监控告警
• 部署Alertmanager
• 配置Prometheus与Alertmanager通信
• 在Prometheus中创建告警规则
• 告警状态
Alertmanager如何工作
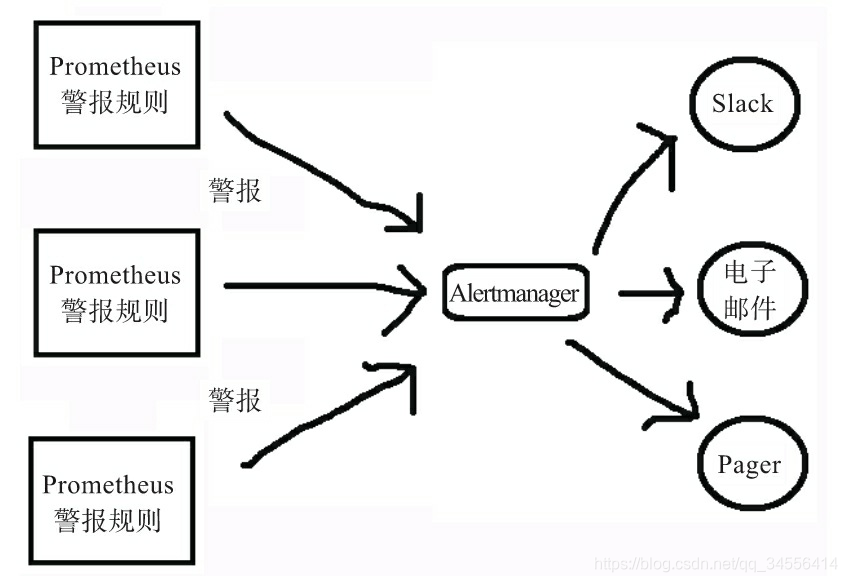
Alertmanager处理从客户端发来的警报,客户端通常是Prometheus服务器(如图所示)。它还可以接收来自其他工具的警报。Alertmanager对警报进行去重、分组,然后路由到不同的接收器,如电子邮件、短信或SaaS服务(PagerDuty等)。
部署Alertmanager

要实现告警通过altermanager这个组件完成的,必须告诉普罗米修斯altermanager是谁,到时候评估高级规则里面触发了阈值好把告警事件推送给altermanager,然后进入其自己内部的处理逻辑,处理完之后发送到接收人。
在altermanager里面还需要配置接收人,分组,收敛
[root@localhost system]# pwd
/usr/lib/systemd/system
[root@localhost ~]# tar xf alertmanager-0.21.0.linux-amd64.tar.gz
[root@localhost ~]# mv alertmanager-0.21.0.linux-amd64 /usr/local/alertmanager
[root@localhost system]# systemctl daemon-reload
[root@localhost system]# systemctl start alertmanager.service
[root@localhost system]# cat alertmanager.service
# vi /usr/lib/systemd/system/grafana.service
[Unit]
Description=alertmanager
[Service]
ExecStart=/usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml
ExecReload=/bin/kill -HUP $MAINPID
KillMode=process
Restart=on-failure
[Install]
WantedBy=multi-user.target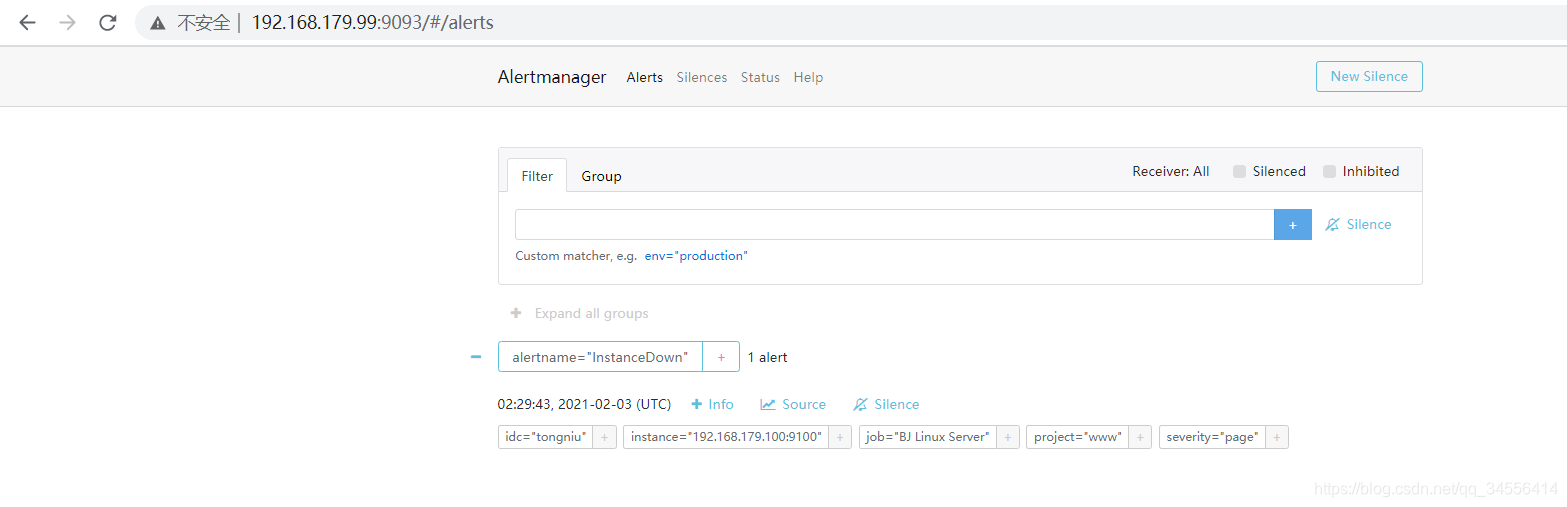
配置Prometheus与Alertmanager通信
alerting:
alertmanagers:
- static_configs:
- targets:
- 127.0.0.1:9093配置告警规则也是在普罗米修斯这里进行配置
配置Alertmanager
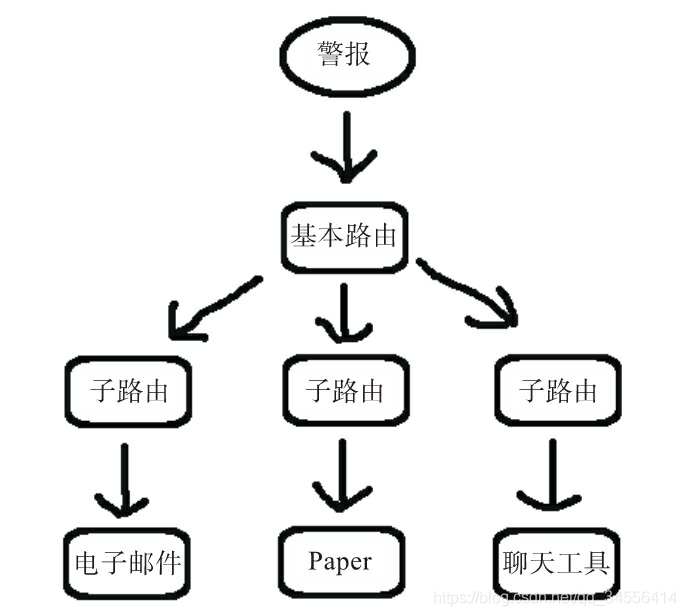
接下来,我们看看route块,它会告诉Alertmanager如何处理特定的传入警报。警报根据规则进行匹配然后采取相应的操作。你可以把路由想象成有树枝的树,每个警报都从树的根(基本路由或基本节点)进入(如图所示)。除了基本节点之外,每个路由都有匹配的标准,这些标准应该匹配所有警报。然后,你可以定义子路由或子节点,它们是树的分支,对某些特定的警报感兴趣,或者会采取某些特定的操作。例如,来自特定集群的所有警报可能由特定的子路由处理。
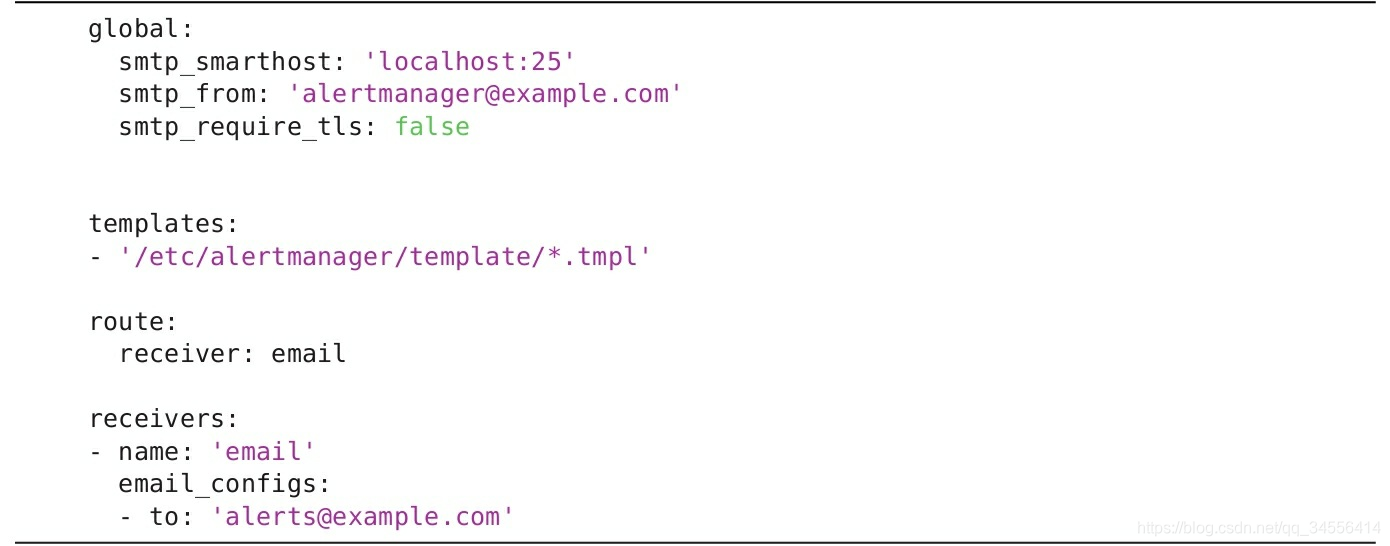
修改altermanager的配置文件
分组的概念:将类似的指标分组,比如说监控linux服务器会监控其负载,资源负载就是一个分组,这个分组下面会有cpu的指标,内存的指标。
rules.yml: |
groups:
- name: kubernetes
rules:
- alert: KubernetesNodeReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 1
for: 30s
labels:
severity: critical
annotations:
summary: Kubernetes Node ready (instance {
{ $labels.instance }})
description: "Node {
{ $labels.node }} has been unready for a long time\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "{
{ $labels.instance }} stop"
description: "{
{ $labels.instance }}:job{
{ $labels.job }} stop"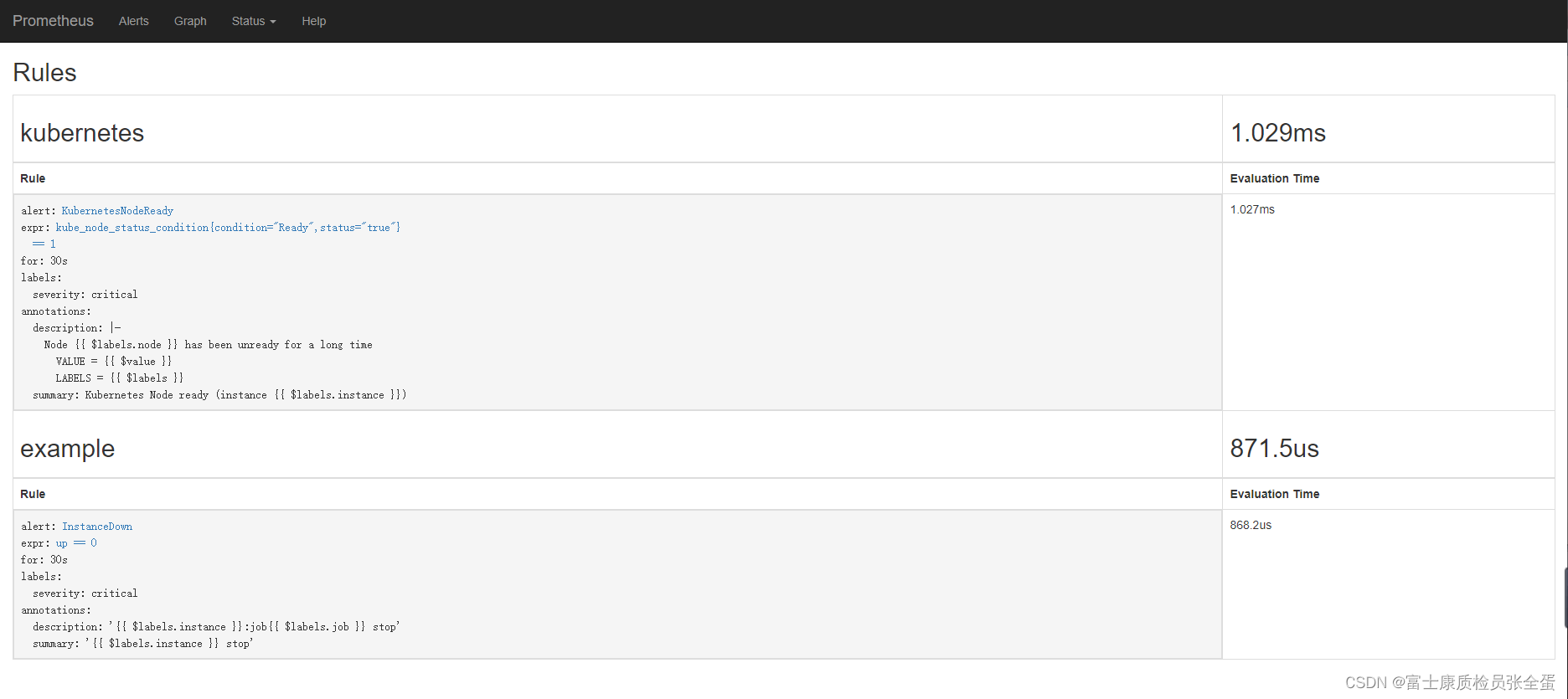
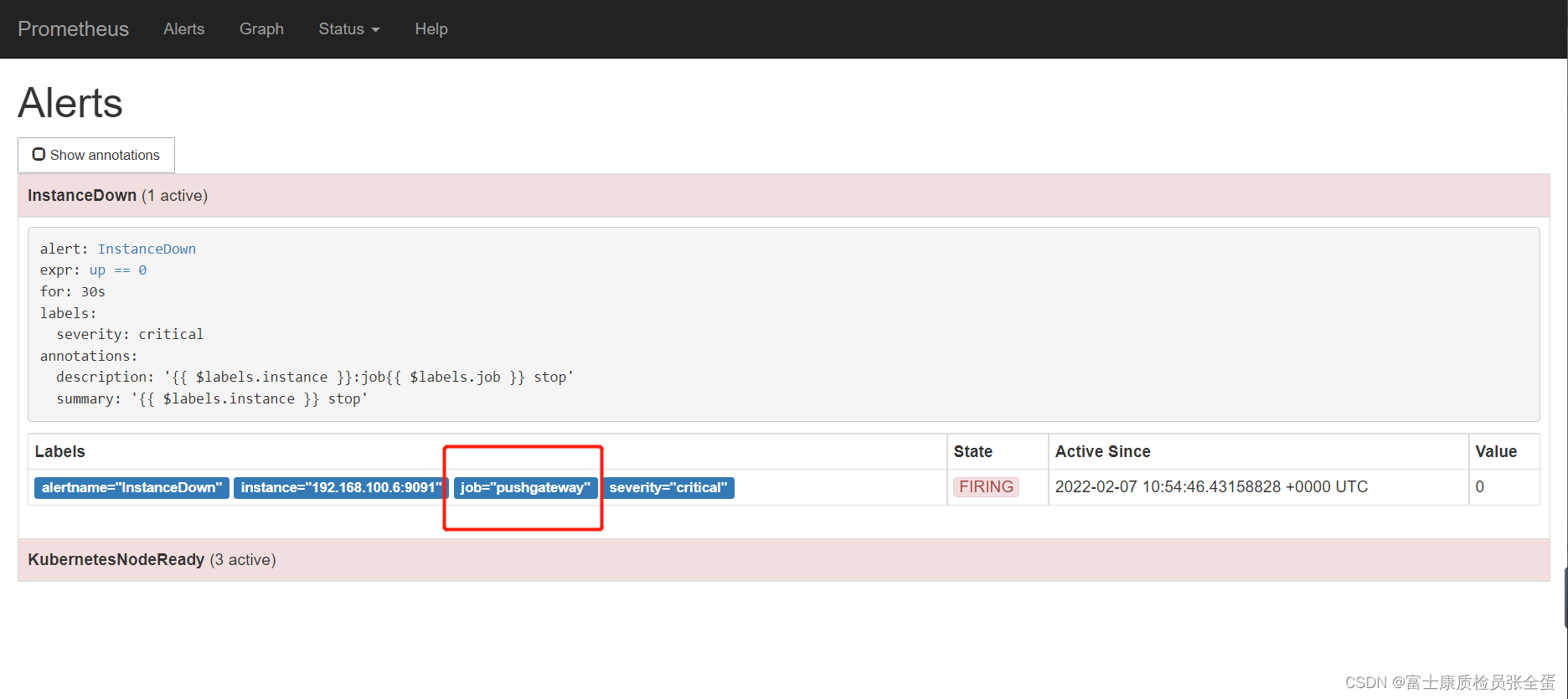
每个告警也不是每个人都需要收到,这个时候就需要根据指标当中的不同标签发送给不同的人,这下面加了一个routes节点,在这下面有两块的接收人,根据不同的标签发给不同的项目组的人,总之就是通过标签去匹配。Altermanager根据指标当中的标签匹配发送到不同的收件人。
一个是对告警进行分组,一个routes根据标签发送给不同的人。
route:
group_by: [alertname]
group_wait: 10s
group_interval: 10s
repeat_interval: 100m
receiver: default
routes:
- receiver: email
group_wait: 15s
match:
job: pushgateway
receivers:
- name: 'default'
webhook_configs:
- url: 'http://192.168.100.5:8060/dingtalk/cluster1/send'
send_resolved: true
- name: 'email'
email_configs:
- to: '[email protected]'
send_resolved: true
~ 

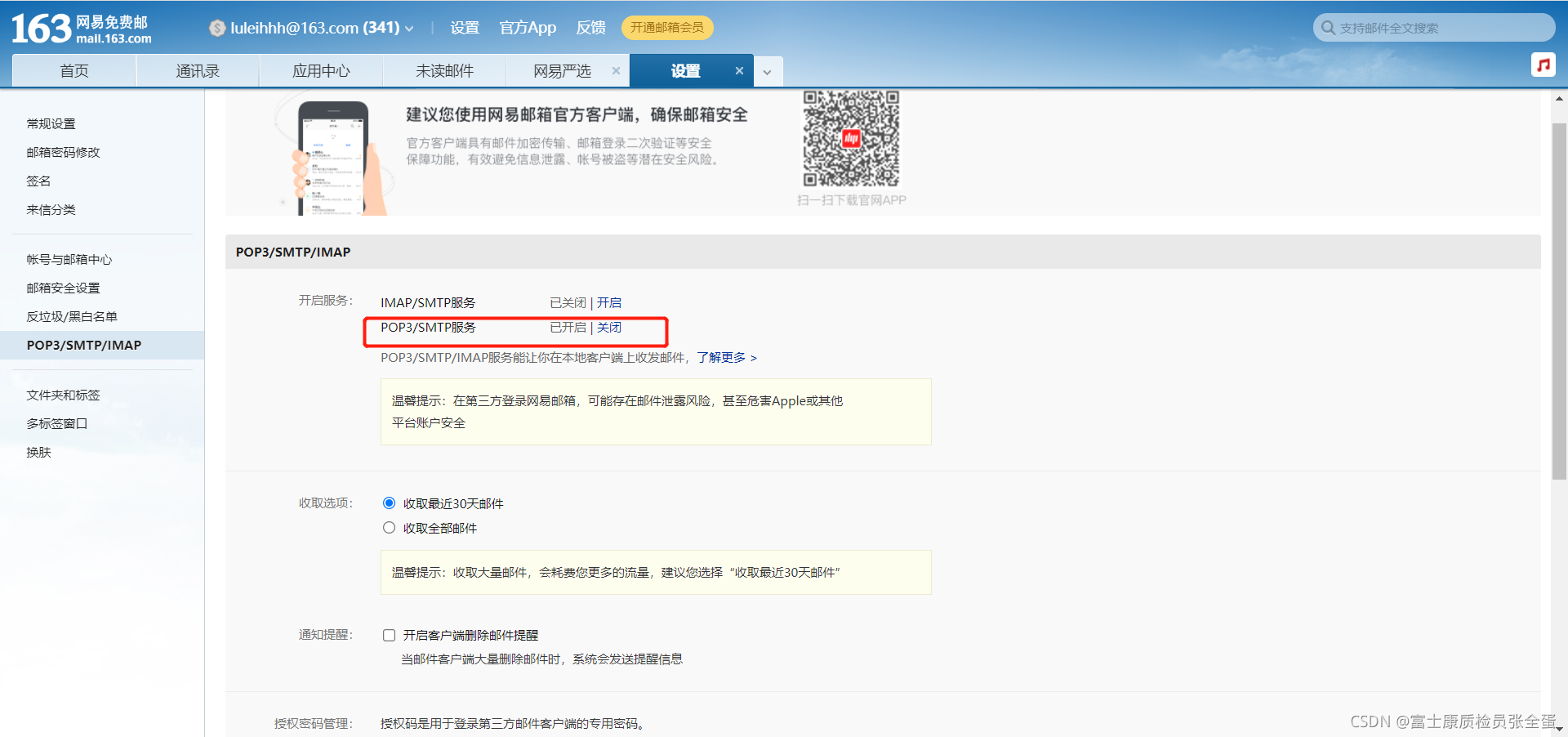
[root@localhost ~]# cat /usr/local/alertmanager/alertmanager.yml
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: '[email protected]'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'xxxxxxxxxxxxxxx'
smtp_require_tls: false
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 10m
receiver: 'mail'
receivers:
- name: 'mail'
email_configs:
- to: '[email protected]'
- to: '[email protected]'产生告警之后等待10s, 同一个组还有报警,那就和其他告警一起发出去,产生告警不会立刻发出去,等待这个组内其他告警产生,然后一起发出去。
route: #用于配置告警分发策略
group_by: [alertname] # 采用哪个标签来作为分组依据
group_wait: 10s # 组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出
group_interval: 10s # 如果有不同的组,两组告警的间隔时间
repeat_interval: 10m # 重复告警的间隔时间,减少相同邮件的发送频率
receiver: default-receiver # 设置默认接收人
普罗米修斯启用告警配置
这个目录就是一个相对路径
rule_files:
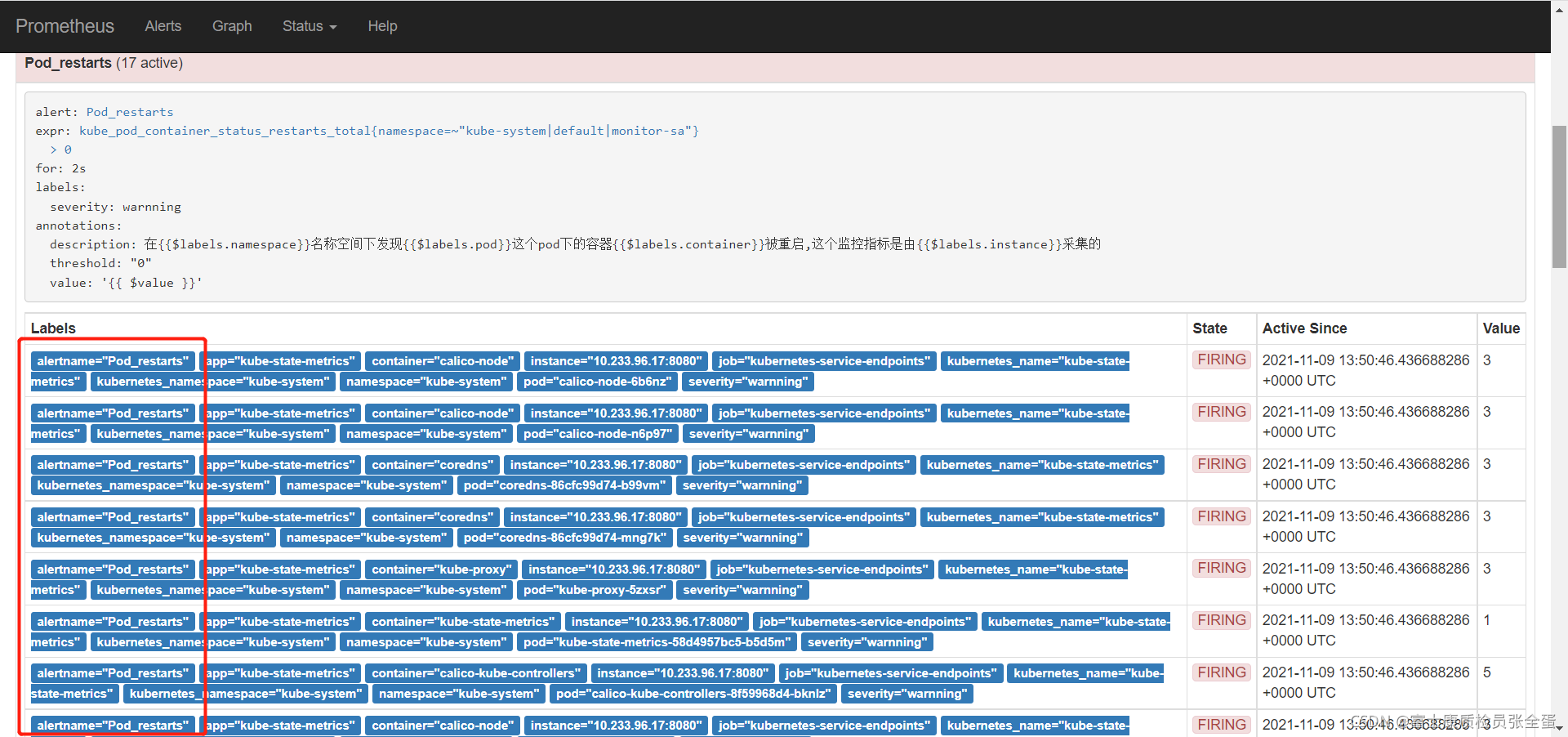
- "rules/*.yml"创建告警规则,这个是在分组下面创建告警规则,up为1代表正常 up为0代表不正常
只要采集目标端up指标等于0那么普罗米修斯评估到触发阈值了,然后将其发向latermanager
1m钟之内,只要处于处于条件为真的状态up==0那么就触发
自定义标签,也就是自定义,让你收到告警的时候对标签更加清晰,附加信息说明告警
[root@localhost ~]# mkdir -p /usr/local/prometheus/rules
[root@localhost ~]# cat /usr/local/prometheus/rules/node.yml
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0 # 基于PromQL的触发条件
for: 1m # 等待评估时间
labels: # 自定义标签
severity: page
annotations: # 指定附加信息
summary: " {
{ $labels.instance }} 停止工作"
description: "{
{ $labels.instance }}:job{
{ $labels.job }} 已经停止5分钟以上."这里可以写多个分组,如果还要分组- name
只要采集的指标当中有的指标都可以在告警描述当中引用
每个被监控端都有up这个标签,up为1代表服务正常,如果等于0代表服务不正常。所以可以通过up获取所有的被监控端状态

查看告警规则是否生效
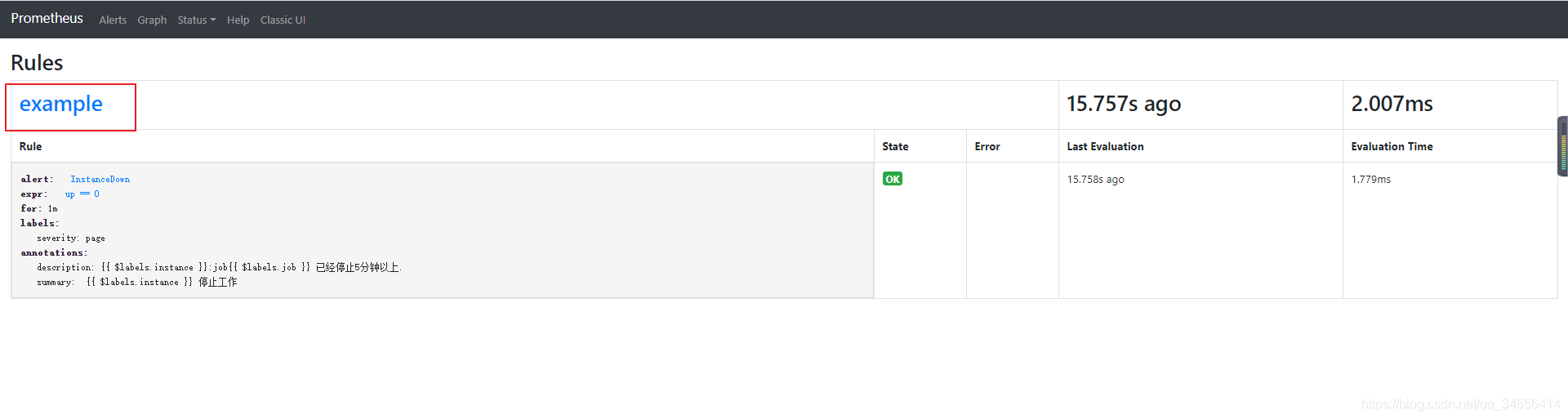
告警状态
• Inactive:这里什么都没有发生。
• Pending:已触发阈值,但未满足告警持续时间,也就是for字段
• Firing:已触发阈值且满足告警持续时间。警报发送给接受者。

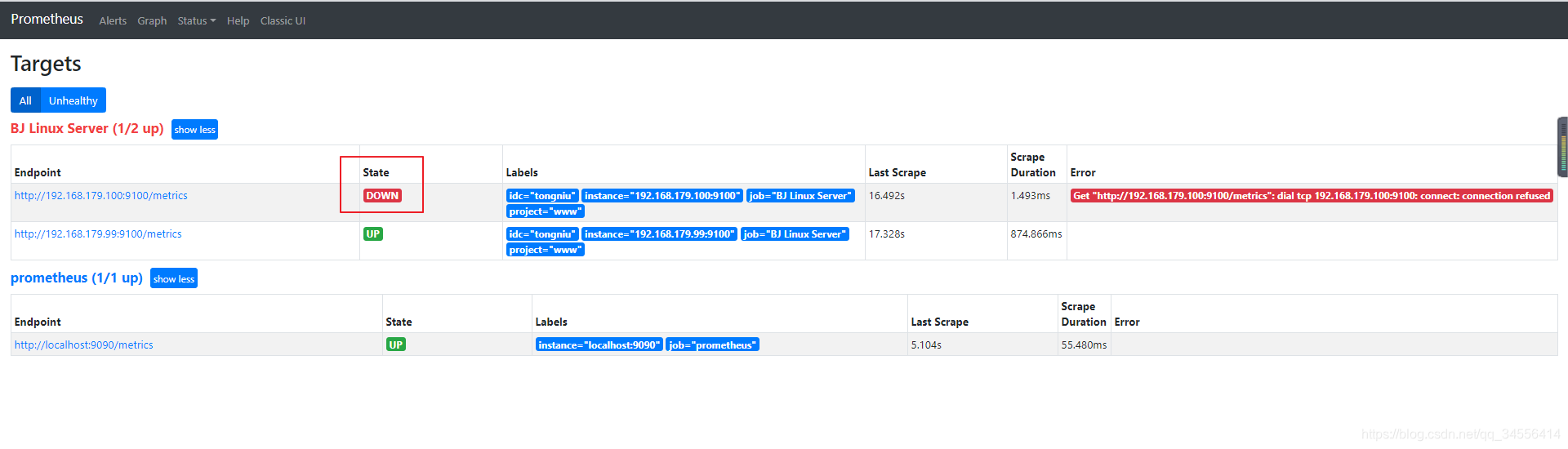
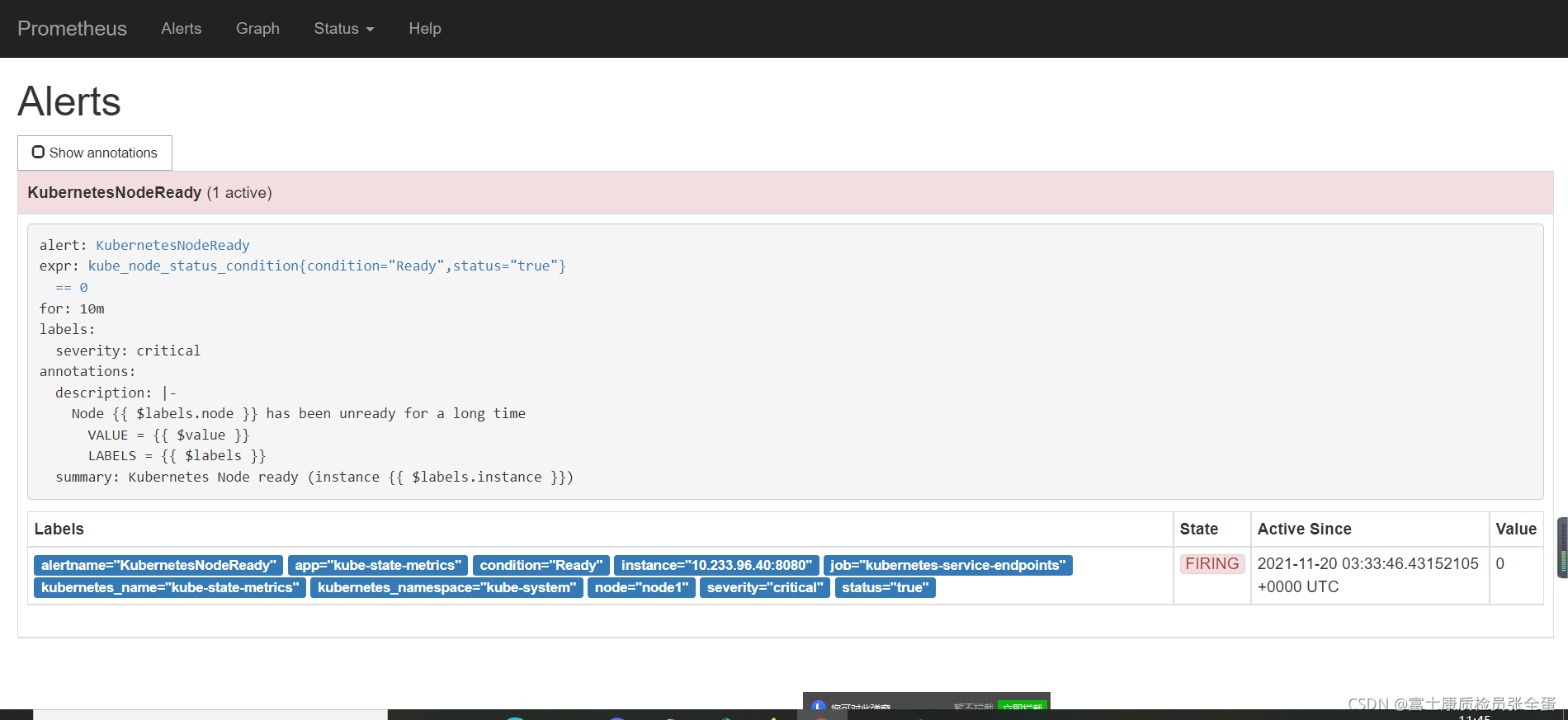
被监控端一个主机down了,查看告警 ,可以看到告警处于pending的状态,进入for循环评估当中

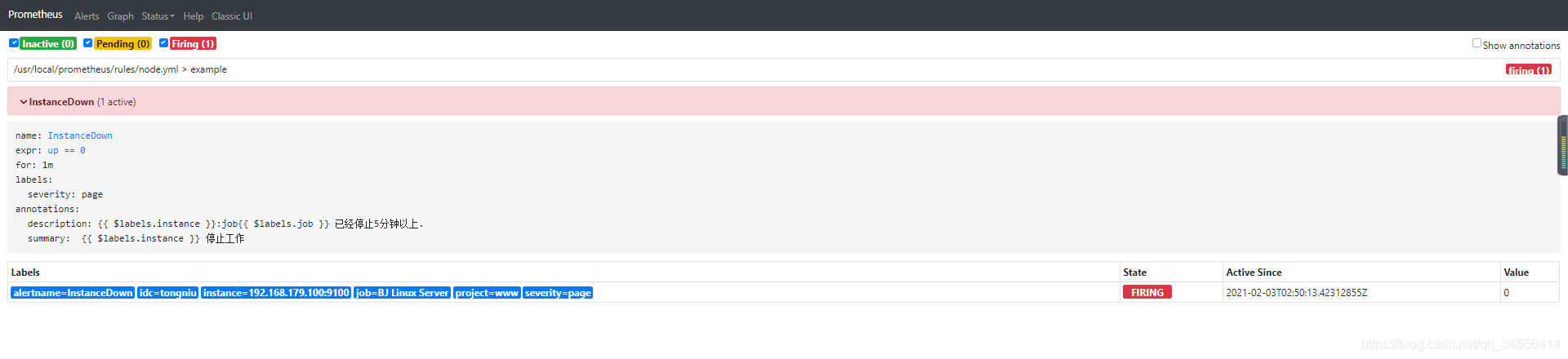
在评估期内满足条件告警状态触发了,此时状态为Firing
这里可以在告警规则里面定义一些标签,方面后期的处理,主要是在altermanager里面体现
最后邮箱查看,记住,同一个组下面的多个告警触发,在发送的时候会合并为一封邮件!

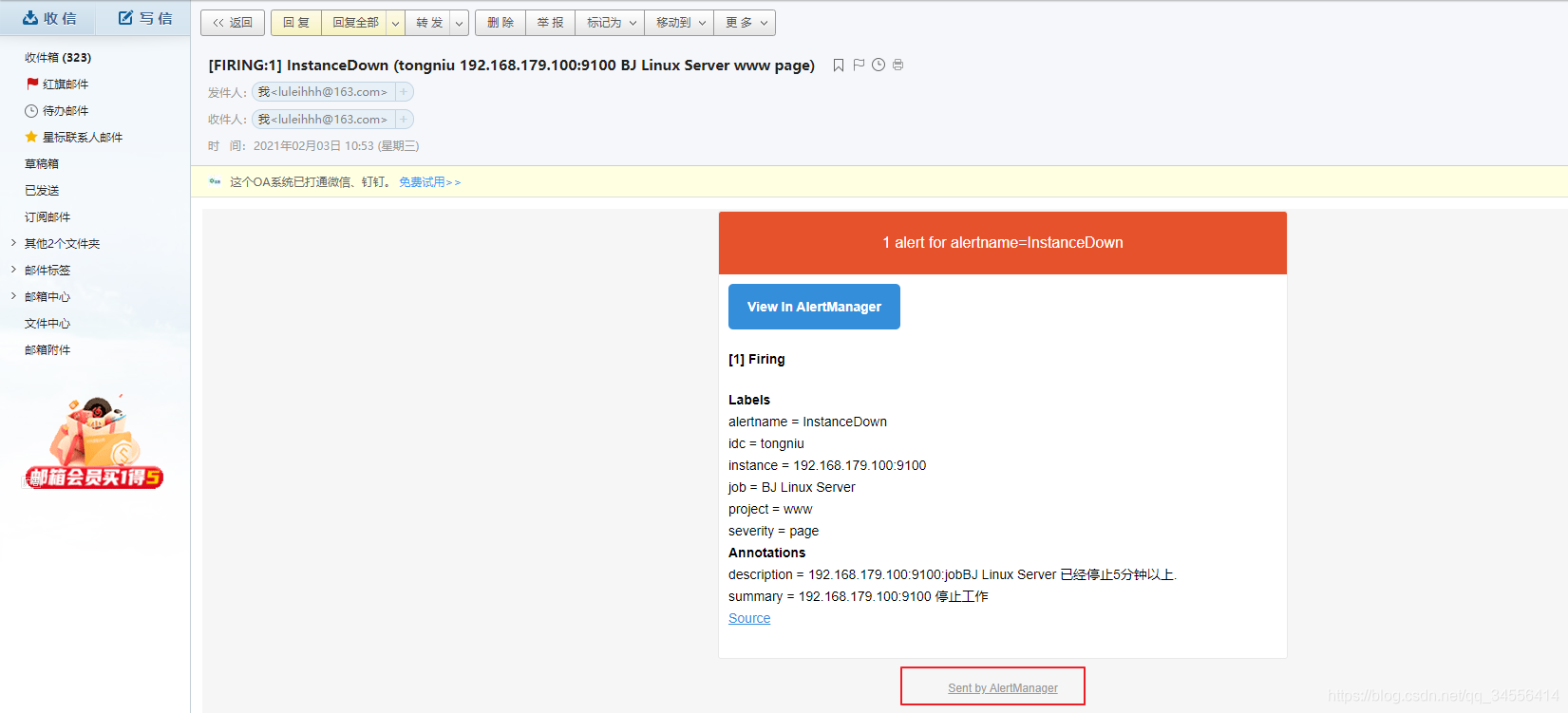
最后一点我想说的是, repeat_interval: 10m # 重复告警间隔发送时间 ,可以看到相同的告警再次触发需要间隔十分钟,建议配置为1m钟

Kubernetes Node ready
Node { { $labels.node }} has been unready for a long time
- alert: KubernetesNodeReady
expr: kube_node_status_condition{condition="Ready",status="true"} == 0
for: 10m
labels:
severity: critical
annotations:
summary: Kubernetes Node ready (instance {
{ $labels.instance }})
description: "Node {
{ $labels.node }} has been unready for a long time\n VALUE = {
{ $value }}\n LABELS = {
{ $labels }}"
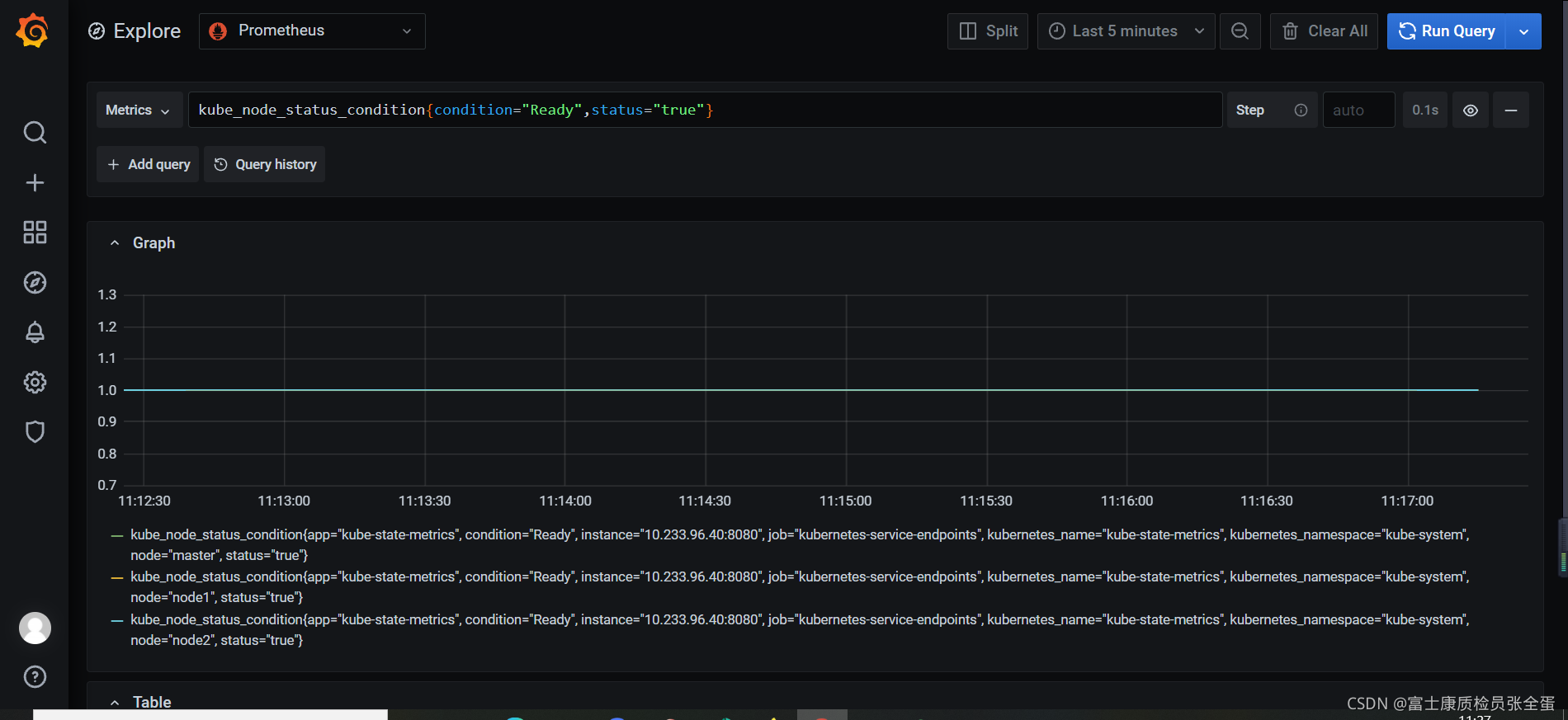


Prometheus一条告警怎么触发的?

Prometheus scrape_interval: 15s:采集的时间间隔是15s,也就是默认每隔15s采集一次指标,也就是有一个实例宕掉了,正好前一秒刚好采集完,那么还要等15s才能采集到这个指标,普罗米修斯才能感知到。
Prometheus evaluation_interval: 1m:告警评估周期,也就是每隔多长时间对采集的指标做个评估
Prometheus for: 30s 评估时间
Alertmanager group_wait: 10s 还需要分组,所以告警在这还会等待
所以告警触发了并不是马上就可以通知到你,需要经历上面的阶段。