GPU计算
NVIDIA公司发布的CUDA是建立在GPU上的一个通用并行计算平台和编程模型,CUDA编程可以利用GPU的并行计算引擎来更加高效地解决比较复杂的计算难题。GPU的并行计算最成功的一个应用就是深度学习领域。
GPU通常不作为一个独立运行的计算平台,而需要与CPU协同工作,它可以看成是CPU的协处理器,因此GPU的并行计算实际上是指基于CPU和GPU的异构计算架构,GPU和CPU之间通过PCIe总线连接在一起来协同工作。CPU的运算核心较少,但其可以实现复杂的逻辑运算,因此其适合控制密集型任务,而且CPU上的线程是重量级的。GPU的运算核心较多,其特别适合数据并行的计算密集型任务,其线程是轻量级的。基于CPU和GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行计算程序,GPU主要处理数据密集型的并行计算程序,从而发挥最大的功效。
GPU硬件资源
在硬件上,GPU的资源包括SP和SM。
- SP:最基本的处理单元,streaming processor,也称为CUDA core。具体的指令和任务都是在SP上处理的。GPU进行并行计算,也就是很多个SP同时进行运算。我们所说的几百核心的GPU值指的都是SP的数量;
- SM:多个SP加上其他的一些资源组成一个streaming multiprocessor。也叫GPU大核,其他资源如:warp scheduler,register,shared memory等。SM可以看做GPU的心脏(对比CPU核心),register和shared memory是SM的稀缺资源。CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力。
每个SM包含的SP数量依据GPU架构而不同,Fermi架构GF100是32个,GF10X架构是48个,Kepler架构是192个,Maxwell架构是128个,Turing架构是64个。
GPU软件资源
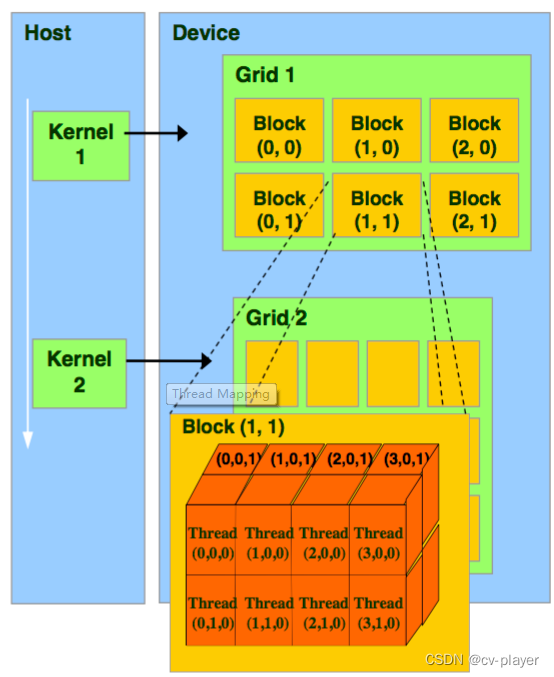
从软件上看,即GPU的线程模型,可以分为Grid、Block、Thread和Warp。
- Thread:一个CUDA的并行程序会被以许多个threads来执行。
- Block:若干个threads组成一个block,同一个block中的threads可以同步,也可以通过shared memory通信。
- Grid:若干个blocks可以组成Grid。
- Warp:GPU执行程序时的调度单位,同一个warp里的线程执行相同的指令,即SIMT。
GPU存储资源
每一个Thread都有自己的local memory和resigters,每一个Block有shared memory,这个Block中的所有Thread都可以访问,Grid之间会有Global memory和Cache,所有的Grid都可以访问。
CUDA编程
CUDA提供了多种编程语言支持,如C/C++、Python、Fortran等。
CUDA编程工具:
- 编译器:nvcc
- 调试器:nvcc-gdb
- 性能分析:nsight、nvprof。
CUDA编程模型是一个异构模型,它假设系统是由一个主机和一个设备组成的,而且各自拥有独立的内存,CPU所在位置称为主机端(host),而GPU所在位置称为设备端(device)。一个CUDA程序即包含host程序,也包含device程序,CUDA程序在运行时可以分配和释放设备上的内存,并且在主机内存和设备内存之间进行传输,在设备上运行核函数。
典型的CUDA编程包括以下五个流程:
- 分配GPU内存,并进行数据的初始化;
- 从CPU内存中拷贝数据到GPU内存中;
- 调用CUDA的核函数来完成指定的计算;
- 将数据从GPU内存中拷贝回CPU内存中;
- 释放GPU内存。