目录
一:常见数据结构介绍、Redis常见命令
1. Redis数据结构介绍
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样:
基本类型:String、Hash、List、Set、SortedSet

特殊类型:GEO、BitMap、HyperLog

Redis为了方便我们学习,将操作不同数据类型的命令也做了分组,在官网( https://redis.io/commands )可以查看到不同的命令:
通过官方文档查看

通过命令行进行查看(要先进入客户端)

2. Redis通用命令
通用指令是部分数据类型的,都可以使用的指令,常见的有:
①KEYS:查看符合模板的所有key;
②DEL:删除一个指定的key;
③EXISTS:判断key是否存在;
④EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除;
⑤TTL:查看一个key的剩余有效期;
通过help [command] 可以查看一个命令的具体用法,例如:

(1) KEYS:查看符合模板的所有key
不建议在生产环境设备上使用,因为模糊查询比较慢,数据多的话可能要搜很长时间;又因为redis是单线程,在搜索的这段时间内是无法执行其它的命令,被阻塞!
keys * #查看所有的key
keys a* #查看所有的以a开头的key
(2)DEL:删除一个指定的key
通过帮助文档查看

实操
①先使用mset批量插入数据(后面会讲)
mset key value key value.....
②进行删除操作:单个删除或者批量删除

(3)EXISTS:判断key是否存在
通过帮助文档查看

实操

(4)EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
通过帮助文档查看
expire是很常用的,redis是把数据存储到内存中的,如果长时间不清理内存肯定会被撑爆;所以对于验证码登录的验证信息等,我们可以设置存活时间,过一段时间就删除。

实操

(5)TTL:查看一个KEY的剩余有效期
通过帮助文档查看

实操
-1:代表此时的key有效期是永久;
-2:代表此时的key已经被删除了,不存在了;
①对于age字段没有设置有效期,结果就是-1,表示永久有效

②对于age字段设置有效期,有效期一直在自动减少,直到结果是-2,表示已经被删除、不存在

3. String类型
String类型,也就是字符串类型,是Redis中最简单的存储类型!
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
①string:普通字符串;
②int:整数类型,可以做自增、自减操作;
③float:浮点类型,可以做自增、自减操作;
总结:不管是哪种格式,底层都是字节数组形式存储,只不过是编码方式不同。
注:字符串类型的最大空间不能超过512m!

String类型的常见命令
①SET:添加或者修改已经存在的一个String类型的键值对;
②GET:根据key获取String类型的value;
③MSET:批量添加多个String类型的键值对;
④MGET:根据多个key获取多个String类型的value;
⑤INCR:让一个整型的key自增1;
⑥INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增;
注:改成负数就可以完成自减的操作;实际上有一个专门负责自减的decr!
⑦INCRBYFLOAT:让一个浮点类型的数字自增并指定步长;
⑧SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行;
注:注意set的区别,set添加时如果已存在会覆盖已有的值,而setnx是根本不会执行!实际上setnx是一个组合命令,setnx name jack,就等价于set name jack nx!
⑨SETEX:添加一个String类型的键值对,并且指定有效期;
注:setex就等价于先添加在设置有效期,也是一个组合命令,如:setex name 10 jack就等价于set name jack 和 expire name 10,或者合成一步:set name jack ex 10!
思考:Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key呢?
例如:需要存储用户、商品信息到redis,有一个用户id是1,有一个商品id恰好也是1,此时id是一样的,存入redis岂不是会产生冲突?
key的结构:Redis的key允许有多个单词形成层级结构,多个单词之间用':'隔开,格式如下:
项目名:业务名:类型:id
这个格式并非固定,也可以根据自己的需求来删除或添加词条;例如我们的项目名称叫 oa,有user和product两种不同类型的数据,我们可以这样定义key:
user相关的key:oa:user:1
product相关的key:oa:product:1
如果Value是一个Java对象,例如一个User对象,则可以将对象序列化为JSON字符串后存储:
| KEY |
VALUE |
| heima:user:1 |
{"id":1, "name": "Jack", "age": 21} |
| heima:product:1 |
{"id":1, "name": "小米11", "price": 4999} |
使用“冒号:”隔开,很自然的会形成层级结构!例如:存入以下数据
set hema:user:1 '{"id":1, "name":"Jack", "age": 21}'
set hema:user:2 '{"id":2, "name":"Rose", "age": 18}'
set hema:product:1 '{"id":1, "name":"小米11", "price": 4999}'
set hema:product:2 '{"id":2, "name":"荣耀6", "price": 2999}'此时通过命令行客户端界面,没有什么特殊之处,就是key长一些

但是我们打开图像界面客户端,就会发现是层级结构

4. Hash类型
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构!
(1)String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:
| KEY |
VALUE |
| heima:user:1 |
{name:"Jack", age:21} |
| heima:user:2 |
{name:"Rose", age:18} |
(2)Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:
| KEY |
VALUE |
|
| field |
value |
|
| heima:user:1 |
name |
Jack |
| age |
21 |
|
| heima:user:2 |
name |
Rose |
| age |
18 |
|
Hash类型的常见命令
①HSET key field value:添加或者修改hash类型key的field的值;
②HGET key field:获取一个hash类型key的field的值;
③HMSET:批量添加多个hash类型key的field的值;
④HMGET:批量获取多个hash类型key的field的值;
⑤HGETALL:获取一个hash类型的key中的所有的field和value;
⑥HKEYS:获取一个hash类型的key中的所有的field;
⑦HVALS:获取一个hash类型的key中的所有的value;
⑧HINCRBY:让一个hash类型key的字段值自增并指定步长;
⑨HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行;
①HSET key field value:添加或者修改hash类型key的field的值
hset heima:user:3 name lucy
hset heima:user:3 age 18注意是相同的key
注:相当于存储key和value,而value又是一个field和value,想要修改直接进行覆盖即可!

存储结构:

②HGET key field:获取一个hash类型key的field的值
hget heima:user:3 name
hget heima:user:3 age正常取值

③HMSET:批量添加多个hash类型key的field的值
注:实际上hset现在也可以批量添加,hmset和hset现在功能相同!
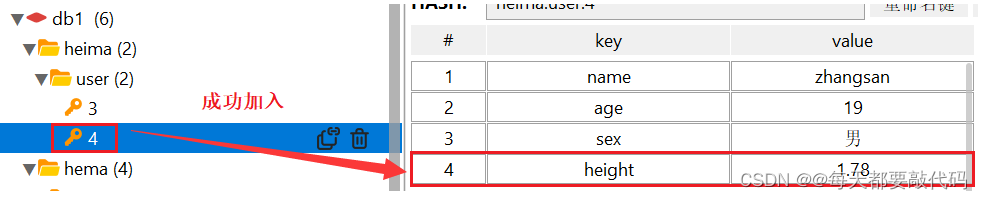
hmset heima:user:4 name zhangsan age 15 sex 男进行批量添加
![]()
存储结构:

④HMGET:批量获取多个hash类型key的field的值
hmget heima:user:4 name age sex批量获取

⑤HGETALL:获取一个hash类型的key中的所有的field和value
hgetall heima:user:4根据key获取value中的field+value

⑥HKEYS:获取一个hash类型的key中的所有的field
hkeys heima:user:4根据key获取value中的field

⑦HVALS:获取一个hash类型的key中的所有的value
hvals heima:user:4根据key获取value中的value

⑧HINCRBY:让一个hash类型key的字段值自增并指定步长
hincrby heima:user:4 age 2 #自增
hincrby heima:user:4 age -2 #自减根据key,设置value的field字段的增长步长

⑨HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
hsetnx heima:user:4 height 1.78复合命令,添加一个新的key的field值(不存在就添加,存在就不执行)
5. List类型
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构;既可以支持正向检索和也可以支持反向检索!
特征也与LinkedList类似:
①有序
②元素可以重复
③插入和删除快
④查询速度一般
注:常用来存储一个有序数据,例如:朋友圈点赞列表,评论列表等!
List类型的常见命令
①LPUSH key element ... :向列表左侧插入一个或多个元素
②LPOP key:取出、移除并返回列表左侧的第一个元素,没有则返回nil
③RPUSH key element ... :向列表右侧插入一个或多个元素
④RPOP key:取出、移除并返回列表右侧的第一个元素
⑤LRANGE key star end:返回一段角标范围内的所有元素
⑥BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

①LPUSH key element ... :向列表左侧插入一个或多个元素
lpush user 1 2 3 #从左边插入3个数据存储结构:是逆序的

②LPOP key :取出、移除并返回列表左侧的第一个元素,没有则返回nil;也可以指定具体的个数
lpop user #一个一个取
lpop user 2 #一下子取出两个,自己指定数量明面上是从左侧取出数据,也就是3和2

实际上也从列表中移除这两个数据了

注:既能取出数据又同时把这些数据移除!
③RPUSH key element ... :向列表右侧插入一个或多个元素
rpush user 4 5 6 #从右边插入3个数据存储结构:相当于一个横这的栈结构: 3<--2<--1(第一个数据)-->4-->5-->6

④RPOP key:取出、移除并返回列表右侧的第一个元素
rpop user 2 #取出右侧的两个数据从右侧取出两个数据,也就是6和5,同时也会从列表中移除

当没有数据可取时,就会返回nil 
⑤LRANGE key star end:返回一段角标范围内的所有元素
lrange user 2 4 #取出2-4角标范围的元素重新插入数据,此时数据如下:

角标下标是从0开始的,2-4就对应着1、4、5元素

⑥BLPOP和BRPOP:与LPOP和RPOP类似;在没有元素时等待指定时间,而不是直接返回nil
使用lpop取出数据
lpop users #取出一个数据对于一个列表中没有元素,使用LPOP取数据会返回nil

使用blpop取出数据
blpop users 10 #取出一个数据对于一个列表中没有元素,使用BLPOP取数据会进入阻塞状态

等待10秒过后,如果此列表中还没有元素,也会返回nil

思考1:如何利用List结构模拟一个栈?
栈是先进后出、后进先出的数据结构,并且入口和出口在同一边;所以就可以使用LPUSH、LPOP或者RPUSH、RPOP进行模拟实现!
思考2:如何利用List结构模拟一个队列?
队列是先进先出、后进后出的数据结构,并且入口和出口在不同边;所以可以使用LPUSH、RPOP或者RPUSH、LPOP进行模拟实现!
思考3:如何利用List结构模拟一个阻塞队列?
首先是队列,然后是阻塞;入口和出口在不同边,出队时采用BLPOP或BRPOP即可!
6. Set类型
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap;因为也是一个hash表,因此具备与HashSet类似的特征:
①无序;
②元素不可重复;
③查找快;
④支持交集、并集、差集等功能;
Set类型的常见命令
①SADD key member ... :向set中添加一个或多个元素
②SREM key member ... : 移除set中的指定元素
③SCARD key: 返回set中元素的个数
④SISMEMBER key member:判断一个元素是否存在于set中
⑤SMEMBERS:获取set中的所有元素
①SADD key member ... :向set中添加一个或多个元素
sadd s1 a b c #添加a b c元素执行结果

②SREM key member ... : 移除set中的指定元素
srem s1 a #移除指定的a元素执行结果
![]()
③SCARD key: 返回set中元素的个数
scard s1 #查看s1列表中的元素个数执行结果

④SISMEMBER key member:判断一个元素是否存在于set中
sismember s1 a #a已经删除了,返回0
sismember s1 b #b没有删除,返回1
执行结果

⑤SMEMBERS:获取set中的所有元素
smembers s1 #显示s1列表中的所有元素执行结果

⑥SINTER key1 key2 ... :求key1与key2的交集
⑦SDIFF key1 key2 ... :求key1与key2的差集
⑧SUNION key1 key2 ..:求key1和key2的并集
对于两个集合s1和s2

⑥SINTER key1 key2 ... :求key1与key2的交集
sinter s1 s2执行结果:

图解:

⑦SDIFF key1 key2 ... :求key1与key2的差集
sdiff s1 s2执行结果:
![]()
图解:
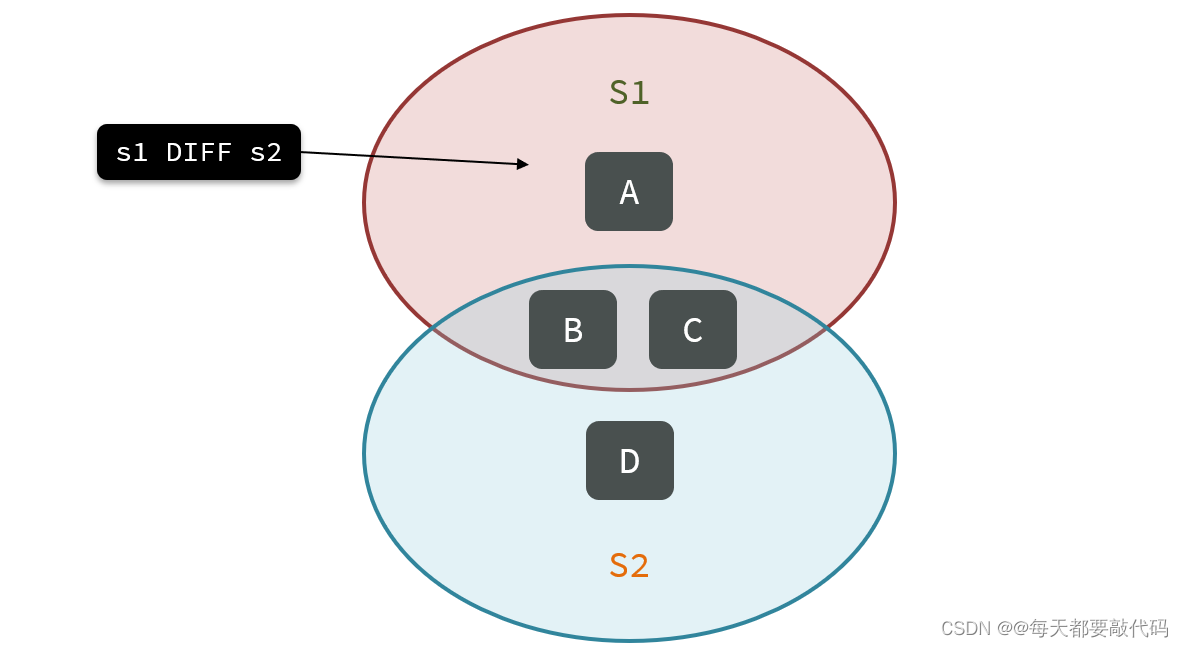
⑧SUNION key1 key2 ..:求key1和key2的并集
sunion s1 s2
执行结果:

Set命令的练习
将下列数据用Redis的Set集合来存储:
(1)张三的好友有:李四、王五、赵六;
(2)李四的好友有:王五、麻子、二狗;
①张三的好友有:李四、王五、赵六
sadd zhangsan lisi wangwu zhaoliu②李四的好友有:王五、麻子、二狗
sadd lisi wangwu manzi ergou利用Set的命令实现下列功能:
①计算张三的好友有几人
②计算张三和李四有哪些共同好友
③查询哪些人是张三的好友却不是李四的好友
④查询张三和李四的好友总共有哪些人
⑤判断李四是否是张三的好友
⑥判断张三是否是李四的好友
⑦将李四从张三的好友列表中移除
①计算张三的好友有几人
scard zhangsan②计算张三和李四有哪些共同好友
sinter zhangsan lisi #交集
③查询哪些人是张三的好友却不是李四的好友
sdiff zhangsan lisi #差集
④查询张三和李四的好友总共有哪些人
SUNION zhangsan lisi #并集⑤判断李四是否是张三的好友
SISMEMBER zhangsan lisi
⑥判断张三是否是李四的好友
SISMEMBER lisi zhangsan⑦将李四从张三的好友列表中移除
srem zhangsan lisi7. SortedSet类型
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大;SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表!
SortedSet具备下列特性:
①可排序
②元素不重复
③查询速度快
总结:因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能!
SortedSet类型的常见命令
①ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值;
②ZREM key member:删除sorted set中的一个指定元素;
③ZSCORE key member : 获取sorted set中的指定元素的score值;
④ZRANK key member:获取sorted set 中的指定元素的排名;
⑤ZCARD key:获取sorted set中的元素个数;
⑥ZCOUNT key min max:统计score值在给定范围内的所有元素的个数;
⑦ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值;
⑧ZRANGE key min max:按照score排序后,获取指定排名范围内的元素;
⑨ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素;
⑩ZDIFF、ZINTER、ZUNION:求差集、交集、并集;
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可!
SortedSet命令练习
将班级的下列学生得分存入Redis的SortedSet中:
Jack 85, Lucy 89, Rose 82, Tom 95, Jerry 78, Amy 92, Miles 76并实现下列功能:
①删除Tom同学
②获取Amy同学的分数
③获取Rose同学的排名
④查询80分以下有几个学生
⑤给Amy同学加2分
⑥查出成绩前3名的同学
⑦查出成绩80分以下的所有同学
①添加元素(分数在前,元素在后)
zadd stus 85 Jack 89 Lucy 82 Rose 95 Tom 78 Jerry 92 Amy 76 Miles插入的数据默认就是升序的

②删除Tom同学
zrem stus Tom执行结果:
![]()
③获取Amy同学的分数
zscore stus Amy执行结果:
![]()
④获取Rose同学的排名(前面我们已经删除了Tom)
升序排:默认就是升序排,我们知道Rose是第3名,返回2,是从0开始的下标!
![]()
降序排:加上REV就是降序排,删除了Tom,应该是第四名,返回的应该是3
![]()
⑤获取stus中所有元素的个数
zcard stus执行结果:前面删除了Tom,此时肯定就只有6个了
![]()
⑥查询80分以下有几个学生
zcount stus 0 80 #根据分数范围查人数执行结果:
![]()
⑦查出成绩后3名、前3名的同学
zrange stus 0 2 #后三名,根据排名范围,查具体的人
zrevrange stus 0 2 #前三名执行结果:
注:后3名也就是0-2,是升序排的,就是前3个分数最低的人

注:前3名,需要我们加上rev降序排,就是前3个分数最高的人

⑧给Amy同学加2分
zincrby stus 2 Miles #分数在前,元素在后;负数就是减分
执行结果:原来是76,增加2
![]()
⑨查出成绩80分以下的所有同学
zrangebyscore stus 0 80 #根据分数范围,查具体的人执行结果:

图书推荐
本期图书:《算法精粹:经典计算机科学问题的Java实现 》
无论何种软件开发问题,都有可能已经有了解决方案。本书收集了非常有用的解决方案,可以指导你学习那些经过千锤百炼的解决问题的技术。本书介绍的原则和算法可以保证你在一个又一个的项目中节省大量的时间。
本书包含50多个练习,这些练习是多年来一直在计算机科学课堂中使用的。你可以通过实践这些例子来探索核心算法、约束问题、人工智能应用等。
本书主要内容包括:
①递归、记忆化和位操作。
②搜索、图和遗传算法。
③约束满足问题。
④k均值聚类、神经网络和对抗搜索。

快速了解入口:
感兴趣的小伙伴可以可以通过以下链接进行了解或购买:算法精粹:经典计算机科学问题的Java实现(基于Java 11)
参与方式:
本次送书暂定 1 本,超过1000浏览量加送一本!
活动时间:截止到 2023-04-23 00:00:00。抽奖方式:利用程序进行抽奖。
参与方式:关注博主(只限粉丝福利哦)、点赞、收藏,评论区随机抽取,最多三条评论!