一、Kafka的概述
1.1 定义
Kafka是一个开源的分布式事件流平台 (Event Streaming Platform),被广泛用于高性能数据管道、流分
析、数据集成和关键任务应用。
1.2 各消息队列的比较
目前比 较常见的消息队列产品主要有Kafka、RabbitMQ 、RocketMQ 等。
在大数据场景主要采用Kafka作为消息队列。在JavaEE开发中主要采用RabbitMQ、RocketMQ。
几种常见MQ对比:
| RabbitMQ | RocketMQ | Kafka | |
|---|---|---|---|
| 公司/社区 | Rabbit | 阿里 | Apache |
| 开发语言 | Erlang | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 高 | 高 |
| 单机吞吐量 | 一般 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
1.3 传统消息队列的应用场景
传统的消息队列的主要应用场景包括:缓存/流量消峰、解耦和异步通信。
1)缓存/流量消峰
比如双十一的并发量达到了2亿每秒,但是业务系统的处理速度只有1000万每秒。
请求的数量远远超过了系统的承受能力,此时系统就会宕机,奔溃。
如果使用消息队列去接收这些请求,把它们都缓存在消息队列中,系统只需要按自己的处理速度去消费数据即可。
只是要多花点时间,但是保障了整个业务系统的可用性。
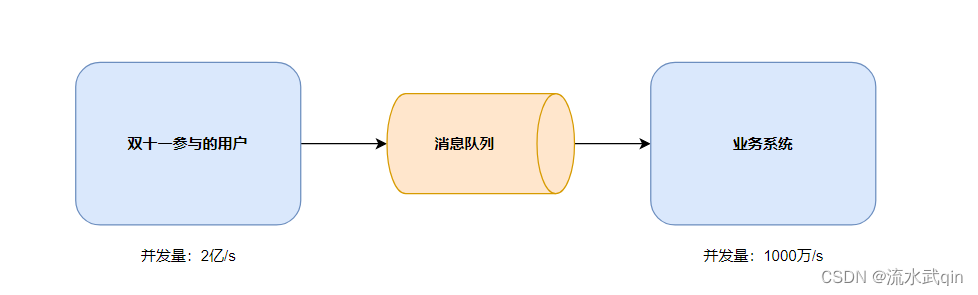
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
2)解耦
不管提供者端和消费者端如何变动,都不需要有多套实现。只需要和消息队列进行交互即可。
大大降低了系统的耦合度和开发成本。
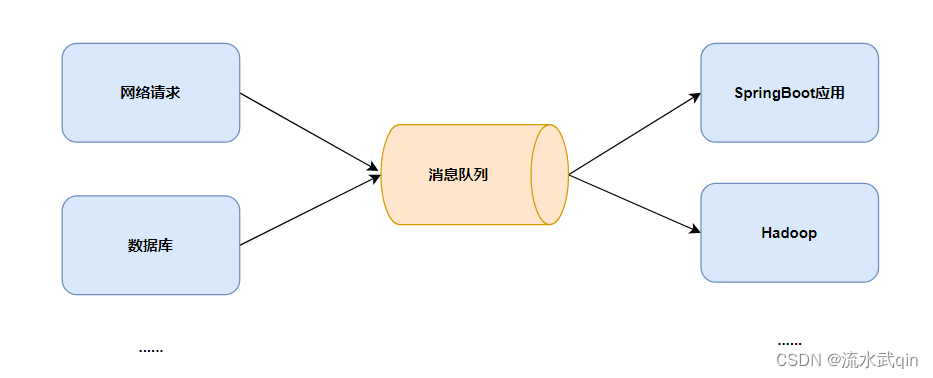
允许开发中独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
3)异步通信
比如一个充值流程,充值是最为重要的任务,必须保证立即执行,而发送短信相对来说不是那么重要的任务。
这样一来我们无需顺序执行充值和发送短信两个流程去增大系统的压力。
可以在充值成功之后把发短信的请求写入消息队列当中,让消费服务慢慢去消费这些请求。
即使消息丢失了,没有成功发送短信,也不会对核心业务(充值)造成影响,更不会造成系统异常。
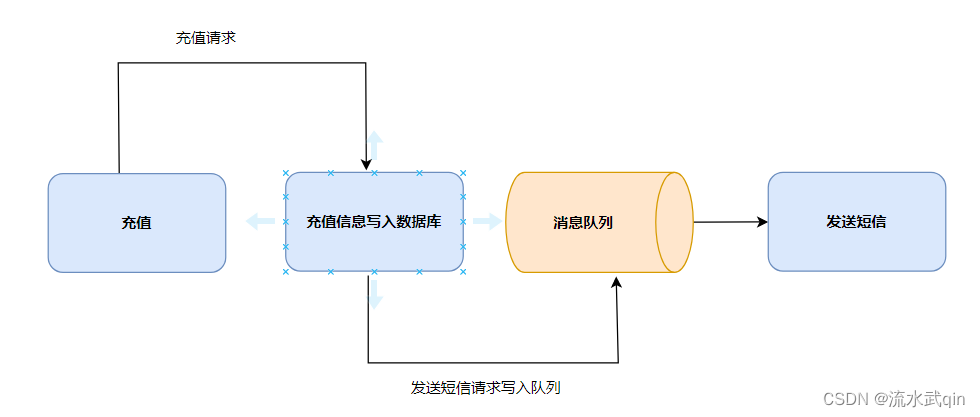
允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
二、Kafka的两种发布模式
2.1 点对点模式
消费者主动拉取数据,消息收到后清除消息。

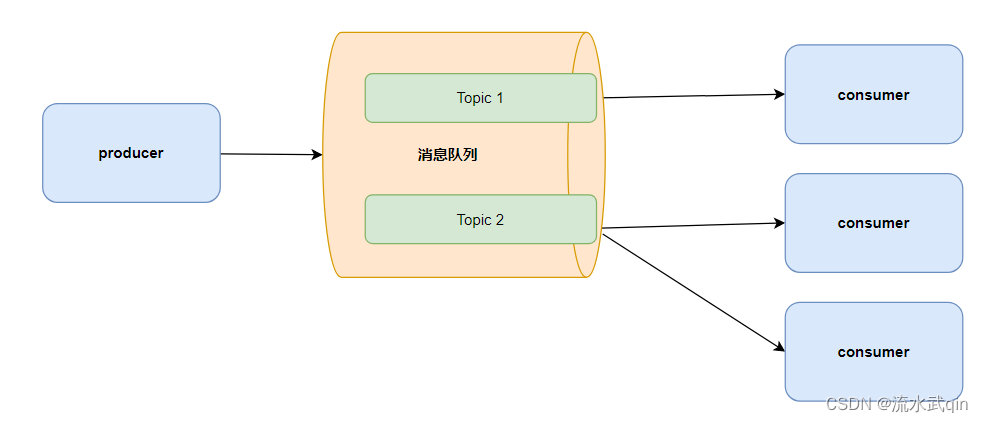
2.2 发布/订阅模式
可以有多个topic主题(浏览、点赞、收藏、评论等)
消费者消费数据之后,不删除数据,其它消费者还可以继续消费,至于什么时候删除数据,后面会处理。
因此每个消费者是相互独立的,都可以消费到数据。
由于这种模式更能适应更复杂的业务环境,所以多数情况都是使用发布订阅模式。
三、Kafka的基础架构
3.1 基础架构
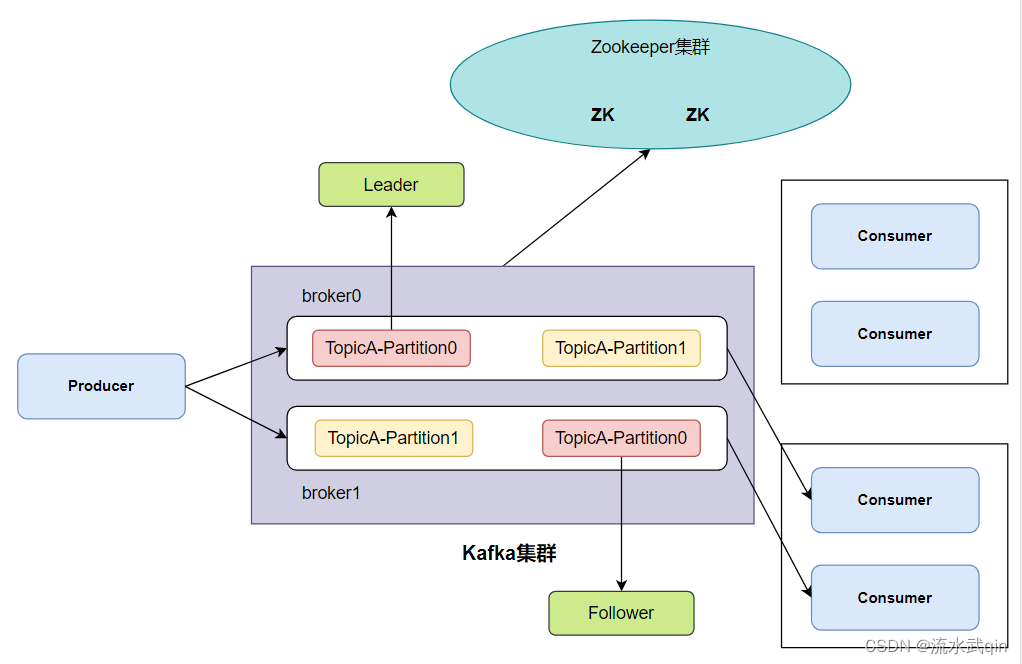
1.为方便扩展,并提高吞吐量,一个topic分为多个partition(分区),每个分区存储在不同的Kafka节点上。
分区的好处在于,如果一个Broker节点,只能存1T数据,但是此时数据量有2T,此时就可以使用分区,把数据
分别存储到两台Broker节点上。
2.配合分区的设计,提出消费者组的概念,组内每个消费者并行消费 。
3.为提高可用性,为每个partition增加若干副本,并且只有一个副本是Leader、其它都是Follower,消费者
只会消费Leader上的数据。如果Leader挂了,会有Follower当选为新的Leader。
4.ZK中记录谁是leader,但是Kafka2.8.0以后也可以配置不采用ZK,并且未来不使用ZK也是趋势,因为它已
经成为了Kafka的一道瓶颈。
3.2 角色说明
Producer:消息生产者,就是向Kafka broker发消息的客户端。Consumer:消息消费者,向Kafka broker取消息的客户端。Consumer Group(CG):消费者组,由多个consumer组成。消费者组内每个消 费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费;消费者组之间互不 影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。Broker:一台Kafka服务器就是一个broker。一个集群由多个broker 组成。一个broker可以容纳多个topic。Topic:可以理解为一个队列,生产者和消费者面向的都是一个 topic。Partition:分区。为了实现扩展性,一个非常大的topic可以分布到多个broker(即服 务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。Replica:副本。一个topic的每个分区都有若干个副本,由一个Leader和若干个Follower组成。Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数 据的对象都是Leader。
列。Replica:副本。一个topic的每个分区都有若干个副本,由一个Leader和若干个Follower组成。Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数 据的对象都是Leader。Follower:每个分区多个副本中的“从”节点,实时从Leader中同步数据,保持和Leader数据的同步。Leader发生故障时,某个Follower会成为新的Leader。