title: 设计模式之美总结(面向对象篇)
date: 2022-10-11 17:02:54
tags:
- 设计模式
categories: - 设计模式
cover: https://cover.png
feature: false
文章目录
1. 代码质量的好坏
下面这些几乎涵盖我们所能听到的描述代码质量的所有常用词汇,这些描述方法语义更丰富、更专业、更细化
灵活性(flexibility)、可扩展性(extensibility)、可维护性(maintainability)、可读性(readability)、可理解性(understandability)、易修改性(changeability)、可复用(reusability)、可测试性(testability)、模块化(modularity)、高内聚低耦合(high cohesion loose coupling)、高效(high effciency)、高性能(high performance)、安全性(security)、兼容性(compatibility)、易用性(usability)、整洁(clean)、清晰(clarity)、简单(simple)、直接(straightforward)、少即是多(less code is more)、文档详尽(welldocumented)、分层清晰(well-layered)、正确性(correctness、bug free)、健壮性(robustness)、鲁棒性(robustness)、可用性(reliability)、可伸缩性(scalability)、稳定性(stability)、优雅(elegant)、好(good)、坏(bad)
……
实际上,很难通过其中的某个或者某几个词汇来全面地评价代码质量。因为这些词汇都是从不同维度来说的。并不能通过单一的维度去评价一段代码写的好坏。比如,即使一段代码的可扩展性很好,但可读性很差,那也不能说这段代码质量高
除此之外,不同的评价维度也并不是完全独立的,有些是具有包含关系、重叠关系或者可以互相影响的。比如,代码的可读性好、可扩展性好,就意味着代码的可维护性好。而且,各种评价维度也不是非黑即白的。比如,不能简单地将代码分为可读与不可读。如果用数字来量化代码的可读性的话,它应该是一个连续的区间值,而非 0、1 这样的离散值
对一段代码的质量评价,常常有很强的主观性。正是因为代码质量评价的主观性,使得这种主观评价的准确度,跟工程师自身经验有极大的关系。越是有经验的工程师,给出的评价也就越准确。常用的评价标准为:可维护性、可读性、可扩展性、灵活性、简洁性(简单、复杂)、可复用性、可测试性
1.1 可维护性(maintainability)
落实到编码开发,所谓的“维护”无外乎就是修改 bug、修改老的代码、添加新的代码之类的工作。所谓“代码易维护”就是指,在不破坏原有代码设计、不引入新的 bug 的情况下,能够快速地修改或者添加代码。所谓“代码不易维护”就是指,修改或者添加代码需要冒着极大的引入新 bug 的风险,并且需要花费很长的时间才能完成
如何来判断代码可维护性的好坏?
- 代码的可维护性是由很多因素协同作用的结果。代码的可读性好、简洁、可扩展性好,就会使得代码易维护;相反,就会使得代码不易维护
- 更细化地讲,如果代码分层清晰、模块化好、高内聚低耦合、遵从基于接口而非实现编程的设计原则等等,那就可能意味着代码易维护
- 除此之外,代码的易维护性还跟项目代码量的多少、业务的复杂程度、利用到的技术的复杂程度、文档是否全面、团队成员的开发水平等诸多因素有关
- 所以,从正面去分析一个代码是否易维护稍微有点难度。不过可以从侧面上给出一个比较主观但又比较准确的感受。如果 bug 容易修复,修改、添加功能能够轻松完成,那我们就可以主观地认为代码对我们来说易维护。相反,如果修改一个 bug,修改、添加一个功能,需要花费很长的时间,那我们就可以主观地认为代码对我们来说不易维护
代码质量的评价有很强的主观性

1.2 可读性(readability)
代码的可读性应该是评价代码质量最重要的指标之一
软件设计大师 Martin Fowler 曾经说过:“Any fool can write code that a computer can understand. Good programmers write code that humans can understand.”
“任何傻瓜都会编写计算机能理解的代码。好的程序员能够编写人能够理解的代码。”
如何评价一段代码的可读性?
- 要看代码是否符合编码规范、命名是否达意、注释是否详尽、函数是否长短合适、模块划分是否清晰、是否符合高内聚低耦合等等
- 从正面上,很难给出一个覆盖所有评价指标的列表。这也是无法量化可读性的原因
- 实际上,Code Review 是一个很好的测验代码可读性的手段。如果你的同事可以轻松地读懂你写的代码,那说明你的代码可读性很好;如果同事在读你的代码时,有很多疑问,那就说明你的代码可读性有待提高了
1.3 可扩展性(extensibility)
代码的可扩展性是评价代码质量非常重要的标准,可扩展性表示代码应对未来需求变化的能力。和可读性一样,代码是否易扩展也很大程度上决定代码是否易维护
代码的可扩展性表示,在不修改或少量修改原有代码的情况下,通过扩展的方式添加新的功能代码。直白说法就是,代码预留了一些功能扩展点,可以把新功能代码,直接插到扩展点上,而不需要因为要添加一个功能而大动干戈,改动大量的原始代码
关于代码的扩展性,涉及到“对修改关闭,对扩展开放”这条设计原则
1.4 灵活性(flexibility)
灵活性是一个很抽象的评价标准,可以设想几个场景:
- 当添加一个新的功能代码的时候,原有的代码已经预留好了扩展点,不需要修改原有的代码,只要在扩展点上添加新的代码即可。这个时候,除了可以说代码易扩展,还可以说代码写得灵活
- 当要实现一个功能的时候,发现原有代码中,已经抽象出了很多底层可以复用的模块、类等代码,我们可以拿来直接使用。这个时候,除了可以说代码易复用之外,还可以说代码写得灵活
- 当使用某组接口的时候,如果这组接口可以应对各种使用场景,满足各种不同的需求,除了可以说接口易用之外,还可以说这个接口设计得灵活或者代码写得灵活
从上面列举的场景来看,如果一段代码易扩展、易复用或者易用,都可以称这段代码写得比较灵活。所以,灵活这个词的含义非常宽泛
1.5 简洁性(simplicity)
有一条非常著名的设计原则,KISS 原则:“Keep It Simple,Stupid”。这个原则说的意思就是,尽量保持代码简单。代码简单、逻辑清晰,也就意味着易读、易维护。思从深而行从简,用最简单的方法解决最复杂的问题
1.6 可复用性(reusability)
代码的可复用性可以简单地理解为,尽量减少重复代码的编写,复用已有的代码
- 当讲到面向对象特性的时候,会讲到继承、多态存在的目的之一,就是为了提高代码的可复用性
- 当讲到设计原则的时候,会讲到单一职责原则也跟代码的可复用性相关
- 当讲到重构技巧的时候,会讲到解耦、高内聚、模块化等都能提高代码的可复用性
可见,可复用性也是一个非常重要的代码评价标准,是很多设计原则、思想、模式等所要达到的最终效果。代码可复用性跟 DRY(Don’t Repeat Yourself)这条设计原则的关系也很紧密
1.7 可测试性(testability)
相对于前面六个评价标准,代码的可测试性是一个相对较少被提及,但又非常重要的代码质量评价标准。代码可测试性的好坏,能从侧面上非常准确地反应代码质量的好坏。代码的可测试性差,比较难写单元测试,那基本上就能说明代码设计有问题
如何才能写出高质量的代码?
针对什么是高质量的代码,前面讲到了七个最常用、最重要的评价指标。所以问如何写出高质量的代码,也就等同于在问,如何写出易维护、易读、易扩展、灵活、简洁、可复用、可测试的代码
要写出满足这些评价标准的高质量代码,需要掌握一些更加细化、更加能落地的编程方法论,包括面向对象设计思想、设计原则、设计模式、编码规范、重构技巧等。而所有这些编程方法论的最终目的都是为了编写出高质量的代码。比如:
- 面向对象中的继承、多态能让我们写出可复用的代码
- 编码规范能让我们写出可读性好的代码
- 设计原则中的单一职责、DRY、基于接口而非实现、里式替换原则等,可以让我们写出可复用、灵活、可读性好、易扩展、易维护的代码
- 设计模式可以让我们写出易扩展的代码
- 持续重构可以时刻保持代码的可维护性等等
2. 面向对象、设计原则、设计模式、编程规范、重构 之间的关系
1、面向对象
现在,主流的编程范式或者是编程风格有三种,分别是面向过程、面向对象和函数式编程。面向对象这种编程风格又是这其中最主流的。现在比较流行的编程语言大部分都是面向对象编程语言。大部分项目也都是基于面向对象编程风格开发的。面向对象编程因为其具有丰富的特性(封装、抽象、继承、多态),可以实现很多复杂的设计思路,是很多设计原则、设计模式编码实现的基础
- 面向对象的四大特性:封装、抽象、继承、多态
- 面向对象编程与面向过程编程的区别和联系
- 面向对象分析、面向对象设计、面向对象编程
- 接口和抽象类的区别以及各自的应用场景
- 基于接口而非实现编程的设计思想
- 多用组合少用继承的设计思想
- 面向过程的贫血模型和面向对象的充血模型
2、设计原则
设计原则是指导代码设计的一些经验总结。设计原则听起来都比较抽象,定义描述都比较模糊,不同的人会有不同的解读。对于每一种设计原则,需要掌握它的设计初衷,能解决哪些编程问题,有哪些应用场景。只有这样,才能在项目中灵活恰当地应用这些原则
- SOLID 原则 -SRP 单一职责原则
- SOLID 原则 -OCP 开闭原则
- SOLID 原则 -LSP 里式替换原则
- SOLID 原则 -ISP 接口隔离原则
- SOLID 原则 -DIP 依赖倒置原则
- DRY 原则、KISS 原则、YAGNI 原则、LOD 法则
3、设计模式
设计模式是针对软件开发中经常遇到的一些设计问题,总结出来的一套解决方案或者设计思路。大部分设计模式要解决的都是代码的可扩展性问题
经典的设计模式有 23 种。随着编程语言的演进,一些设计模式(比如 Singleton)也随之过时,甚至成了反模式,一些则被内置在编程语言中(比如 Iterator),另外还有一些新的模式诞生(比如 Monostate)。它们又可以分为三大类:创建型、结构型、行为型
- 创建型
常用的有:单例模式、工厂模式(工厂方法和抽象工厂)、建造者模式
不常用的有:原型模式 - 结构型
常用的有:代理模式、桥接模式、装饰者模式、适配器模式
不常用的有:门面模式、组合模式、享元模式 - 行为型
常用的有:观察者模式、模板模式、策略模式、职责链模式、迭代器模式、状态模式
不常用的有:访问者模式、备忘录模式、命令模式、解释器模式、中介模式
4、编程规范
编程规范主要解决的是代码的可读性问题。编码规范相对于设计原则、设计模式,更加具体、更加偏重代码细节。对于编码规范,很多书籍已经讲得很好了(比如《重构》《代码大全》《代码整洁之道》等
5、代码重构
在软件开发中,只要软件在不停地迭代,就没有一劳永逸的设计。随着需求的变化,代码的不停堆砌,原有的设计必定会存在这样那样的问题。针对这些问题,就需要进行代码重构。重构是软件开发中非常重要的一个环节。持续重构是保持代码质量不下降的有效手段,能有效避免代码腐化到无可救药的地步
而重构的工具就是前面罗列的那些面向对象设计思想、设计原则、设计模式、编码规范。实际上,设计思想、设计原则、设计模式一个最重要的应用场景就是在重构的时候。对于重构,需要掌握以下几个知识点:
- 重构的目的(why)、对象(what)、时机(when)、方法(how)
- 保证重构不出错的技术手段:单元测试和代码的可测试性;
- 两种不同规模的重构:大重构(大规模高层次)和小重构(小规模低层次)
五者之间的联系
- 面向对象编程因为其具有丰富的特性(封装、抽象、继承、多态),可以实现很多复杂的设计思路,是很多设计原则、设计模式等编码实现的基础
- 设计原则是指导代码设计的一些经验总结,对于某些场景下,是否应该应用某种设计模式,具有指导意义。比如,“开闭原则”是很多设计模式(策略、模板等)的指导原则
- 设计模式是针对软件开发中经常遇到的一些设计问题,总结出来的一套解决方案或者设计思路。应用设计模式的主要目的是提高代码的可扩展性。从抽象程度上来讲,设计原则比设计模式更抽象。设计模式更加具体、更加可执行
- 编程规范主要解决的是代码的可读性问题。编码规范相对于设计原则、设计模式,更加具体、更加偏重代码细节、更加能落地。持续的小重构依赖的理论基础主要就是编程规范
- 重构作为保持代码质量不下降的有效手段,利用的就是面向对象、设计原则、设计模式、编码规范这些理论
实际上,面向对象、设计原则、设计模式、编程规范、代码重构,这五者都是保持或者提高代码质量的方法论,本质上都是服务于编写高质量代码这一件事的。在某个场景下,该不该用这个设计模式,那就看能不能提高代码的可扩展性;要不要重构,那就看重代码是否存在可读、可维护问题等

3. 面向对象与面向过程
3.1 什么是面向对象编程和面向对象编程语言?
面向对象编程的英文缩写是 OOP,全称是 Object Oriented Programming。对应地,面向对象编程语言的英文缩写是 OOPL,全称是 Object Oriented Programming Language
面向对象编程中有两个非常重要、非常基础的概念,那就是类(Class)和对象(Object)。这两个概念最早出现在 1960 年,在 Simula 这种编程语言中第一次使用。而面向对象编程这个概念第一次被使用是在 Smalltalk 这种编程语言中。Smalltalk 被认为是第一个真正意义上的面向对象编程语言
直到今天,如果不按照严格的定义来说,大部分编程语言都是面向对象编程语言,比如 Java、C++、Go、Python、C#、Ruby、JavaScript、Objective-C、Scala、PHP、Perl 等等。除此之外,大部分程序员在开发项目的时候,都是基于面向对象编程语言进行的面向对象编程
什么是面向对象编程?什么语言才算是面向对象编程语言?
- 面向对象编程是一种编程范式或编程风格。它以类或对象作为组织代码的基本单元,并将封装、抽象、继承、多态四个特性,作为代码设计和实现的基石
- 面向对象编程语言是支持类或对象的语法机制,并有现成的语法机制,能方便地实现面向对象编程四大特性(封装、抽象、继承、多态)的编程语言
一般来讲, 面向对象编程都是通过使用面向对象编程语言来进行的,但是,不用面向对象编程语言,照样可以进行面向对象编程。反过来讲,即便使用面向对象编程语言,写出来的代码也不一定是面向对象编程风格的,也有可能是面向过程编程风格的
理解面向对象编程及面向对象编程语言两个概念,其中最关键的一点就是理解面向对象编程的四大特性。这四大特性分别是:封装、抽象、继承、多态。不过也有另外一种说法,那就是只包含三大特性:封装、继承、多态,不包含抽象
3.2 如何判定某编程语言是否是面向对象编程语言?
对于什么是面向对象编程、什么是面向对象编程语言,并没有一个官方的、统一的定义。而且,从 1960 年,也就是 60 年前面向对象编程诞生开始,这两个概念就在不停地演化,所以,也无法给出一个明确的定义,也没有必要给出一个明确定义
实际上,面向对象编程从字面上,按照最简单、最原始的方式来理解,就是将对象或类作为代码组织的基本单元,来进行编程的一种编程范式或者编程风格,并不一定需要封装、抽象、继承、多态这四大特性的支持。但是,在进行面向对象编程的过程中,人们不停地总结发现,有了这四大特性,我们就能更容易地实现各种面向对象的代码设计思路
比如,在面向对象编程的过程中,经常会遇到 is-a 这种类关系(比如狗是一种动物),而继承这个特性就能很好地支持这种 is-a 的代码设计思路,并且解决代码复用的问题,所以,继承就成了面向对象编程的四大特性之一。但是随着编程语言的不断迭代、演化,人们发现继承这种特性容易造成层次不清、代码混乱,所以,很多编程语言在设计的时候就开始摒弃继承特性,比如 Go 语言。但是,并不能因为它摒弃了继承特性,就一刀切地认为它不是面向对象编程语言了
只要某种编程语言支持类或对象的语法概念,并且以此作为组织代码的基本单元,那就可以被粗略地认为它就是面向对象编程语言了。至于是否有现成的语法机制,完全地支持了面向对象编程的四大特性、是否对四大特性有所取舍和优化,可以不作为判定的标准。按照严格的定义,很多语言都不能算得上面向对象编程语言,但按照不严格的定义来讲,现在流行的大部分编程语言都是面向对象编程语言
3.3 什么是面向对象分析和面向对象设计?
面向对象分析英文缩写是 OOA,全称是 Object Oriented Analysis;面向对象设计的英文缩写是 OOD,全称是 Object Oriented Design。OOA、OOD、OOP 三个连在一起就是面向对象分析、设计、编程(实现),正好是面向对象软件开发要经历的三个阶段
面向对象分析与设计中的“分析”和“设计”这两个词,简单类比软件开发中的需求分析、系统设计。之所以在前面加“面向对象”这几个字,因为是围绕着对象或类来做需求分析和设计的。分析和设计两个阶段最终的产出是类的设计,包括程序被拆解为哪些类,每个类有哪些属性方法,类与类之间如何交互等等。它们比其他的分析和设计更加具体、更加落地、更加贴近编码,更能够顺利地过渡到面向对象编程环节。这也是面向对象分析和设计,与其他分析和设计最大的不同点
3.4 封装、抽象、继承、多态分别可以解决哪些编程问题?
1、封装(Encapsulation)
封装也叫作信息隐藏或者数据访问保护。类通过暴露有限的访问接口,授权外部仅能通过类提供的方式(或者叫函数)来访问内部信息或者数据。对于封装这个特性,需要编程语言本身提供一定的语法机制来支持。这个语法机制就是访问权限控制。Java 语言中的 private、public 等关键字就是访问权限控制语法。private 关键字修饰的属性只能类本身访问,可以保护其不被类之外的代码直接访问
public class Wallet {
private BigDecimal balance;
private long balanceLastModifiedTime;
public Wallet() {
this.balance = BigDecimal.ZERO;
this.balanceLastModifiedTime = System.currentTimeMillis();
}
public void increaseBalance(BigDecimal increasedAmount) {
if (increasedAmount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException("...");
}
this.balance.add(increasedAmount);
this.balanceLastModifiedTime = System.currentTimeMillis();
}
}
上面代码中只暴露了 increaseBalance() 方法,并没有暴露 set() 方法。对于 balanceLastModifiedTime 这个属性,它完全是跟 balance 这个属性的修改操作绑定在一起的。只有在 balance 修改的时候,这个属性才会被修改。所以,把 balanceLastModifiedTime 这个属性的修改操作完全封装在了 increaseBalance() 方法,不对外暴露任何修改这个属性的方法和业务细节。这样也可以保证 balance 和 balanceLastModifiedTime 两个数据的一致性
封装的意义是什么?它能解决什么编程问题?
- 如果对类中属性的访问不做限制,那任何代码都可以访问、修改类中的属性,虽然这样看起来更加灵活,但从另一方面来说,过度灵活也意味着不可控,属性可以随意被修改,而且修改逻辑可能散落在代码中的各个角落,势必影响代码的可读性、可维护性
- 除此之外,类仅仅通过有限的方法暴露必要的操作,也能提高类的易用性。如果把类属性都暴露给类的调用者,调用者想要正确地操作这些属性,就势必要对业务细节有足够的了解。而这对于调用者来说也是一种负担。相反,如果我们将属性封装起来,暴露少许的几个必要的方法给调用者使用,调用者就不需要了解太多背后的业务细节,用错的概率就减少很多
2、抽象(Abstraction)
抽象讲的是如何隐藏方法的具体实现,让调用者只需要关心方法提供了哪些功能,并不需要知道这些功能是如何实现的。在面向对象编程中,常借助编程语言提供的接口类(比如 Java 中的 interface 关键字语法)或者抽象类(比如 Java 中的 abstract 关键字语法)这两种语法机制,来实现抽象这一特性。这里用“接口类”而不是“接口”,是因为“接口”这个词太泛化,可以指很多概念,比如 API 接口等,所以用“接口类”特指编程语言提供的接口语法
public interface IPictureStorage {
void savePicture(Picture picture);
Image getPicture(String pictureId);
void deletePicture(String pictureId);
void modifyMetaInfo(String pictureId, PictureMetaInfo metaInfo);
}
public class PictureStorage implements IPictureStorage {
// ... 省略其他属性...
@Override
public void savePicture(Picture picture) {
... }
@Override
public Image getPicture(String pictureId) {
... }
@Override
public void deletePicture(String pictureId) {
... }
@Override
public void modifyMetaInfo(String pictureId, PictureMetaInfo metaInfo) {
... }
}
实际上,抽象这个特性是非常容易实现的,并不需要非得依靠接口类或者抽象类这些特殊语法机制来支持。换句话说,并不是说一定要为实现类(PictureStorage)抽象出接口类(IPictureStorage),才叫作抽象。即便不编写 IPictureStorage 接口类,单纯的 PictureStorage 类本身就满足抽象特性
之所以这么说,是因为类的方法是通过编程语言中的“函数”这一语法机制来实现的。通过函数包裹具体的实现逻辑,这本身就是一种抽象。调用者在使用函数的时候,并不需要去研究函数内部的实现逻辑,只需要通过函数的命名、注释或者文档,了解其提供了什么功能,就可以直接使用了,并不需要了解它的底层代码是怎么实现的
前面提到,抽象有时候会被排除在面向对象的四大特性之外,因为抽象这个概念是一个非常通用的设计思想,并不单单用在面向对象编程中,也可以用来指导架构设计等。而且这个特性也并不需要编程语言提供特殊的语法机制来支持,只需要提供“函数”这一非常基础的语法机制,就可以实现抽象特性、所以,它没有很强的“特异性”,有时候并不被看作面向对象编程的特性之一
抽象的意义是什么?它能解决什么编程问题?
- 上升一个思考层面的话,抽象及其前面讲到的封装都是人类处理复杂性的有效手段。在面对复杂系统的时候,人脑能承受的信息复杂程度是有限的,所以我们必须忽略掉一些非关键性的实现细节。而抽象作为一种只关注功能点不关注实现的设计思路,正好帮我们的大脑过滤掉许多非必要的信息
- 抽象作为一个非常宽泛的设计思想,在代码设计中,起到非常重要的指导作用。很多设计原则都体现了抽象这种设计思想,比如基于接口而非实现编程、开闭原则(对扩展开放、对修改关闭)、代码解耦(降低代码的耦合性)等
- 在定义(或者叫命名)类的方法的时候,也要有抽象思维,不要在方法定义中,暴露太多的实现细节,以保证在某个时间点需要改变方法的实现逻辑的时候,不用去修改其定义
3、继承(Inheritance)
继承是用来表示类之间的 is-a 关系,比如猫是一种哺乳动物。从继承关系上来讲,继承可以分为两种模式,单继承和多继承。单继承表示一个子类只继承一个父类,多继承表示一个子类可以继承多个父类,比如猫既是哺乳动物,又是爬行动物
为了实现继承这个特性,编程语言需要提供特殊的语法机制来支持,比如 Java 使用 extends 关键字来实现继承,C++ 使用冒号(class B : public A),Python 使用 paraentheses(),Ruby 使用 <。不过,有些编程语言只支持单继承,不支持多重继承,比如 Java、PHP、C#、Ruby 等,而有些编程语言既支持单重继承,也支持多重继承,比如 C++、Python、Perl 等
继承存在的意义是什么?它能解决什么编程问题?
- 继承最大的一个好处就是代码复用。假如两个类有一些相同的属性和方法,就可以将这些相同的部分,抽取到父类中,让两个子类继承父类。这样,两个子类就可以重用父类中的代码,避免代码重复。不过,这一点也并不是继承所独有的,也可以通过其他方式来解决这个代码复用的问题,比如利用组合关系而不是继承关系
- 上升一个思维层面,去思考继承这一特性,从人类认知的角度上来说,是一种 is-a 关系。通过继承来关联两个类,反应真实世界中的这种关系,非常符合人类的认知,而且,从设计的角度来说,也有一种结构美感
- 但过度使用继承,继承层次过深过复杂,就会导致代码可读性、可维护性变差。为了了解一个类的功能,不仅需要查看这个类的代码,还需要按照继承关系一层一层地往上查看“父类、父类的父类……”的代码。还有,子类和父类高度耦合,修改父类的代码,会直接影响到子类
所以,继承这个特性也是一个非常有争议的特性。很多人觉得继承是一种反模式。应该尽量少用,甚至不用。可以联系“多用组合少用继承”这种设计思想进行理解
4、多态(Polymorphism)
多态是指,子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现
public class DynamicArray {
private static final int DEFAULT_CAPACITY = 10;
protected int size = 0;
protected int capacity = DEFAULT_CAPACITY;
protected Integer[] elements = new Integer[DEFAULT_CAPACITY];
public int size() {
return this.size;
}
public Integer get(int index) {
return elements[index];
}
//... 省略 n 多方法...
public void add(Integer e) {
ensureCapacity();
elements[size++] = e;
}
protected void ensureCapacity() {
//... 如果数组满了就扩容... 代码省略...
}
}
public class SortedDynamicArray extends DynamicArray {
@Override
public void add(Integer e) {
ensureCapacity();
for (int i = size - 1; i >= 0; --i) {
// 保证数组中的数据有序
if (elements[i] > e) {
elements[i + 1] = elements[i];
} else {
break;
}
}
elements[i + 1] = e;
++size;
}
}
public class Example {
public static void test(DynamicArray dynamicArray) {
dynamicArray.add(5);
dynamicArray.add(1);
dynamicArray.add(3);
for (int i = 0; i < dynamicArray.size(); ++i)
}
System.out.println(dynamicArray[i]);
}
public static void main(String args[]) {
DynamicArray dynamicArray = new SortedDynamicArray();
test(dynamicArray); // 打印结果:1、3、5
}
}
多态这种特性也需要编程语言提供特殊的语法机制来实现。在上面的例子中,用到了三个语法机制来实现多态
- 第一个语法机制是编程语言要支持父类对象可以引用子类对象,也就是可以将 SortedDynamicArray 传递给 DynamicArray
- 第二个语法机制是编程语言要支持继承,也就是 SortedDynamicArray 继承了 DynamicArray,才能将 SortedDyamicArray 传递给 DynamicArray
- 第三个语法机制是编程语言要支持子类可以重写(Override)父类中的方法,也就是 SortedDyamicArray 重写了 DynamicArray 中的 add() 方法
通过这三种语法机制配合在一起,我们就实现了在 test() 方法中,子类 SortedDyamicArray 替换父类 DynamicArray,执行子类 SortedDyamicArray 的 add()方法,也就是实现了多态特性
对于多态特性的实现方式,除了利用“继承加方法重写”这种实现方式之外,还有其他两种比较常见的的实现方式,一个是利用接口类语法,另一个是利用 duck-typing 语法。不过,并不是每种编程语言都支持接口类或者 duck-typing 这两种语法机制,比如 C++就不支持接口类语法,而 duck-typing 只有一些动态语言才支持,比如 Python、JavaScript 等
利用接口类来实现多态特性
public interface Iterator {
String hasNext();
String next();
String remove();
}
public class Array implements Iterator {
private String[] data;
public String hasNext() {
...}
public String next() {
...}
public String remove() {
...}
//... 省略其他方法...
}
public class LinkedList implements Iterator {
private LinkedListNode head;
public String hasNext() {
...}
public String next() {
...}
public String remove() {
...}
//... 省略其他方法...
}
public class Demo {
private static void print(Iterator iterator) {
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
public static void main(String[] args) {
Iterator arrayIterator = new Array();
print(arrayIterator);
Iterator linkedListIterator = new LinkedList();
print(linkedListIterator);
}
}
在这段代码中,Iterator 是一个接口类,定义了一个可以遍历集合数据的迭代器。Array 和 LinkedList 都实现了接口类 Iterator。通过传递不同类型的实现类(Array、LinkedList)到 print(Iterator iterator) 函数中,支持动态的调用不同的 next()、hasNext() 实现
用 duck-typing 来实现多态特性
class Logger:
def record(self):
print(“I write a log into file.”)
class DB:
def record(self):
print(“I insert data into db. ”)
def test(recorder):
recorder.record()
def demo():
logger = Logger()
db = DB()
test(logger)
test(db)
duck-typing 实现多态的方式非常灵活。Logger 和 DB 两个类没有任何关系,既不是继承关系,也不是接口和实现的关系,但是只要它们都有定义了 record() 方法,就可以被传递到 test() 方法中,在实际运行的时候,执行对应的 record() 方法
也就是说,只要两个类具有相同的方法,就可以实现多态,并不要求两个类之间有任何关系,这就是所谓的 duck-typing,是一些动态语言所特有的语法机制。而像 Java 这样的静态语言,通过继承实现多态特性,必须要求两个类之间有继承关系,通过接口实现多态特性,类必须实现对应的接口
多态特性存在的意义是什么?它能解决什么编程问题?
- 多态特性能提高代码的可扩展性和复用性
- 多态也是很多设计模式、设计原则、编程技巧的代码实现基础,比如策略模式、基于接口而非实现编程、依赖倒置原则、里式替换原则、利用多态去掉冗长的 if-else 语句等等
3.5 什么是面向过程编程与面向过程编程语言?
面向过程编程也是一种编程范式或编程风格。它以过程(可以为理解方法、函数、操作)作为组织代码的基本单元,以数据(可以理解为成员变量、属性)与方法相分离为最主要的特点。面向过程风格是一种流程化的编程风格,通过拼接一组顺序执行的方法来操作数据完成一项功能
面向过程编程语言首先是一种编程语言。它最大的特点是不支持类和对象两个语法概念,不支持丰富的面向对象编程特性(比如继承、多态、封装),仅支持面向过程编程
用如下案例来看看用面向过程和面向对象两种编程风格,编写出来的代码有什么不同
有一个记录了用户信息的文本文件 users.txt,每行文本的格式是 name&age&gender(比如,小
王 &28& 男)。现在想要从 users.txt 文件中逐行读取用户信息,然后格式化成 name\tage\tgender(其中,\t 是分隔符)这种文本格式,并且按照 age 从小到达排序之后,重新写入到另一个文本文件 formatted_users.txt 中
使用 C 语言这种面向过程的编程语言来编写:
struct User {
char name[64];
int age;
char gender[16];
};
struct User parse_to_user(char* text) {
// 将 text(“小王 &28& 男”) 解析成结构体 struct User
}
char* format_to_text(struct User user) {
// 将结构体 struct User 格式化成文本(" 小王\t28\t 男 ")
}
void sort_users_by_age(struct User users[]) {
// 按照年龄从小到大排序 users
}
void format_user_file(char* origin_file_path, char* new_file_path) {
// open files...
struct User users[1024]; // 假设最大 1024 个用户
int count = 0;
while(1) {
// read until the file is empty
struct User user = parse_to_user(line);
users[count++] = user;
}
sort_users_by_age(users);
for (int i = 0; i < count; ++i) {
char* formatted_user_text = format_to_text(users[i]);
// write to new file...
}
// close files...
}
int main(char** args, int argv) {
format_user_file("/home/zheng/user.txt", "/home/zheng/formatted_users.txt");
}
使用 Java 这种面向对象的编程语言来编写:
public class User {
private String name;
private int age;
private String gender;
public User(String name, int age, String gender) {
this.name = name;
this.age = age;
this.gender = gender;
}
public static User praseFrom(String userInfoText) {
// 将 text(“小王 &28& 男”) 解析成类 User
}
public String formatToText() {
// 将类 User 格式化成文本(" 小王\t28\t 男 ")
}
}
public class UserFileFormatter {
public void format(String userFile, String formattedUserFile) {
// Open files...
List users = new ArrayList<>();
while (1) {
// read until file is empty
// read from file into userText...
User user = User.parseFrom(userText);
users.add(user);
}
// sort users by age...
for (int i = 0; i < users.size(); ++i) {
String formattedUserText = user.formatToText();
// write to new file...
}
// close files...
}
}
public class MainApplication {
public static void main(Sring[] args) {
UserFileFormatter userFileFormatter = new UserFileFormatter();
userFileFormatter.format("/home/zheng/users.txt", "/home/zheng/formatted_us
}
}
从上面的代码中,可以看出面向过程和面向对象最基本的区别就是,代码的组织方式不同。面向过程风格的代码被组织成了一组方法集合及其数据结构(struct User),方法和数据结构的定义是分开的。面向对象风格的代码被组织成一组类,方法和数据结构被绑定一起,定义在类中
3.6 面向对象编程相比面向过程编程有哪些优势?
1、OOP 更加能够应对大规模复杂程序的开发
当需求足够简单,整个程序的处理流程只有一条主线,很容易被划分成顺序执行的几个步骤,然后逐句翻译成代码,这就非常适合采用面向过程这种面条式的编程风格来实现
但对于大规模复杂程序的开发来说,整个程序的处理流程错综复杂,并非只有一条主线。如果把整个程序的处理流程画出来的话,会是一个网状结构。如果再用面向过程编程这种流程化、线性的思维方式,去翻译这个网状结构,去思考如何把程序拆解为一组顺序执行的方法,就会比较吃力
面向对象编程是以类为思考对象。在进行面向对象编程的时候,并不是一上来就去思考,如何将复杂的流程拆解为一个一个方法,而是采用曲线救国的策略,先去思考如何给业务建模,如何将需求翻译为类,如何给类之间建立交互关系,而完成这些工作完全不需要考虑错综复杂的处理流程。当有了类的设计之后,然后再像搭积木一样,按照处理流程,将类组装起来形成整个程序。这种开发模式、思考问题的方式,能在应对复杂程序开发的时候,思路更加清晰
除此之外,面向对象编程还提供了一种更加清晰的、更加模块化的代码组织方式。比如开发一个系统,业务逻辑复杂,代码量很大,可能要定义数百个函数、数百个数据结构,那如何分门别类地组织这些函数和数据结构,才能不至于看起来比较凌乱呢?类就是一种非常好的组织这些函数和数据结构的方式,是一种将代码模块化的有效手段
像 C 语言这种面向过程的编程语言,也可以按照功能的不同,把函数和数据结构放到不同的文件里,以达到给函数和数据结构分类的目的,照样可以实现代码的模块化。只不过面向对象编程本身提供了类的概念,强制你做这件事情,而面向过程编程并不强求
实际上,利用面向过程的编程语言照样可以写出面向对象风格的代码,只不过可能会比用面向对象编程语言来写面向对象风格的代码,付出的代价要高一些。而且,面向过程编程和面向对象编程并非完全对立的。很多软件开发中,尽管利用的是面向过程的编程语言,也都有借鉴面向对象编程的一些优点
2、OOP 风格的代码更易复用、易扩展、易维护
面向过程编程是一种非常简单的编程风格,并没有像面向对象编程那样提供丰富的特性。而面向对象编程提供的封装、抽象、继承、多态这些特性,能极大地满足复杂的编程需求,能方便我们写出更易复用、易扩展、易维护的代码
- 封装特性:封装特性是面向对象编程相比于面向过程编程的一个最基本的区别,因为它基于的是面向对象编程中最基本的类的概念
面向对象编程通过类这种组织代码的方式,将数据和方法绑定在一起,通过访问权限控制,只允许外部调用者通过类暴露的有限方法访问数据,而不会像面向过程编程那样,数据可以被任意方法随意修改。因此,面向对象编程提供的封装特性更有利于提高代码的易维护性 - 抽象特性:函数本身就是一种抽象,它隐藏了具体的实现
在使用函数的时候,只需要了解函数具有什么功能,而不需要了解它是怎么实现的。从这一点上,不管面向过程编程还是是面向对象编程,都支持抽象特性。但面向对象编程还提供了其他抽象特性的实现方式。这些实现方式是面向过程编程所不具备的,比如基于接口实现的抽象。基于接口的抽象,可以在不改变原有实现的情况下,轻松替换新的实现逻辑,提高了代码的可扩展性 - 继承特性:继承特性是面向对象编程相比于面向过程编程所特有的两个特性之一(另一个是多态)
两个类有一些相同的属性和方法,我们就可以将这些相同的代码,抽取到父类中,让两个子类继承父类。这样两个子类也就可以重用父类中的代码,避免了代码重复写多遍,提高了代码的复用性 - 多态特性:在需要修改一个功能实现的时候,可以通过实现一个新的子类的方式,在子类中重写原来的功能逻辑,用子类替换父类
在实际的代码运行过程中,调用子类新的功能逻辑,而不是在原有代码上做修改。这就遵从了“对修改
关闭、对扩展开放”的设计原则,提高代码的扩展性。除此之外,利用多态特性,不同的类对象可以传递给相同的方法,执行不同的代码逻辑,提高了代码的复用性
基于这四大特性,利用面向对象编程,可以更轻松地写出易复用、易扩展、易维护的代码。当然,不能说利用面向过程风格就不可以写出易复用、易扩展、易维护的代码,但没有四大特性的帮助,付出的代价可能就要高一些
3、OOP 语言更加人性化、更加高级、更加智能
人类最开始跟机器打交道是通过 0、1 这样的二进制指令,然后是汇编语言,再之后才出现了高级编程语言。在高级编程语言中,面向过程编程语言又早于面向对象编程语言出现。之所以先出现面向过程编程语言,是因为跟机器交互的方式,从二进制指令、汇编语言到面向过程编程语言,是一个非常自然的过渡,都是一种流程化的、面条式的编程风格,用一组指令顺序操作数据,来完成一项任务
从指令到汇编再到面向过程编程语言,跟机器打交道的方式在不停地演进,从中很容易发现这样一条规律,那就是编程语言越来越人性化,让人跟机器打交道越来越容易。笼统点讲,就是编程语言越来越高级。实际上,在面向过程编程语言之后,面向对象编程语言的出现,也顺应了这样的发展规律,也就是说,面向对象编程语言比面向过程编程语言更加高级!
跟二进制指令、汇编语言、面向过程编程语言相比,面向对象编程语言的编程套路、思考问题的方式,是完全不一样的。前三者是一种计算机思维方式,而面向对象是一种人类的思维方式。在用前面三种语言编程的时候,是在思考如何设计一组指令,告诉机器去执行这组指令,操作某些数据,完成某个任务。而在进行面向对象编程时候,是在思考如何给业务建模,如何将真实的世界映射为类或者对象,这让我们更加能聚焦到业务本身,而不是思考如何跟机器打交道。可以这么说,越高级的编程语言离机器越“远”,离人类越“近”,越“智能”
3.7 哪些代码设计看似是面向对象,实际是面向过程的?
1、滥用 getter、setter 方法
目前开发中,通常在定义完类的属性之后,会顺手把这些属性的 getter、setter 方法都定义上。或者直接用 IDE 或者 Lombok 插件(如果是 Java 项目的话)自动生成所有属性的 getter、setter 方法。面向对象封装的定义是:通过访问权限控制,隐藏内部数据,外部仅能通过类提供的有限的接口访问、修改内部数据。所以,暴露不应该暴露的 setter 方法,明显违反了面向对象的封装特性。数据没有访问权限控制,任何代码都可以随意修改它,代码就退化成了面向过程编程风格的了
如下例:
public class ShoppingCart {
private int itemsCount;
private double totalPrice;
private List<ShoppingCartItem> items = new ArrayList<>();
public int getItemsCount() {
return this.itemsCount;
}
public void setItemsCount(int itemsCount) {
this.itemsCount = itemsCount;
}
public double getTotalPrice() {
return this.totalPrice;
}
public void setTotalPrice(double totalPrice) {
this.totalPrice = totalPrice;
}
public List<ShoppingCartItem> getItems() {
return this.items;
}
public void addItem(ShoppingCartItem item) {
items.add(item);
itemsCount++;
totalPrice += item.getPrice();
}
// ... 省略其他方法...
}
在这段代码中有三个私有(private)属性:itemsCount、totalPrice、items
-
对于 itemsCount、totalPrice 两个属性,定义了它们的 getter、setter 方法。这样一来,虽然将它们定义成 private 私有属性,但是提供了 public 的 getter、setter 方法,这就跟将这两个属性定义为 public 公有属性,没有什么两样了。外部可以通过 setter 方法随意地修改这两个属性的值。除此之外,任何代码都可以随意调用 setter 方法,来重新设置 itemsCount、totalPrice 属性的值,这也会导致其跟 items 属性的值不一致
-
对于 items 属性,定义了它的 getter 方法和 addItem() 方法,并没有定义它的 setter 方法。但 items 属性的 getter 方法,返回的是一个 List 集合容器。外部调用者在拿到这个容器之后,是可以操作容器内部数据的,也就是说,外部代码还是能修改 items 中的数据,如:
ShoppingCart cart = new ShoppCart(); ... cart.getItems().clear(); // 清空购物车这样的代码写法,会导致 itemsCount、totalPrice、items 三者数据不一致。不应该将清空购物车的业务逻辑暴露给上层代码。正确的做法应该是,在 ShoppingCart 类中定义一个 clear() 方法,将清空购物车的业务逻辑封装在里面,透明地给调用者使用。如下:
public class ShoppingCart { // ... 省略其他代码... public void clear() { items.clear(); itemsCount = 0; totalPrice = 0.0; } }假如需要查看购物车中都买了啥,那这个时候,ShoppingCart 类不得不提供 items 属性的 getter 方法了,可以通过 Java 提供的
Collections.unmodifiableList()方法,让 getter 方法返回一个不可被修改的UnmodifiableList 集合容器,而这个容器类重写了 List 容器中跟修改数据相关的方法,比如 add()、clear() 等方法。一旦调用这些修改数据的方法,代码就会抛出 UnsupportedOperationException 异常,这样就避免了容器中的数据被修改,如:public class ShoppingCart { // ... 省略其他代码... public List<ShoppingCartItem> getItems() { return Collections.unmodifiableList(this.items); } } public class UnmodifiableList<E> extends UnmodifiableCollection<E> implements List<E> { public boolean add(E e) { throw new UnsupportedOperationException(); } public void clear() { throw new UnsupportedOperationException(); } // ... 省略其他代码... } ShoppingCart cart = new ShoppingCart(); List<ShoppingCartItem> items = cart.getItems(); items.clear(); // 抛出 UnsupportedOperationException 异常这样还是存在问题,当调用者通过 ShoppingCart 的 getItems() 获取到 items 之后,虽然没法修改容器中的数据,但仍然可以修改容器中每个对象(ShoppingCartItem)的数据,如:
ShoppingCart cart = new ShoppingCart(); cart.add(new ShoppingCartItem(...)); List<ShoppingCartItem> items = cart.getItems(); ShoppingCartItem item = items.get(0); item.setPrice(19.0); // 这里修改了 item 的价格属性
2、滥用全局变量和全局方法
在面向对象编程中,常见的全局变量有单例类对象、静态成员变量、常量等,常见的全局方法有静态方法
- 单例类对象在全局代码中只有一份,所以,它相当于一个全局变量
- 静态成员变量归属于类上的数据,被所有的实例化对象所共享,也相当于一定程度上的全局变量
- 常量是一种非常常见的全局变量,比如一些代码中的配置参数,一般都设置为常量,放到一个 Constants 类中
- 静态方法一般用来操作静态变量或者外部数据。如各种 Utils 类,里面的方法一般都会定义成静态方法,在不用创建对象的情况下,直接拿来使用。静态方法将方法与数据分离,破坏了封装特性,是典型的面向过程风格
Constants 类
public class Constants {
public static final String MYSQL_ADDR_KEY = "mysql_addr";
public static final String MYSQL_DB_NAME_KEY = "db_name";
public static final String MYSQL_USERNAME_KEY = "mysql_username";
public static final String MYSQL_PASSWORD_KEY = "mysql_password";
public static final String REDIS_DEFAULT_ADDR = "192.168.7.2:7234";
public static final int REDIS_DEFAULT_MAX_TOTAL = 50;
public static final int REDIS_DEFAULT_MAX_IDLE = 50;
public static final int REDIS_DEFAULT_MIN_IDLE = 20;
// ...
}
在上面这段代码中,把程序中所有用到的常量,都集中地放到这个 Constants 类中。但定义一个如此大而全的 Constants 类,并不是一种很好的设计思路
- 首先,这样的设计会影响代码的可维护性
如果参与开发同一个项目的工程师有很多,在开发过程中,可能都要涉及修改这个类,比如往这个类里添加常量,那这个类就会变得越来越大,成百上千行都有可能,查找修改某个常量也会变得比较费时,而且还会增加提交代码冲突的概率 - 其次,这样的设计还会增加代码的编译时间
当 Constants 类中包含很多常量定义的时候,依赖这个类的代码就会很多。那每次修改 Constants 类,都会导致依赖它的类文件重新编译,因此会浪费很多不必要的编译时间。对于一个非常大的工程项目来说,编译一次项目花费的时间可能是几分钟,甚至几十分钟。而我们在开发过程中,每次运行单元测试,都会触发一次编译的过程,这个编译时间就有可能会影响到我们的开发效率 - 最后,这样的设计还会影响代码的复用性
如果要在另一个项目中,复用本项目开发的某个类,而这个类又依赖 Constants 类。即便这个类只依赖 Constants 类中的一小部分常量,仍然需要把整个 Constants 类也一并引入,也就引入了很多无关的常量到新的项目中
如何改进 Constants 类的设计?
第一种是将 Constants 类拆解为功能更加单一的多个类,比如跟 MySQL 配置相关的常量,放到 MysqlConstants 类中;跟 Redis 配置相关的常量,放到RedisConstants 类中
另一种我个人觉得更好的设计思路,那就是并不单独地设计 Constants 常量类,而是哪个类用到了某个常量,就把这个常量定义到这个类中。比如,RedisConfig 类用到了 Redis 配置相关的常量,那就直接将这些常量定义在 RedisConfig 中,这样也提高了类设计的内聚性和代码的复用性
Utils 类
Utils 类的出现是基于:如果有两个类 A 和 B,它们要用到一块相同的功能逻辑,为了避免代码重复,不应该在两个类中,将这个相同的功能逻辑,重复地实现两遍
面向对象特性的继承可以实现代码复用。利用继承特性,把相同的属性和方法,抽取出来,定义到父类中。子类复用父类中的属性和方法,达到代码复用的目的。但是,有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系,比如 Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。仅仅为了代码复用,生硬地抽象出一个父类出来,会影响到代码的可读性
既然继承不能解决这个问题,可以定义一个新的的类,实现 URL 拼接和分割的方法。而拼接和分割两个方法,不需要共享任何数据,所以新的类不需要定义任何属性,这个时候,就可以把它定义为只包含静态方法的 Utils 类了
实际上,只包含静态方法不包含任何属性的 Utils 类,是彻彻底底的面向过程的编程风格。但这并不是说,就要杜绝使用 Utils 类了。实际上,从 Utils 类存在的目的来看,它在软件开发中还是挺有用的,能解决代码复用问题。所以,并不是说完全不能用 Utils 类,而是说,要尽量避免滥用,不要不加思考地随意去定义 Utils 类
3、定义数据和方法分离的类
传统的 MVC 结构分为 Model 层、Controller 层、View 层这三层。在做前后端分离之后,三层结构在后端开发中,会稍微有些调整,被分为 Controller 层、Service 层、Repository 层
- Controller 层负责暴露接口给前端调用,Service 层负责核心业务逻辑,Repository 层负责数据读写
- 而在每一层中,又会定义相应的 VO(View Object)、BO(Business Object)、Entity
- 一般情况下,VO、BO、Entity 中只会定义数据,不会定义方法,所有操作这些数据的业务逻辑都定义在对应的 Controller 类、Service 类、Repository 类中。这就是典型的面向过程的编程风格
实际上,这种开发模式叫作基于贫血模型的开发模式,也是现在非常常用的一种 Web 项目的开发模式
3.8 在面向对象编程中,为什么容易写出面向过程风格的代码?
在生活中,你去完成一个任务,你一般都会思考,应该先做什么、后做什么,如何一步一步地顺序执行一系列操作,最后完成整个任务。面向过程编程风格恰恰符合人的这种流程化思维方式
而面向对象编程风格正好相反。它是一种自底向上的思考方式。它不是先去按照执行流程来分解任务,而是将任务翻译成一个一个的小的模块(也就是类),设计类之间的交互,最后按照流程将类组装起来,完成整个任务。这样的思考路径比较适合复杂程序的开发,但并不是特别符合人类的思考习惯
除此之外,面向对象编程要比面向过程编程难一些。在面向对象编程中,类的设计还是挺需要技巧,挺需要一定设计经验的。要去思考如何封装合适的数据和方法到一个类里,如何设计类之间的关系,如何设计类之间的交互等等诸多设计问题
面向对象编程和面向过程编程的使用
- 如果开发的是微小程序,或者是一个数据处理相关的代码,以算法为主,数据为辅,那脚本式的面向过程的编程风格就更适合一些
- 实际上,面向过程编程是面向对象编程的基础,面向对象编程离不开基础的面向过程编程。仔细想想,类中每个方法的实现逻辑,不就是面向过程风格的代码吗
- 除此之外,面向对象和面向过程两种编程风格,也并不是非黑即白、完全对立的。在用面向对象编程语言开发的软件中,面向过程风格的代码并不少见,甚至在一些标准的开发库(比如 JDK、Apache Commons、Google Guava)中,也有很多面向过程风格的代码
- 不管使用面向过程还是面向对象哪种风格来写代码,最终的目的还是写出易维护、易读、易复用、易扩展的高质量代码
4. 接口与抽象类
在面向对象编程中,抽象类和接口是两个经常被用到的语法概念,是面向对象四大特性,以及很多设计模式、设计思想、设计原则编程实现的基础。比如,可以使用接口来实现面向对象的抽象特性、多态特性和基于接口而非实现的设计原则,使用抽象类来实现面向对象的继承特性和模板设计模式等等
不过,并不是所有的面向对象编程语言都支持这两个语法概念,比如,C++ 这种编程语言只支持抽象类,不支持接口;而像 Python 这样的动态编程语言,既不支持抽象类,也不支持接口。尽管有些编程语言没有提供现成的语法来支持接口和抽象类,但仍然可以通过一些手段来模拟实现这两个语法概念
4.1 什么是抽象类和接口?
1、抽象类的定义
下面这段代码是一个比较典型的抽象类的使用场景(模板设计模式)。Logger 是一个记录日志的抽象类,FileLogger 和 MessageQueueLogger 继承 Logger,分别实现两种不同的日志记录方式:记录日志到文件中和记录日志到消息队列中。FileLogger 和 MessageQueueLogger 两个子类复用了父类 Logger 中的 name、enabled、minPermittedLevel 属性和 log() 方法,但因为这两个子类写日志的方式不同,它们又各自重写了父类中的 doLog() 方法
// 抽象类
public abstract class Logger {
private String name;
private boolean enabled;
private Level minPermittedLevel;
public Logger(String name, boolean enabled, Level minPermittedLevel) {
this.name = name;
this.enabled = enabled;
this.minPermittedLevel = minPermittedLevel;
}
public void log(Level level, String message) {
boolean loggable = enabled && (minPermittedLevel.intValue() <= level.intVal
if (!loggable) return;
doLog(level, message);
}
protected abstract void doLog(Level level, String message);
}
// 抽象类的子类:输出日志到文件
public class FileLogger extends Logger {
private Writer fileWriter;
public FileLogger(String name, boolean enabled, Level minPermittedLevel, String filepath) {
super(name, enabled, minPermittedLevel);
this.fileWriter = new FileWriter(filepath);
}
@Override
public void doLog(Level level, String mesage) {
// 格式化 level 和 message, 输出到日志文件
fileWriter.write(...);
}
}
// 抽象类的子类: 输出日志到消息中间件 (比如 kafka)
public class MessageQueueLogger extends Logger {
private MessageQueueClient msgQueueClient;
public MessageQueueLogger(String name, boolean enabled,
Level minPermittedLevel, MessageQueueClient msgQueueClient) {
super(name, enabled, minPermittedLevel);
this.msgQueueClient = msgQueueClient;
}
@Override
protected void doLog(Level level, String mesage) {
// 格式化 level 和 message, 输出到消息中间件
msgQueueClient.send(...);
}
}
- 抽象类不允许被实例化,只能被继承。也就是说,不能 new 一个抽象类的对象出来(
Logger logger = new Logger(…);会报编译错误) - 抽象类可以包含属性和方法。方法既可以包含代码实现(比如 Logger 中的 log() 方法),也可以不包含代码实现(比如 Logger 中的 doLog() 方法)。不包含代码实现的方法叫作抽象方法
- 子类继承抽象类,必须实现抽象类中的所有抽象方法。对应到示例代码中就是,所有继承 Logger 抽象类的子类,都必须重写 doLog() 方法
2、接口的定义
下面这段代码是一个比较典型的接口的使用场景。通过 Java 中的 interface 关键字定义了一个 Filter 接口。AuthencationFilter 和 RateLimitFilter 是接口的两个实现类,分别实现了对 RPC 请求鉴权和限流的过滤功能
// 接口
public interface Filter {
void doFilter(RpcRequest req) throws RpcException;
}
// 接口实现类:鉴权过滤器
public class AuthencationFilter implements Filter {
@Override
public void doFilter(RpcRequest req) throws RpcException {
//... 鉴权逻辑..
}
}
// 接口实现类:限流过滤器
public class RateLimitFilter implements Filter {
@Override
public void doFilter(RpcRequest req) throws RpcException {
//... 限流逻辑...
}
}
// 过滤器使用 demo
public class Application {
// filters.add(new AuthencationFilter());
// filters.add(new RateLimitFilter());
private List<Filter> filters = new ArrayList<>();
public void handleRpcRequest(RpcRequest req) {
try {
for (Filter filter : fitlers) {
filter.doFilter(req);
}
} catch(RpcException e) {
// ... 处理过滤结果...
}
// ... 省略其他处理逻辑...
}
}
- 接口不能包含属性(也就是成员变量)
- 接口只能声明方法,方法不能包含代码实现
- 类实现接口的时候,必须实现接口中声明的所有方法
3、区别
从语法特性上对比,两者有比较大的区别,比如抽象类中可以定义属性、方法的实现,而接口中不能定义属性,方法也不能包含代码实现等等。除了语法特性,从设计的角度,两者也有比较大的区别
抽象类实际上就是类,只不过是一种特殊的类,这种类不能被实例化为对象,只能被子类继承。继承关系是一种 is-a 的关系,那抽象类既然属于类,也表示一种 is-a 的关系。相对于抽象类的 is-a 关系来说,接口表示一种 has-a 关系,表示具有某些功能。对于接口,有一个更加形象的叫法,那就是协议(contract)
4.2 抽象类和接口能解决什么编程问题?
为什么需要抽象类?它能够解决什么编程问题?
抽象类不能实例化,只能被继承。继承能解决代码复用的问题。所以,抽象类也是为代码复用而生的。多个子类可以继承抽象类中定义的属性和方法,避免在子类中,重复编写相同的代码
不过,既然继承本身就能达到代码复用的目的,而继承也并不要求父类一定是抽象类,那不使用抽象类,照样也可以实现继承和复用。从这个角度上来讲,貌似并不需要抽象类这种语法。拿打印日志的例子来说,把代码改造一下,Logger 不再是抽象类,只是一个普通的父类
// 父类:非抽象类,就是普通的类. 删除了 log(),doLog(),新增了 isLoggable().
public class Logger {
private String name;
private boolean enabled;
private Level minPermittedLevel;
public Logger(String name, boolean enabled, Level minPermittedLevel) {
//... 构造函数不变,代码省略...
}
protected boolean isLoggable() {
boolean loggable = enabled && (minPermittedLevel.intValue() <= level.intVal
return loggable;
}
}
// 子类:输出日志到文件
public class FileLogger extends Logger {
private Writer fileWriter;
public FileLogger(String name, boolean enabled,
Level minPermittedLevel, String filepath) {
//... 构造函数不变,代码省略...
}
public void log(Level level, String mesage) {
if (!isLoggable()) return;
// 格式化 level 和 message, 输出到日志文件
fileWriter.write(...);
}
}
// 子类: 输出日志到消息中间件 (比如 kafka)
public class MessageQueueLogger extends Logger {
private MessageQueueClient msgQueueClient;
public MessageQueueLogger(String name, boolean enabled,
Level minPermittedLevel, MessageQueueClient msgQueueClient) {
/ /... 构造函数不变,代码省略...
}
public void log(Level level, String mesage) {
if (!isLoggable()) return;
// 格式化 level 和 message, 输出到消息中间件
msgQueueClient.send(...);
}
}
这个设计思路虽然达到了代码复用的目的,但是无法使用多态特性了。像下面这样编写代码,就会出现编译错误,因为 Logger 中并没有定义 log() 方法
Logger logger = new FileLogger("access-log", true, Level.WARN, "/users/wangzhen
logger.log(Level.ERROR, "This is a test log message.");
这个问题解决起来很简单。在 Logger 父类中,定义一个空的 log() 方法,让子类重写父类的 log() 方法,实现自己的记录日志的逻辑,但这个设计思路显然没有之前通过抽象类的实现思路优雅
- 在 Logger 中定义一个空的方法,会影响代码的可读性
如果不熟悉 Logger 背后的设计思想,代码注释又不怎么给力,在阅读 Logger 代码的时候,就可能对为什么定义一个空的 log() 方法而感到疑惑 - 当创建一个新的子类继承 Logger 父类的时候,有可能会忘记重新实现 log() 方法
之前基于抽象类的设计思路,编译器会强制要求子类重写 log() 方法,否则会报编译错误 - Logger 可以被实例化,换句话说,可以 new 一个 Logger 出来,并且调用空的 log() 方法。这也增加了类被误用的风险
当然,这个问题可以通过设置私有的构造函数的方式来解决。不过,显然没有通过抽象类来的优雅
为什么需要接口?它能够解决什么编程问题?
抽象类更多的是为了代码复用,而接口就更侧重于解耦。接口是对行为的一种抽象,相当于一组协议或者契约,你可以联想类比一下 API 接口。调用者只需要关注抽象的接口,不需要了解具体的实现,具体的实现代码对调用者透明。接口实现了约定和实现相分离,可以降低代码间的耦合性,提高代码的可扩展性
实际上,接口是一个比抽象类应用更加广泛、更加重要的知识点。比如经常提到的“基于接口而非实现编程”,就是一条几乎天天会用到,并且能极大地提高代码的灵活性、扩展性的设计思想
4.3 如何模拟抽象类和接口两个语法概念?
1、通过抽象类来模拟接口
接口的定义:接口中没有成员变量,只有方法声明,没有方法实现,实现接口的类必须实现接口中的所有方法。只要满足这样几点,从设计的角度上来说,就可以把它叫作接口。如下 C++ 代码:
class Strategy {
// 用抽象类模拟接口
public:
~Strategy();
virtual void algorithm()=0;
protected:
Strategy();
};
抽象类 Strategy 没有定义任何属性,并且所有的方法都声明为 virtual 类型(等同于 Java中的 abstract 关键字),这样,所有的方法都不能有代码实现,并且所有继承这个抽象类的子类,都要实现这些方法。从语法特性上来看,这个抽象类就相当于一个接口
2、普通类来模拟接口
如果既不是 Java,也不是 C++,而是现在比较流行的动态编程语言,比如 Python、Ruby 等,在这些动态语言中,不仅没有接口的概念,也没有类似 abstract、virtual 这样的关键字来定义抽象类,那该如何实现呢?实际上,除了用抽象类来模拟接口之外,还可以用普通类来模拟接口,Java 代码实现如下:
public class MockInteface {
protected MockInteface() {
}
public void funcA() {
throw new MethodUnSupportedException();
}
}
类中的方法必须包含实现,这个不符合接口的定义。但是,可以让类中的方法抛出 MethodUnSupportedException 异常,来模拟不包含实现的接口,并且能强迫子类在继承这个父类的时候,都去主动实现父类的方法,否则就会在运行时抛出异常。那又如何避免这个类被实例化呢?实际上很简单,只需要将这个类的构造函数声明为 protected 访问权限就可以了
实际上,对于动态编程语言来说,还有一种对接口支持的策略,那就是 duck-typing
4.4 如何决定该用抽象类还是接口?
判断的标准很简单。如果要表示一种 is-a 的关系,并且是为了解决代码复用的问题,我们就用抽象类;如果要表示一种 has-a 关系,并且是为了解决抽象而非代码复用的问题,那我们就可以使用接口
从类的继承层次上来看,抽象类是一种自下而上的设计思路,先有子类的代码重复,然后再抽象成上层的父类(也就是抽象类)。而接口正好相反,它是一种自上而下的设计思路。在编程的时候,一般都是先设计接口,再去考虑具体的实现
5. 基于接口而非实现编程
5.1 如何解读原则中的“接口”二字?
“基于接口而非实现编程”这条原则的英文描述是:“Program to an interface, not an implementation”。这条原则最早出现于 1994 年 GoF 的《设计模式》这本书,它先于很多编程语言而诞生(比如 Java 语言),是一条比较抽象、泛化的设计思想,并不局限于编程语言的“接口”语法
从本质上来看,“接口”就是一组“协议”或者“约定”,是功能提供者提供给使用者的一个“功能列表”。“接口”在不同的应用场景下会有不同的解读,比如服务端与客户端之间的“接口”,类库提供的“接口”,甚至是一组通信的协议都可以叫作“接口”。这些对“接口”的理解,都比较偏上层、偏抽象,与实际的写代码离得有点远。如果落实到具体的编码,“基于接口而非实现编程”这条原则中的“接口”,可以理解为编程语言中的接口或者抽象类
这条原则能非常有效地提高代码质量,之所以这么说,那是因为,应用这条原则,可以将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低耦合性,提高扩展性
实际上,“基于接口而非实现编程”这条原则的另一个表述方式,是“基于抽象而非实现编程”。后者的表述方式其实更能体现这条原则的设计初衷。在软件开发中,最大的挑战之一就是需求的不断变化,这也是考验代码设计好坏的一个标准。越抽象、越顶层、越脱离具体某一实现的设计,越能提高代码的灵活性,越能应对未来的需求变化。好的代码设计,不仅能应对当下的需求,而且在将来需求发生变化的时候,仍然能够在不破坏原有代码设计的情况下灵活应对。而抽象就是提高代码扩展性、灵活性、可维护性最有效的手段之一
5.2 如何运用这条原则?
假设系统中有很多涉及图片处理和存储的业务逻辑。图片经过处理之后被上传到阿里云上。为了代码复用,封装了图片存储相关的代码逻辑,提供了一个统一的 AliyunImageStore 类,供整个系统来使用。具体的代码实现如下所示:
public class AliyunImageStore {
//... 省略属性、构造函数等...
public void createBucketIfNotExisting(String bucketName) {
// ... 创建 bucket 代码逻辑...
// ... 失败会抛出异常..
}
public String generateAccessToken() {
// ... 根据 accesskey/secrectkey 等生成 access token
}
public String uploadToAliyun(Image image, String bucketName, String accessTok
//... 上传图片到阿里云...
//... 返回图片存储在阿里云上的地址 (url)...
}
public Image downloadFromAliyun(String url, String accessToken) {
//... 从阿里云下载图片...
}
}
// AliyunImageStore 类的使用举例
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
//... 省略其他无关代码...
public void process() {
Image image = ...; // 处理图片,并封装为 Image 对象
AliyunImageStore imageStore = new AliyunImageStore(/* 省略参数 */);
imageStore.createBucketIfNotExisting(BUCKET_NAME);
String accessToken = imageStore.generateAccessToken();
imagestore.uploadToAliyun(image, BUCKET_NAME, accessToken);
}
}
整个上传流程包含三个步骤:创建 bucket(可以简单理解为存储目录)、生成 access token 访问凭证、携带 access token 上传图片到指定的 bucket 中。代码完全能满足将图片存储在阿里云的业务需求
过了一段时间后,假如自建了私有云,不再将图片存储到阿里云了,而是将图片存储到自建私有云上。为了满足这样一个需求的变化,该如何修改代码呢?这时需要重新设计实现一个存储图片到私有云的 PrivateImageStore 类,并用它替换掉项目中所有的 AliyunImageStore 类对象
新的 PrivateImageStore 类需要设计实现哪些方法,才能在尽量最小化代码修改的情况下,替换掉 AliyunImageStore 类呢?这就要求我们必须将 AliyunImageStore 类中所定义的所有 public 方法,在 PrivateImageStore 类中都逐一定义并重新实现一遍。而这样做就会存在一些问题:
- 首先,AliyunImageStore 类中有些函数命名暴露了实现细节,比如,
uploadToAliyun()和downloadFromAliyun()
最初只考虑将图片存储在阿里云上。而把这种包含“aliyun”字眼的方法,照抄到 PrivateImageStore 类中,显然是不合适的。如果在新类中重新命名uploadToAliyun()、downloadFromAliyun()这些方法,那就意味着,要修改项目中所有使用到这两个方法的代码,代码修改量可能就会很大 - 其次,将图片存储到阿里云的流程,跟存储到私有云的流程,可能并不是完全一致的
比如,阿里云的图片上传和下载的过程中,需要生产 access token,而私有云不需要 access token。一方面,AliyunImageStore 中定义的generateAccessToken()方法不能照抄到 PrivateImageStore 中;另一方面,在使用 AliyunImageStore 上传、下载图片的时候,代码中用到了generateAccessToken()方法,如果要改为私有云的上传下载流程,这些代码都需要做调整
这两个问题该如何解决呢?解决这个问题的根本方法就是,在编写代码的时候,要遵从“基于接口而非实现编程”的原则,具体如下 3 点:
- 函数的命名不能暴露任何实现细节。比如,前面提到的
uploadToAliyun()就不符合要求,应该改为去掉 aliyun 这样的字眼,改为更加抽象的命名方式,比如:upload() - 封装具体的实现细节。比如,跟阿里云相关的特殊上传(或下载)流程不应该暴露给调用者。可以对上传(或下载)流程进行封装,对外提供一个包裹所有上传(或下载)细节的方法,给调用者使用
- 为实现类定义抽象的接口。具体的实现类都依赖统一的接口定义,遵从一致的上传功能协议。使用者依赖接口,而不是具体的实现类来编程
public interface ImageStore {
String upload(Image image, String bucketName);
Image download(String url);
}
public class AliyunImageStore implements ImageStore {
//... 省略属性、构造函数等...
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
String accessToken = generateAccessToken();
//... 上传图片到阿里云...
//... 返回图片在阿里云上的地址 (url)...
}
public Image download(String url) {
String accessToken = generateAccessToken();
//... 从阿里云下载图片...
}
private void createBucketIfNotExisting(String bucketName) {
// ... 创建 bucket...
// ... 失败会抛出异常..
}
private String generateAccessToken() {
// ... 根据 accesskey/secrectkey 等生成 access token
}
}
// 上传下载流程改变:私有云不需要支持 access token
public class PrivateImageStore implements ImageStore {
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
//... 上传图片到私有云...
//... 返回图片的 url...
}
public Image download(String url) {
//... 从私有云下载图片...
}
private void createBucketIfNotExisting(String bucketName) {
// ... 创建 bucket...
// ... 失败会抛出异常..
}
}
// ImageStore 的使用举例
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
//... 省略其他无关代码...
public void process() {
Image image = ...;// 处理图片,并封装为 Image 对象
ImageStore imageStore = new PrivateImageStore(...);
imagestore.upload(image, BUCKET_NAME);
}
}
除此之外,很多人在定义接口的时候,希望通过实现类来反推接口的定义。先把实现类写好,然后看实现类中有哪些方法,照抄到接口定义中。如果按照这种思考方式,就有可能导致接口定义不够抽象,依赖具体的实现。这样的接口设计就没有意义了。不过,如果觉得这种思考方式更加顺畅,那也没问题,只是将实现类的方法搬移到接口定义中的时候,要有选择性的搬移,不要将跟具体实现相关的方法搬移到接口中,比如 AliyunImageStore 中的 generateAccessToken() 方法
在做软件开发的时候,一定要有抽象意识、封装意识、接口意识。在定义接口的时候,不要暴露任何实现细节。接口的定义只表明做什么,而不是怎么做。而且,在设计接口的时候,我们要多思考一下,这样的接口设计是否足够通用,是否能够做到在替换具体的接口实现的时候,不需要任何接口定义的改动
5.3 是否需要为每个类定义接口?
做任何事情都要讲求一个“度”,过度使用这条原则,非得给每个类都定义接口,接口满天飞,也会导致不必要的开发负担。至于什么时候,该为某个类定义接口,实现基于接口的编程,什么时候不需要定义接口,直接使用实现类编程,做权衡的根本依据,还是要回归到设计原则诞生的初衷上来
这条原则的设计初衷是,将接口和实现相分离,封装不稳定的实现,暴露稳定的接口。上游系统面向接口而非实现编程,不依赖不稳定的实现细节,这样当实现发生变化的时候,上游系统的代码基本上不需要做改动,以此来降低代码间的耦合性,提高代码的扩展性
从这个设计初衷上来看,如果在业务场景中,某个功能只有一种实现方式,未来也不可能被其他实现方式替换,那就没有必要为其设计接口,也没有必要基于接口编程,直接使用实现类就可以了
除此之外,越是不稳定的系统,越是要在代码的扩展性、维护性上下功夫。相反,如果某个系统特别稳定,在开发完之后,基本上不需要做维护,那就没有必要为其扩展性,投入不必要的开发时间
6. 组合优于继承,多用组合少用继承
在面向对象编程中,有一条非常经典的设计原则,那就是:组合优于继承,多用组合少用继承。为什么不推荐使用继承?组合相比继承有哪些优势?如何判断该用组合还是继承?
6.1 为什么不推荐使用继承?
继承是面向对象的四大特性之一,用来表示类之间的 is-a 关系,可以解决代码复用的问题。虽然继承有诸多作用,但继承层次过深、过复杂,也会影响到代码的可维护性。所以,对于是否应该在项目中使用继承,有很多争议。很多人觉得继承是一种反模式,应该尽量少用,甚至不用。为什么会有这样的争议?如下例:
1、假设要设计一个关于鸟的类。将“鸟类”这样一个抽象的事物概念,定义为一个抽象类 AbstractBird。所有更细分的鸟,比如麻雀、鸽子、乌鸦等,都继承这个抽象类
2、大部分鸟都会飞,那可不可以在 AbstractBird 抽象类中,定义一个 fly() 方法呢?答案是否定的。尽管大部分鸟都会飞,但也有特例,比如鸵鸟就不会飞。鸵鸟继承具有 fly() 方法的父类,那鸵鸟就具有“飞”这样的行为,这显然不符合我们对现实世界中事物的认识。当然,可以在鸵鸟这个子类中重写(Override)fly() 方法,让它抛出 UnSupportedMethodException 异常就可以了。代码实现如下:
public class AbstractBird {
//... 省略其他属性和方法...
public void fly() {
//... }
}
public class Ostrich extends AbstractBird {
// 鸵鸟
//... 省略其他属性和方法...
public void fly() {
throw new UnSupportedMethodException("I can't fly.'");
}
}
3、这种设计思路虽然可以解决问题,但不够优美。因为除了鸵鸟之外,不会飞的鸟还有很多,比如企鹅。对于这些不会飞的鸟来说,都需要重写 fly() 方法,抛出异常。这样的设计,一方面,徒增了编码的工作量;另一方面,也违背了最小知识原则(Least Knowledge Principle,也叫最少知识原则或者迪米特法则),暴露不该暴露的接口给外部,增加了类使用过程中被误用的概率
4、这时可以再通过 AbstractBird 类派生出两个更加细分的抽象类:会飞的鸟类 AbstractFlyableBird 和不会飞的鸟类 AbstractUnFlyableBird,让麻雀、乌鸦这些会飞的鸟都继承 AbstractFlyableBird,让鸵鸟、企鹅这些不会飞的鸟,都继承 AbstractUnFlyableBird 类。具体的继承关系如下:
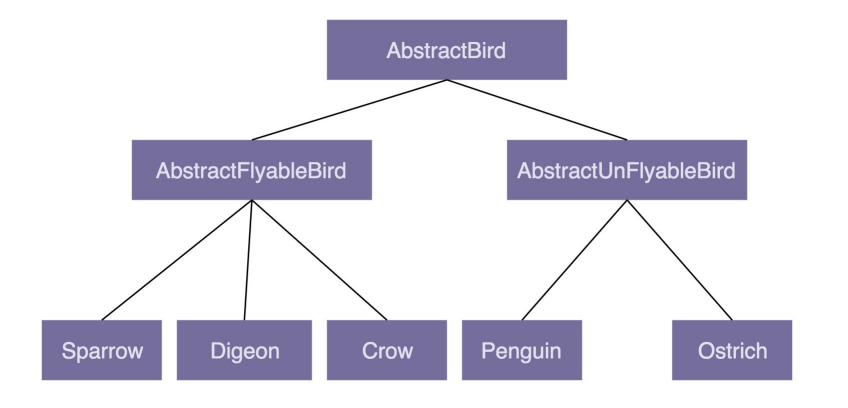
5、从图中可以看出,继承关系变成了三层。不过,整体上来讲,目前的继承关系还比较简单,层次比较浅,也算是一种可以接受的设计思路。再继续加点难度。在刚刚这个场景中,只关注“鸟会不会飞”,但如果还关注“鸟会不会叫”,那这个时候,又该如何设计类之间的继承关系呢?
6、是否会飞?是否会叫?两个行为搭配起来会产生四种情况:会飞会叫、不会飞会叫、会飞不会叫、不会飞不会叫。如果继续沿用刚才的设计思路,那就需要再定义四个抽象类(AbstractFlyableTweetableBird、AbstractFlyableUnTweetableBird、AbstractUnFlyableTweetableBird、AbstractUnFlyableUnTweetableBird)
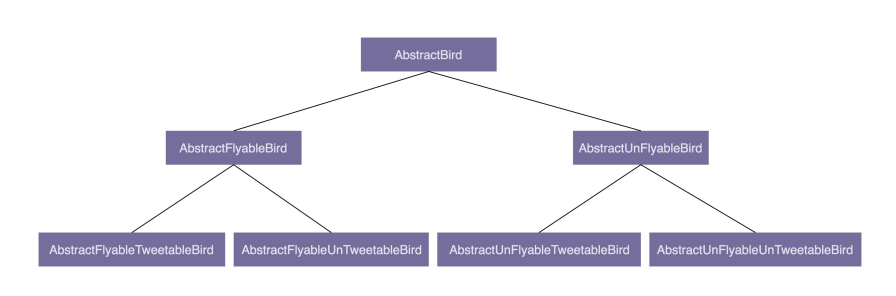
7、如果还需要考虑“是否会下蛋”这样一个行为,那估计就要组合爆炸了。类的继承层次会越来越深、继承关系会越来越复杂。而这种层次很深、很复杂的继承关系,一方面,会导致代码的可读性变差。因为要搞清楚某个类具有哪些方法、属性,必须阅读父类的代码、父类的父类的代码……一直追溯到最顶层父类的代码。另一方面,这也破坏了类的封装特性,将父类的实现细节暴露给了子类。子类的实现依赖父类的实现,两者高度耦合,一旦父类代码修改,就会影响所有子类的逻辑
总之,继承最大的问题就在于:继承层次过深、继承关系过于复杂会影响到代码的可读性和可维护性。这也是为什么不推荐使用继承
6.2 组合相比继承有哪些优势?
实际上,可以利用组合(composition)、接口、委托(delegation)三个技术手段,一块儿来解决刚刚继承存在的问题
前面讲到接口的时候说过,接口表示具有某种行为特性。针对“会飞”这样一个行为特性,可以定义一个 Flyable 接口,只让会飞的鸟去实现这个接口。对于会叫、会下蛋这些行为特性,可以类似地定义 Tweetable 接口、EggLayable 接口。将这个设计思路翻译成 Java 代码如下:
public interface Flyable {
void fly();
}
public interface Tweetable {
void tweet();
}
public interface EggLayable {
void layEgg();
}
public class Ostrich implements Tweetable, EggLayable {
// 鸵鸟
//... 省略其他属性和方法...
@Override
public void tweet() {
//... }
@Override
public void layEgg () {
//... }
}
public class Sparrow impelents Flayable,Tweetable,EggLayable {
// 麻雀
//... 省略其他属性和方法...
@Override
public void fly() {
//... }
@Override
public void tweet () {
//... }
@Override
public void layEgg () {
//... }
}
不过,接口只声明方法,不定义实现。也就是说,每个会下蛋的鸟都要实现一遍 layEgg() 方法,并且实现逻辑是一样的,这就会导致代码重复的问题。那这个问题又该如何解决呢?
可以针对三个接口再定义三个实现类,它们分别是:实现了 fly() 方法的 FlyAbility类、实现了 tweet() 方法的 TweetAbility 类、实现了 layEgg() 方法的 EggLayAbility 类。然后,通过组合和委托技术来消除代码重复。代码实现如下所示:
public interface Flyable {
void fly();
}
public class FlyAbility implements Flyable {
@Override
public void fly() {
//... }
}
// 省略 Tweetable/TweetAbility/EggLayable/EggLayAbility
public class Ostrich implements Tweetable, EggLayable {
// 鸵鸟
private TweetAbility tweetAbility = new TweetAbility(); // 组合
private EggLayAbility eggLayAbility = new EggLayAbility(); // 组合
//... 省略其他属性和方法...
@Override
public void tweet() {
tweetAbility.tweet(); // 委托
}
@Override
public void layEgg() {
eggLayAbility.layEgg(); // 委托
}
}
继承主要有三个作用:表示 is-a 关系,支持多态特性,代码复用。而这三个作用都可以通过其他技术手段来达成
- 比如 is-a 关系,可以通过组合和接口的 has-a 关系来替代
- 多态特性可以利用接口来实现
- 代码复用我们可以通过组合和委托来实现
所以,从理论上讲,通过组合、接口、委托三个技术手段,完全可以替换掉继承,在项目中不用或者少用继承关系,特别是一些复杂的继承关系
6.3 如何判断该用组合还是继承?
尽管鼓励多用组合少用继承,但组合也并不是完美的,继承也并非一无是处。从上面的例子来看,继承改写成组合意味着要做更细粒度的类的拆分。这也就意味着,要定义更多的类和接口。类和接口的增多也就或多或少地增加代码的复杂程度和维护成本。所以,在实际的项目开发中,我们还是要根据具体的情况,来具体选择该用继承还是组合
如果类之间的继承结构稳定(不会轻易改变),继承层次比较浅(比如,最多有两层继承关系),继承关系不复杂,就可以大胆地使用继承。反之,系统越不稳定,继承层次很深,继承关系复杂,就尽量使用组合来替代继承
除此之外,还有一些设计模式会固定使用继承或者组合。比如,装饰者模式(decorator pattern)、策略模式(strategy pattern)、组合模式(composite pattern)等都使用了组合关系,而模板模式(template pattern)使用了继承关系
有的时候,从业务含义上,A 类和 B 类并不一定具有继承关系。比如,Crawler 类和 PageAnalyzer 类,它们都用到了 URL 拼接和分割的功能,但并不具有继承关系(既不是父子关系,也不是兄弟关系)。仅仅为了代码复用,生硬地抽象出一个父类出来,会影响到代码的可读性。这个时候,使用组合就更加合理、更加灵活。代码实现如下:
public class Url {
//... 省略属性和方法
}
public class Crawler {
private Url url; // 组合
public Crawler() {
this.url = new Url();
}
//...
}
public class PageAnalyzer {
private Url url; // 组合
public PageAnalyzer() {
this.url = new Url();
}
//..
}
还有一些特殊的场景要求必须使用继承。如果你不能改变一个函数的入参类型,而入参又非接口,为了支持多态,只能采用继承来实现。比如下面这样一段代码,其中 FeignClient 是一个外部类,我们没有权限去修改这部分代码,但是希望能重写这个类在运行时执行的 encode() 函数。这个时候,只能采用继承来实现了
public class FeignClient {
// feighn client 框架代码
//... 省略其他代码...
public void encode(String url) {
//... }
}
public void demofunction(FeignClient feignClient) {
//...
feignClient.encode(url);
//...
}
public class CustomizedFeignClient extends FeignClient {
@Override
public void encode(String url) {
//... 重写 encode 的实现...}
}
// 调用
FeignClient client = new CustomizedFeignClient();
demofunction(client);
组合并不完美,继承也不是一无是处。控制好它们的副作用、发挥它们各自的优势,在不同的场合下,恰当地选择使用继承还是组合
7. 基于贫血模型的 MVC 架构
很多业务系统都是基于 MVC 三层架构来开发的。实际上,更确切点讲,这是一种基于贫血模型的 MVC 三层架构开发模式。虽然这种开发模式已经成为标准的 Web 项目的开发模式,但它却违反了面向对象编程风格,是一种彻彻底底的面向过程的编程风格,因此而被有些人称为反模式(anti-pattern)。特别是领域驱动设计(Domain Driven Design,简称 DDD)盛行之后,这种基于贫血模型的传统的开发模式就更加被人诟病。而基于充血模型的 DDD 开发模式越来越被人提倡
7.1 什么是基于贫血模型的传统开发模式?
MVC 三层架构
MVC 三层架构中的 M 表示 Model,V 表示 View,C 表示 Controller。它将整个项目分为三层:展示层、逻辑层、数据层。MVC 三层开发架构是一个比较笼统的分层方式,落实到具体的开发层面,很多项目也并不会 100% 遵从 MVC 固定的分层方式,而是会根据具体的项目需求,做适当的调整
很多 Web 或者 App 项目都是前后端分离的,后端负责暴露接口给前端调用。这种情况下,一般就将后端项目分为 Repository 层、Service 层、Controller 层。其中,Repository 层负责数据访问,Service 层负责业务逻辑,Controller 层负责暴露接口。当然,这只是其中一种分层和命名方式。不同的项目、不同的团队,可能会对此有所调整。不过,万变不离其宗,只要是依赖数据库开发的 Web 项目,基本的分层思路都大差不差
什么是贫血模型?
// Controller+VO(View Object) //
public class UserController {
private UserService userService; // 通过构造函数或者 IOC 框架注入
public UserVo getUserById(Long userId) {
UserBo userBo = userService.getUserById(userId);
UserVo userVo = [...convert userBo to userVo...];
return userVo;
}
}
public class UserVo {
// 省略其他属性、get/set/construct 方法
private Long id;
private String name;
private String cellphone;
}
// Service+BO(Business Object) //
public class UserService {
private UserRepository userRepository; // 通过构造函数或者 IOC 框架注入
public UserBo getUserById(Long userId) {
UserEntity userEntity = userRepository.getUserById(userId);
UserBo userBo = [...convert userEntity to userBo...];
return userBo;
}
}
public class UserBo {
// 省略其他属性、get/set/construct 方法
private Long id;
private String name;
private String cellphone;
}
// Repository+Entity //
public class UserRepository {
public UserEntity getUserById(Long userId) {
//... }
}
public class UserEntity {
// 省略其他属性、get/set/construct 方法
private Long id;
private String name;
private String cellphone;
}
平时开发 Web 后端项目的时候,基本上都是这么组织代码的。其中,UserEntity 和 UserRepository 组成了数据访问层,UserBo 和 UserService 组成了业务逻辑层,UserVo 和 UserController 在这里属于接口层
从代码中可以发现,UserBo 是一个纯粹的数据结构,只包含数据,不包含任何业务逻辑。业务逻辑集中在 UserService 中。我们通过 UserService 来操作 UserBo。换句话说,Service 层的数据和业务逻辑,被分割为 BO 和 Service 两个类中。像 UserBo 这样,只包含数据,不包含业务逻辑的类,就叫作贫血模型(Anemic Domain Model)。同理,UserEntity、UserVo 都是基于贫血模型设计的。这种贫血模型将数据与操作分离,破坏了面向对象的封装特性,是一种典型的面向过程的编程风格
7.2 什么是基于充血模型的 DDD 开发模式?
什么是充血模型?
在贫血模型中,数据和业务逻辑被分割到不同的类中。充血模型(Rich Domain Model)正好相反,数据和对应的业务逻辑被封装到同一个类中。因此,这种充血模型满足面向对象的封装特性,是典型的面向对象编程风格
什么是领域驱动设计?
领域驱动设计,即 DDD,主要是用来指导如何解耦业务系统,划分业务模块,定义业务领域模型及其交互。领域驱动设计这个概念并不新颖,早在 2004 年就被提出了,到现在已经有十几年的历史了。不过,它被大众熟知,还是基于另一个概念的兴起,那就是微服务
除了监控、调用链追踪、API 网关等服务治理系统的开发之外,微服务还有另外一个更加重要的工作,那就是针对公司的业务,合理地做微服务拆分。而领域驱动设计恰好就是用来指导划分服务的。所以,微服务加速了领域驱动设计的盛行
领域驱动设计有点儿类似敏捷开发、SOA、PAAS 等概念,听起来很高大上,但实际上只值“五分钱”。即便你没有听说过领域驱动设计,对这个概念一无所知,只要你是在开发业务系统,也或多或少都在使用它。做好领域驱动设计的关键是,看你对自己所做业务的熟悉程度,而并不是对领域驱动设计这个概念本身的掌握程度。即便你对领域驱动搞得再清楚,但是对业务不熟悉,也并不一定能做出合理的领域设计
实际上,基于充血模型的 DDD 开发模式实现的代码,也是按照 MVC 三层架构分层的。Controller 层还是负责暴露接口,Repository 层还是负责数据存取,Service 层负责核心业务逻辑。它跟基于贫血模型的传统开发模式的区别主要在 Service 层
- 在基于贫血模型的传统开发模式中,Service 层包含 Service 类和 BO 类两部分,BO 是贫血模型,只包含数据,不包含具体的业务逻辑。业务逻辑集中在 Service 类中
- 在基于充血模型的 DDD 开发模式中,Service 层包含 Service 类和 Domain 类两部分。Domain 就相当于贫血模型中的 BO。不过,Domain 与 BO 的区别在于它是基于充血模型开发的,既包含数据,也包含业务逻辑。而 Service 类变得非常单薄
总结一下的话就是,基于贫血模型的传统的开发模式,重 Service 轻 BO;基于充血模型的 DDD 开发模式,轻 Service 重 Domain
7.3 为什么基于贫血模型的传统开发模式如此受欢迎?
基于贫血模型的传统开发模式,将数据与业务逻辑分离,违反了 OOP 的封装特性,实际上是一种面向过程的编程风格。但是,现在几乎所有的 Web 项目,都是基于这种贫血模型的开发模式,甚至连 Java Spring 框架的官方 demo,都是按照这种开发模式来编写的
前面也讲过,面向过程编程风格有种种弊端,比如,数据和操作分离之后,数据本身的操作就不受限制了。任何代码都可以随意修改数据。既然基于贫血模型的这种传统开发模式是面向过程编程风格的,那它又为什么会被广大程序员所接受呢?关于这个问题,总结了下面三点原因:
- 大部分情况下,开发的系统业务可能都比较简单,简单到就是基于 SQL 的 CRUD 操作,所以,根本不需要动脑子精心设计充血模型,贫血模型就足以应付这种简单业务的开发工作。除此之外,因为业务比较简单,即便使用充血模型,那模型本身包含的业务逻辑也并不会很多,设计出来的领域模型也会比较单薄,跟贫血模型差不多,没有太大意义
- 充血模型的设计要比贫血模型更加有难度。因为充血模型是一种面向对象的编程风格。从一开始就要设计好针对数据要暴露哪些操作,定义哪些业务逻辑。而不是像贫血模型那样,只需要定义数据,之后有什么功能开发需求,就在 Service 层定义什么操作,不需要事先做太多设计
- 思维已固化,转型有成本。基于贫血模型的传统开发模式经历了这么多年,已经深得人心、习以为常。随便问一个旁边的大龄同事,基本上他过往参与的所有 Web 项目应该都是基于这个开发模式的,而且也没有出过啥大问题。如果转向用充血模型、领域驱动设计,那势必有一定的学习成本、转型成本。很多人在没有遇到开发痛点的情况下,是不愿意做这件事情的
7.4 什么项目应该考虑使用基于充血模型的 DDD 开发模式?
基于贫血模型的传统的开发模式,比较适合业务比较简单的系统开发。相对应的,基于充血模型的 DDD 开发模式,更适合业务复杂的系统开发。比如,包含各种利息计算模型、还款模型等复杂业务的金融系统
除了代码层面的区别之外(一个业务逻辑放到 Service 层,一个放到领域模型中),还有一个非常重要的区别,那就是两种不同的开发模式会导致不同的开发流程。基于充血模型的 DDD 开发模式的开发流程,在应对复杂业务系统的开发的时候更加有优势。为什么这么说呢?首先先看基于贫血模型的传统的开发模式都是怎么实现一个功能需求的
- 平时的开发,大部分都是 SQL 驱动(SQL-Driven)的开发模式。接到一个后端接口的开发需求的时候,就去看接口需要的数据对应到数据库中,需要哪张表或者哪几张表,然后思考如何编写 SQL 语句来获取数据。之后就是定义 Entity、BO、VO,然后模板式地往对应的 Repository、Service、Controller 类中添加代码
- 业务逻辑包裹在一个大的 SQL 语句中,而 Service 层可以做的事情很少。SQL 都是针对特定的业务功能编写的,复用性差。当要开发另一个业务功能的时候,只能重新写个满足新需求的 SQL 语句,这就可能导致各种长得差不多、区别很小的 SQL 语句满天飞
- 所以,在这个过程中,很少有人会应用领域模型、OOP 的概念,也很少有代码复用意识。对于简单业务系统来说,这种开发方式问题不大。但对于复杂业务系统的开发来说,这样的开发方式会让代码越来越混乱,最终导致无法维护
如果在项目中,应用基于充血模型的 DDD 的开发模式,那对应的开发流程就完全不一样了。在这种开发模式下,需要事先理清楚所有的业务,定义领域模型所包含的属性和方法。领域模型相当于可复用的业务中间层。新功能需求的开发,都基于之前定义好的这些领域模型来完成
越复杂的系统,对代码的复用性、易维护性要求就越高,就越应该花更多的时间和精力在前期设计上。而基于充血模型的 DDD 开发模式,正好需要前期做大量的业务调研、领域模型设计,所以它更加适合这种复杂系统的开发
7.5 如何利用基于充血模型的 DDD 开发一个虚拟钱包系统?
7.5.1 钱包业务背景介绍
很多具有支付、购买功能的应用(比如淘宝、滴滴出行、极客时间等)都支持钱包的功能。应用为每个用户开设一个系统内的虚拟钱包账户,支持用户充值、提现、支付、冻结、透支、转赠、查询账户余额、查询交易流水等操作。下图是一张典型的钱包功能界面:
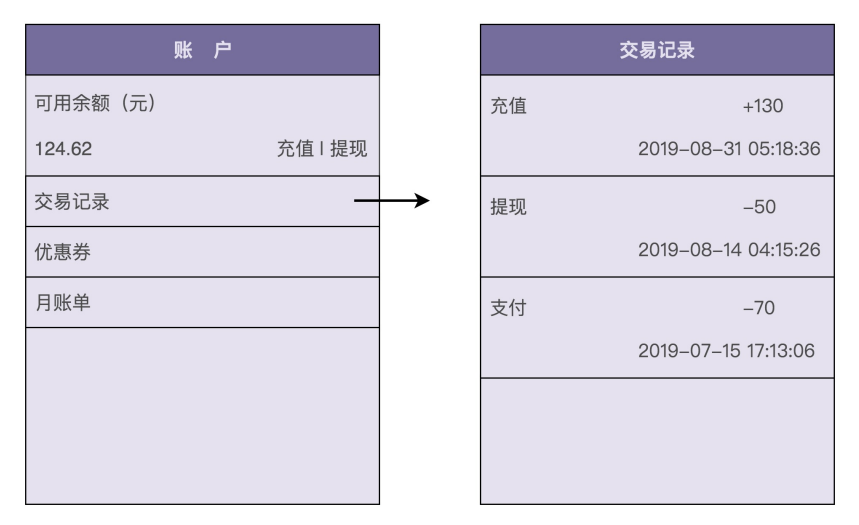
一般来讲,每个虚拟钱包账户都会对应用户的一个真实的支付账户,有可能是银行卡账户,也有可能是三方支付账户(比如支付宝、微信钱包)。这里限定钱包暂时只支持充值、提现、支付、查询余额、查询交易流水这五个核心的功能,其他比如冻结、透支、转赠等不常用的功能,暂不考虑。接下来一块儿看下它们的业务实现流程
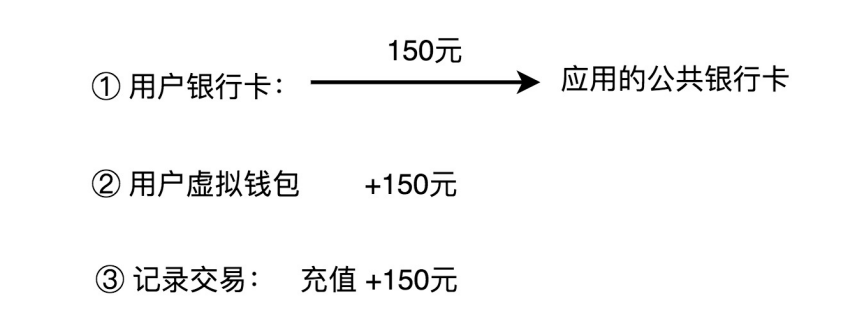
1、充值
用户通过三方支付渠道,把自己银行卡账户内的钱,充值到虚拟钱包账号中。这整个过程,可以分解为三个主要的操作流程:
- 第一个操作是从用户的银行卡账户转账到应用的公共银行卡账户
- 第二个操作是将用户的充值金额加到虚拟钱包余额上
- 第三个操作是记录刚刚这笔交易流水
2、支付
用户用钱包内的余额,支付购买应用内的商品。实际上,支付的过程就是一个转账的过程,从用户的虚拟钱包账户划钱到商家的虚拟钱包账户上,然后触发真正的银行转账操作,从应用的公共银行账户转钱到商家的银行账户(注意,这里并不是从用户的银行账户转钱到商家的银行账户)。除此之外,也需要记录这笔支付的交易流水信息
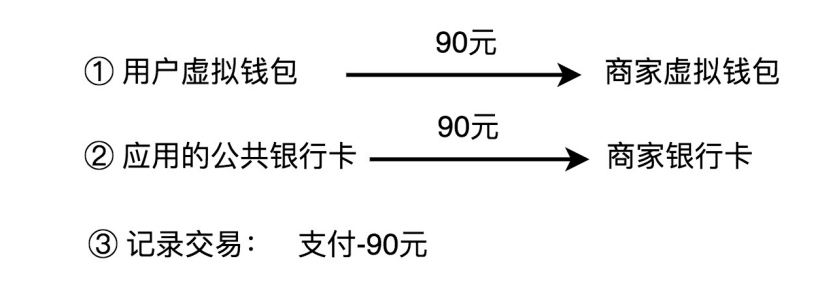
3、提现
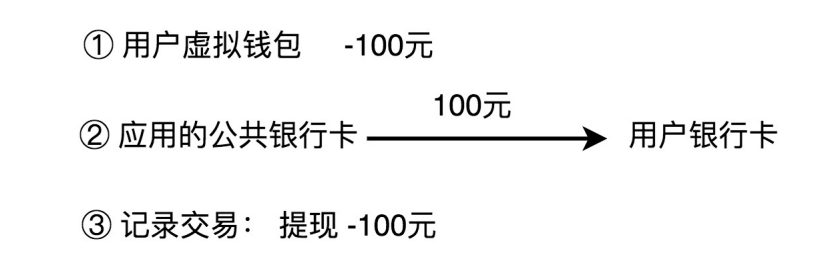
除了充值、支付之外,用户还可以将虚拟钱包中的余额,提现到自己的银行卡中。这个过程实际上就是扣减用户虚拟钱包中的余额,并且触发真正的银行转账操作,从应用的公共银行账户转钱到用户的银行账户。同样,也需要记录这笔提现的交易流水信息
4、查询余额
查询余额功能比较简单,看一下虚拟钱包中的余额数字即可
5、查询交易流水
查询交易流水也比较简单。这里只支持三种类型的交易流水:充值、支付、提现。在用户充值、支付、提现的时候,会记录相应的交易信息。在需要查询的时候,只需要将之前记录的交易流水,按照时间、类型等条件过滤之后,显示出来即可
7.5.2 钱包系统的设计思路
根据上面的业务实现流程和数据流转图,可以把整个钱包系统的业务划分为两部分,其中一部分单纯跟应用内的虚拟钱包账户打交道,另一部分单纯跟银行账户打交道。基于这样一个业务划分,给系统解耦,将整个钱包系统拆分为两个子系统:虚拟钱包系统和三方支付系统
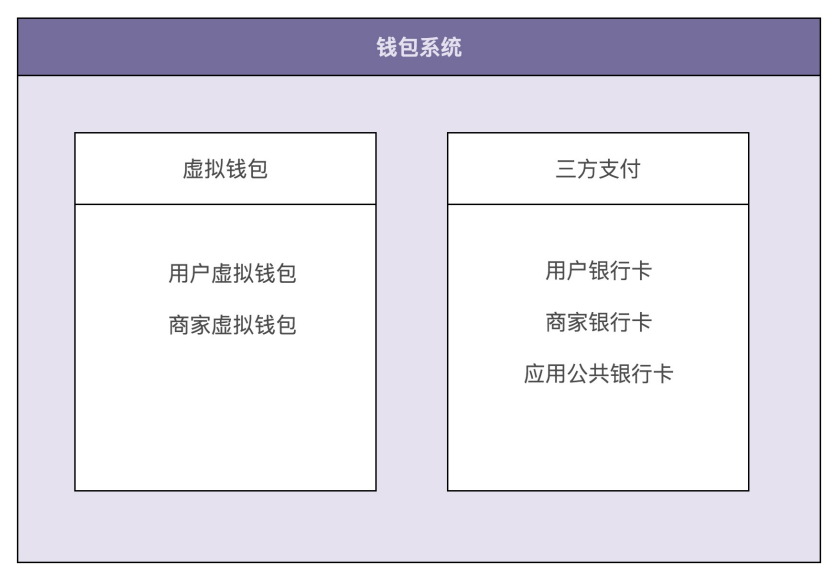
如果要支持钱包的这五个核心功能,虚拟钱包系统需要对应实现哪些操作?
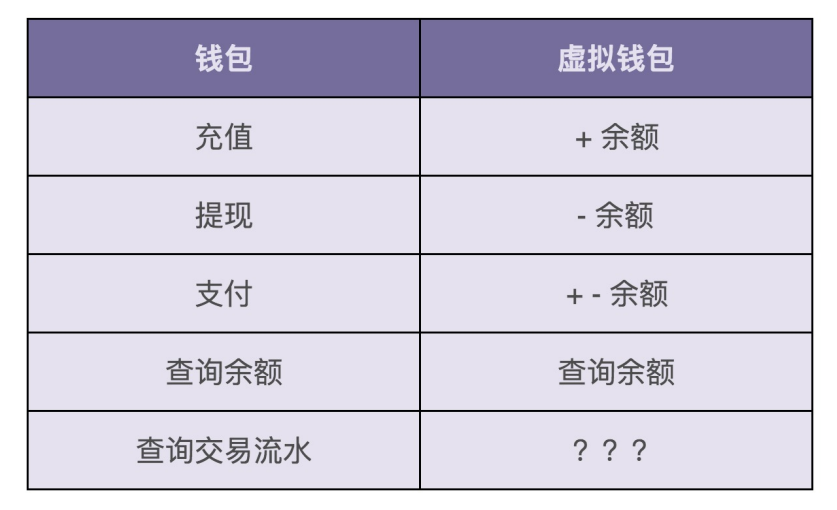
从图中可以看出,虚拟钱包系统要支持的操作非常简单,就是余额的加加减减。其中,充值、提现、查询余额三个功能,只涉及一个账户余额的加减操作,而支付功能涉及两个账户的余额加减操作:一个账户减余额,另一个账户加余额。图中问号的部分,也就是交易流水该如何记录和查询?先看一下交易流水都需要包含哪些信息:

从图中可以发现,交易流水的数据格式包含两个钱包账号,一个是入账钱包账号,一个是出账钱包账号。为什么要有两个账号信息呢?这主要是为了兼容支付这种涉及两个账户的交易类型。不过,对于充值、提现这两种交易类型来说,只需要记录一个钱包账户信息就够了,所以,这样的交易流水数据格式的设计稍微有点浪费存储空间
实际上,还有另外一种交易流水数据格式的设计思路,可以解决这个问题。把“支付”这个交易类型,拆为两个子类型:支付和被支付。支付单纯表示出账,余额扣减,被支付单纯表示入账,余额增加。这样在设计交易流水数据格式的时候,只需要记录一个账户信息即可
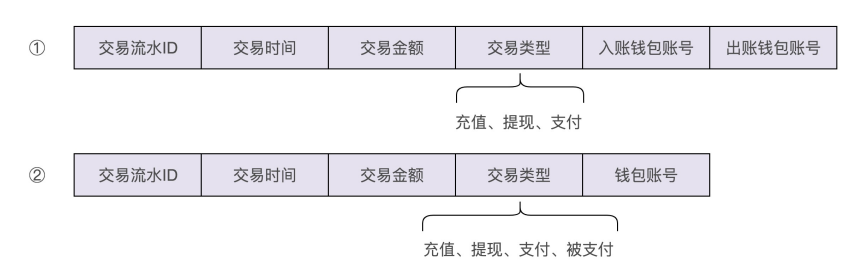
这两种交易流水数据格式的设计思路,哪一个更好呢?
第一种设计思路更好些。因为交易流水有两个功能:一个是业务功能,比如,提供用户查询交易流水信息;另一个是非业务功能,保证数据的一致性。这里主要是指支付操作数据的一致性
支付实际上就是一个转账的操作,在一个账户上加上一定的金额,在另一个账户上减去相应的金额。需要保证加金额和减金额这两个操作,要么都成功,要么都失败。如果一个成功,一个失败,就会导致数据的不一致,一个账户明明减掉了钱,另一个账户却没有收到钱
保证数据一致性的方法有很多,比如依赖数据库事务的原子性,将两个操作放在同一个事务中执行。但是,这样的做法不够灵活,因为有可能做了分库分表,支付涉及的两个账户可能存储在不同的库中,无法直接利用数据库本身的事务特性,在一个事务中执行两个账户的操作。当然,还有一些支持分布式事务的开源框架,但是,为了保证数据的强一致性,它们的实现逻辑一般都比较复杂、本身的性能也不高,会影响业务的执行时间。所以,更加权衡的一种做法就是,不保证数据的强一致性,只实现数据的最终一致性,也就是刚刚提到的交易流水要实现的非业务功能
对于支付这样的类似转账的操作,在操作两个钱包账户余额之前,先记录交易流水,并且标记为“待执行”,当两个钱包的加减金额都完成之后,再回过头来,将交易流水标记为“成功”。在给两个钱包加减金额的过程中,如果有任意一个操作失败,就将交易记录的状态标记为“失败”。通过后台补漏 Job,拉取状态为“失败”或者长时间处于“待执行”状态的交易记录,重新执行或者人工介入处理
如果选择第二种交易流水的设计思路,使用两条交易流水来记录支付操作,那记录两条交易流水本身又存在数据的一致性问题,有可能入账的交易流水记录成功,出账的交易流水信息记录失败。所以,权衡利弊,选择第一种稍微有些冗余的数据格式设计思路
充值、提现、支付这些业务交易类型,是否应该让虚拟钱包系统感知?换句话说,是否应该在虚拟钱包系统的交易流水中记录这三种类型?
答案是否定的。虚拟钱包系统不应该感知具体的业务交易类型。前面讲到,虚拟钱包支持的操作,仅仅是余额的加加减减操作,不涉及复杂业务概念,职责单一、功能通用。如果耦合太多业务概念到里面,势必影响系统的通用性,而且还会导致系统越做越复杂。因此,不希望将充值、支付、提现这样的业务概念添加到虚拟钱包系统中
如果不在虚拟钱包系统的交易流水中记录交易类型,那在用户查询交易流水的时候,如何显示每条交易流水的交易类型呢?
从系统设计的角度,不应该在虚拟钱包系统的交易流水中记录交易类型。从产品需求的角度来说,又必须记录交易流水的交易类型。听起来比较矛盾,这个问题该如何解决呢?
可以通过记录两条交易流水信息的方式来解决。前面讲到,整个钱包系统分为两个子系统,上层钱包系统的实现,依赖底层虚拟钱包系统和三方支付系统。对于钱包系统来说,它可以感知充值、支付、提现等业务概念,所以,在钱包系统这一层额外再记录一条包含交易类型的交易流水信息,而在底层的虚拟钱包系统中记录不包含交易类型的交易流水信息
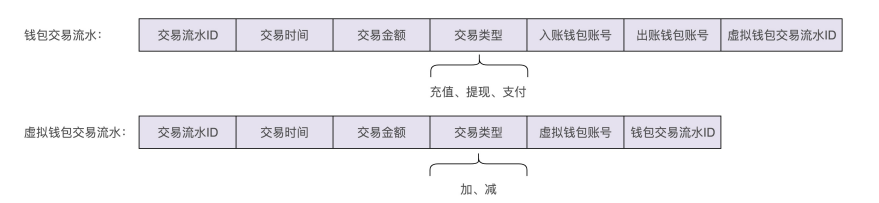
通过查询上层钱包系统的交易流水信息,去满足用户查询交易流水的功能需求,而虚拟钱包中的交易流水就只是用来解决数据一致性问题。实际上,它的作用还有很多,比如用来对账等
7.5.3 基于贫血模型的传统开发模式
典型的 Web 后端项目的三层结构。其中,Controller 和 VO 负责暴露接口,具体的代码实现如下所示(省略了具体的代码实现):
public class VirtualWalletController {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletService virtualWalletService;
public BigDecimal getBalance(Long walletId) {
... } // 查询余额
public void debit(Long walletId, BigDecimal amount) {
... } // 出账
public void credit(Long walletId, BigDecimal amount) {
... } // 入账
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
...} // 转账
}
Service 和 BO 负责核心业务逻辑,Repository 和 Entity 负责数据存取。Repository 这一层的代码实现比较简单,也省略掉了。Service 层的代码如下所示。这里省略了一些不重要的校验代码,比如,对 amount 是否小于 0、钱包是否存在的校验等等
public class VirtualWalletBo {
// 省略 getter/setter/constructor 方法
private Long id;
private Long createTime;
private BigDecimal balance;
}
public class VirtualWalletService {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWalletBo getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWalletBo walletBo = convert(walletEntity);
return walletBo;
}
public BigDecimal getBalance(Long walletId) {
return virtualWalletRepo.getBalance(walletId);
}
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
if (balance.compareTo(amount) < 0) {
throw new NoSufficientBalanceException(...);
}
walletRepo.updateBalance(walletId, balance.subtract(amount));
}
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
BigDecimal balance = walletEntity.getBalance();
walletRepo.updateBalance(walletId, balance.add(amount));
}
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
VirtualWalletTransactionEntity transactionEntity = new VirtualWalletTransac
transactionEntity.setAmount(amount);
transactionEntity.setCreateTime(System.currentTimeMillis());
transactionEntity.setFromWalletId(fromWalletId);
transactionEntity.setToWalletId(toWalletId);
transactionEntity.setStatus(Status.TO_BE_EXECUTED);
Long transactionId = transactionRepo.saveTransaction(transactionEntity);
try {
debit(fromWalletId, amount);
credit(toWalletId, amount);
} catch (InsufficientBalanceException e) {
transactionRepo.updateStatus(transactionId, Status.CLOSED);
...rethrow exception e...
} catch (Exception e) {
transactionRepo.updateStatus(transactionId, Status.FAILED);
...rethrow exception e...
}
transactionRepo.updateStatus(transactionId, Status.EXECUTED);
}
}
以上便是利用基于贫血模型的传统开发模式来实现的虚拟钱包系统。尽管对代码稍微做了简化,但整体的业务逻辑就是上面这样子。其中大部分代码逻辑都非常简单,最复杂的是 Service 中的 transfer() 转账函数。为了保证转账操作的数据一致性,添加了一些跟 transaction 相关的记录和状态更新的代码
7.5.4 基于充血模型的 DDD 开发模式
基于充血模型的 DDD 开发模式,跟基于贫血模型的传统开发模式的主要区别就在 Service 层,Controller 层和 Repository 层的代码基本上相同。所以,重点看一下,Service 层按照基于充血模型的 DDD 开发模式该如何来实现
在这种开发模式下,把虚拟钱包 VirtualWallet 类设计成一个充血的 Domain 领域模型,并且将原来在 Service 类中的部分业务逻辑移动到 VirtualWallet 类中,让 Service 类的实现依赖 VirtualWallet 类。代码实现如下:
public class VirtualWallet {
// Domain 领域模型 (充血模型)
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public BigDecimal balance() {
return this.balance;
}
public void debit(BigDecimal amount) {
if (this.balance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance.add(amount);
}
}
public class VirtualWalletService {
// 通过构造函数或者 IOC 框架注入
private VirtualWalletRepository walletRepo;
private VirtualWalletTransactionRepository transactionRepo;
public VirtualWallet getVirtualWallet(Long walletId) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
return wallet;
}
public BigDecimal getBalance(Long walletId) {
return virtualWalletRepo.getBalance(walletId);
}
public void debit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.debit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
public void credit(Long walletId, BigDecimal amount) {
VirtualWalletEntity walletEntity = walletRepo.getWalletEntity(walletId);
VirtualWallet wallet = convert(walletEntity);
wallet.credit(amount);
walletRepo.updateBalance(walletId, wallet.balance());
}
public void transfer(Long fromWalletId, Long toWalletId, BigDecimal amount) {
//... 跟基于贫血模型的传统开发模式的代码一样...
}
}
上面的代码中领域模型 VirtualWallet 类很单薄,包含的业务逻辑很简单。相对于原来的贫血模型的设计思路,这种充血模型的设计思路,貌似并没有太大优势。这也是大部分业务系统都使用基于贫血模型开发的原因。不过,如果虚拟钱包系统需要支持更复杂的业务逻辑,那充血模型的优势就显现出来了。比如,要支持透支一定额度和冻结部分余额的功能。这个时候,重新来看一下 VirtualWallet 类的实现代码
public class VirtualWallet {
private Long id;
private Long createTime = System.currentTimeMillis();;
private BigDecimal balance = BigDecimal.ZERO;
private boolean isAllowedOverdraft = true;
private BigDecimal overdraftAmount = BigDecimal.ZERO;
private BigDecimal frozenAmount = BigDecimal.ZERO;
public VirtualWallet(Long preAllocatedId) {
this.id = preAllocatedId;
}
public void freeze(BigDecimal amount) {
... }
public void unfreeze(BigDecimal amount) {
...}
public void increaseOverdraftAmount(BigDecimal amount) {
... }
public void decreaseOverdraftAmount(BigDecimal amount) {
... }
public void closeOverdraft() {
... }
public void openOverdraft() {
... }
public BigDecimal balance() {
return this.balance;
}
public BigDecimal getAvaliableBalance() {
BigDecimal totalAvaliableBalance = this.balance.subtract(this.frozenAmount)
if (isAllowedOverdraft) {
totalAvaliableBalance += this.overdraftAmount;
}
return totalAvaliableBalance;
}
public void debit(BigDecimal amount) {
BigDecimal totalAvaliableBalance = getAvaliableBalance();
if (totoalAvaliableBalance.compareTo(amount) < 0) {
throw new InsufficientBalanceException(...);
}
this.balance.subtract(amount);
}
public void credit(BigDecimal amount) {
if (amount.compareTo(BigDecimal.ZERO) < 0) {
throw new InvalidAmountException(...);
}
this.balance.add(amount);
}
}
领域模型 VirtualWallet 类添加了简单的冻结和透支逻辑之后,功能看起来就丰富了很多,代码也没那么单薄了。如果功能继续演进,可以增加更加细化的冻结策略、透支策略、支持钱包账号(VirtualWallet id 字段)自动生成的逻辑(不是通过构造函数经外部传入ID,而是通过分布式 ID 生成算法来自动生成 ID)等等。VirtualWallet 类的业务逻辑会变得越来越复杂,也就很值得设计成充血模型了
7.5.5 辩证思考与灵活应用
1、在基于充血模型的 DDD 开发模式中,将业务逻辑移动到 Domain 中,Service 类变得很薄,但在代码设计与实现中,并没有完全将 Service 类去掉,这是为什么?或者说,Service 类在这种情况下担当的职责是什么?哪些功能逻辑会放到 Service 类中?
区别于 Domain 的职责,Service 类主要有下面这样几个职责
-
Service 类负责与 Repository 交流
VirtualWalletService 类负责与 Repository 层打交道,调用 Respository 类的方法,获取数据库中的数据,转化成领域模型 VirtualWallet,然后由领域模型 VirtualWallet 来完成业务逻辑,最后调用
Repository 类的方法,将数据存回数据库之所以让 VirtualWalletService 类与 Repository 打交道,而不是让领域模型 VirtualWallet 与 Repository 打交道,那是因为想保持领域模型的独立性,不与任何其他层的代码(Repository 层的代码)或开发框架(比如 Spring、MyBatis)耦合在一起,将流程性的代码逻辑(比如从 DB 中取数据、映射数据)与领域模型的业务逻辑解耦,让领域模型更加可复用
-
Service 类负责跨领域模型的业务聚合功能
VirtualWalletService 类中的transfer()转账函数会涉及两个钱包的操作,因此这部分业务逻辑无法放到 VirtualWallet 类中,所以,暂且把转账业务放到 VirtualWalletService 类中了。当然,虽然功能演进,使得转账业务变得复杂起来之后,也可以将转账业务抽取出来,设计成一个独立的领域模型 -
Service 类负责一些非功能性及与三方系统交互的工作
比如幂等、事务、发邮件、发消息、记录日志、调用其他系统的 RPC 接口等,都可以放到 Service 类中
2、在基于充血模型的 DDD 开发模式中,尽管 Service 层被改造成了充血模型,但是 Controller 层和 Repository 层还是贫血模型,是否有必要也进行充血领域建模呢?
没有必要。Controller 层主要负责接口的暴露,Repository 层主要负责与数据库打交道,这两层包含的业务逻辑并不多,前面也提到了,如果业务逻辑比较简单,就没必要做充血建模,即便设计成充血模型,类也非常单薄,看起来也很奇怪
尽管这样的设计是一种面向过程的编程风格,但只要控制好面向过程编程风格的副作用,照样可以开发出优秀的软件。那这里的副作用怎么控制呢?
拿 Repository 的 Entity 来说,即便它被设计成贫血模型,违反面相对象编程的封装特性,有被任意代码修改数据的风险,但 Entity 的生命周期是有限的。一般来讲,把它传递到 Service 层之后,就会转化成 BO 或者 Domain 来继续后面的业务逻辑。Entity 的生命周期到此就结束了,所以也并不会被到处任意修改
再来说说 Controller 层的 VO。实际上 VO 是一种 DTO(Data Transfer Object,数据传输对象)。它主要是作为接口的数据传输承载体,将数据发送给其他系统。从功能上来讲,它理应不包含业务逻辑、只包含数据。所以,将它设计成贫血模型也是比较合理的
7.6 如何对接口鉴权这样一个功能开发做面向对象分析?
7.6.1 面向对象分析/需求分析(OOA)
假设,你正在参与开发一个微服务。微服务通过 HTTP 协议暴露接口给其他系统调用,说直白点就是,其他系统通过 URL 来调用微服务的接口。“为了保证接口调用的安全性,希望设计实现一个接口调用鉴权功能,只有经过认证之后的系统才能调用接口,没有认证过的系统调用接口会被拒绝”。这个时候,你该如何来做呢?
前面讲过,面向对象分析主要的分析对象是“需求”,因此,面向对象分析可以粗略地看成“需求分析”。实际上,不管是需求分析还是面向对象分析,首先要做的都是将笼统的需求细化到足够清晰、可执行。需要通过沟通、挖掘、分析、假设、梳理,搞清楚具体的需求有哪些,哪些是现在要做的,哪些是未来可能要做的,哪些是不用考虑做的
实际上,这跟做算法题类似,先从最简单的方案想起,然后再优化。所以,这里把整个的分析过程分为了循序渐进的四轮。每一轮都是对上一轮的迭代优化,最后形成一个可执行、可落地的需求列表
1、第一轮基础分析
对于如何做鉴权这样一个问题,最简单的解决方案就是,通过用户名加密码来做认证。给每个允许访问服务的调用方,派发一个应用名(或者叫应用 ID、AppID)和一个对应的密码(或者叫秘钥)。调用方每次进行接口请求的时候,都携带自己的 AppID 和密码。微服务在接收到接口调用请求之后,会解析出 AppID 和密码,跟存储在微服务端的AppID 和密码进行比对。如果一致,说明认证成功,则允许接口调用请求;否则,就拒绝
接口调用请求
2、第二轮分析优化
不过,这样的验证方式,每次都要明文传输密码。密码很容易被截获,是不安全的。那如果借助加密算法(比如 SHA),对密码进行加密之后,再传递到微服务端验证,是不是就可以了呢?实际上,这样也是不安全的,因为加密之后的密码及 AppID,照样可以被未认证系统(或者说黑客)截获,未认证系统可以携带这个加密之后的密码以及对应的 AppID,伪装成已认证系统来访问接口。这就是典型的“重放攻击”
提出问题,然后再解决问题,是一个非常好的迭代优化方法。对于刚刚这个问题,可以借助 OAuth 的验证思路来解决。调用方将请求接口的 URL 跟 AppID、密码拼接在一起,然后进行加密,生成一个 token。调用方在进行接口请求的的时候,将这个 token 及 AppID,随 URL 一块传递给微服务端。微服务端接收到这些数据之后,根据 AppID 从数据库中取出对应的密码,并通过同样的 token 生成算法,生成另外一个 token。用这个新
生成的 token 跟调用方传递过来的 token 对比。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求

3、第三轮分析优化
不过,这样的设计仍然存在重放攻击的风险,还是不够安全。每个 URL 拼接上 AppID、密码生成的 token 都是固定的。未认证系统截获 URL、token 和 AppID 之后,还是可以通过重放攻击的方式,伪装成认证系统,调用这个 URL 对应的接口
为了解决这个问题,可以进一步优化 token 生成算法,引入一个随机变量,让每次接口请求生成的 token 都不一样。可以选择时间戳作为随机变量。原来的 token 是对 URL、AppID、密码三者进行加密生成的,现在将 URL、AppID、密码、时间戳四者进行加密来生成 token。调用方在进行接口请求的时候,将 token、AppID、时间戳,随 URL 一并传递给微服务端
微服务端在收到这些数据之后,会验证当前时间戳跟传递过来的时间戳,是否在一定的时间窗口内(比如一分钟)。如果超过一分钟,则判定 token 过期,拒绝接口请求。如果没有超过一分钟,则说明 token 没有过期,就再通过同样的 token 生成算法,在服务端生成新的 token,与调用方传递过来的 token 比对,看是否一致。如果一致,则允许接口调用请求;否则,就拒绝接口调用请求

4、第四轮分析优化
虽然这样还是不够安全,未认证系统还是可以在这一分钟的 token 失效窗口内,通过截获请求、重放请求,来调用接口。但攻与防之间,本来就没有绝对的安全。能做的就是,尽量提高攻击的成本。这个方案虽然还有漏洞,但是实现起来足够简单,而且不会过度影响接口本身的性能(比如响应时间)。所以,权衡安全性、开发成本、对系统性能的影响,这个方案算是比较折中、比较合理的了
实际上,还有一个细节没有考虑到,那就是,如何在微服务端存储每个授权调用方的AppID 和密码。当然,这个问题并不难。最容易想到的方案就是存储到数据库里,比如 MySQL。不过,开发像鉴权这样的非业务功能,最好不要与具体的第三方系统有过度的耦合
针对 AppID 和密码的存储,最好能灵活地支持各种不同的存储方式,比如 ZooKeeper、本地配置文件、自研配置中心、MySQL、Redis 等。不一定针对每种存储方式都去做代码实现,但起码要留有扩展点,保证系统有足够的灵活性和扩展性,能够在切换存储方式的时候,尽可能地减少代码的改动
5、最终确定需求
到此,需求已经足够细化和具体了。现在按照鉴权的流程,对需求再重新描述一下:
- 调用方进行接口请求的时候,将 URL、AppID、密码、时间戳拼接在一起,通过加密算法生成 token,并且将 token、AppID、时间戳拼接在 URL 中,一并发送到微服务端
- 微服务端在接收到调用方的接口请求之后,从请求中拆解出 token、AppID、时间戳
- 微服务端首先检查传递过来的时间戳跟当前时间,是否在 token 失效时间窗口内。如果已经超过失效时间,那就算接口调用鉴权失败,拒绝接口调用请求
- 如果 token 验证没有过期失效,微服务端再从自己的存储中,取出 AppID 对应的密码,通过同样的 token 生成算法,生成另外一个 token,与调用方传递过来的 token 进行匹配;如果一致,则鉴权成功,允许接口调用,否则就拒绝接口调用
这就是需求分析的整个思考过程,从最粗糙、最模糊的需求开始,通过“提出问题 -解决问题”的方式,循序渐进地进行优化,最后得到一个足够清晰、可落地的需求描述
7.6.2 面向对象设计(OOD)
面向对象分析的产出是详细的需求描述,那面向对象设计的产出就是类。在面向对象设计环节,将需求描述转化为具体的类的设计。把这一设计环节拆解细化一下,主要包含以下几个部分:
- 划分职责进而识别出有哪些类
- 定义类及其属性和方法
- 定义类与类之间的交互关系
- 将类组装起来并提供执行入口
7.6.2.1 划分职责进而识别出有哪些类
在面向对象有关书籍中经常讲到,类是现实世界中事物的一个建模。但是,并不是每个需求都能映射到现实世界,也并不是每个类都与现实世界中的事物一一对应。对于一些抽象的概念,是无法通过映射现实世界中的事物的方式来定义类的
所以,大多数讲面向对象的书籍中,还会讲到另外一种识别类的方法,那就是把需求描述中的名词罗列出来,作为可能的候选类,然后再进行筛选。不过,作者个人更喜欢另外一种方法,那就是根据需求描述,把其中涉及的功能点,一个一个罗列出来,然后再去看哪些功能点职责相近,操作同样的属性,可否应该归为同一个类
首先,要做的是逐句阅读需求描述,拆解成小的功能点,一条一条罗列下来。注意,拆解出来的每个功能点要尽可能的小。每个功能点只负责做一件很小的事情(专业叫法是“单一职责”)。逐句拆解需求分析第五点的最终需求描述之后,得到的功能点列表如下:
- 把 URL、AppID、密码、时间戳拼接为一个字符串
- 对字符串通过加密算法加密生成 token
- 将 token、AppID、时间戳拼接到 URL 中,形成新的 URL
- 解析 URL,得到 token、AppID、时间戳等信息
- 从存储中取出 AppID 和对应的密码
- 根据时间戳判断 token 是否过期失效
- 验证两个 token 是否匹配
从上面的功能列表中发现,1、2、6、7 都是跟 token 有关,负责 token 的生成、验证;3、4 都是在处理 URL,负责 URL 的拼接、解析;5 是操作 AppID 和密码,负责从存储中读取 AppID 和密码。所以,可以粗略地得到三个核心的类:AuthToken、Url、CredentialStorage。AuthToken 负责实现 1、2、6、7 这四个操作;Url 负责 3、4 两个操作;CredentialStorage 负责 5 这个操作
当然,这是一个初步的类的划分,其他一些不重要的、边边角角的类,可能暂时没法一下子想全,但这也没关系,面向对象分析、设计、编程本来就是一个循环迭代、不断优化的过程。根据需求,先给出一个粗糙版本的设计方案,然后基于这样一个基础,再去迭代优化,会更加容易一些,思路也会更加清晰一些
不过,接口调用鉴权这个开发需求比较简单,所以,需求对应的面向对象设计并不复杂,识别出来的类也并不多。但如果面对的是更加大型的软件开发、更加复杂的需求开发,涉及的功能点可能会很多,对应的类也会比较多,像刚刚那样根据需求逐句罗列功能点的方法,最后会得到一个长长的列表,就会有点凌乱、没有规律。针对这种复杂的需求开发,首先要做的是进行模块划分,将需求先简单划分成几个小的、独立的功能模块,然后再在模块内部,应用上面讲的方法,进行面向对象设计。而模块的划分和识别,跟类的划分和识别,是类似的套路
7.6.2.2 定义类及其属性和方法
通过分析需求描述,识别出了三个核心的类,它们分别是 AuthToken、Url 和 CredentialStorage。现在来看每个类都有哪些属性和方法。还是从功能点列表中挖掘
1、AuthToken 类
相关的功能点有四个:
- 把 URL、AppID、密码、时间戳拼接为一个字符串
- 对字符串通过加密算法加密生成 token
- 根据时间戳判断 token 是否过期失效
- 验证两个 token 是否匹配
对于方法的识别,很多面向对象相关的书籍,一般都是这么讲的,识别出需求描述中的动词,作为候选的方法,再进一步过滤筛选。类比一下方法的识别,可以把功能点中涉及的名词,作为候选属性,然后同样进行过滤筛选。借用这个思路,根据功能点描述,识别出来 AuthToken 类的属性和方法如下:

从上面的类图中,可以发现这样三个小细节:
- 并不是所有出现的名词都被定义为类的属性,比如 URL、AppID、密码、时间戳这几个名词,把它作为了方法的参数
- 还需要挖掘一些没有出现在功能点描述中属性,比如 createTime,expireTimeInterval,它们用在
isExpired()函数中,用来判定 token 是否过期 - 还给 AuthToken 类添加了一个功能点描述中没有提到的方法
getToken()
第一个细节告诉我们,从业务模型上来说,不应该属于这个类的属性和方法,不应该被放到这个类里。比如 URL、AppID 这些信息,从业务模型上来说,不应该属于 AuthToken,所以我们不应该放到这个类中
第二、第三个细节告诉我们,在设计类具有哪些属性和方法的时候,不能单纯地依赖当下的需求,还要分析这个类从业务模型上来讲,理应具有哪些属性和方法。这样可以一方面保证类定义的完整性,另一方面不仅为当下的需求还为未来的需求做些准备
2、Url 类
相关的功能点有两个:
- 将 token、AppID、时间戳拼接到 URL 中,形成新的 URL
- 解析 URL,得到 token、AppID、时间戳等信息
虽然需求描述中,都是以 URL 来代指接口请求,但是,接口请求并不一定是以 URL 的形式来表达,还有可能是 dubbo RPC 等其他形式。为了让这个类更加通用,命名更加贴切,接下来把它命名为 ApiRequest。下面是根据功能点描述设计的 ApiRequest 类:

3、CredentialStorage 类
相关的功能点有一个:
- 从存储中取出 AppID 和对应的密码
CredentialStorage 类非常简单,类图如下所示。为了做到抽象封装具体的存储方式,这里将 CredentialStorage 设计成了接口,基于接口而非具体的实现编程

7.6.2.3 定义类与类之间的交互关系
类与类之间都哪些交互关系呢?UML 统一建模语言中定义了六种类之间的关系。它们分别是:泛化、实现、关联、聚合、组合、依赖。关系比较多,而且有些还比较相近,比如聚合和组合。各关系如下:
-
泛化(Generalization)
可以简单理解为继承关系public class A { ... } public class B extends A { ... } -
实现(Realization)
一般是指接口和实现类之间的关系public interface A { ...} public class B implements A { ... } -
聚合(Aggregation)
一种包含关系,A 类对象包含 B 类对象,B 类对象的生命周期可以不依赖 A 类对象的生命周期,也就是说可以单独销毁 A 类对象而不影响 B 对象,比如课程与学生之间的关系public class A { private B b; public A(B b) { this.b = b; } } -
组合(Composition)
也是一种包含关系。A 类对象包含 B 类对象,B 类对象的生命周期依赖 A 类对象的生命周期,B 类对象不可单独存在,比如鸟与翅膀之间的关系public class A { private B b; public A() { this.b = new B(); } } -
关联(Association)
一种非常弱的关系,包含聚合、组合两种关系。具体到代码层面,如果 B 类对象是 A 类的成员变量,那 B 类和 A 类就是关联关系public class A { private B b; public A(B b) { this.b = b; } } 或者 public class A { private B b; public A() { this.b = new B(); } } -
依赖(Dependency)
一种比关联关系更加弱的关系,包含关联关系。不管是 B 类对象是 A 类对象的成员变量,还是 A 类的方法使用 B 类对象作为参数或者返回值、局部变量,只要 B 类对象和 A 类对象有任何使用关系,都称它们有依赖关系public class A { private B b; public A(B b) { this.b = b; } } 或者 public class A { private B b; public A() { this.b = new B(); } } 或者 public class A { public void func(B b) { ... } }
个人觉得这样拆分有点太细,增加了学习成本,对于指导编程开发没有太大意义。这里对类与类之间的关系做了调整,只保留了四个关系:泛化、实现、组合、依赖
泛化、实现、依赖的定义不变,组合关系替代 UML 中组合、聚合、关联三个概念,也就相当于重新命名关联关系为组合关系,并且不再区分 UML 中的组合和聚合两个概念。之所以这样重新命名,是为了跟前面讲的“多用组合少用继承”设计原则中的“组合”统一含义。只要 B 类对象是 A 类对象的成员变量,那就称,A 类跟 B 类是组合关系
因为目前只有三个核心的类,所以只用到了实现关系,也即 CredentialStorage 和 MysqlCredentialStorage 之间的关系。下面组装类的时候,还会用到依赖关系、组合关系,但是泛化关系暂时没有用到
7.6.2.4 将类组装起来并提供执行入口
类定义好了,类之间必要的交互关系也设计好了,接下来要将所有的类组装在一起,提供一个执行入口。这个入口可能是一个 main() 函数,也可能是一组给外部用的 API 接口。通过这个入口,便能触发整个代码跑起来
接口鉴权并不是一个独立运行的系统,而是一个集成在系统上运行的组件,所以,封装所有的实现细节,设计了一个最顶层的 ApiAuthencator 接口类,暴露一组给外部调用者使用的 API 接口,作为触发执行鉴权逻辑的入口。具体的类的设计如下所示:

7.6.3 面向对象编程(OOP)
面向对象设计完成之后,已经定义清晰了类、属性、方法、类之间的交互,并且将所有的类组装起来,提供了统一的执行入口。接下来,面向对象编程的工作,就是将这些设计思路翻译成代码实现。有了前面的类图,这部分工作相对来说就比较简单了。这里只给出比较复杂的 ApiAuthencator 的实现:
public interface ApiAuthencator {
void auth(String url);
void auth(ApiRequest apiRequest);
}
public class DefaultApiAuthencatorImpl implements ApiAuthencator {
private CredentialStorage credentialStorage;
public ApiAuthencator() {
this.credentialStorage = new MysqlCredentialStorage();
}
public ApiAuthencator(CredentialStorage credentialStorage) {
this.credentialStorage = credentialStorage;
}
@Override
public void auth(String url) {
ApiRequest apiRequest = ApiRequest.buildFromUrl(url);
auth(apiRequest);
}
@Override
public void auth(ApiRequest apiRequest) {
String appId = apiRequest.getAppId();
String token = apiRequest.getToken();
long timestamp = apiRequest.getTimestamp();
String originalUrl = apiRequest.getOriginalUrl();
AuthToken clientAuthToken = new AuthToken(token, timestamp);
if (clientAuthToken.isExpired()) {
throw new RuntimeException("Token is expired.");
}
String password = credentialStorage.getPasswordByAppId(appId);
AuthToken serverAuthToken = AuthToken.generate(originalUrl, appId, password
if (!serverAuthToken.match(clientAuthToken)) {
throw new RuntimeException("Token verfication failed.");
}
}
}
7.6.4 辩证思考与灵活应用
在之前的讲解中,面向对象分析、设计、实现,每个环节的界限划分都比较清楚。而且,设计和实现基本上是按照功能点的描述,逐句照着翻译过来的。这样做的好处是先做什么、后做什么,非常清晰、明确,有章可循
不过,在平时的工作中,大部分程序员往往都是在脑子里或者草纸上完成面向对象分析和设计,然后就开始写代码了,边写边思考边重构,并不会严格地按照刚刚的流程来执行。而且,说实话,即便在写代码之前,花很多时间做分析和设计,绘制出完美的类图、UML 图,也不可能把每个细节、交互都想得很清楚。在落实到代码的时候,还是要反复迭代、重构、打破重写
毕竟,整个软件开发本来就是一个迭代、修修补补、遇到问题解决问题的过程,是一个不断重构的过程。没法严格地按照顺序执行各个步骤