path=/; httponly', b'L3em_2132_lastvisit=1521870215; expires=Mon, 23-Apr-2018 06:43:35 GMT; Max-Age=2592000; path=/', b'L3em_2132_sid=pwg1uj; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/', b'L3em_2132_lastact=1521873815%09member.php%09logging; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/', b'L3em_2132_sid=pwg1uj; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/']
cookieInfoLst = ['L3em_2132_saltkey=Tb0DPHLs; expires=Mon, 23-Apr-2018 06:43:35 GMT; Max-Age=2592000; path=/; httponly', 'L3em_2132_lastvisit=1521870215; expires=Mon, 23-Apr-2018 06:43:35 GMT; Max-Age=2592000; path=/', 'L3em_2132_sid=pwg1uj; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/', 'L3em_2132_lastact=1521873815%09member.php%09logging; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/', 'L3em_2132_sid=pwg1uj; expires=Sun, 25-Mar-2018 06:43:35 GMT; Max-Age=86400; path=/']
sid = pwg1uj
2018-03-24 14:38:59 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSApwg1uj&0.8624172924051665&modid=undefined> (referer: http://www.51baiduyun.com/)
parseUpdateForCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSApwg1uj&0.8624172924051665&modid=undefined
updateRe = <_sre.SRE_Match object; span=(1079, 1092), match='update=22682&'>
update = 22682
2018-03-24 14:39:01 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&update=22682&idhash=cSApwg1uj> (referer: http://www.51baiduyun.com/)
parseCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&update=22682&idhash=cSApwg1uj
2018-03-24 14:39:01 [PIL.PngImagePlugin] DEBUG: STREAM b'IHDR' 16 13
2018-03-24 14:39:01 [PIL.PngImagePlugin] DEBUG: STREAM b'IDAT' 41 2539
2018-03-24 14:39:02 [PIL.Image] DEBUG: Error closing: 'NoneType' object has no attribute 'close'
输入验证码
>C94a
input captcha is : C94a
开始模拟登录百度云俱乐部
2018-03-24 14:39:13 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1> (referer: http://www.51baiduyun.com/misc.php?mod=seccode&update=22682&idhash=cSApwg1uj)
parseLoginResPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1
text = <?xml version="1.0" encoding="utf-8"?>
<root><![CDATA[抱歉,验证码填写错误<script type="text/javascript" reload="1">if(typeof errorhandle_login=='function') {errorhandle_login('抱歉,验证码填写错误', {});}</script>]]></root>
subject = clawerName had finished, reason = finished, finishedTime = 2018-03-24 14:39:13.302602- 登录失败:密码错误
start baiduyun clawer
2018-03-24 14:37:14 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login> (referer: http://www.51baiduyun.com/)
parseLoginArgsPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&infloat=yes&handlekey=login&inajax=1&ajaxtarget=fwin_content_login
formhashRe = <_sre.SRE_Match object; span=(650, 682), match='name="formhash" value="ded981e3"'>, refererRe = <_sre.SRE_Match object; span=(708, 757), match='name="referer" value="http://www.51baiduyun.com/">
Set-Cookie = [b'L3em_2132_saltkey=lnzh8Msb; expires=Mon, 23-Apr-2018 06:41:51 GMT; Max-Age=2592000; path=/; httponly', b'L3em_2132_lastvisit=1521870111; expires=Mon, 23-Apr-2018 06:41:51 GMT; Max-Age=2591999; path=/', b'L3em_2132_sid=j91h9s; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/', b'L3em_2132_lastact=1521873711%09member.php%09logging; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/', b'L3em_2132_sid=j91h9s; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/']
cookieInfoLst = ['L3em_2132_saltkey=lnzh8Msb; expires=Mon, 23-Apr-2018 06:41:51 GMT; Max-Age=2592000; path=/; httponly', 'L3em_2132_lastvisit=1521870111; expires=Mon, 23-Apr-2018 06:41:51 GMT; Max-Age=2591999; path=/', 'L3em_2132_sid=j91h9s; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/', 'L3em_2132_lastact=1521873711%09member.php%09logging; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/', 'L3em_2132_sid=j91h9s; expires=Sun, 25-Mar-2018 06:41:51 GMT; Max-Age=86399; path=/']
sid = j91h9s
2018-03-24 14:37:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSAj91h9s&0.5541295116875323&modid=undefined> (referer: http://www.51baiduyun.com/)
parseUpdateForCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&action=update&idhash=cSAj91h9s&0.5541295116875323&modid=undefined
updateRe = <_sre.SRE_Match object; span=(1079, 1092), match='update=12248&'>
update = 12248
2018-03-24 14:37:19 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://www.51baiduyun.com/misc.php?mod=seccode&update=12248&idhash=cSAj91h9s> (referer: http://www.51baiduyun.com/)
parseCaptcha: statusCode = 200, url = http://www.51baiduyun.com/misc.php?mod=seccode&update=12248&idhash=cSAj91h9s
2018-03-24 14:37:19 [PIL.PngImagePlugin] DEBUG: STREAM b'IHDR' 16 13
2018-03-24 14:37:19 [PIL.PngImagePlugin] DEBUG: STREAM b'IDAT' 41 2498
输入验证码
2018-03-24 14:37:20 [PIL.Image] DEBUG: Error closing: 'NoneType' object has no attribute 'close'
>CY7R
input captcha is : CY7R
开始模拟登录百度云俱乐部
2018-03-24 14:37:25 [scrapy.core.engine] DEBUG: Crawled (200) <POST http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1> (referer: http://www.51baiduyun.com/misc.php?mod=seccode&update=12248&idhash=cSAj91h9s)
parseLoginResPage: statusCode = 200, url = http://www.51baiduyun.com/member.php?mod=logging&action=login&loginsubmit=yes&handlekey=login&loginhash=Lpd1b&inajax=1
text = <?xml version="1.0" encoding="utf-8"?>
<root><![CDATA[登录失败,您还可以尝试 3 次<script type="text/javascript" reload="1">if(typeof errorhandle_login=='function') {errorhandle_login('登录失败,您还可以尝试 3 次', {'loginperm':'3'});}</script>]]></root>
subject = clawerName had finished, reason = finished, finishedTime = 2018-03-24 14:37:25.7986023.4. 说明
- 其实从整个过程来看,是比较简单的,唯一需要特别注意的点就是如何保证获取到的验证码和这些用户参数保持一定的关联性,scrapy是通过cookie传递做到了这一点。同理,如果想在scrapy中使用requests模块,只需要将cookie(要分清请求的cookie和服务器返回的cookie是不一样的)取出,放入到requests的get,post请求中去。