Spark基础性能调优
做推荐算法相关的工作时,数据量是非常大的,我们学习Spark就很有必要。不同的写法性能是不相同的,偶然间发现美团点评技术团队的博客(首页 - 美团点评技术团队)已经有人分享过Spark性能优化指南,解决了我很多疑惑,避免遗忘对它进行整理,总的来说优化方案主要分为开发调优、资源调优、数据倾斜调优、shuffle调优四个部分。
开发调优
最基本的Spark性能优化,就是要优化你的代码。Spark中rdd内部的转换关系是一个DAG(有向无环图),只有出发了action 算子才开始计算。开始可以画出计算pipeline,写得多了脑子自然会形成计算的pipeline,在开发过程中,时时刻刻都要注意一些性能优化的基本原则。
原则一:避免创建重复的RDD,尽可能复用同一个RDD
对于同一份数据不要创建多个RDD,对不同的数据执行算子操作时要尽可能地复用一个RDD。
原则二:对多次使用的RDD进行持久化
前面已经提到Spark中rdd内部的转换关系是一个DAG,因此对于一个RDD执行多次算子时,都会重新从源头处计算一遍,这种方式的性能是很差的。如下图所示,其中D和E代表action算子,在计算D和E时要分别从A开始计算。
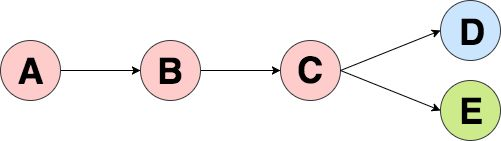
最好的方法就是对C进行持久化,此时Spark就会将数据保存到内存或者磁盘中,以后每次对C这个RDD进行算子操作时,都会直接从内存或磁盘中提取持久化的RDD数据,不会从源头处重新计算一遍
尽量避免使用shuffle类算子
Spark作业运行过程中,最消耗性能的地方就是shuffle过程。shuffle过程就是将分布在集群中多个节点上的同一个key,拉取到同一个节点上,进行groupby或join等操作,reduceByKey、join、distinct、repartition等都属于shuffle算子。
shuffle顾名思义就是被打散,是否被shuffle就看计算后对应多少分区,那么:
1.如果一个RDD的依赖的每个分区只依赖另一个RDD的同一个分区,就是narow,如图上的map、filter、union等,这样就不需要进行shuffle,同时还可以按照流水线的方式,把一个分区上的多个操作放在一个Task里进行。
2.如果一个RDD的每个分区需要依赖另一个RDD的所有分区,就是wide,如图上的groupbykey,这样的依赖需要进行shuffle,运算量倍增。
原则四:使用预聚合的shuffle操作
如果有些时候实在无法避免使用shuffle操作,那么尽量使用可以预聚合的算子。预聚合就是在每个节点本地对相同的key进行一次聚合操作,多条相同的key被聚合起来后,那么其他节点再拉取所有节点上的相同key时,就会大大减少磁盘IO以及网络传输开销。下图所示,每个节点本地首先对于相同key进行了聚合。

原则五:使用高性能的算子
除了shuffle相关的算子有优化原则之外,其他的算子也都有着相应的优化原则,不一一陈述。
资源调优
在spark-submit时可以为作业配置合适的资源,理论上来说资源给的越多任务执行得越快,但集群又不是你家的,侵占太多资源可能会被kill掉。摩拜的Spark部署在集群上,公司内部共享这些资源,Spark的SparkContext先把任务提交到YARN上,再由Application Master创建应用程序,然后为它向Resource Manager申请资源,并启动Executor来运行任务集,同时监控它的整个运行过程,直到运行完成。

资源相关的参数
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/31/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
给出本次项目执行时所给的资源,还是比较省的,这个可以根据集群的情况进行调整。
spark-submit \
--master yarn \
--executor-memory 8G \
--num-executors 16 \
--executor-cores 2
数据倾斜调优
数据倾斜就是大部分执行得很快,个别任务执行得很慢。比如进行groupby的时候,某个key对应的数据量特别大,就会发生数据倾斜。
shuffle过程会导致数据倾斜,可能会触发数据倾斜的shuffle算子包括distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等,因此能很快定位导致数据倾斜的代码。
遇到数据倾斜时通常会使用repartition这个转换操作对RDD进行重新分区,重新分区后数据会均匀分布在不同的分区中,避免了数据倾斜。
