目录
概念就不讲了,直接操作………………
docker安装
使用prometheus实现钉钉告警是用容器实现的,所以要安装docker,安装方法可以看之前的文章docker的安装和启动–centos7。
出现如下效果则成功
[root@iZbp16vhn64fpaj6qmsum0Z ~]# docker --version
Docker version 24.0.2, build cb74dfc
接下来就是安装启动,看之前的文章就好
准备工作
镜像拉取
拉取需要使用的镜像
docker pull prom/node-exporter
docker pull grafana/grafana
docker pull prom/prometheus
docker pull prom/alertmanager
docker pull timonwong/prometheus-webhook-dingtalk
如下所示

其中
prom/node-exporter:用于收集主机系统信息和指标的
grafana/grafana:是一个用于可视化和分析监控指标的开源平台。
prom/prometheus:是一个开源的监控系统,用于收集和存储时间序列数据,并提供基于数据的查询、报警和可视化功能。
prom/alertmanager:是 Prometheus 的告警管理器,用于处理和路由来自 Prometheus 服务器的告警通知。
timonwong/prometheus-webhook-dingtalk:是一个用于将 Prometheus 告警通知发送到钉钉的 Webhook,它是一个第三方的开源软件。
容器启动
启动node-exporter
docker run -d -p 9100:9100 -v /proc:/host/proc:ro -v /sys:/host/sys:ro -v /:/rootfs:ro prom/node-exporter
查看访问
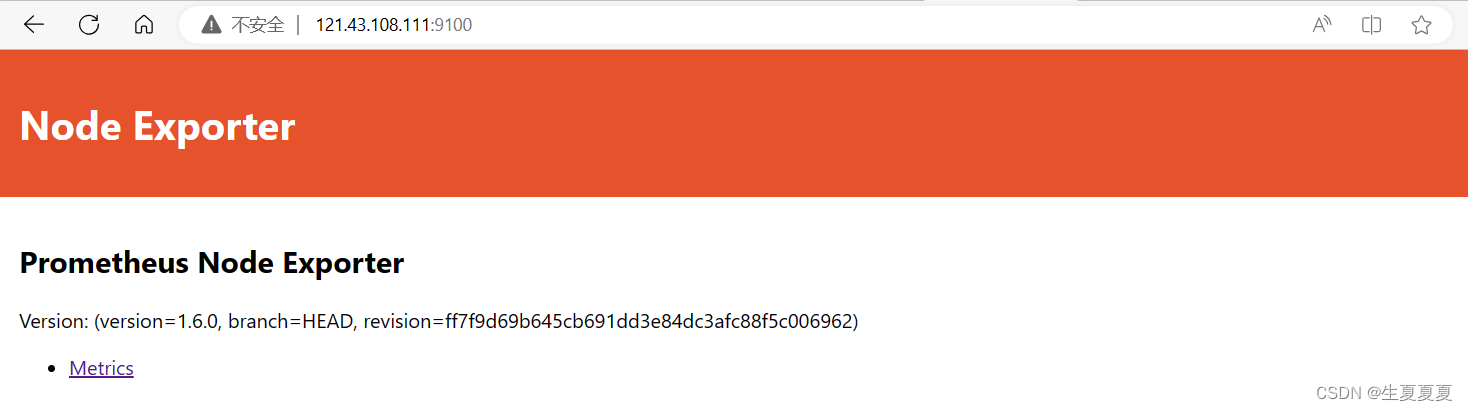
启动prometheus
在启动prometheus之前,可以自己编写一个prometheus.yml文件,然后使用卷挂载到该容器内部。
# 创建挂载目录
mkdir /opt/prometheus
cd /opt/prometheus/
# 编写该文件
vim prometheus.yml
prometheus.yml文件
global:
scrape_interval: 60s
evaluation_interval: 60s
# Alertmanager配置
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['121.43.108.111:9090'] # 采取prometheus指标数据
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['121.43.108.111:9100'] # 采取本地指标数据
labels:
instance: localhost
启动
docker run -d -p 9090:9090 -v /opt/prometheus:/etc/prometheus prom/prometheus
查看访问
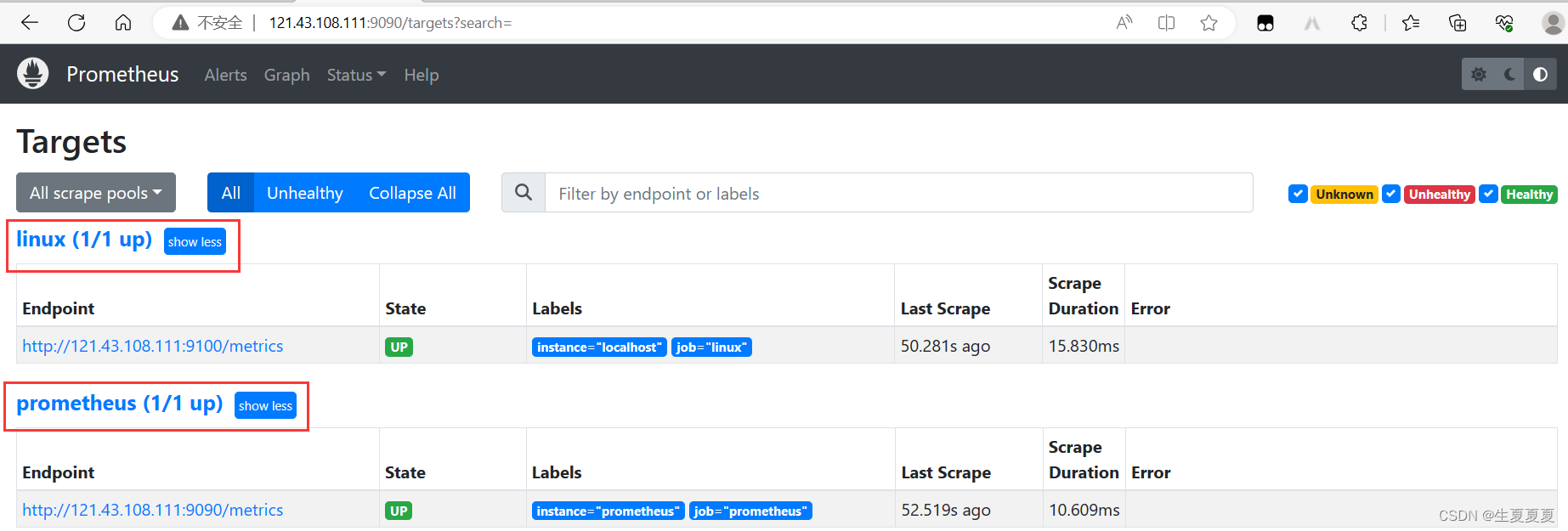
启动grafana
docker run -d -p 3000:3000 --name=grafana grafana/grafana
查看访问
启动webhook-prometheus-dingtalk
首先获取钉钉告警机器人的webhook token
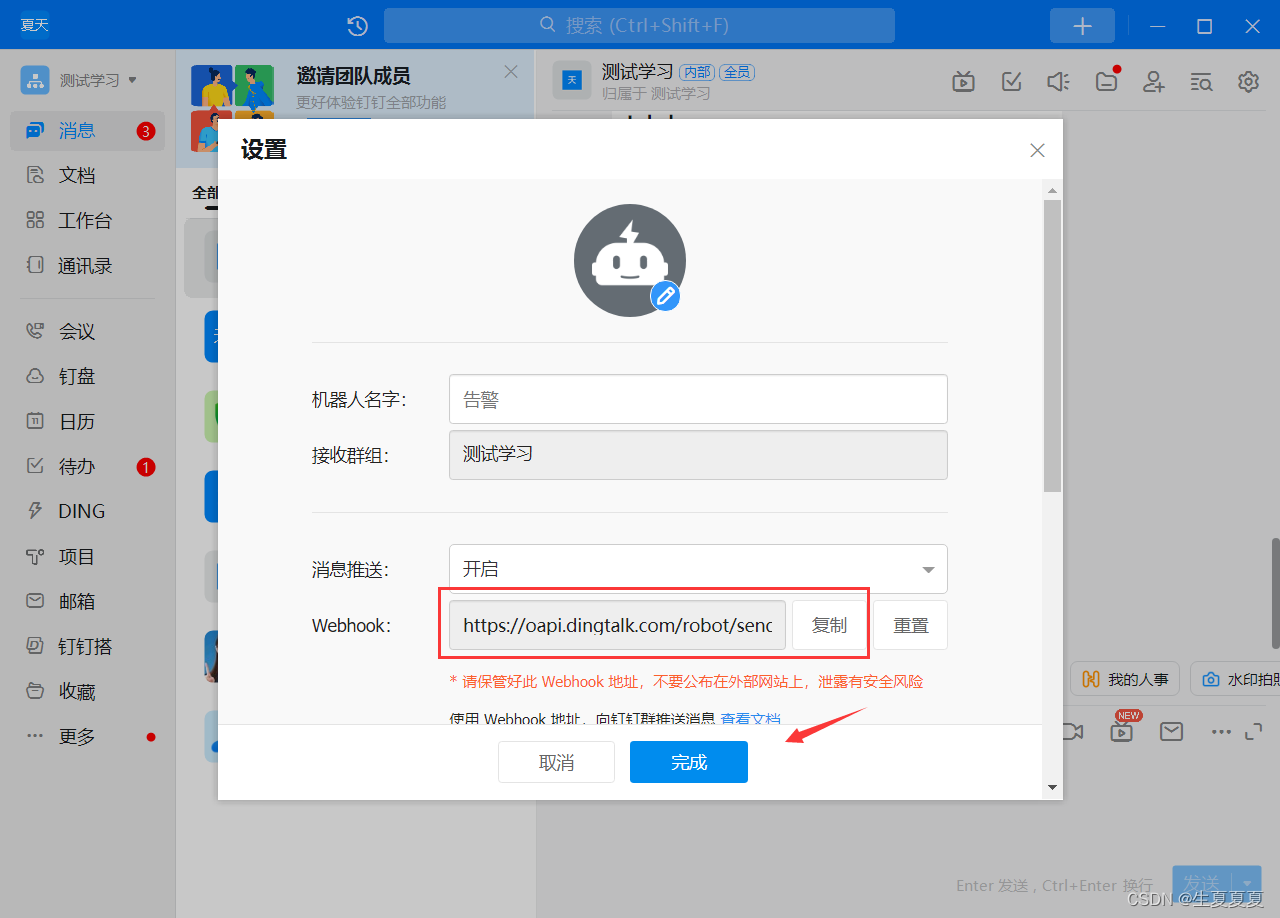
启动
注意:这里要改为 --ding.profile=“webhook1=自己复制的webhook”
docker run -d --restart always -p 8060:8060 timonwong/prometheus-webhook-dingtalk:v0.3.0 --ding.profile="webhook1=复制的webhook"
启动alertmanager
在启动alertmanager之前,可以自己编写一个alertmanager.yml文件,然后使用卷挂载到该容器内部。
# 创建挂载目录
mkdir /opt/alertmanager
cd /opt/alertmanager/
# 编写该文件
vim alertmanager.yml
alertmanager.yml
global:
resolve_timeout: 5m
route: # 告警路由配置,定义如何处理和发送告警
receiver: webhook
group_wait: 30s
group_interval: 1m
repeat_interval: 4h
group_by: [alertname]
routes:
- receiver: webhook
group_wait: 10s
receivers: # 告警接收者配置,定义如何处理和发送告警
- name: webhook
webhook_configs:
- url: http://121.43.108.111:8060/dingtalk/webhook1/send # 告警 Webhook URL
send_resolved: true # 是否发送已解决的告警。如果设置为 true,则在告警解决时发送通知
启动
docker run -d -p 9093:9093 -v /opt/alertmanager/:/etc/alertmanager/ --name alertmanager prom/alertmanager
查看访问
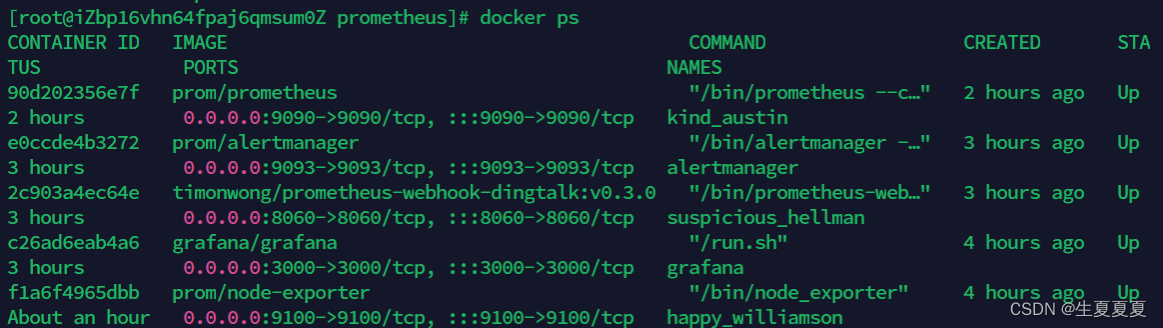
所有容器启动成功如下
将prometheus和alertmanager进行关联
在prometheus目录下新建一个rules.yml文件的告警规则
[root@iZbp16vhn64fpaj6qmsum0Z prometheus]# pwd
/opt/prometheus
[root@iZbp16vhn64fpaj6qmsum0Z prometheus]# cat rules.yml
groups:
- name: host_monitoring
rules:
- alert: 内存报警
expr: netdata_system_ram_MiB_average{
chart="system.ram",dimension="free",family="ram"} < 800
for: 2m
labels:
team: node
annotations:
Alert_type: 内存报警
Server: '{
{$labels.instance}}'
#summary: "{
{$labels.instance}}: High Memory usage detected"
explain: "内存使用量超过90%,目前剩余量为:{
{ $value }}M"
#description: "{
{$labels.instance}}: Memory usage is above 80% (current value is: {
{ $value }})" - alert: CPU报警
expr: netdata_system_cpu_percentage_average{
chart="system.cpu",dimension="idle",family="cpu"} < 20 for: 2m
labels:
team: node
annotations:
Alert_type: CPU报警
Server: '{
{$labels.instance}}'
explain: "CPU使用量超过80%,目前剩余量为:{
{ $value }}"
#summary: "{
{$labels.instance}}: High CPU usage detected"
#description: "{
{$labels.instance}}: CPU usage is above 80% (current value is: {
{ $value }})"
- alert: 磁盘报警
expr: netdata_disk_space_GiB_average{
chart="disk_space._",dimension="avail",family="/"} < 4
for: 2m
labels:
team: node
annotations:
Alert_type: 磁盘报警
Server: '{
{$labels.instance}}'
explain: "磁盘使用量超过90%,目前剩余量为:{
{ $value }}G"
- alert: 服务告警
expr: up == 0
for: 2m
labels:
team: node
annotations:
Alert_type: 服务报警
Server: '{
{$labels.instance}}'
explain: "netdata服务已关闭"
修改prometheus.yml文件,进行关联
[root@iZbp16vhn64fpaj6qmsum0Z prometheus]# pwd
/opt/prometheus
[root@iZbp16vhn64fpaj6qmsum0Z prometheus]# cat prometheus.yml
global:
scrape_interval: 60s
evaluation_interval: 60s
# Alertmanager配置
alerting:
alertmanagers:
- static_configs:
- targets: ["121.43.108.111:9093"]
# rule配置
rule_files:
- "/etc/prometheus/rules.yml"
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['121.43.108.111:9090']
labels:
instance: prometheus
- job_name: linux
static_configs:
- targets: ['121.43.108.111:9100']
labels:
instance: localhost
注意:因为我们是使用挂载的方式将配置文件投射到容器中,相应的文件路径也要发生变化。
比如:rule_files: [“/etc/prometheus/rules.yml”] 的路径就要填写为容器内该文件存放的路径。
重新启动prometheus
docker restart prometheus的容器id
查看显示
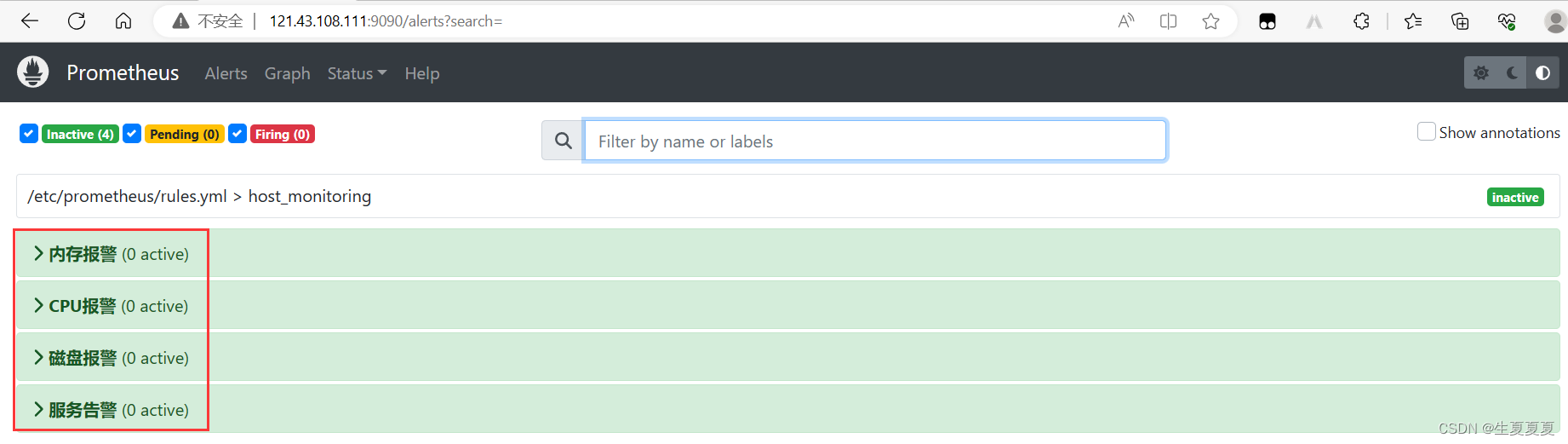
测试
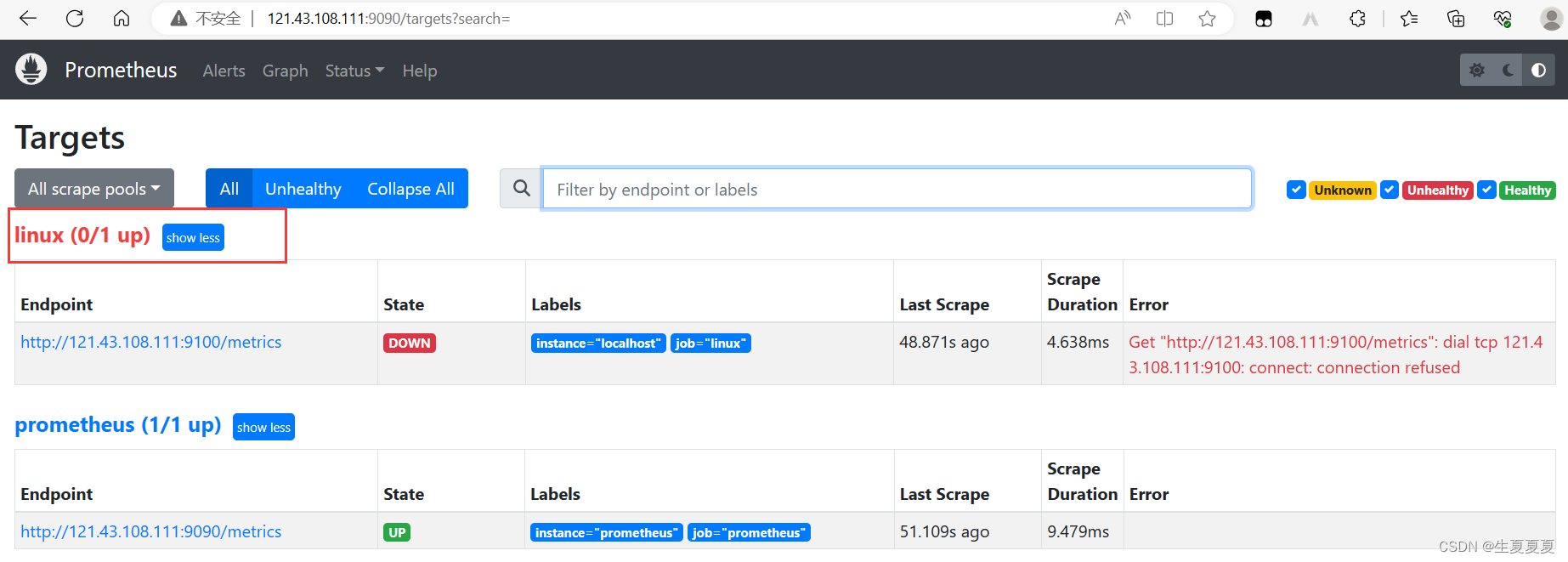
将node-exporter所在的容器停掉,查看效果
docker stop node-exporter所在的容器id
node-exporter
alertmanager
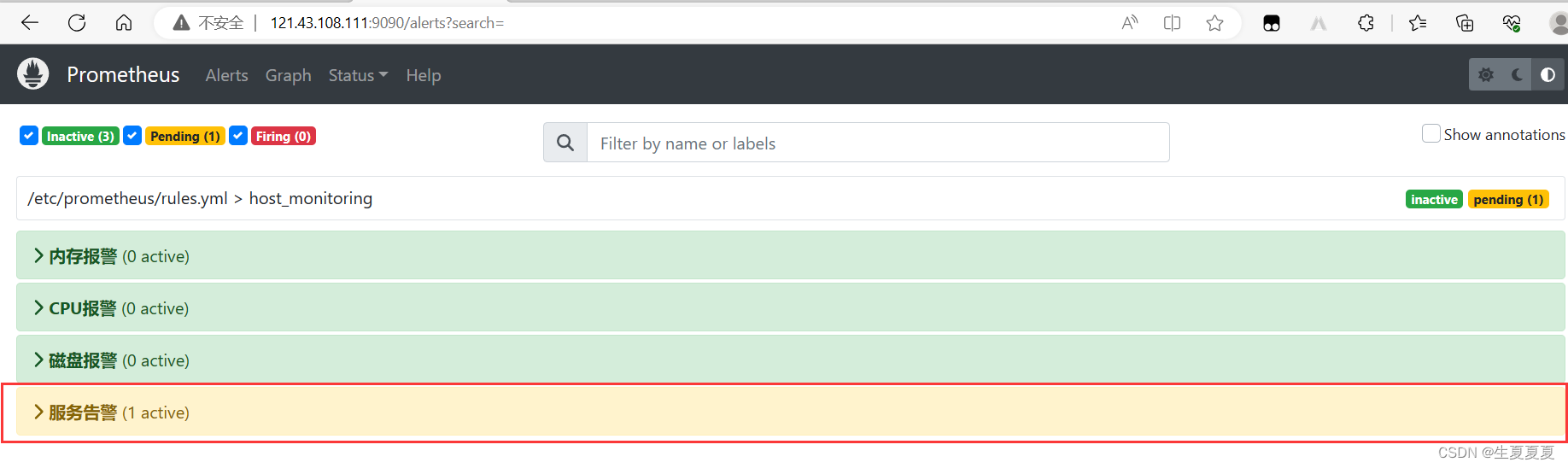
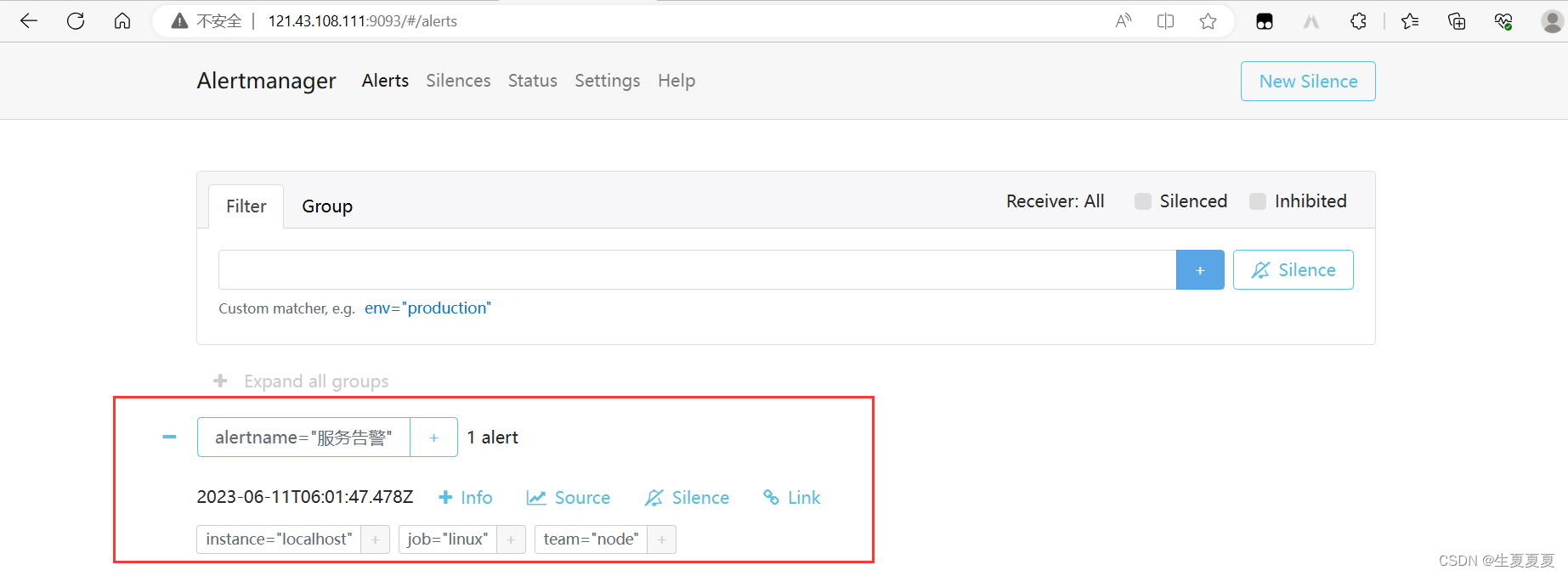
钉钉查看告警
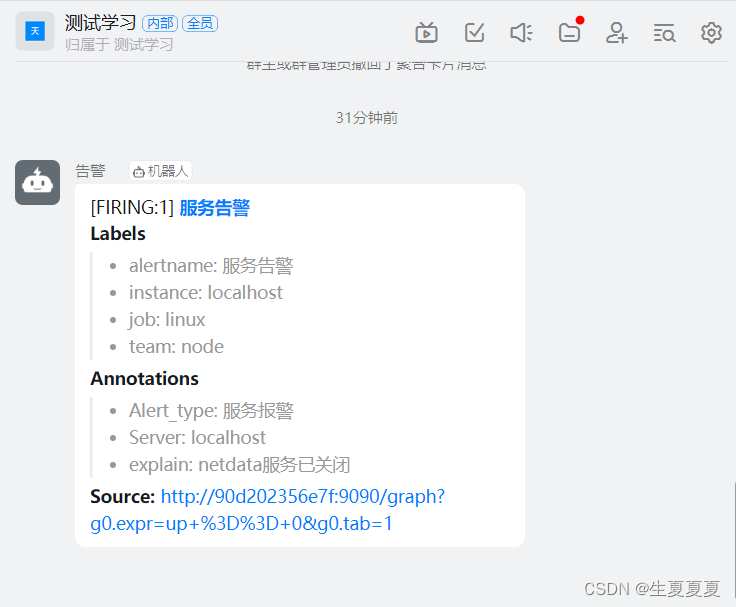
将node-exporter所在的容器重启,查看效果
docker restart node-exporter所在的容器id
钉钉查看
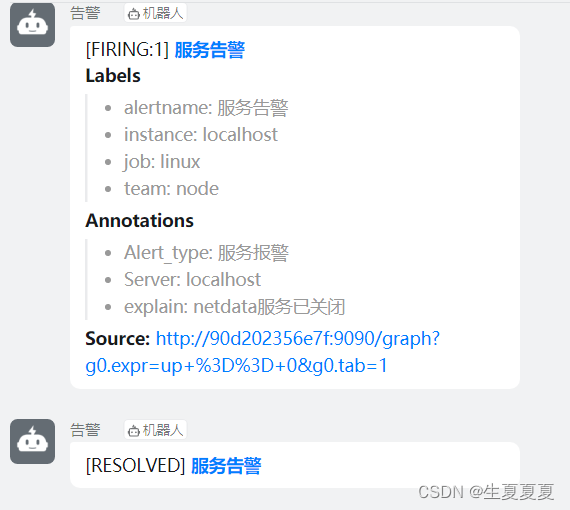
结束
参考文章: 在这里