MySQL
理论知识
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
索引的底层是一颗B+树,那么联合索引当然还是一颗B+树,只不过联合索引的健值数量不是一个,而
是多个。构建一颗B+树只能根据一个值来构建,因此数据库依据联合索引最左的字段来构建B+树。
https://www.bilibili.com/video/BV1Ca411d7RM?p=6&vd_source=aa05fb870c31dea69394e3d1beb9e83c
更多msyql知识可以听一下这个课
例子:假如创建一个(a,b)的联合索引,那么它的索引树是这样的
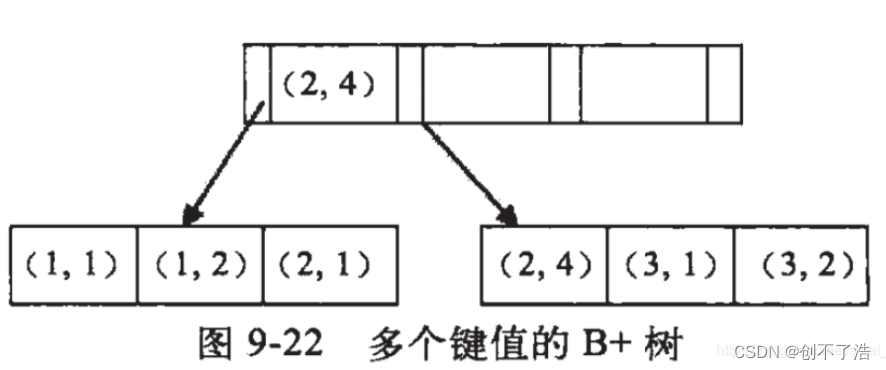
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
实例代码
在mytest数据库下创建Student表
use mytest;
drop table if exists `student`;
create table `student`
(
`id` int not null auto_increment,
`name` varchar(50) not null,
`number` varchar(20) not null,
`address` varchar(100),
`age` int default 0,
primary key (`id`)
)Engine=InnoDB DEFAULT CHARSET=utf8;
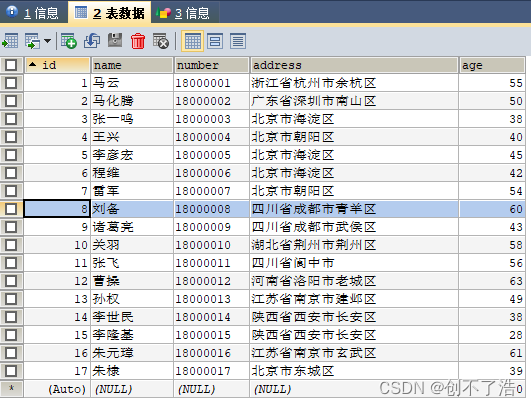
insert into student (`name`, `number`, `address`, `age`)
values
("马云", "18000001", "浙江省杭州市余杭区", 55),
("马化腾", "18000002", "广东省深圳市南山区", 50),
("张一鸣", "18000003", "北京市海淀区", 38),
("王兴", "18000004", "北京市朝阳区", 40),
("李彦宏", "18000005", "北京市海淀区", 45),
("程维", "18000006", "北京市海淀区", 42),
("雷军", "18000007", "北京市朝阳区", 54),
("刘备", "18000008", "四川省成都市青羊区", 60),
("诸葛亮", "18000009", "四川省成都市武侯区", 43),
("关羽", "18000010", "湖北省荆州市荆州区", 58),
("张飞", "18000011", "四川省阆中市", 56),
("曹操", "18000012", "河南省洛阳市老城区", 63),
("孙权", "18000013", "江苏省南京市建邺区", 49),
("李世民", "18000014", "陕西省西安市长安区", 38),
("李隆基", "18000015", "陕西省西安市长安区", 28),
("朱元璋", "18000016", "江苏省南京市玄武区", 61),
("朱棣", "18000017", "北京市东城区", 39);
explain的使用

关于SQL查询是否用到索引,使用explain关键字查询SQL语句性能,具体可以参考这篇文章
https://blog.csdn.net/qq_27198345/article/details/116382587
查询非索引信息
EXPLAIN SELECT name, address FROM student WHERE address LIKE "北京市%";

我们可以看到没有使用任何的索引,type为ALL,查询rows为17,说明为全表扫描。
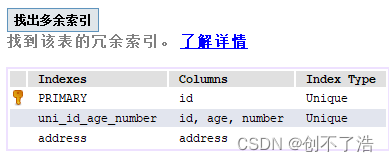
Student表创建单一的索引
创建地址索引
alter table student add index (address(9));
再进行查询进行性能分析
EXPLAIN SELECT name, address FROM student WHERE address LIKE "北京市%";

我们发现possible_keys有address但是实际的key没有!!! 这点我与我参考的博文有出入,可能不同版本的mysql,我的是5.7。这位博主的用到了索引。大家理解下就行了,用到了索引就查询的更快。而且虽然name在前,address在后不影响使用单一索引。 这个和联合索引的顺序要区别开。 下面有不含id联合索引,注意看区别。

Student表上创建联合索引
CREATE UNIQUE INDEX uni_id_age_number ON student(id,age,number)

验证联合索引
我这个稍微不太严谨的地方把主键id作为联合索引,因为mysql底层默认会建立一个id为索引的B+树,因为id已经能够区分每一行,所以就算使用联合索引他也会只使用id的索引来查询。大家能够理解这个意思就行了。如果使用非id列作为联合索引,底层则会另外生成一个非id的联合索引。这也是为什么数据量很大上亿级别的数据,不太建议搞索引的原因。但其实他们都满足最左匹配的规则。如果想要做实验可以自己手动多插入一列,来对比一下。
1 全值匹配查询
EXPLAIN SELECT * FROM student WHERE id = 10 AND age = 58 AND number = 18000010
用到了索引,where子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序 ,因为使用了id为索引,所以只用到了一个id索引,没用联合索引。我们试一下不用id作为联合索引效果有啥不一样。

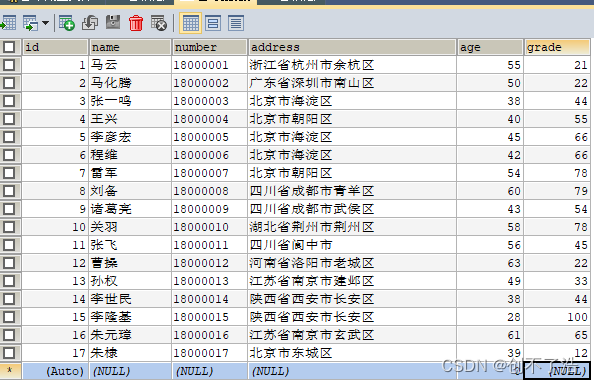
添加一列作为联合索引
ALTER TABLE student ADD grade INT(4);
手动添加数据后如下,本来想直接插入一行数据,发现比较麻烦,直接手动输入了。 可以看下这篇文章 联结两个表新加一列数据。
MySQL:向已有数据表中插入新的一列数据
https://blog.csdn.net/Yvettre/article/details/80239531
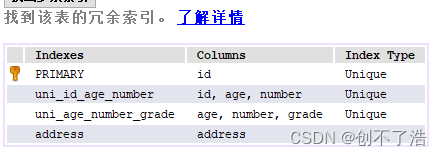
创建联合索引(不包含id)
CREATE UNIQUE INDEX uni_age_number_grade ON student(age,number,grade)
全值匹配查询时
不使用id作为联合索引,就用了联合索引
EXPLAIN SELECT * FROM student WHERE grade = 78 AND age = 58 AND number = 18000010

2匹配左边的列时
EXPLAIN SELECT * FROM student WHERE id = 10
EXPLAIN SELECT * FROM student WHERE id = 10 AND age = 58
EXPLAIN SELECT * FROM student WHERE id = 10 AND age = 58 AND number = 18000010


都从最左边开始连续匹配,用到了索引
直接查询age和number则不会使用到索引。
EXPLAIN SELECT * FROM student WHERE age = 58

EXPLAIN SELECT * FROM student WHERE number = 18000010

EXPLAIN SELECT * FROM student WHERE age = 58 AND number = 18000010

这些没有从最左边开始,最后查询没有用到索引,用的是全表扫描 。
不连续时只用到id的索引,age和nuber都没用到
EXPLAIN SELECT * FROM student WHERE id = 10 AND number = 18000010

EXPLAIN SELECT * FROM student WHERE age = 58 AND grade = 78

这个也有所出入,用到了索引。各个版本的mysql有点区别。

3 匹配列前缀
正常是这样的,如果列是字符型的话它的比较规则是先比较字符串的第一个字符,第一个字符小的哪个字符串就比较小,如果两个字符串第一个字符相通,那就再比较第二个字符,第二个字符比较小的那个字符串就比较小,依次类推,比较字符串。
如果a是字符类型,那么前缀匹配用的是索引,后缀和中缀只能全表扫描了
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As'//全表查询
select * from table_name where a like '%As%'//全表查询
创建user1表,不把name设为key 则没有使用索引
CREATE TABLE `user1` (
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` VARCHAR(255) DEFAULT NULL COMMENT '姓名',
`age` INT DEFAULT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
#KEY `idx_name` (`name`) ##删除这句话like 不能使用索引
) ENGINE=INNODB COMMENT='用户表';

加上name作为索引后使用了索引。

4匹配范围查询
select * from table_name where a > 1 and a < 3
可以对最左边的列进行范围查询
select * from table_name where a > 1 and a < 3 and b > 1;
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引,在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤
5精确匹配某一列范围匹配另外一列
如果左边的列是精确查找的,右边的列可以进行范围查找
select * from table_name where a = 1 and b > 3;
a=1的情况下b是有序的,进行范围查找走的是联合索引
6排序
颠倒顺序的没用到索引
