
论文标题:Boosting Accuracy and Robustness of Student Models via Adaptive Adversarial Distillation
论文链接:https://openaccess.thecvf.com/content/CVPR2023/papers/Huang_Boosting_Accuracy_and_Robustness_of_Student_Models_via_Adaptive_Adversarial_CVPR_2023_paper.pdf
作者单位:香港科技大学(广州),香港科技大学,东莞理工学院,麦考瑞大学
代码链接:https://github.com/boyellow/AdaAD
导读
当今,机器学习,特别是深度学习,在各个领域得到广泛应用。在实时应用和边缘设备中,常常需要部署轻量级模型[1]。然而,在边缘部署中,由于预算有限,轻量级模型通常缺乏足够的保护机制。与大规模模型相比,轻量级模型更容易受到针对恶意目的的对抗性攻击(Adversarial Attacks)的风险[2,3]。
因此,在实际应用中,提高轻量级模型对恶意攻击的对抗鲁棒性(Robustness)至关重要。许多研究表明,对抗性训练(Adversarial Training)对于提高模型的鲁棒性是有效的。然而,一些研究表明,对于参数过量化的大模型,对抗训练效果更好[4],而在轻量级模型上提高鲁棒性的效果非常有限,甚至会严重降低在自然样本上的准确率。
最近的研究关注于通过对抗性鲁棒蒸馏(Adversarial Robustness Distillation)来提高轻量级模型的鲁棒性能[5]。与传统知识蒸馏[1]不同的是,对抗性鲁棒蒸馏不仅要求学生模型从鲁棒教师模型继承准确性能,还需要继承鲁棒性能。
动机
目前存在的对抗性鲁棒蒸馏方法通常采用两种方式来引导鲁棒蒸馏过程,即:
- 硬标签(
Hard Label) - 软标签(
Soft Label)
这些方法的优化目标是使得学生模型在邻近区域内的所有样本点上的预测值与固定标签一致。然而,这样做必然会引入对模型光滑性的过度校正问题。已有文献表明,这种过度校正问题是准确率和鲁棒性之间存在权衡的一个重要原因[6,7]。因此,现有的对抗性鲁棒蒸馏方法在轻量级模型上的准确率和鲁棒性方面存在限制。
在这篇文章中,作者提出了一种自适应对抗蒸馏AdaAD(Adaptive Adversarial Distillation)方法,通过自适应的方式寻找最优的匹配点(Match Points)用于蒸馏训练过程。AdaAD可以有效缓解过度校正问题,并且可以允许使用更大的搜索半径(Search Radius)进行寻找。实验表明,相比已有的方法,AdaAD可以显著提高学生模型的准确率和鲁棒性。
方法
AdaAD
作者认为对抗性鲁棒蒸馏的期望目标是学生模型可以最大化地和鲁棒教师模型在所有样本点和样本点的邻近区域内进行预测对齐。这个最大化对齐目标可以被形式化地定义为:
L A D = ∬ D ( S ( x + δ ) , T ( x + δ ) ) d δ d x , \mathcal{L}_{\mathrm{AD}} = \iint \mathcal{D}(S(x+\delta), T(x+\delta)) d \delta dx, LAD=∬D(S(x+δ),T(x+δ))dδdx,
其中 D \mathcal{D} D表示一种距离度量, S ( ⋅ ) S(\cdot) S(⋅)和 T ( ⋅ ) T(\cdot) T(⋅)分别表示学生模型和教师模型。然而,由于深度学习的高维特性,直接优化上述的目标是非常困难的。作者提出了AdaAD,一种基于min-max的框架来近似求解上述的优化目标:
min max ∣ ∣ δ ∣ ∣ p ≤ ϵ D ( S ( x + δ ) , T ( x + δ ) ) , \min \max_{||\delta ||_p \le \epsilon } \mathcal{D}(S(x+\delta), T(x+\delta)), min∣∣δ∣∣p≤ϵmaxD(S(x+δ),T(x+δ)),
这个框架包括了两步。第一步是在给定的原始样本点 x 0 x_0 x0和其 ϵ \epsilon ϵ-邻域找到学生模型和教师模型预测差异最大化的点 x ∗ x^* x∗,即:
x ∗ = x + arg max ∣ ∣ δ ∣ ∣ p ≤ ϵ K L ( S ( x + δ ) ∣ ∣ T ( x + δ ) ) , x^{*}=x+\underset{||\delta||_{p} \leq \epsilon}{\arg\max } \ \mathrm{KL}(S(x+\delta) ||T(x+\delta)) , x∗=x+∣∣δ∣∣p≤ϵargmax KL(S(x+δ)∣∣T(x+δ)),
作者在文中使用KL散度作为两个模型预测差异的距离度量。第二步是最小化学生模型和教师模型的最大预测差异去对齐两个模型:
arg min θ s K L ( S ( x ∗ ) ∣ ∣ T ( x ∗ ) ) . \underset{\theta_{s}}{\arg\min } \ \mathrm{KL}(S(x^*) ||T(x^*)). θsargmin KL(S(x∗)∣∣T(x∗)).
具体来看,AdaAD的内层优化细节如下图所示:
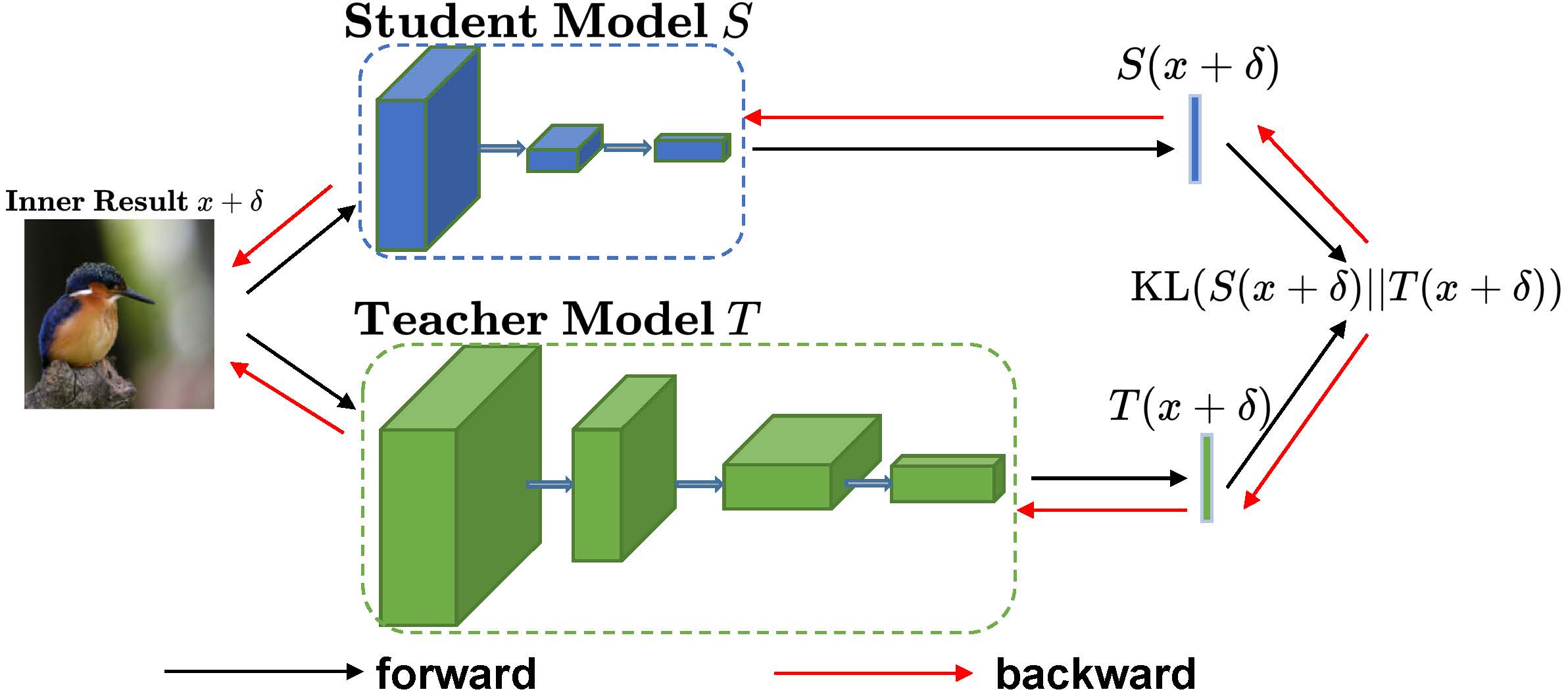
AdaAD的益处
1. 缓解模型光滑性的过度校正问题
已有的对抗训练和对抗性鲁棒蒸馏方法通常考虑使用固定的硬标签(Hard Label)或者固定的软标签(Soft Label)去引导鲁棒蒸馏过程。这些方法的优化目标是使得学生模型在一个样本点的邻近区域(Neighborhood Region)内所有点上的预测值去和一个固定的标签进行对齐。给定一个原始样本点 x 0 x_0 x0,和其 ϵ \epsilon ϵ-邻域,这一对齐目标可以表示为:
∀ x ∈ B ( x 0 , ϵ ) , S ( x ) = p ( y ∣ x 0 ) or S ( x ) = T ( x 0 ) , \forall x \in \mathcal{B}(x_0, \epsilon), S(x)=p(y|x_0) \ \text{or} \ S(x)=T(x_0), ∀x∈B(x0,ϵ),S(x)=p(y∣x0) or S(x)=T(x0),
其中, p ( y ∣ x 0 ) p(y|x_0) p(y∣x0)和T(x_0)分别表示数据集中的硬标签和教师模型对原始样本的软标签。这一过度校正问题导致了训练得到的模型在准确率和鲁棒性之间会出现严重的权衡(Trade-off)。而提出的AdaAD促使学生模型在一个样本点邻域内所有点上的预测值和教师模型在这个邻域内的预测分布进行对齐,从而显著缓解了过度校正问题。具体来说,AdaAD的对齐目标表示为:
∀ x ∈ B ( x 0 , ϵ ) , S ( x ) = T ( x ) . \forall x \in \mathcal{B}(x_0, \epsilon), S(x)=T(x). ∀x∈B(x0,ϵ),S(x)=T(x).
2. 允许更大的搜索半径
和对抗训练以及已有的对抗性鲁棒蒸馏方法不同的是,AdaAD在max内层优化中找寻的匹配点代表的是学生模型和老师模型预测差异最大的点,这些点并不一定是高度对抗性的,因此不同于已有的对抗训练和对抗性鲁棒蒸馏方法,AdaAD是可以在max内层优化中允许使用更大的搜索半径。更大的搜索半径也意味着对于学生模型和教师模型之间的对齐约束更强,实验表明增大搜索半径可以显著提高学生模型的鲁棒性能。
实验
白盒攻击评估
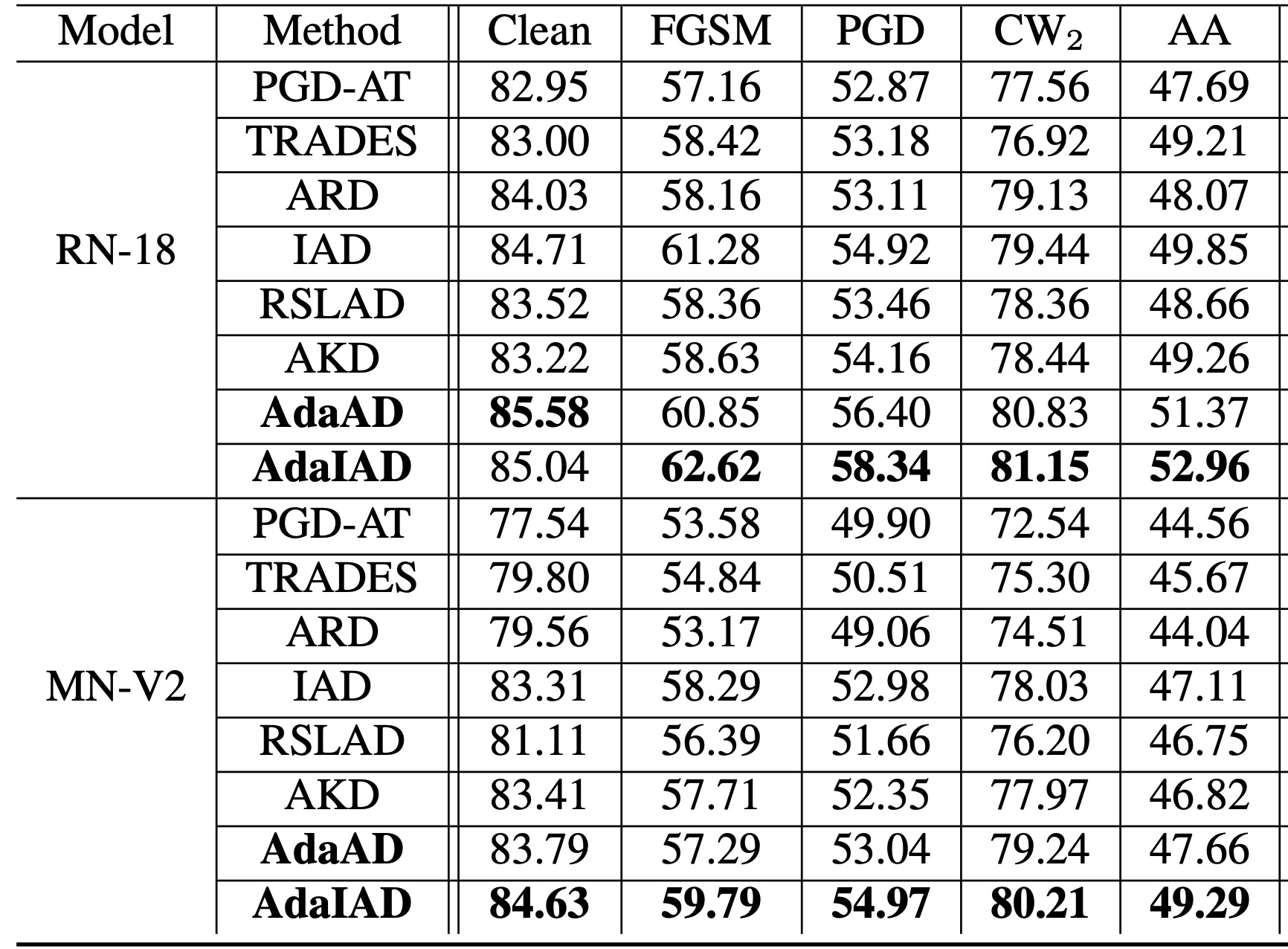
上表展示了提出的AdaAD和AdaIAD以及其他最先进方法在CIFAR-10数据集上对于不同对抗性攻击的识别精度。首先,从上表中可以看出,对抗性鲁棒蒸馏方法在准确率和鲁棒性方面明显优于对抗训练方法,这表明其在提高轻量级模型鲁棒性方面比对抗训练更有效、更具竞争力。其次,AdaAD和AdaIAD在准确率和鲁棒性方面明显超越了最先进方法,这表明AdaAD和AdaIAD能够显著改善准确率和鲁棒性之间的权衡(Trade-off)。值得注意的是,由于AA (AutoAttack)攻击包括两种基于查询的攻击方式,因此AdaAD和AdaIAD在提高AA识别准确率方面的有效性表明,他们对于基于查询攻击的有效性也是可靠的。
增大搜索半径
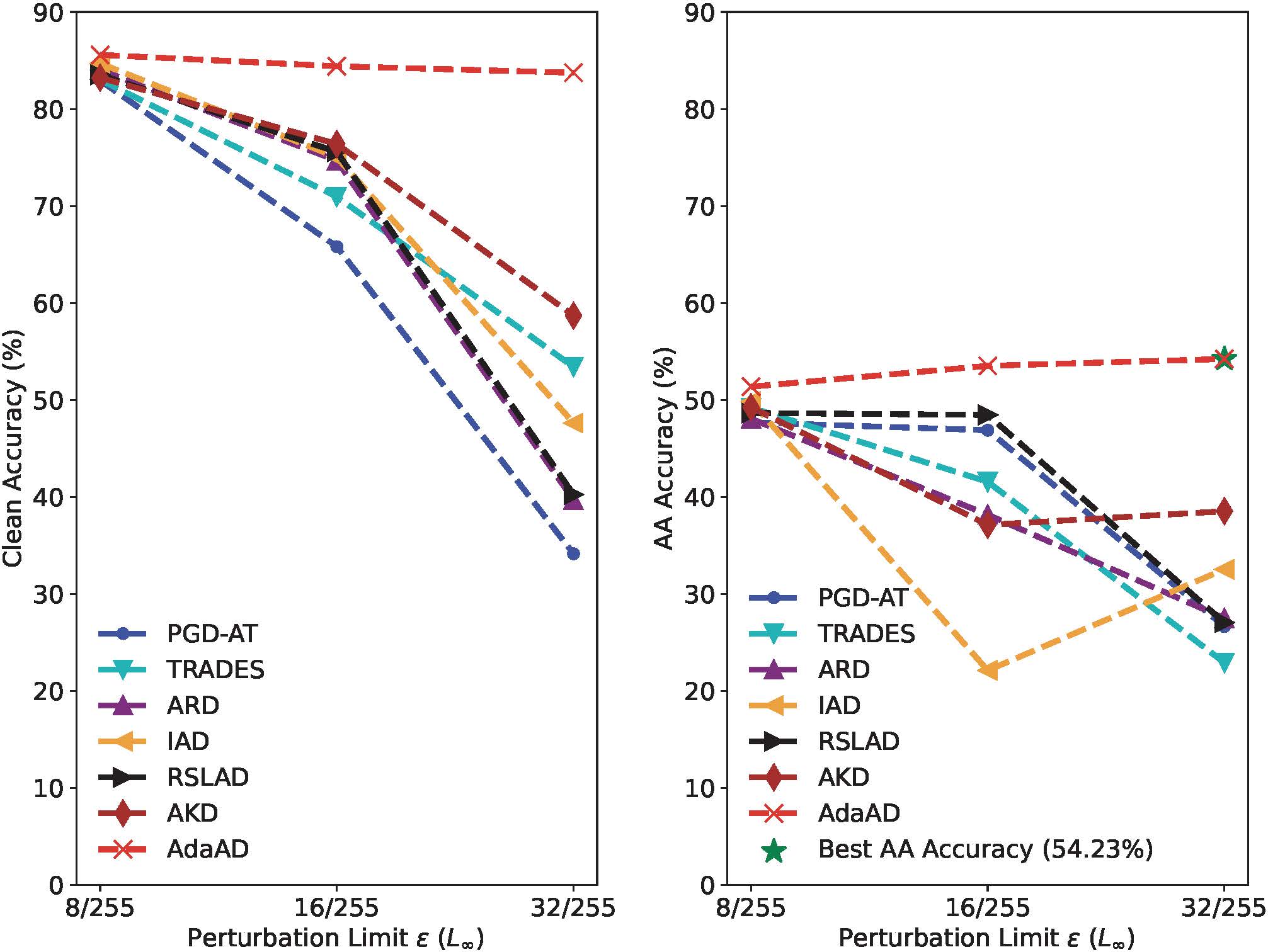
上图评估了在CIFAR-10数据集上,使用不断增大的搜索半径 ϵ \epsilon ϵ训练的ResNet-18学生模型的准确率和AutoAttack识别准确率(AA准确率)。总体而言,所提出的AdaAD在所有 ϵ \epsilon ϵ值情况下都显著提高了准确率和鲁棒性,大幅度超过了其他方法。具体来说,当将ε从8/255增加到32/255时,AdaAD的准确率几乎保持不变,而AA准确率呈现持续增加的趋势,而所有比较方法的准确率急剧下降至60%以下,其AA准确率下降至40%以下。在没有使用额外数据增强的情况下,我们提出的AdaAD方法可以在 ϵ \epsilon ϵ设置为32/255时,取得54.23%的AA准确率。这些结果验证了自适应特性使得AdaAD能够在较大的局部区域内搜索学生模型与教师模型之间的预测差异的上界,从而使得学生模型能够更好地继承教师模型的鲁棒性并且几乎不损失准确率。
总结
本文通过在min-max框架中最大化教师模型和学生模型之间的预测差异,提出了一个新的对抗蒸馏目标函数。此外,作者设计了一种自适应对抗蒸馏方案,即AdaAD,通过在内层优化中自适应地搜索最佳的“匹配点”来进行对抗性鲁棒蒸馏。最后,大量的实验证明,提出的方法在准确率和鲁棒性上明显优于当前最先进的对抗训练和对抗性鲁棒蒸馏方法。
参考文献
[1] Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. CoRR, abs/1503.02531, 2015
[2] Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nel- son, Nedim Srndic, Pavel Laskov, Giorgio Giacinto, and Fabio Roli. Evasion attacks against machine learning at test time. In ECML PKDD, pages 387–402, 2013
[3] Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. In ICLR, 2015
[4] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In ICLR, 2018.
[5] Micah Goldblum, Liam Fowl, Soheil Feizi, and Tom Gold- stein. Adversarially robust distillation. In AAAI, pages 3996– 4003, 2020.
[6] Stutz, Matthias Hein, and Bernt Schiele. Confidence- calibrated adversarial training: Generalizing to unseen at- tacks. In ICML, pages 9155–9166, 2020.
[7] Tianyu Pang, Min Lin, Xiao Yang, Jun Zhu, and Shuicheng Yan. Robustness and accuracy could be reconcilable by (proper) definition. In ICML, pages 17258–17277, 2022.