前言
YOLACT是经典的单阶段、实时、实例分割方法,在YOLOv5和YOLOv8中的实例分割,也是基于 YOLACT实现的,有必要理解一下它的模型结构和设计思路。
论文:YOLACT: Real-time Instance Segmentation
开源地址:https://github.com/dbolya/yolact

YOLACT(You Only Look At CoefficienTs)
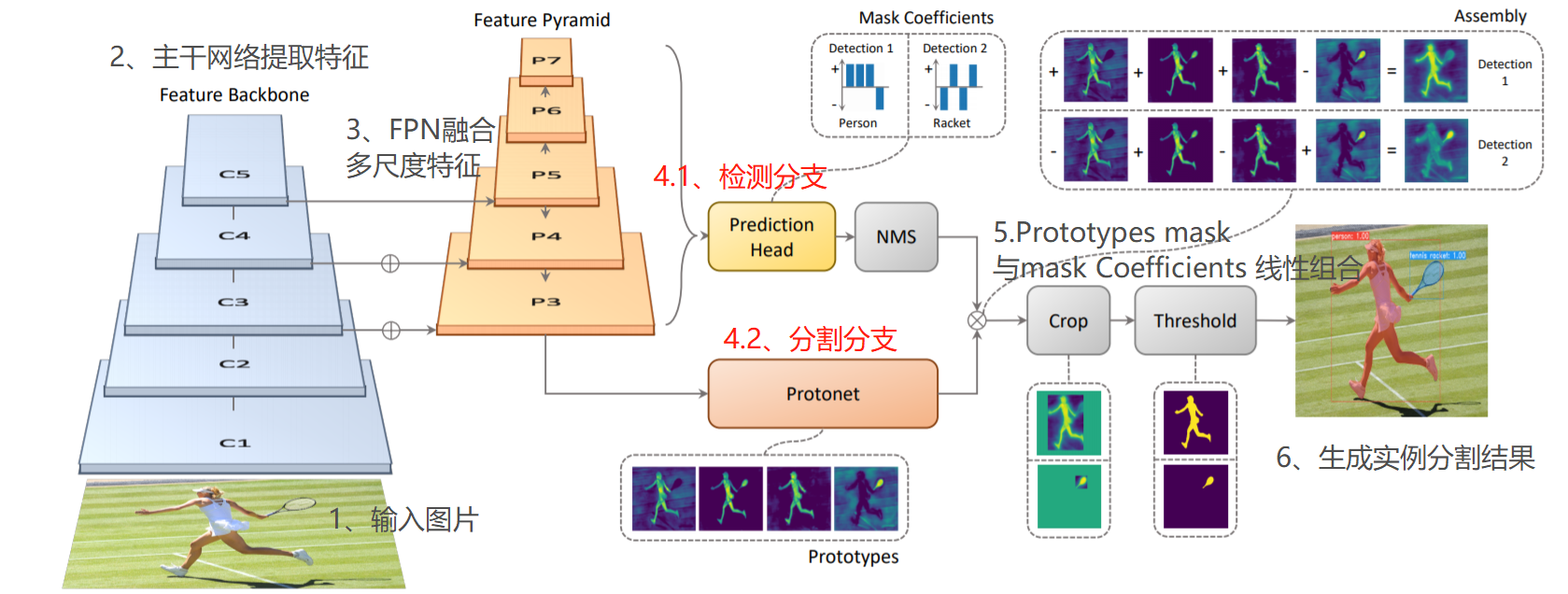
一、模型框架
它对于one-stage 单阶段模型,添加了一个mask分支(与检测分支并行),整体模型结构如下图,流程思路:
1、输入图片;
2、通过主干网络对图片,进行特征提取;
3、经过FPN特征金字塔,对不同尺寸的特征图进行融合;
4.1、检测分支,对于每个目标物体,都输出类别、边框信息(x,y,w,h)、k个mask Coefficients(mask的的置信度,取值1或-1);
4.2、分割分支,针对当前输入图片,输出k个Prototype(mask原型图);不同图片,输出的Prototype有差异,但数量也是k个。
5、对于每个目标物体,将k个mask Coefficients(mask的的置信度)与k个Prototype(mask原型图)进行相乘,然后将所有结果相加,得到该目标物体的实例分割结果。
二、YOLACT 主要特点
YOLACT 主要特点是将实例分割任务,划分为两个并行任务:
- 将实例分割任务,划分为两个并行任务;(目标检测Detect、实例分割mask 是并行计算的,这样设计的网络是单阶段的,适合YOLO系列,速度快)
- 在实例分割分支生成k个mask原型图(prototype masks),检测分支生成k个mask原型图的置信度(mask coefficients),然后将mask原型图与mask原型置信度进行线性组合,生成实例分割结果。
- 比如在一张街道场景的图片,图中有行人、车辆、建筑物、树木等,当检测分支框中的是行人,那么行人相关的mask原型图置信度高(头、身体、手、脚、随身物品等的位置、轮廓、编码位置敏感的方向等原型图),其它的类别mask原型图置信度低,这样组合形成实例分割的结果。
这里重点讲一下prototype masks
【1】YOLACT 实际上是学习了一种分布表示,在一张图片中可能有多个类别,但不同类别之间的物体共享 prototypes 的组合
在 prototype 空间
- 某些 prototypes 对图片空间分块,
- 某些 prototypes 定位实例,
- 某些 prototypes 检测实例廓形,
- 某些 prototypes 编码位置敏感的方向图(position-sensitive directional maps)等等,
- 这些 prototypes 的组合构成了最终的分割结果.
【2】每一个prototype mask是生成的相对于整张图片的,不是局部的
如下图所示,生成的prototype mask是对于整张图片的;

【3】prototype masks 的数量与物体类别无关(如,类别数量可能多于 prototypes 的数量);
YOLACT 是针对每张图片学习 prototypes,即:不同图片生成的prototypes会有差异;
区别于对整个数据集所学习的全局共享的 prototypes.
比如在 BoF(Bag of Feature) 中,是对整个数据集所学习的全局共享的 prototypes.
BOF 是一种图像特征提取方法,其实际上起源于文本领域的 BoW(Bag of Words) 模型. BoW 假定对于一个文本而言,忽略其词序、语法、句法等,仅看作是一个个词语的组合,每个词的出现都是相互独立的,不依赖于其它词的出现.
BOF 假设图像相当于一个文本,图像中的不同局部区域或特征可以看作是构成图像的词汇(codebook). 如图:

根据得到的图像的词汇,统计每个单词的频次,即可得到图片的特征向量,如图:
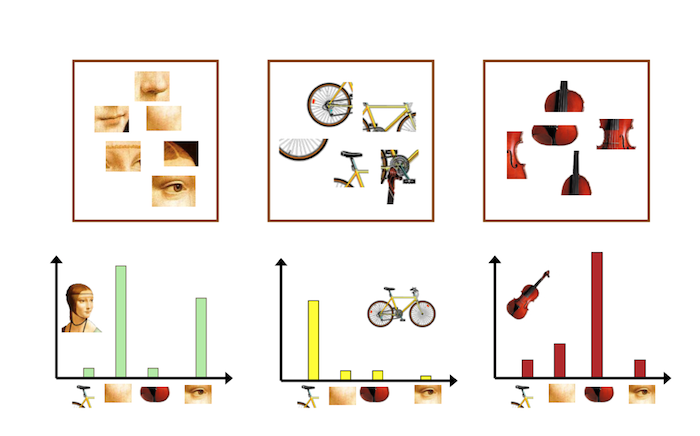
YOLACT 是针对每张图片学习 prototypes,而 BOFs 是对整个数据集所学习的全局共享的 prototypes.
参考:https://www.aiuai.cn/aifarm1190.html
三、模型组件结构
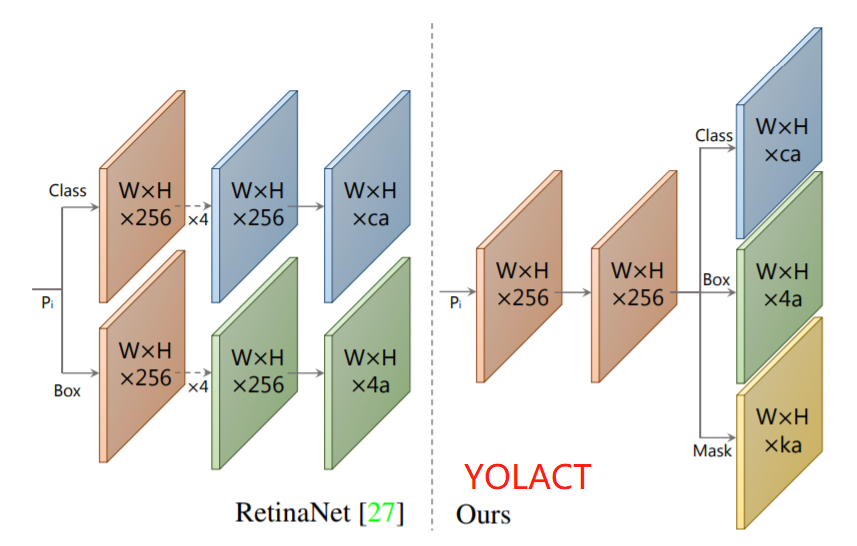
3.1 目标检测 分支
通常的YOLO系列目标检测器包含两个预测输出分支
- 一个分支,预测 c 个类别置信度
- 另一个分支,预测 4 个边界框回归值
对于YOLACT模型,添加一个分支,来预测k个mask Coefficients(mask的的置信度,取值1或-1)每个 coefficient 分别对应一个 prototype
这样“目标检测”分支,预测的信息包括:类别、边框信息(x,y,w,h)、k个mask Coefficients
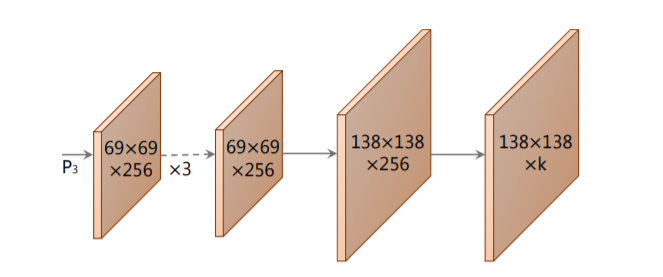
3.2 实例分割 分支
YOLACT 的 “实例分割”(protonet) 会输出整张图片的 k 个 prototype masks 集合.
首先看看“实例分割”分支中,通过什么操作生成prototype的:
1、“实例分割”分支中,输入是FPN中的P3特征图,该特征图分辨率高,更好保留空间细节信息;同时融合了一定的语义信息。
2、然后对特征图进行上采样,中间没有跳跃连接、特征融合之类的,朴素的FCN结构;(这部分有待改进)。
3、再通过1*1卷积调整特征图的通道数量为k,这样就形成了k个Prototype(mask原型图)
需要注意:这个分支不会计算损失;而且在线性组合后最终的 mask loss,才计算损失。
3.3 Mask 线性组合
对于每个目标物体,将k个mask Coefficients(mask的的置信度)与k个Prototype(mask原型图)进行相乘,然后将所有结果相加,并再接 sigmoid 非线性函数,生成最终的 masks;这样就得到该目标物体的实例分割结果。
其中的计算公式如下:
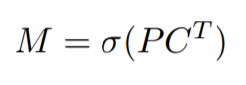
- P是k个Prototype mask,维度是h*w*k
- C是k个mask Coefficients,维度是n*k,这里n是指检测分支中,预测出n个目标物体了
是指sigmoid函数
首先对k个mask Coefficients,进行转至,调整维度为k*n;
然后k个Prototype mask与k个mask Coefficients相乘,h*w*k和k*n,得到维度为h*w*n的特征图
最后对特征图进行sigmoid处理,这样就得到n目标物体的实例分割结果了
四、损失函数
模型主要由物体类别损失、边框回归损失、mask分类损失,三部分组成模型损失函数。
物体类别损失 采用二分类交叉熵损失(BCE),判断物体类别;因为输出特征图,c个类别,对应有c个通道;每个通道的特征图,分别判断类别是否和标签的一样,是或不是,二分类即可。
边框回归损失 采用IOU损失。
其中的mask分类损失,是使用二分类交叉熵损失(BCE)进行计算
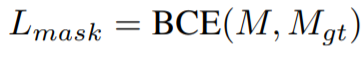
一张图片可能有多个物体;对于每个物体,模型生成一张实例分割结果的特征图,我们通过逐个像素判断,该像素是否属于当前的物体,进行计算整张图片的损失情况。
五、模型效果
在 COCO test-dev 数据集,基于单张 Titan Xp 显卡,模型性能对比:
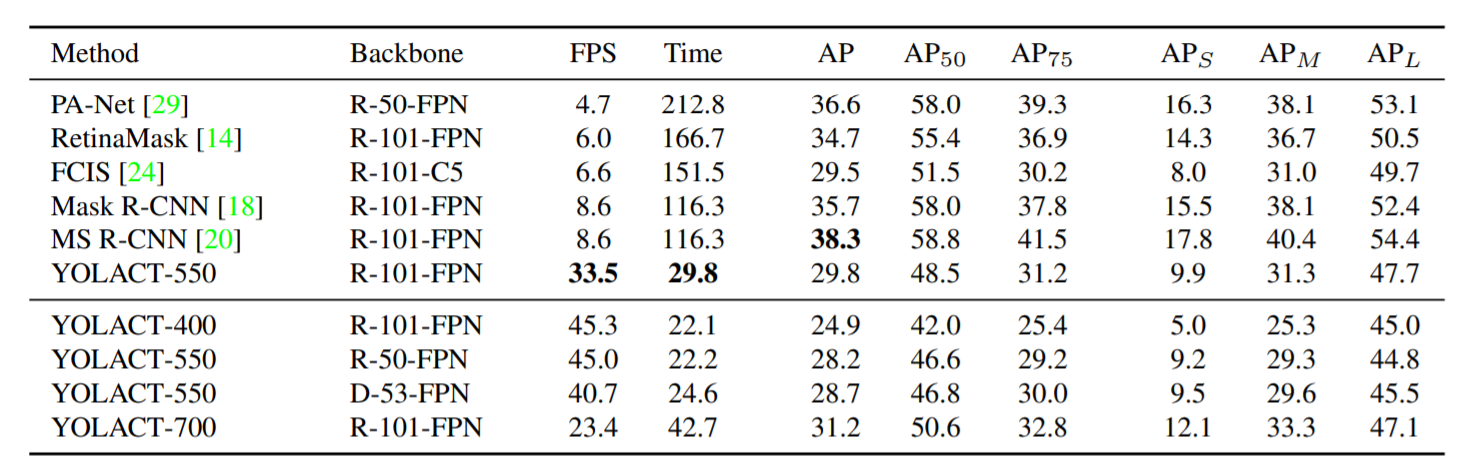
模型效果:

细节信息对比:

分享完成~
本文只供大家参考与学习,谢谢~