【深度学习】学习率与学习率衰减详解:torch.optim.lr_scheduler用法
—————————————————————————————————————————————————————————————
1. 介绍
深度学习模型训练过程中,经过一定的epoch之后,模型的性能趋于饱和,此时降低学习率,在小范围内进一步调整模型的参数,可以进一步提升模型的性能。
- 经过多年的发展,也出现了多种学习率衰减算法,比如线性衰减、指数衰减、cosine衰减等,下面将pyTorch中提供的学习率衰减算法进行整理。
1.1 学习率与学习率衰减
模型参数的学习主要是通过反向传播和梯度下降,
- 而其中梯度下降的学习率设置方法是指数衰减:在训练神经网络时,需要设置学习率(learing rate)控制参数更新的速度,学习率决定了参数每次更新的幅度,
- 如果幅度过大,则可能导致参数在极优值的两侧来回移动;
- 若幅度过小,又会大大降低优化速度。
通过指数衰减的学习率既可以让模型在训练的前期快速接近较优解,又可以保证模型在训练后期不会有太大的波动,从而更加接近局部的最优解。
—————————————————————————————————————————————————————————————
2. TensorFlow中的学习率衰减
- TensorFlow提供了一种更加灵活的学习率设置方法-指数衰减法,使用tf.train.exponential_decay实现。指数衰减法的核心思想是,先使用较大的学习率来快速得到一个比较优的解,然后随着迭代的继续逐步减小学习率,使得模型更加稳定。
tf.train.exponential_decay函数可以用以下代码实现的功能来展示:
decayed_learning_rate = learning_rate*decay_rate^(global_step/decay_steps)
# decayed_learning_rate为每一轮优化时使用的学习率,learning_rate为事先设定的初始学习率,
# decay_rate为衰减系数,global_step为迭代次数,decay_steps为衰减速度(即迭代多少次进行衰减)
由代码可见,
- 使用此函数,随着迭代次数的增加,学习率逐步降低。tf.train.exponential_decay 可以通过设置参数staircase选择不同的衰减方式,其默认值为False,即每一次迭代都进行学习率的优化,不同的训练数据有不同的学习率,而当学习率减小时,对应的训练数据对模型训练结果的影响也会变小。若staircase的值为True时,global_step/decay_steps的值会被转化为整数,decay_steps通常代表了完整的使用一遍训练数据所需要的迭代次数,所以每完整的使用完一遍训练数据,学习率才会重新计算并减小一次,这可以使得训练数据集中的所有数据对模型有相等的作用。
1)具体的函数使用代码如下:
global_step = tf.Variable(0) #迭代次数初始值为0
# 通过exponential_decay生成学习率
learning_rate = tf.train.exponential_decay(0.1, global_step, 100, 0.96, staircase=True)
# 0.1为初始学习率,global_step为迭代次数,100为衰减速度,0.96为衰减率
# 使用指数衰减的学习率,在minimize函数中传入global_step,它将自动更新,learning_rate也随即被更新
learning_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
# 神经网络反向传播算法,使用梯度下降算法GradientDescentOptimizer来优化权重值,learning_rate为学习率,
# minimize中参数loss是损失函数,global_step表明了当前迭代次数(会被自动更新)
2)一般来说,初始学习率、衰减系数和衰减速度都是根据经验设置的。为了更好理解学习率的详细设置,通过Tensorflow框架中学习率设置为例。
- 在tensorflow中提供了一个灵活的学习率设置方法,tf.train.exponential_decay函数实现了指数衰减,其实现的原理如下:
decayed_learning_rate=learning_rate*decay_rate^(global_step/decay_steps)
其中:
- decayed_learning_rate:每一轮优化时使用的学习率 (当前学习率)
- learning_rate:事先设定的初始学习率
- decay_rate:衰减系数 (学习率的衰减系数)
- decay_steps:衰减速度 (相当于iteration ,总样本/batch-size)
tf.train.exponential_decay 函数还可以通过设置参数 staircase 选择不同的衰减方式。
- staircase是false,这时的学习率会随迭代的轮数成平滑的衰减下降,这里的不同训练数据有不同的学习率。
- staircase是true,(global_step/decay_steps)会被转化为整数,这时学习率会随着轮数成阶梯状下降,在这种设置下decay_steps指完整的使用一遍训练数据所需要的迭代轮数(总的训练样本数处以每一个batch中的训练样本数),这里的意思就是每完整的过完一遍训练数据,学习率就减少一次,这可以使得训练集中的所有数据对模型训练有相等的作用。
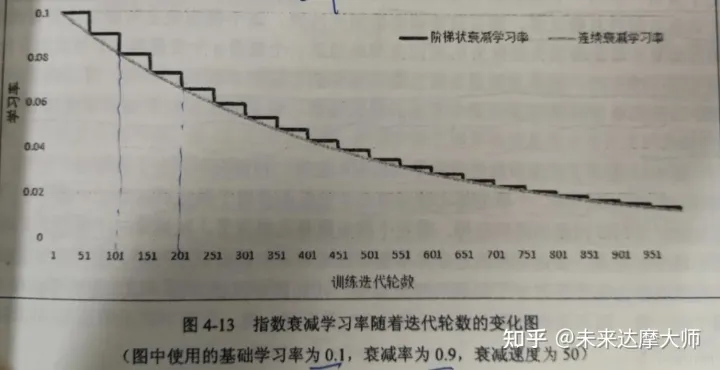
3)使用如下:
EARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True)
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step)
代码完整示例:
import tensorflow as tf
from numpy.random import RandomState
# 假设我们要最小化函数 y=x^2 , 选择初始点 x0=5
TRAINING_STEPS = 100
LEARNING_RATE = 1
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x)
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y)
global_step = tf.Variable(0)
LEARNING_RATE = tf.train.exponential_decay(0.1, global_step, 1, 0.96, staircase=True)
x = tf.Variable(tf.constant(5, dtype=tf.float32), name="x")
y = tf.square(x)
train_op = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(y, global_step=global_step)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(TRAINING_STEPS):
sess.run(train_op)
if i % 10 == 0:
LEARNING_RATE_value = sess.run(LEARNING_RATE)
x_value = sess.run(x)
print ("After %s iteration(s): x%s is %f, learning rate is %f." \
% (i+1, i+1, x_value, LEARNING_RATE_value))
运行结果:
After 1 iteration(s): x1 is 4.000000, learning rate is 0.096000.
After 11 iteration(s): x11 is 0.690561, learning rate is 0.063824.
After 21 iteration(s): x21 is 0.222583, learning rate is 0.042432.
After 31 iteration(s): x31 is 0.106405, learning rate is 0.028210.
After 41 iteration(s): x41 is 0.065548, learning rate is 0.018755.
After 51 iteration(s): x51 is 0.047625, learning rate is 0.012469.
After 61 iteration(s): x61 is 0.038558, learning rate is 0.008290.
After 71 iteration(s): x71 is 0.033523, learning rate is 0.005511.
After 81 iteration(s): x81 is 0.030553, learning rate is 0.003664.
After 91 iteration(s): x91 is 0.028727, learning rate is 0.002436.
—————————————————————————————————————————————————————————————
3. PyTorch中的学习率衰减
- pyTorch官方介绍:https://pytorch.org/docs/stable/optim.html
torch.optim.lr_scheduler模块提供了一些根据epoch训练次数来调整学习率(learning rate)的方法。\
- 一般情况下我们会设置随着epoch的增大而逐渐减小学习率从而达到更好的训练效果。
而 torch.optim.lr_scheduler.ReduceLROnPlateau 则提供了基于训练中某些测量值使学习率动态下降的方法。
学习率的调整应该放在optimizer更新之后,下面是一个参考蓝本:
optimizer = ...
scheduler = ...
for epoch in range(100):
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step()
- scheduler.step()执行学习率衰减操作。
pyTorch 1.1.0之前的版本,是在optimizer更新之前进行学习率衰减。
- 之后的版本调整为先进行optimizer更新,再进行学习率衰减。
- 如果在1.1.0之后的版本中,先调用了scheduler.step()再调用optimizer.step(),造成的后果是第一次的学习率衰减并未生效。
- 如果pytorch升级到1.1.0之后的版本无法复现原始的训练结果,那么就需要检查是不是调用scheduler.step()的顺序出错了。
—————————————————————————————————————————————————————————————
2.1 optimizer 综述
为了了解lr_scheduler,我们先以Adam()为例了解一下优化器(所有 optimizers 都继承自torch.optim.Optimizer类):
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
1)参数:
- params(iterable):需要优化的网络参数,传进来的网络参数必须是 Iterable(官网对这个参数用法讲的不太清楚,下面有例子清楚的说明param具体用法)。
- 如果优化一个网络,网络的每一层看做一个parameter group,一整个网络就是parameter groups(一般给赋值为net.parameters()),补充一点,net.parameters()函数返回的parameter groups实际上是一个变成了generator的字典;
- 如果同时优化多个网络,有两种方法:
- 将多个网络的参数合并到一起,当成一个网络的参数来优化(一般赋值为[*net_1.parameters(), *net_2.parameters(), …, *net_n.parameters()]或itertools.chain(net_1.parameters(), net_2.parameters(), …, net_n.parameters()));
- 当成多个网络优化,这样可以很容易的让多个网络的学习率各不相同(一般赋值为[{‘params’: net_1.parameters()}, {‘params’: net_2.parameters()}, …, {‘params’: net_n.parameters()})。
- lr (float, optional):学习率;
- betas (Tuple[float, float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999));
- eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8);
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0);
- amsgrad (boolean, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)。
2)属性:
- optimizer.defaults: 字典,存放这个优化器的一些初始参数,有:‘lr’, ‘betas’, ‘eps’, ‘weight_decay’, ‘amsgrad’。事实上这个属性继承自torch.optim.Optimizer父类;
- optimizer.param_groups:列表,每个元素都是一个字典,每个元素包含的关键字有:‘params’, ‘lr’, ‘betas’, ‘eps’, ‘weight_decay’, ‘amsgrad’,params类是各个网络的参数放在了一起。这个属性也继承自torch.optim.Optimizer父类。
由于上述两个属性都继承自所有优化器共同的基类,所以是所有优化器类都有的属性,并且两者字典中键名相同的元素值也相同(经过lr_scheduler后 lr 就不同了)。
3)用法示例:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
self.conv2 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
net_2 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
print("******************optimizer_1*********************")
print("optimizer_1.defaults:", optimizer_1.defaults)
print("optimizer_1.param_groups长度:", len(optimizer_1.param_groups))
print("optimizer_1.param_groups一个元素包含的键:", optimizer_1.param_groups[0].keys())
print()
optimizer_2 = torch.optim.Adam([*net_1.parameters(), *net_2.parameters()], lr = initial_lr)
# optimizer_2 = torch.opotim.Adam(itertools.chain(net_1.parameters(), net_2.parameters())) # 和上一行作用相同
print("******************optimizer_2*********************")
print("optimizer_2.defaults:", optimizer_2.defaults)
print("optimizer_2.param_groups长度:", len(optimizer_2.param_groups))
print("optimizer_2.param_groups一个元素包含的键:", optimizer_2.param_groups[0].keys())
print()
optimizer_3 = torch.optim.Adam([{
"params": net_1.parameters()}, {
"params": net_2.parameters()}], lr = initial_lr)
print("******************optimizer_3*********************")
print("optimizer_3.defaults:", optimizer_3.defaults)
print("optimizer_3.param_groups长度:", len(optimizer_3.param_groups))
print("optimizer_3.param_groups一个元素包含的键:", optimizer_3.param_groups[0].keys())
对应输出为:
******************optimizer_1*********************
optimizer_1.defaults: {
'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_1.param_groups长度: 1
optimizer_1.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_2*********************
optimizer_2.defaults: {
'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_2.param_groups长度: 1
optimizer_2.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
******************optimizer_3*********************
optimizer_3.defaults: {
'lr': 0.1, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
optimizer_3.param_groups长度: 2
optimizer_3.param_groups一个元素包含的键: dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad'])
- 注意:lr_scheduler更新 optimizer 的 lr,更新的是 optimizer.param_groups[n][‘lr’],而不是 optimizer.defaults[‘lr’]。
—————————————————————————————————————————————————————————————
2.2 lr_scheduler调整策略:根据训练次数
pyTorch官方介绍:https://pytorch.org/docs/stable/optim.html
torch.optim.lr_scheduler 中大部分调整学习率的方法都是根据 epoch训练次数,这里介绍常见的几种方法,其他方法以后用到再补充。
- 要了解每个类的更新策略,可直接查看官网doc中的源码,每类都有个get_lr方法,定义了更新策略。
—————————————————————————————————————————————————————————————
2.2.0 直接手动修改optimizer的lr参数
optimizer 通过 param_group 来管理参数组,
- 它里面保存了参数组及其对应的学习率、动量等;
因此可以通过更改 param_group[‘lr’] 的值来更改对应参数组的学习率。
代码示例:
import torch
import matplotlib.pyplot as plt
import torch.optim as optim
from torch.optim import lr_scheduler
from torchvision.models import AlexNet
model = AlexNet(num_classes=2)
LR = 0.1
optimizer = optim.SGD(params=model.parameters(),lr=LR)
plt.figure()
x = list(range(100))
y=[]
for epoch in range(100):
if epoch % 5 == 0:
for p in optimizer.param_groups:
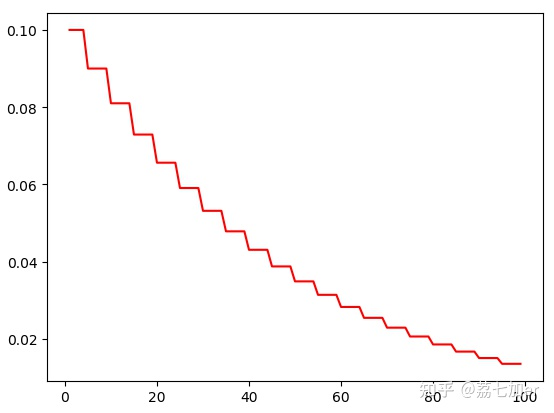
p['lr'] *= 0.9
y.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(x,y,color = 'r')
plt.show()
2.2.1 自定义调整学习率(LambdaLR)
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
1)参数:
- optimizer (Optimizer):要更改学习率的优化器;
- lr_lambda(function or list):根据epoch计算 λ 的函数;或者是一个 list 的这样的function,分别计算各个parameter groups的学习率更新用到的 λ ;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为 -1表示从头开始训练,即从epoch=1开始。
2)更新策略,公式表示:
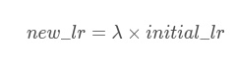
- 其中,new_lr是得到新的学习率, λ \lambda λ 是根据 epoch 计算λ 函数;或者是一个list的这样的 function,分别计算各个parameter groups的学习率更新用到的 λ;initial_lr 是初始的学习率。
3)注意:在将 optimizer 传给 scheduler 后,在shcduler类的__init__方法中会给optimizer.param_groups列表中的那个元素(字典)增加一个key = "initial_lr"的元素表示初始学习率,等于optimizer.defaults[‘lr’]。
4)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = LambdaLR(optimizer_1, lr_lambda=lambda epoch: 1/(epoch+1))
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.050000
第3个epoch的学习率:0.033333
第4个epoch的学习率:0.025000
第5个epoch的学习率:0.020000
第6个epoch的学习率:0.016667
第7个epoch的学习率:0.014286
第8个epoch的学习率:0.012500
第9个epoch的学习率:0.011111
第10个epoch的学习率:0.010000
关键行解析:
第1~3行 : import一些包。
第7~13行: 简单定义一个网络类,并没有实现网络应有的功能,只是用来定义optimizer的。
第15行: 实例化一个网络。
第17行: 实例化一个Adam对象。
第18行: 实例化一个LambdaLR对象。lr_lambda是根据epoch更新lr的函数。
第20行: 打印出初始的lr。optimizer_1.defaults保存的是初始的参数。
第22~28行: 模仿训练的epoch。
第25~26行: 更新网络参数(这里省略了loss.backward())。
第27行: 打印这一个epoch更新参数所用的学习率,由于我们只给optimizer_1传了一个net.parameters(),所以optimizer_1.param_groups长度为1。
第28行: 更新学习率。
5)补充:cycleGAN中使用torch.optim.lr_scheduler.LambdaLR实现了前niter个epoch用initial_lr为学习率,之后的niter_decay个epoch线性衰减lr,直到最后一个epoch衰减为0。参考:知乎
—————————————————————————————————————————————————————————————
2.2.2 每 s 个 epoch 更新一次参数(等步长调整学习率(StepLR))
class torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
1)参数:
- optimizer (Optimizer):要更改学习率的优化器;
- step_size(int):每训练step_size个epoch,更新一次参数;
- gamma(float):更新lr的乘法因子;
- last_epoch (int):最后一个epoch的index,如果是训练了很多个epoch后中断了,继续训练,这个值就等于加载的模型的epoch。默认为-1表示从头开始训练,即从epoch=1开始。
2)更新策略:
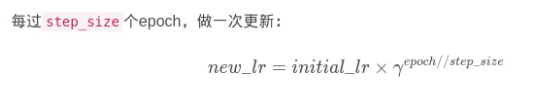
3)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import StepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = StepLR(optimizer_1, step_size=3, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.001000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.000100
—————————————————————————————————————————————————————————————
2.2.3 多步长调整学习率(MultiStepLR)
class torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
1)
- 参数:

2)更新策略:

3)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import MultiStepLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = MultiStepLR(optimizer_1, milestones=[3, 7], gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.010000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000
—————————————————————————————————————————————————————————————
2.2.4 指数衰减调整学习率(ExponentialLR)
class torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma, last_epoch=-1)
1)
- 参数:

2)更新策略:
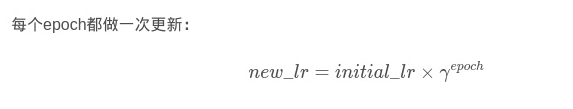
3)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ExponentialLR
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ExponentialLR(optimizer_1, gamma=0.1)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 11):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step()
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.010000
第3个epoch的学习率:0.001000
第4个epoch的学习率:0.000100
第5个epoch的学习率:0.000010
第6个epoch的学习率:0.000001
第7个epoch的学习率:0.000000
第8个epoch的学习率:0.000000
第9个epoch的学习率:0.000000
第10个epoch的学习率:0.000000
—————————————————————————————————————————————————————————————
2.2.5 余弦退火调整学习率(CosineAnnealingLR)
class torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
1)
- 参数:

2)更新策略:

3)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import CosineAnnealingLR
import itertools
import matplotlib.pyplot as plt
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = CosineAnnealingLR(optimizer_1, T_max=20)
print("初始化的学习率:", optimizer_1.defaults['lr'])
lr_list = [] # 把使用过的lr都保存下来,之后画出它的变化
for epoch in range(1, 101):
# train
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lr_list.append(optimizer_1.param_groups[0]['lr'])
scheduler_1.step()
# 画出lr的变化
plt.plot(list(range(1, 101)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
输出结果过长不再展示,下面展示lr的变化图:
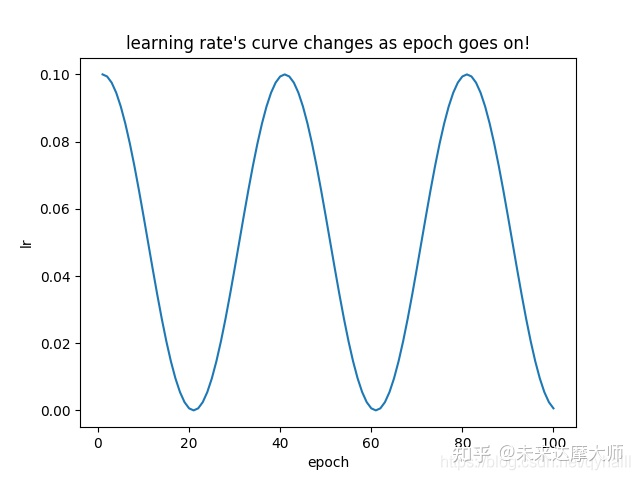
- 可以看到 lr 的变化类似于cos函数的变化图。
—————————————————————————————————————————————————————————————
2.2.6 其他的一些 lr_scheduler
- torch.optim.lr_scheduler.CyclicLR
- torch.optim.lr_scheduler.OneCycleLR
- torch.optim.lr_scheduler.CosineAnnealingWarmRestarts
—————————————————————————————————————————————————————————————
2.3 lr_scheduler调整策略:根据训练中某些测量值
- 不依赖 epoch 更新 lr 的只有这个:torch.optim.lr_scheduler.ReduceLROnPlateau。
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
1)
- 参数:

2)更新策略:

3)举例说明:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import ReduceLROnPlateau
import itertools
initial_lr = 0.1
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
net_1 = model()
optimizer_1 = torch.optim.Adam(net_1.parameters(), lr = initial_lr)
scheduler_1 = ReduceLROnPlateau(optimizer_1, mode='min', factor=0.1, patience=2)
print("初始化的学习率:", optimizer_1.defaults['lr'])
for epoch in range(1, 15):
# train
test = 2
optimizer_1.zero_grad()
optimizer_1.step()
print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
scheduler_1.step(test)
输出:
初始化的学习率: 0.1
第1个epoch的学习率:0.100000
第2个epoch的学习率:0.100000
第3个epoch的学习率:0.100000
第4个epoch的学习率:0.100000
第5个epoch的学习率:0.010000
第6个epoch的学习率:0.010000
第7个epoch的学习率:0.010000
第8个epoch的学习率:0.001000
第9个epoch的学习率:0.001000
第10个epoch的学习率:0.001000
第11个epoch的学习率:0.000100
第12个epoch的学习率:0.000100
第13个epoch的学习率:0.000100
第14个epoch的学习率:0.000010
—————————————————————————————————————————————————————————————
参考
【1】torch.optim.lr_scheduler:调整学习率_qyhaill的博客-CSDN博客_lr_scheduler
【2】decay_rate, decay_steps ,batchsize,iteration,epoch
【3】https://zhuanlan.zhihu.com/p/494010639
【4】https://blog.csdn.net/cdknight_happy/article/details/109379102
【5】https://zhuanlan.zhihu.com/p/475824165