基于发布和订阅的分布式消息系统
消息:Kfaka的数据单元称为消息,字节数组组成,是一条记录
批次:消息分批次写入Kafka,批次是一组消息,这组消息属于同一个主题和分区
> 分批次提高吞吐量,减少网络开销
> 时间延迟相对长
> 压缩批次数据,提升传输和存储能力
模式:消息的数据格式,数据格式的一致性消除读写操作之间的耦合性
主题:Kafka的消息通过主题进行分类,主题被分为多个分区,每个分区是一个提交日志(Commit Log About Transaction)。
分区:消息以追加的形式写入分区,先入先出的顺序读取,因为有多个分区,整个主题无法保证,分区可以保证顺序,分区可以存储在不同的服务器上

生产者和消费者
除了生产者和消费者,还有Connector API和Streams API
生产者
> 默认把同一个主题的消息均衡写入分区
> 也可以通过消息键和分区器实现向指定的分区写数据
> 分区器为键生成一个散列值,散列值映射到分区上,则同一个键的消息写到同一个分区
消费者
> 订阅一个或者多个主题,按照消息生成的顺序读取消息
> 偏移量是不断递增的整数值,记录消息是否被读取过,创建消息时,偏移量加到消息里,每个分区偏移量时唯一的,消费者把每个分区最后读取的消息偏移量保存在ZooKeeper或者Kafka中,关闭或者重启,读取状态不会消失
> 个人理解,这里的一个消费者并不是一个用户,而是订阅了相同主题的一批用户,为同一个主题下同一个分区的同一批用户记录偏移量
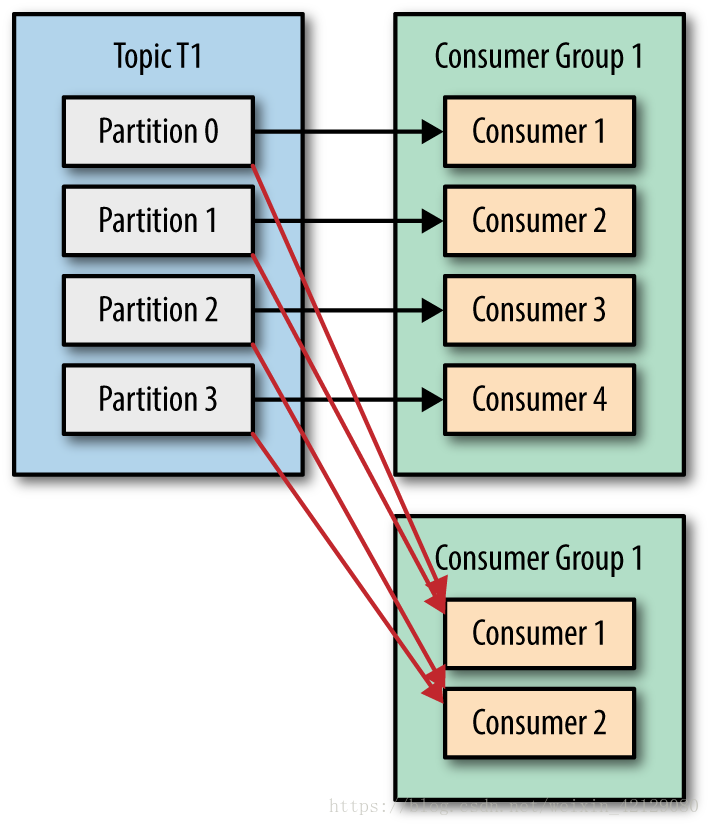
> 消费者是消费者群组的一部分,群组的多个消费者共同读取一个主题,保证每个分区被群组一个消费者使用,消费者与分区的映射关系叫所有权
> 不同的消费者群组可以读取同一个主题,但对于同一个群组中不同消费者不能读取相同分区
broker和集群
一个独立的Kafka服务器称为broker
> 接收来自生产者的消息,为消息设置偏移量,并提交消息到磁盘保存
> 为消费者提供服务,对读取请求作出响应,返回提交到磁盘上的消息
broker是集群的组成部分,集群中有一个broker是集群控制器
> 控制器负责管理工作,包括分区分配给broker和监控broker
> 分区从属于broker,该broker称为分区的首领。
> 分区可以分配给多个broker,分区复制,实现消息冗余,如果broker失效,其他broker可以接管分区。
保留消息
> 一定期限的消息保留策略
保留一定时间或者一定字节大小的消息,达到上限时,消息删除。
多集群
使用多集群的原因
1) 数据类型分离 2) 安全需求隔离 3) 多数据中心(灾难恢复)
Kafka消息复制机制只能在单个集群中进行,不能在多集群中进行
MirrorMaker工具可以实现集群之间消息复制,核心组件是一个生产者和一个消费者,两者通过队列相连,消费者从集群读取数据,生产者把消息发送到另一个集群