目录
一、思考题
一个问题:我们常说,现在是互联网时代、移动互联网时代,那何为互联网时代?从何时开始,又何时结束?
另一个问题:时代在变化,IT技术也在变化,是时代变化导致技术变更?还是技术变更引起时代变化呢?
二、互联网时代
2.1 Web 1.0
第一代互联网(Web 1.0)是PC(个人计算机)互联网,从1994年发展至今,提升了全球信息传输的效率,降低了信息获取的门槛。
第一代互联网的优势在于高效地传输信息,因此网络新闻、在线搜索、电子邮件、即时通信、电子商务、彩信彩铃、客户端和网页游戏等应用普及,互联网用户被迅速连接起来。
这个时代的代表公司包括雅虎、谷歌、亚马逊、新浪、搜狐、网易、腾讯、百度、阿里巴巴、京东等。

2.2 Web 2.0
第二代互联网(Web 2.0)是移动互联网,从2008年左右拉开大幕,到今天仍然精彩纷呈。
第二代互联网显著特点:数字化。智能手机的普及,让线上(online)和线下(offline)开始紧密地交互。社交网络、O2O服务(线上到线下服务)、手机游戏、短视频、网络直播、信息流服务、应用分发和互联网金融等移动互联网服务成为社会主流。 在这一阶段,苹果公司、Facebook、爱彼迎、优步、小米、字节跳动、滴滴、美团、蚂蚁金服、拼多多和快手等迅速崛起,成为各自领域的领军企业。

2.3 Web 3.0
第三代互联网(Web 3.0)将是一个去中心化的互联网,旨在打造出一个全新的合约系统,并颠覆个人和机构达成协议的方式。
未来我们将看到一个不同于Web 1.0、2.0的互联网:
区块链让数据成为资产
智能合约打造可编程的智能经济体系
人工智能构建全球智慧大脑并创造“数字人”
物联网让物理世界的现实物体向数字空间广泛映射
AR实现了数字世界与物理世界的叠加
5G网络、云计算、边缘计算将构建更加宏伟的数字新空间
这个发展阶段也同样会出现一系列全新的“杀手级应用”,诞生一批伟大的新型经济组织,而非垄断巨头企业。

三、时代下的问题
时代在发展,隐藏在时代潮流下,技术萌芽契机又是啥?
3.1 大数据
Web3时代带来数据爆炸式增长,以前传统数据等量级早已经不使用,技术引入大数据概念。
麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
这里有幅图:A DAY IN DATA

以下是信息图中突出的每日产生的关键数据:
-
发出5亿条推特
-
发送2940亿封邮件
-
Facebook上新创建4拍字节(PB)数据
-
每辆联网的汽车都会创造出4太字节的数据
-
WhatsApp上发送出650亿条信息
-
50亿次搜索
为了能对上面内容的数据单位有一个大体的概念,我们可以先了解一下各数据单位。
1B (Byte 字节)=8b (bit 位)
1KB (Kilobyte 千字节)=1024B
1MB (Megabyte 兆字节 简称“兆”)=1024KB
1GB (Gigabyte 吉字节 又称“千兆”)=1024MB
1TB (Trillionbyte 万亿字节 太字节)=1024GB
1PB(Petabyte 千万亿字节 拍字节)=1024TB
1EB(Exabyte 百亿亿字节 艾字节)=1024PB
1ZB (Zettabyte 十万亿亿字节 泽字节)=1024EB
1YB (Yottabyte 一亿亿亿字节 尧字节)=1024ZB
只Facebook每天就能产生4,194,304GB的数据,由此可见每天产生的数据量之多。
近年来,伴随着云计算、大数据、物联网、人工智能等信息技术的快速发展和传统产业数字化的转型,数据量呈现几何级增长,据IDC发布《数据时代2025》的报告显示,全球每年产生的数据将从2018年的33ZB增长到175ZB,相当于每天产生491EB的数据。【2017年】

2021年全球实时数据量规模为16ZB(1ZB约等于1万亿GB),占全球数据总量的19.6%,2025年实时数据量将达到51ZB,占数据总量的比重会跃升至29%,“需要快速处理的数据比重在迅速上升”。
3.2 高并发
除了数据量大之后,Web3时代还有一个高难度的挑战:高并发
通俗来讲,高并发是指在同一个时间点,有很多用户同时的访问同一 API 接口或者 Url 地址。它经常会发生在有大活跃用户量,用户高聚集的业务场景中,下面直观感受一下高并发场景:
场景一:天猫双十一


一秒50w+成交量~
而,成交 = 查看 + 下单 + 结算 + 支付.....
场景二:12306购票

2015年阿里云与12306进行合作,免费给12306提供技术支持,把12306网站的查询访问放在了阿里云上。经过阿里改造后的12306系统,年售票量已超过35亿张,是世界上规模最大的实时票务交易系统。平均每日发售车票达900万+张,最高日售车票1000万张,高峰时每秒售票量达1000张,已占到了总销售票量的80%。 高峰日的网络页面浏览量超过1500亿次,啥概念,相当于全中国人每人每天访问了票务页面100多次。【2023年数据】
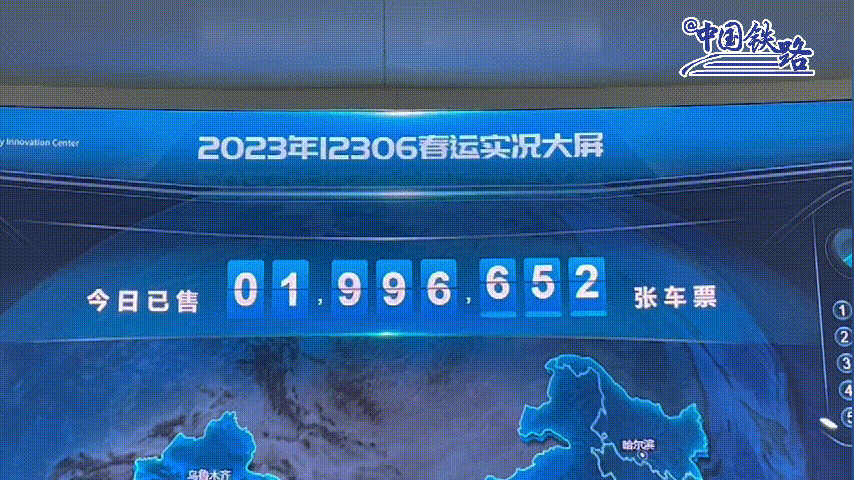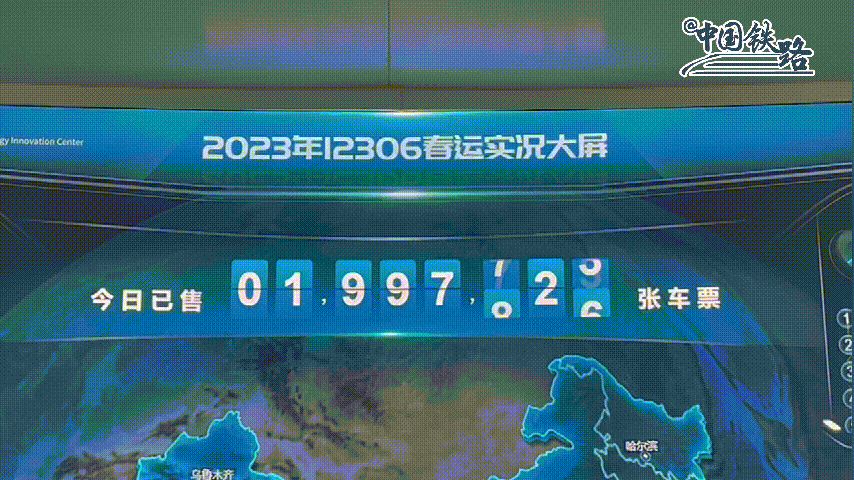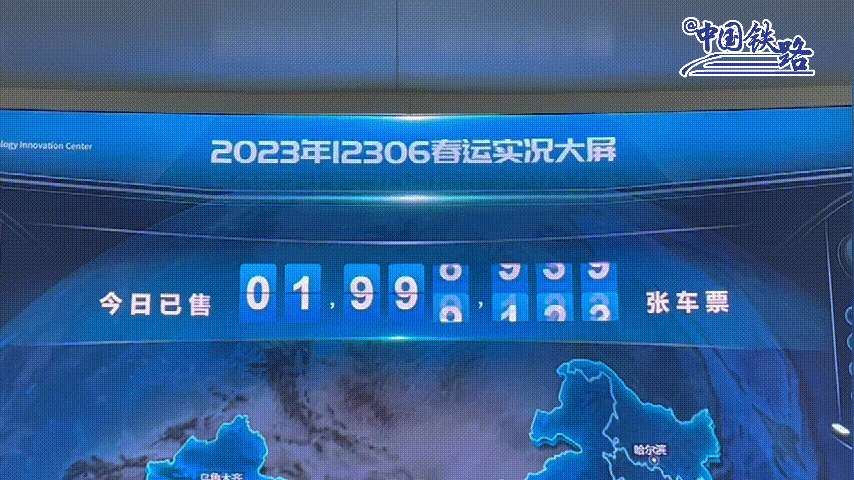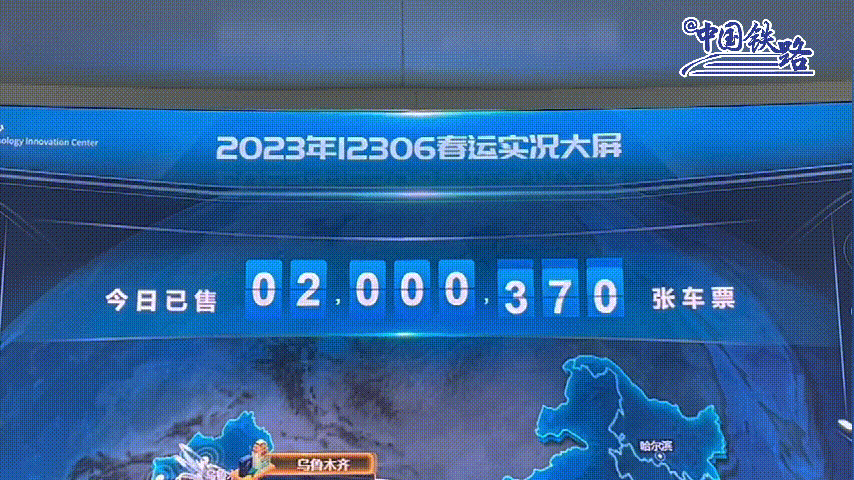
能让上亿人每天盯着网站使劲刷,拼命刷,花钱买软件刷,除了12306,还有谁?斑爷都愿称它为最强。
四、谁为弄潮儿
在此时代背景下,谁会成为弄潮儿?
存储方向:Ceph,Swift, HDFS, RocksDB, LevelDB, memcache, Redis,HBase,MySQL, Postgresql,mongoDB ....
计算方向:对 Spark,MapReduce,Storm,OLAP ,Flume, Kafka...
集群管理方向: YARN,Mesos ....
虚拟化方向:KVM,XEN,VMvare,OpenStack,Cloud Stack ....
平台架构:IaaS, PaaS,SaaS...
微服务:Hessian,Montan,rpcx,gRPC,Thrift,Dubbo,Dubbox,SpringCloud....
上面提到技术都是,都是这个时代的弄潮儿,本专栏重点讲解存储方向中的:Redis
五、NoSQL
提到Redis,绕不开的概念:NoSQL ,一个让传统关系型数据库玩出花的王牌辅助。
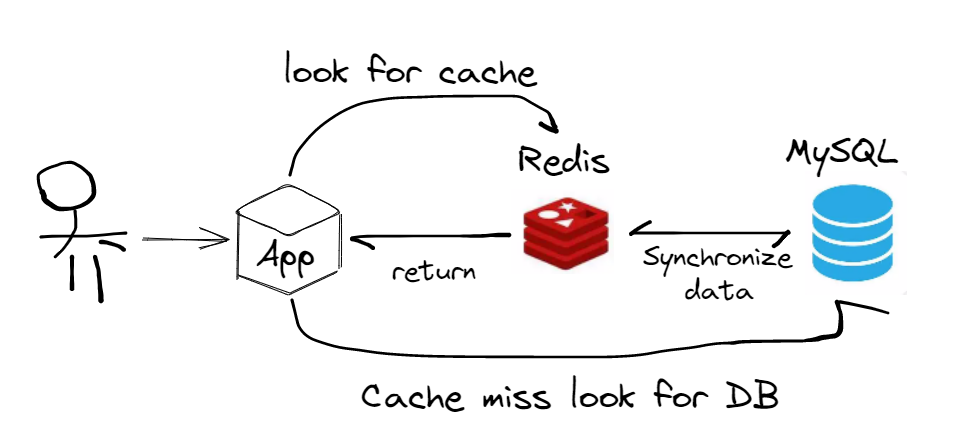
5.1 概念
NoSQL,泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在处理web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,比如:
1 、 Highperformance- 对数据库高并发读写的需求
web2.0 网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所以基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。关系型数据库应付上万次 SQL 查询还勉强顶得住,但是应付上万次 SQL 写数据请求,硬盘IO 就已经无法承受了,其实对于普通的 BS 网站,往往也存在对高并发写请求的需求。
2 、HugeStorage- 对海量数据的高效率存储和访问的需求
对于大型的 SNS 网站,每天用户产生海量的用户动态信息,以国外的 Friend feed 为例,一个月就达到了 2.5 亿条用户动态,对于关系数据库来说,在一张 2.5 亿条记录的表里面进行SQL 查询,效率是极其低下乃至不可忍受的。再例如大型 web 网站的用户登录系统,例如腾讯,盛大,动辄数以亿计的帐号,关系数据库也很难应付。
3、HighScalability&&HighAvailability- 对数据库的高可扩展性和高可用性的需求
在基于 web 的架构当中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没有办法像 Web server 和 App server 那样简单的通过添加更多的硬件和服务节点来扩展性能和负载能力。对于很多需要提供 24 小时不间断服务的网站来说,对数据库系统进行升级和扩展是非常痛苦的事情,往往需要停机维护和数据迁移,可是停机维护随之带来的就是公司收入的减少
然而,强如NoSQL这么牛逼技术,刚出来叫法应该为:No SQL, 意图脱离SQL限制,自立门户,走纯内存路线,但无数事实打脸,在摩尔定律魔咒下,内存硬件短时间还是无法取得实质意义上的突破,No SQL 与SQL 还会相爱相杀到永远。所以现在普遍认可NoSQL第二含义:Not Only SQL。
5.2 分类
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(KV) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
5.3 特点
对于NoSQL并没有一个明确的范围和定义,但是他们都普遍存在下面一些共同特征:
易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间,在架构的层面上带来了可扩展的能力。
大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。
灵活的数据模型
NoSQL无须事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是——个噩梦。这点在大数据量的Web 2.0时代尤其明显。
高可用
NoSQL在不太影响性能的情况,就可以方便地实现高可用的架构。比如Cassandra、HBase模型,通过复制模型也能实现高可用。
5.4 使用场景
NoSQL数据库在以下的这几种情况下比较适用:
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
六、结语
本篇到这就基本结束啦,交代了一下NoSQL出现的时代背景,下一篇,我们的主角:Redis即将登场,敬请期待~