近期,在交流群中有网友谈到SQL Server索引的最左匹配原则,理解为T-SQL中Where条件的书写顺序的问题,这是一个误解。
下面先看下实验结果。
1 、准备数据。
CREATE TABLE [dbo].[t6](
[id] [int] IDENTITY(1,1) NOT NULL,
[hour] [int] NULL,
[ordernumber] [int] NULL,
CONSTRAINT [PK_t6] PRIMARY KEY CLUSTERED ( [id] ASC ) ON [PRIMARY]
) ON [PRIMARY]
GO
insert into t6 values(default,default)
-- 重复执行如下语句,生成10+M记录
insert into t6 select id, hour from t6
update t6 set
hour=id % convert(int,300000*RAND()+2), ordernumber=id % convert(int,3000*RAND()+2)
2 、创建索引1。http://u48582907.b2bname.com/
create index fhsy1 on t6(hour, ordernumber)
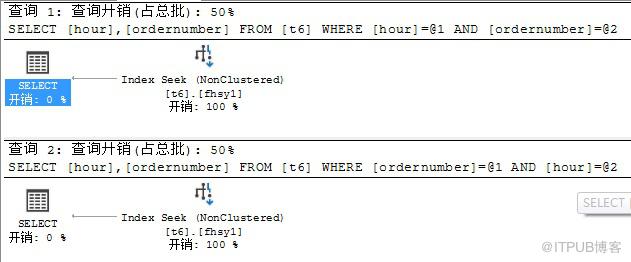
3 、查看两个字段均为等值查询的执行计划。
select hour,ordernumber from t6 where hour=1 and ordernumber=1
select hour,ordernumber from t6 where ordernumber=1 and hour=1

4 、创建索引2。
create index fhsy1 on t6(ordernumber, hour)
5 、再次查看执行计划。


6 、再看一下一个字段为等值,另一个字段为范围查询的执行计划。
select hour,ordernumber from t6 where hour=1 and ordernumber between 1 and 2
select hour,ordernumber from t6 where ordernumber between 1 and 2 and hour=1


select hour,ordernumber from t6 where ordernumber=1 and hour between 1 and 2
select hour,ordernumber from t6 where hour between 1 and 2 and ordernumber=1


结论
1 、索引的最左匹配,是指的检索条件与索引字段的关系,与在T-SQL语句中Where条件中的书写顺序无关。
索引与搜索条件的书写顺序有关,这在上世纪可能还有可能;现在的数据库引擎的智能化程序,应该可以通过智能优化或语句改写,实现顺序无关。这一点都做不到,这个数据库离淘汰就不远了。郑州不孕不育医院:http://yyk.39.net/zz3/zonghe/1d427.html
2 、从Cost来看,索引总是匹配等值检索字段在前的复合索引,这就是被称为 最左匹配原则 的原因。
3 、最左匹配索引的执行计划,是Index Seek/Scan,即先通过等值条件进行定位,再通过不等条件进行范围扫描。一般来说,此执行计划要优于Index Scan,即整个索引的扫描。
疑惑
在等值查询中,CBO会自动选择一个Cost最小的执行计划,索引1和索引2相当,最终执行计划选择索引2而不是索引1,原因不明。应该和索引树的高度、统计信息有关。待查。