高性能Mysql阅读笔记
Mysql存储引擎
Mysql的默认存储引擎:Innodb
在Mysql5.1版本之前,默认存储引擎为: MyISAM
存储引擎的多并发控制区别(MVCC):
InnoDB:
支持事务,采用四个隔离级别
-
Read Uncommitted (读未提交)
并发量最高,事务中的修改即使为提交,在其他事务中也是可见的
-
Read Committed (读已提交)
大多数数据库管理系统的默认隔离级别都是这个(Mysql不是),只能看到已提交的事务修改。
有可能出现两次执行结果是一样的,但结果不一样
-
RepeaTable Read (可重复读)
Mysql的事务默认隔离级别。保证了同一事务的多次读取结果是一致的 -
Serializable (可串行化)
最高的隔离级别,并发量最低,会在读取每一行数据时添加共享锁。
MyISAM:
不支持事务
性能方面,在某些特定场景下,MyISAM性能很好。设计简单,数据以紧密格式存储,插入速度非常快
Mysql的自动提交
Mysq默认采用自动提交模式。也就是说,如果不是显示的开启一个事务,则每一个查询都被当作一个事务执行提交操作。在当前链接中,可以通过设置AUTOCOMMIT变量启用或禁用自动提交模式。(*10)
可以通过命令set autocommit= 0/1(1:启用。0:关闭)
Mysql性能剖析
捕获Mysql的查询到日志文件
可以通过设置long_query_time=0来捕获所有的查询
show variables like 'slow_query_log'; -- 显示是否开启慢sql日志
SET GLOBAL slow_query_log_file -- 指定慢查询日志存储文件的地址和文件名。
SET GLOBAL log_queries_not_using_indexes -- 无论是否超时,未被索引的记录也会记录下来。
SET SESSION long_query_time -- SQL 执行超过这个阈值(秒)将被记录在日志中。
SET SESSION min_examined_row_limit -- 慢查询仅记录扫描行数大于此参数的 SQL。
有分析慢查询日志的工具pt-query-digest,一半情况下,只需要将慢查询日志作为参数传递给pt-query-digest,就可以正确的工作的。他会将查询的分析报告打印出来。
Mysql性能剖析工具
- New Relic (会插入到应用程序中进行性能剖析)
- Mattkit
- Super Smark(可以提供压力测试和负载生成。可以加载测试数据到数据库,并支持堆积生成数据填充到数据表)
SHOW PROFILE
语句分析工具
SHOW PROFILE命令是在Mysql5.1以后的 版本引入的。默认时禁用的,可以通过set profiling=1来开启
该工具会在服务器上执行的所有语句,都会检测其耗费的时间和其他的查询执行状态变更的相关数据.
当有一条查询命令提交到服务器时,会记录分析信息到临时记录表中。
使用方式:
使用命令show PROFILES可以查看记录到的所有执行语句,每一个语句都有一个编码Query_id。找到想查看详情的语句。拿到Query_id。
在通过命令
show profile for QUERY queri_id(上面获取到的Query_id);
如下图所示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LqM2b4AX-1659795260686)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.00.03.png)]](https://img-blog.csdnimg.cn/d7efb63fc6af45f09c9fa15c2bbc426d.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-v5QaRYS2-1659795260687)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.01.47.png)]](https://img-blog.csdnimg.cn/5a8f423f8a934e7781fc472385ba2f52.png)
SHOW STATUS
返回一些计数器,显示了一些操作的次数,例如下sql语句可以快速的查看,使用到临时表的次数。以及使用到索引的读操作(*84)
SHOW STATUS WHERE Variable_name LIKE 'Handler%' OR Variable_name LIKE 'Create%'
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QZWjwCSH-1659795260687)(/Users/xujiangtao/Desktop/截屏2022-08-04 13.12.53.png)]](https://img-blog.csdnimg.cn/8474bcecbddb4c68ad0d3829bead7a62.png)
也可以使用SHOW GLOBAL STATUS展示全局状态
选择优化的数据类型
注意点
- 通常更小的数据类型应该是
- 简单就好,例如整形比字符串的操作代价更低
- 尽量避免NULL值
最好指定列为NOT NULL,如果查询中包含NULL值,对于Mysql来说可能更难优化。因为可为NULL的列使得索引、索引统计和值的比较更为复杂,可为NULL的列会使用更多的存储空间
整数类型
如果是存储整数,可以有一下几种整数类型
也更好的可以使用自增
- TINYINT 范围:(-128-127)所占字节 :8
- SMALLINT 范围:(-8388608-8388607)16
- MEDIUMINT 范围:(-128-127)24
- INT 范围:(-2,147,483,648-2,147,483,647) 32
- BIGINT 范围:(-9223372036854775808-9223372036854775807) 64
浮点数类型
-
DECIMAL
可以存储比BIGINT还大的整数,支持高精度的计算
-
DOUBLE
-
FLOAT
字符串类型
- VARCHAR
可变长字符串,额外需要一个字节记录字符的长度。
思考:
varchar(5)和varchar(2000)的空间开销都是一样的,那么使用更短的列有什么优势吗?
答:会有很大的优势,会节省更多的内存,因为mysql会分配固定大小的内存快来保存内布值。
我们只需要分配真正需要的空间为最佳
- CHAR
用于存放定长的字符,当存储字符时,会删除末尾所有空格,适合存储字段长度接近的值
大型数据类型
- BOLB。(以二进制的方式保存数据)
- TEXT。(以字符格式保存数据)
日期时间类型
- DATETIME
以固定格式保存在YYYYMMDDHHMMSS的整数中(可以保存1001年至9999年)
-
TIMESTAMP
只能保存1970年至2038年,使用时间戳保存时间数据
索引基础
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免使用临时表和排序
- 可以将随机IO变为顺序IO
B-tree
Mysql的索引数据类型使用的B-Tree数据结构来实现的
b-tree通常意味着所有的值是按照顺序存储的。
索引类型
1、单值索引
创建方式:
create index [indexname] ON [tablename](fieldname)
最普通的索引。为该列的所有值创建一个b-tree结构的索引树,并升序排序
2、唯一索引及联合唯一索引
ALTER TABLE tablename ADD UNIQUE [indexname] (fieldname,fieldname)
索引列的值必须唯一。但是可以为null
3、联合索引
create index [indexname] ON [tablename](fieldname,fieldname)
可以指定多列作为索引值,同时按照多列进行升序排序。需要遵循最左匹配原则
5000多万条数据的一张表。通过如下两图,同样的sql。一个添加了联合索引并且覆盖索引。一个没有索引。时间对比也可以看出索引的优化效率
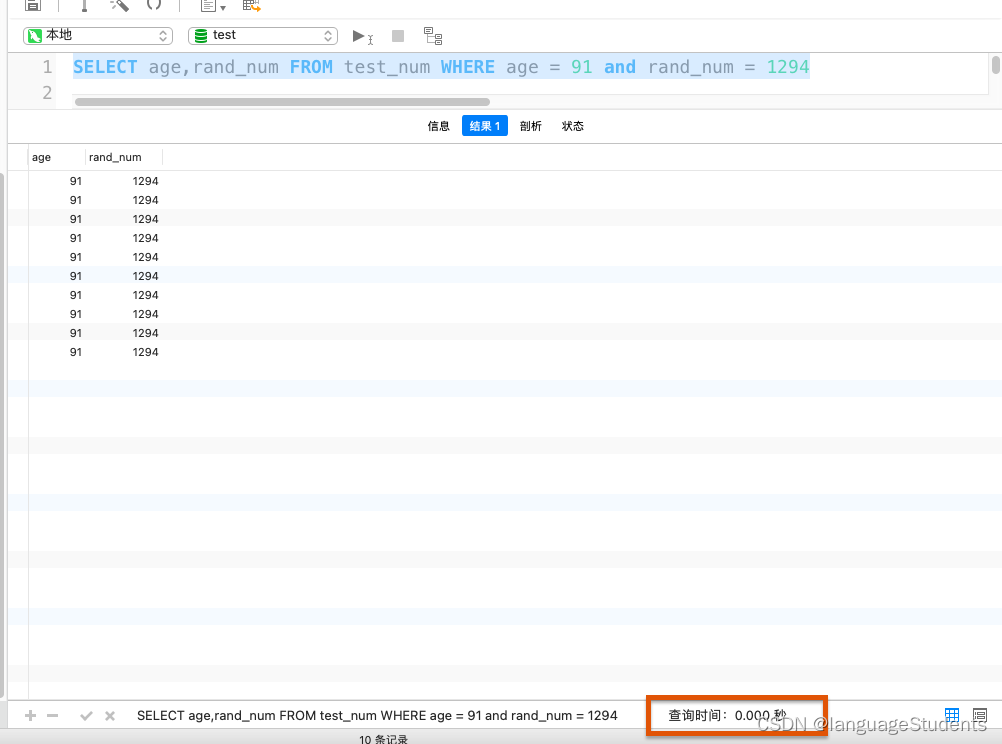
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qxzMDLgu-1659795260688)(/Users/xujiangtao/Desktop/截屏2022-08-06 21.44.42.png)]](https://img-blog.csdnimg.cn/81051638bc5343849387a1adcff2a6af.png)
4、前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));
当有些字段的长度很大的时候,或者大空间的字段类型列。适合使用前缀索引,减小索引文件大小,投稿索引的速度
有时候索引很长的字符列,这会让索引变得大且慢。通常我们可以索引开始的部分字符。这样可以大大节约索引空间,从而提高索引效率,同时也会降低索引的选择率(同样的索引值可能包含多条数据行)
不能在order by和group by中使用。也不能作为覆盖索引
5、聚簇索引
除开聚簇索引,其他的二级索引保存的是
行指针,也就是行主键,找到主键,再通过主键聚簇索引回表找到行数据
与其他索引最大的区别就是索引与数据存在同一块区域,找到了索引就表示可以找到数据。我们数据表中主键就是聚簇索引。当创建表时没有默认指定主键,mysql的存储引擎Innodb会选择唯一的非空索引代替。如果没有这样的索引,innodb会隐式的定义主键作为聚簇索引。
6、覆盖索引
这个不是具体的可以添加的索引,代表你要查询的数据列以及查询条件全部都使用到了索引。而不再需要回表通过主键查询数据。也就是查询的列于索引列一致
覆盖索引可以有效的减少IO,提高查询效率。
减少使用.
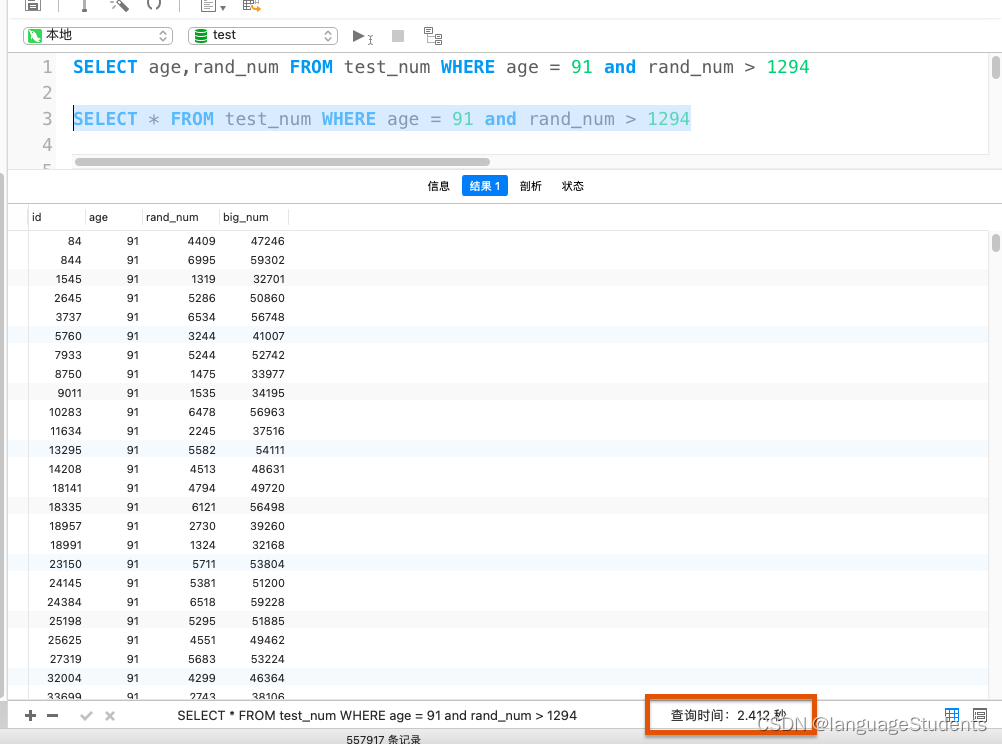
Select *
以下表有五千万的测试数据,一个使用select * 一个使用了索引字段。查询时间的对比,相差了n呗。这也就是覆盖索引所带来的好处。同时在平时也尽量避免使用Select *
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gP1pu13z-1659795260688)(/Users/xujiangtao/Desktop/截屏2022-08-06 21.23.23.png)]](https://img-blog.csdnimg.cn/05d94f9b89524ecabc82612bb26853ab.png)
索引失效场景
- 联合索引不满足最左匹配原则
- 使用
select * - 索引列参与函数计算
- 除
123%这种的其他模糊查询。%123、%123%都会失效 - 类型的隐式转换
- 索引列之间比较
- 使用条件not in、not exists 、is not null