文章目录
从一道题开始:输入一个url后发生了什么?
1. 浏览器自动补全协议、端口
2. 浏览器自动完成url编码
3. 浏览器根据url地址查找本地缓存,根据缓存规则看是否命中缓存,若命中缓存则直接使用缓存,不再发出请求
4. 通过DNS解析找到服务器的IP地址
5. 浏览器向服务器发出建立TCP连接的申请,完成三次握手后,连接通道建立
6. 若使用了HTTPS协议,则还会进行SSL握手,建立加密信道。使用SSL握手时,会确定是否使用HTTP2
7. 浏览器决定要附带哪些cookie到请求头中
8. 浏览器自动设置好请求头、协议版本、cookie,发出GET请求
9. 服务器处理请求,进入后端处理流程。完成处理后,服务器响应一个HTTP报文给浏览器。
10. 浏览器根据使用的协议版本,以及Connection字段的约定,决定是否要保留TCP连接。
11. 浏览器根据响应状态码决定如何处理这一次响应
12. 浏览器根据响应头中的Content-Type字段识别响应类型,如果是text/html,则对响应体的内容进行HTML解析,否则做其他处理
13. 浏览器根据响应头的其他内容完成缓存、cookie的设置
14. 浏览器开始从上到下解析HTML,若遇到外部资源链接,则进一步请求资源
15. 解析过程中生成DOM树、CSSOM树,然后一边生成,一边把二者合并为渲染树(rendering tree),随后对渲染树中的每个节点计算位置和大小(reflow),最后把每个节点利用GPU绘制到屏幕(repaint)
16. 在解析过程中还会触发一系列的事件,当DOM树完成后会触发DOMContentLoaded事件,当所有资源加载完毕后会触发load事件
1.请求协议
可聊点1:http协议相关
=> 追问: http与TCP
a.概念
http:应用层网络协议
TCP:传输层协议
b.关联:http基于TCP实现连接(http依赖TCP实现请求、发送、断开)
优化点:http1.0 => http2.0
UDP vs TCP
TCP:面向连接确认。UDP:面向连接传输
UDP更快,性能更高。但是TCP更确保能收到
(1)TCP 是面向连接的,UDP 是无连接的即发送数据前不需要先建立链接。
(2)TCP 提供可靠的服务。也就是说,通过 TCP 连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP 尽最大努力交付,即不保证可靠交付。
并且因为 tcp 可靠,面向连接,不会丢失数据因此适合大数据量的交换。
(3)TCP 是面向字节流,UDP 面向报文,并且网络出现拥塞不会使得发送速率降低(因此会出现丢包,对实时的应用比如 IP 电话和视频会议等)。
(4)TCP 只能是 1 对 1 的,UDP 支持 1 对 1,1 对多。
(5)TCP 的首部较大为 20 字节,而 UDP 只有 8 字节。
keep-alive (http1.1实现, 2.0没有)
http发送请求之后会断开TCP连接。打开这个配置,保持TCP的连续畅通,不用反复的建立连接
http版本
http1.0 和 http2.0在链接上的区别: 复用通路 - 2.0多个请求复用同一条TCP通路
例:同时发送十条请求:
1.1中:同步发送六条,一条结束,补上一条,直到请求完毕。
2.0中:十条同时发送。(复用通路、无并发限制,尽量避免使用数据多的‘胖接口’,http2.0帮助实现)
c.差别:http - 无状态连接;TCP - 有状态
优化点:
socket连接,封装化的TCP,让我们的应用更加方便的使用调用。
可聊点2: https协议相关
=> 追问:http与https
a. 概念
https=http + SSL(TLS)
位于TCP连接协议与各种应用协议之间
b. 实现原理
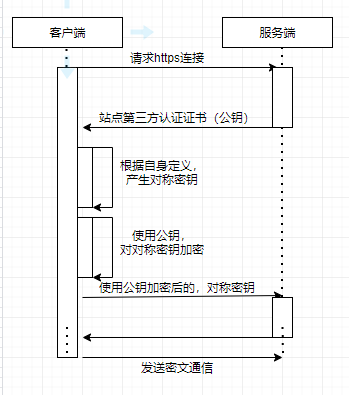
客户端像服务器请求数据,服务端会返回给客户端一个盒子,这个盒子的钥匙(公匙)只有服务端有。客户端收到后,根据自身定义生成对应的密匙,装进盒子后,发送给服务端。服务端用自己的钥匙打开自己的盒子,得到客户端的密钥。这样,只有客户端和服务端才有客户端的钥匙,就可以通过这个密匙加密来进行通信。
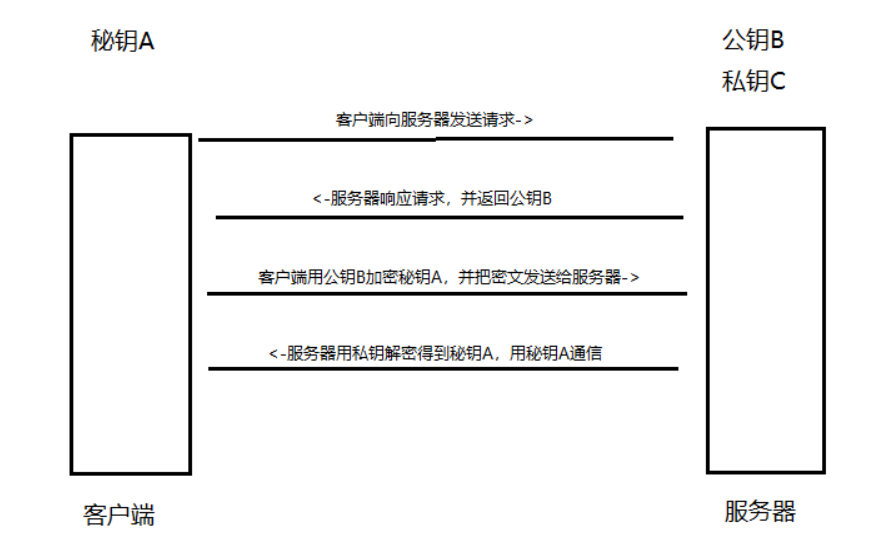
客户端拥有秘钥A,服务器拥有公钥B和私钥C,首先,客户端向服务器发送请求,服务器接到请求,响应请求并把它的公钥B传给客户端,客户端接收到公钥B后用公钥B加密秘钥A,形成一段密文,然后把密文传给服务器,而公钥加密的密文只能用私钥解密,但我们只传输过公钥,所以只有服务器拥有私钥,能够解密这段密文得到秘钥A,这样就只有客户端和服务器这个秘钥A了,中间没有任何人拥有秘钥A,然后客户端和服务器的通信就可以通过秘钥A来进行加密解密,这样就保证了数据传输过程中的加密问题。
c. 优化
https多次连接,导致网络请求加载时间延长,增加开销和消耗。
建议合并请求,长连接。
–可能问到:中间层 整合请求时 - 异常处理–
2.域名解析
IP地址是网络上标识站点的数字地址,为了方便记忆,采用域名来代替IP地址标识站点地址。域名解析就是域名到IP地址的转换过程。域名的解析工作由DNS服务器完成。
1. 浏览器缓存中 - 浏览器中会缓存DNS一段时间
2. 系统缓存 - 系统中找缓存 -> HOST
(没有找到说明当前这台机器没有访问此次域名的记录)
3. 路由器缓存 - 各级路由器缓存域名信息
4. 运营商地方站点的缓存信息 - partner (基本上可以找到)
5. 根域名服务器
优化:
=> CDN - Content Delivery Network
1. 为同一个主机分配多个Ip地址
2. LB - 负载均衡
=> 缓存 => 各级缓存 => 浏览器区分缓存(协商缓存、强缓存)
3.web服务器
常用服务器:apache、ngnix
1.作用:接受请求传递给服务端代码
2.通过反向代理,传递给其他服务器
3.不同域名 => 指向相同ip的服务器 => ngnix域名解析 => 引导到不同的服务监听端口
4.服务(2、3)涉及到 网络优化
手写并发 - QPS
面试:并发优化,10个请求,由于后台或者业务需求只能同时执行三个,如何做一个前端并发请求的控制
(10个请求,每次请求三个,一个结束,补上一个,知道十个全部请求完成)
分析:
输入 :promise请求数组,limit限制参数(默认为3)
存储:reqpool - 请求并发池,控制最大并发量,所有请求一个一个进来,有执行结束的,再塞进来一个
思路:
塞入并发池,直到超过limit,停止。reqpool满了,开始执行。
有一个返回,则再次塞入并发池。
分析时,可根据时间顺序、逻辑顺序、结构顺序 拆解
function qpsLimit(requestPipe, limitMax = 3){
let reqPool = []
// 塞入方法,往并发池里塞入promise请求
const add =()=>{
let _req = requestPipe.shift()
reqPool.push(_req)
}
// 执行的方法,执行实际请求
const run =()=>{
if(requestPipe.length === 0) return //没有要执行的方法,停止
let _finish = Promise.race(reqPool) //有一个执行完,就要添加一个,获取到执行最快的那个
_finish.then((res)=>{
let done=reqPool.indexOf(_finish)
reqPool.slice(done,1) // 请求池中拿出请求完毕的那个请求
add() // 重新添加一个
})
}
// 便利,区分满没满
while(reqPool.length < limitMax ){
add()
}
run()
}
优化思考:结合节流实现,三秒内不会重复发请求
5.浏览器渲染
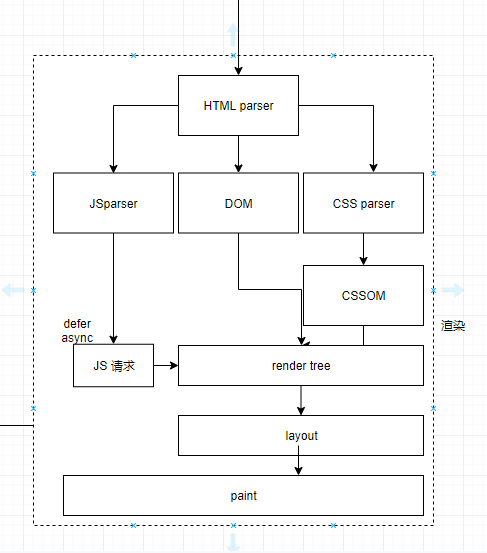
主线:HTML => DOM + CSSOM => renderTree + js => layout => paint
支线:
repaint - 改变文本、颜色等展示,不改变自身及周边的大小和布局
reflow - 元素几何尺寸变了,需要重新计算renderTree(reflow 成本>repaint成本)
渲染流程:首先,渲染引擎解析HTML文档,生成DOM树,css样式会被解析生成CSSOM树。然后CSSOM与DOM生成render Tree。接下来在渲染树的基础上进行布局。最后将渲染树的各个节点绘制到屏幕上,这一步被称为绘制painting
优化: 减少repaint,避免reflow(display: none => reflow; visibility:hidden; => repaint)
页面加载时,添加一个loading,待页面构建完成再展示页面,避免首次加载时,元素或数据加载不全的reflow
6.脚本执行时 - JS
js在代码里能做哪些性能优化?
可聊点:js的垃圾回收
点击了解详情 js垃圾回收
mark & sweep => 触达标记,锁定清空、未触达直接抹掉
// 内存分配:申明变量、函数、对象
// 内存使用:读写内存
// 内存释放
// gc:垃圾回收
const zhaowa = {
js: {
performance: 'good',
teacher: '云隐'
}
}
// 建立引用关系
const _obj = zhaowa
// 引用源给替换掉了 - 暂未gc
zhaowa = 'best'
/**
*此时,zhaowa的值已经变成了‘best’,但是_obj还在用最初对象的值,所以对象还不能被垃圾回 收。
*/
// 深入层级做引用 - 暂未gc
const _class = _obj.js
// obj被拆分成两份存在堆内容中,一个指向_obj,一个指向_class
// 引用方替换 - 暂未gc
_obj = 'over'
// gc 完成
_class = null
优化点:
- 对象层级,宜平不宜深
- 深层引用最好深拷贝,或者用完直接销毁
- 避免循环引用
// 1.循环引用:
function traverseTree(node1, node2) {
node1.parent = node2;
node2.children = node1;
}
// 这种写法,每个节点既有父节点的信息,又有子节点的信息,拿到一个节点,可以知道他的关系节点。可以提高效率。但是这种写法使两个节点相互引用,导致node永远不会被gc。
// 2. 内存泄露
// 莫名其妙的全局变量
function foo() {
bar1 = ''
this.bar2 = ''
}
// 未清理的定时器
setInterval(() => {
}, 1000)
// 使用后的闭包
function zhaowa() {
const _no = 1
return {
number: _no
}
}
7.打包配置的优化
三个方向:
- 懒加载 - 非必要不加载
- 按需引入 - 非必要不引入
- 抽离公共 - 相同项目合并公用