复合索引及最左匹配原则探究
一、概述
上一篇文章中介绍了B+树是如何根据索引构造出来的以及如何使用索引去查询数据的,不知道你有没有发现,那些例子都是某一列作为索引,比较好理解,而今天,我们将要说的是多个列组成的索引是什么样子的,以级其使用的规则。
二、联合索引是长什么样子的?
如果说只有一个列,那么匹配起来是非常简单的,我们只需要对一个列的值不断地进行比较就可以了,但是如果是多个列的话,可能就需要比较多次了。
在利用多个列构建一个B+树的时候,是按照一定的逻辑顺序来构建的。这个逻辑就像是Java中对象的compareTo方法,在比较两个对象是否相等的时候,会去比较他们某些属性是否相等。肯定是先比较属性A,如果相等再比较属性B,以此类推,如果都相等了才说明一样,这里需要注意的是按照顺序,你不能先比较B再比较A。对于联合索引,你可以把它当成一个由多个字段值作为属性所组成的对象,然后在你进行查找的时候会调用它的compareTo方法去比较。
在利用复合索引进行查找的时候最需要注意的就是比较的顺序!
下面我们来看看复合索引长什么样的,以及是如何查找数据的
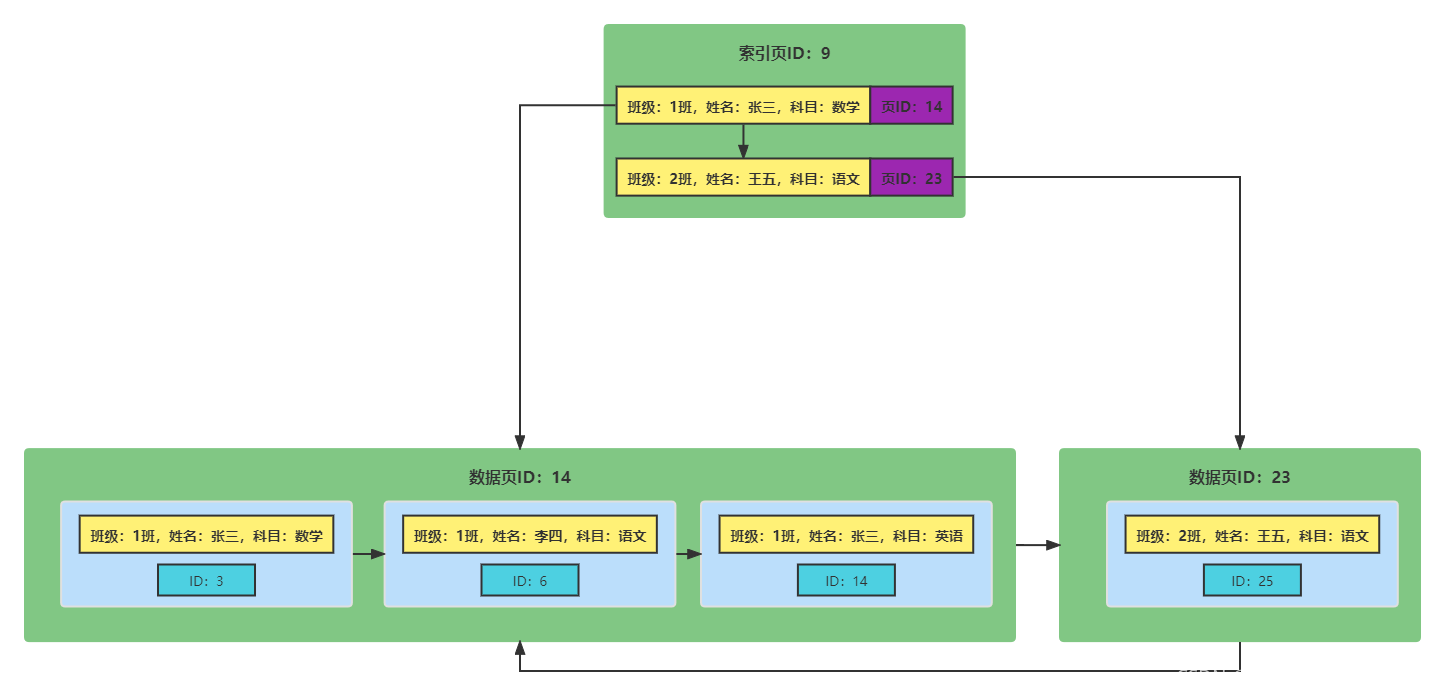
假设当前有这样一个表,有id,班级,姓名,科目,成绩等字段,现在使用"班级,姓名,科目"这三个字段
组成复合索引,大概就是上图的样子。黄色部分的就是复合索引,你可以把它当成一个整体来看。现在我们要查找1班的张三同学的英语成绩,我们首先根据班级来到数据页14,到数据页之后可以根据页目录进行二分查找,也可沿着单向链表进行遍历,总之,在比较的时候发现班级一样之后就会去比较姓名,然后又发现有两条数据,此时再比较科目,最终找到了ID:14,然后利用id去聚簇索引进行回表查询,然后就得到了想要的数据。
三、如何建立和使用复合索引
下面是建立联合索引的SQL语句案例
CREATE TABLE test (
id INT NOT NULL,
col1 CHAR(30) NOT NULL,
col2 CHAR(30) NOT NULL,
col3 CHAR(30) NOT NULL,
col4 CHAR(30) NOT NULL,
PRIMARY KEY (id),
INDEX name (col1,col2,col3)
);
从SQL语句可以看得出来,现在我们根据col1、col2、col3建立了一个连个索引,记住这个顺序,在进行比较的时候至关重要!
下面是可以使用这个索引的SQL语句:
SELECT * FROM test WHERE col1 = 'xxxx';
SELECT * FROM test WHERE col1 = 'xxxx1' and col2 = 'xxxx2'
SELECT * FROM test WHERE col1 = 'xxxx1' and col2 = 'xxxx2' and col3 = 'xxxx3';
SELECT * FROM test WHERE col1 = 'xxxx1' and col2 = 'xxxx2' and (col3 = 'xxxx3' or col3 = 'xxxx4');
SELECT * FROM test WHERE col1 = 'xxxx1' and col2 = 'xxxx2' and (col3 > 'xxxx3' or col3 < 'xxxx4');
下面的SQL语句是没有用到上面的索引的
SELECT * FROM test WHERE col1 = 'xxxx1' or col2 = 'xxxx2' or col3 = 'xxxx3'
最左匹配原则:
如果你细心的话,应该可以看得出来上面两类SQL语句的区别,第一类SQL语句在Where条件中是按照建立索引时的顺序去使用的,而第二类则不是,因为or语句对于MySQL来说是没有顺序可言的。
对于与复合索引,MySQL的优化器是使用最左匹配原则来执行查找操作的,就上面的例子,在whre语句中你就可以用(col1),(col1, col2)以及 (col1, col2, col3)三种方式来进行查找,当然,前提是按照索引的顺序。对于where条件里只有(col1)或者(col1, col2)的情况,复合索引能做的就是帮我们尽可能的缩小搜索范围。
( 注:一个索引最多可以包含 16 列。)
四、覆盖索引是什么?
还是继续用上面的例子,假设现在有下面这个SQL语句:
SELECT col1,col2,col3 FROM test WHERE col1 = 'xxxx1' and col2 = 'xxxx2' and col3 = 'xxxx3';
现在我们要查询的数据正好就在组成复合索引的字段当中,当我们在复合索引中找到数据页之后就可以直接在数据页中获取我们需要的数据,而不需要进行回表操作,这个就是覆盖所有,所以在很多情况下,都不太建议使用select *的写法,一方面是会消耗I/O,另一方面就是无法使用到覆盖索引的操作,换句话说就是会执行大量的回表操作。
五、总结
以上就是本篇的全部内容了,向大家介绍了复合索引以级最左匹配原则的由来,其实这个所谓的最左匹配原则就是复合索引进行搜索时的比较逻辑。
后面还介绍了覆盖索引,这也提醒了我们,在平时写SQL语句时可以去留一下是否可以用到这种方法,并且尽可能少些select *来占用I/O。
如果本篇文章有的地方讲解的有问题或者有需要补充的,欢迎在评论指出,大家共同进步!