1 Spark内存模型
Spark在一个Executor的内存分为三块,
1. 一块是execution内存
2. 一块是Storge 内存
3. 一块是其他内存- 执行内存是执行内存,加入,聚合都是在这部分内存中执行.shuffle的数据也会先缓存在这个内存中,满了再写入磁盘,能减少IO,其实地图过程也是在这个内存中执行的。
- Storge内存是存储broadcast,cache,persist数据的地方
- 其他内存是程序执行时预留给自己的内存(执行代码的时候使用)
execution和Storage是Spark Executor中的内存大户,other占用内存相对较少很多。在Spark-1.6.0以前的版本,execution和Storage的内存是固定分配的,使用的参数spark.shuffle.memoryFraction(execution内存占用Executor总内存大小的的0.2默认值)和spark.storage.memoryFraction(Storage内存占Executor内存的0.6),因为1。6。0以前这两块内存是相互隔离的,这导致了Executor的内存利用率不高,而且需要根据Application的具体情况,使用者自己可以调节这两个参数才能优化Spark的内存使用。在Spark1.6.0以上的版本,execution内存和Storage内存可以互相借用,提高了内存的Spark中内存的使用率,同时也减少了OOM的情况。
1.6版本
| Tables | Are | Cool |
|---|---|---|
| spark.memory.useLegacyMode | false | 是否启用Spark 1.5以前使用的传统内存管理模式。遗留模式严格地将堆空间分割成固定大小的区域,如果应用程序未被调整,可能导致过度溢出。除非启用以下不建议使用的内存分数配 spark.shuffle.memoryFraction spark.storage.memoryFraction spark.storage.unrollFraction |
| spark.shuffle.memoryFraction | 0.2 | (不建议使用)这是只读的,如果spark.memory.useLegacyMode启用。在洗牌过程中用于聚合和cogroup的Java堆的分数。在任何给定时间,用于混洗的所有内存映射的总体大小受限于此限制,超出此限制内容将开始溢出到磁盘。如果泄漏经常发生,请考虑增加此值,代价为 spark.storage.memoryFraction。 |
| spark.storage.memoryFraction | 0.6 | (不建议使用)这是只读的,如果spark.memory.useLegacyMode启用。用于Spark内存缓存的Java堆的分数。这不应该比JVM中的“旧”一代对象大,默认情况下这个对象的堆为0.6,但如果您配置自己的旧一代大小,则可以增加它。 |
| spark.storage.unrollFraction | 0.2 | (不建议使用)这是只读的,如果spark.memory.useLegacyMode启用。spark.storage.memoryFraction用于在内存中展开块的分数。这是通过在没有足够的可用存储空间来整体展开新块时删除现有块来动态分配的。 |
具体请看: Spark的StaticMemoryManager
在Spark1.6.o以后加入了堆外内存,进一步优化了Spark的内存使用,堆外内存使用了JVM堆以外的内存,不会被gc回收,可以减少频繁的full gc,所以在Spark程序中,会长时间逗留在Spark程序中的大内存对象可以使用堆外内存存储。使用堆外内存存储有两种方式。
1. 一种是在RDD调用persist的的时候传入参数StorageLevel.OFF_HEAP,这种使用方式需要配合Tachyon一起使用。
2. 另外一种是使用Spark自带的spark.memory,offHeap.enabled设置为true使用,但是这种使用方式在1。6。0版本还不支持使用,只是多了这个参数,以后的版本会开放。
OOM的问题通常出现在execution这块内存中,因为Storage这块内存在存放数据满了之后,会直接丢弃内存中旧的数据,对性能有影响但是不会又=有OOM的问题。
1.6.0的内存

1.6版本的上面两个是0.75,下面占用0.25,如果没有shuffle,那么storge会借用executor的内存。
2.0以后的内存

详情请看:Spark的UnifiedMemoryManager
2.执行流程
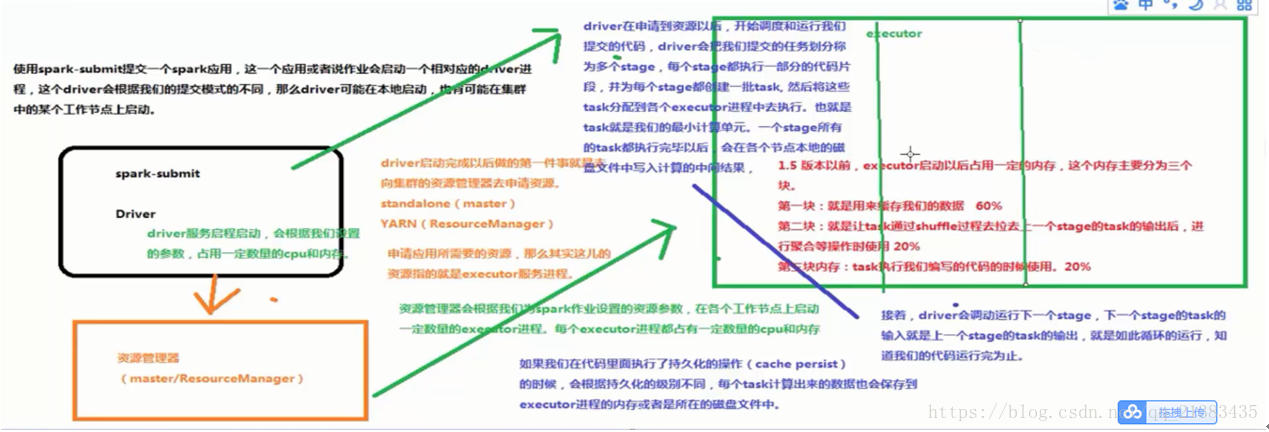
3.资源调优
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上启动相应数量的Executor进程。这个参数非常重要,如果不设置的话,默认只会给你启动少量的Executor,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行设置一般设置50-100个左右的Executor进程比较合适,设置太少或者太多的Executor进程都不好。设置太少,无法充分利用集群资源;设置太多,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存,Executor内存的大小,很多时候直接决定了Spark作业的性能。而且常常跟常见的JVM OOM异常,也有直接的关系。
参数调优建议:每个Executor进程的内存设置为4G-8G比较合适,但是这只是一个参考值。 具体的设置还是要根据俄不同部门的资源队列来确定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,就代表了你的Spark作业申请到的总内存量(也就是所以Executor进程的内存总和)。这个量是不能超过队列的最大内存量的。此外,如果你是跟你团队里的其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3-1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core 核数,这个参数决定了每个Executor进程并执行task线程的能力,因为每个CPU core同一时间只能执行一个task线程,因此每二个Executor进程的CPU core数量越多,越能够快速的执行完分配给自己的所有task线程。
参数调优建议:Executorde cpu core核数一般设置为2-4个比较合适。同样得根据不同部门的资源队列来定。可以看看自己的资源队列最大的CPU core限制是多少,再根据设置的Executor数量,来决定每个Executor进程可以分配到的几个CPU core,同样建议,如果你是跟你团队里的其他人共享这个资源队列,那么申请的总内存量最好不要超过资源队列最大总内存的1/3-1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了,唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉去到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
spark.default.parallelism
参数说明:该参数用于设置每个stage的默认task数量,这个参数极为重要,如果不是指可能会直接影响你的Spark作业性能。
参数调优建议:Spark作业的默认task数量为500-1000个比较合适。很多同学经常烦的一个错误是不去设置这个参数,那么此时就会导致Spark自己根据底层的HDFS的block块的数量来设置task的数量,默认是一个HDFS block块对应一个task,通常的来说,spark默认设置的数量是偏少数的(比如就十几个task),如果task数量偏少的话,就会导致你前面设置好的Executor的参数都前功尽弃。是想一下,无论你的Executor进程有几个,内存和CPU有多大,但是task只有一个或者10个,那么90%的Executor进程可能根本就没有task执行,也就白白的浪费了资源。因此Spark官网建议的设置原则是:该参数为num-executors*executor-cores的2-3被=倍比较合适,比如Executor的总CPUcore数量为300个,那么设置1000个task是可以的,此时可以充分利用Spark集群的资源(一个Cpu core对应2-3个Task)
Spark.storage.memoryFraction

spark.shuffle.memoryFraction
