目录
2.2 BGE / Base Graph Embedding
2.3 GES / Graph Embedding with Side Information
2.4 EGES / Enhanced Graph Embedding with Side Information
一.引言
上一篇文章我们讲到了常规场景下 Word2vec 的应用与实践 Word2vec By Gensim,本文结合推荐系统一起看下阿里巴巴在 2018 年发表的论文 《Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba》- 阿里巴巴百亿级商品 Embedding 电子商务推荐,其基本思想是在传统 GraphEmbedding - DeepWalk 模型的基础上,引入 side information 即辅助信息来补充商品信息,解决长尾商品样本量太少导致的 embedding 学习问题。电商场景下,side information 例如商家、品牌等都可以优化冷启动商品的 embedding 表征,提高推荐准确性。
二.EGES 算法演进
EGES 即 Enhanced Graph Embedding with Side information,意为引入边信息的增强图嵌入。
1.淘宝推荐系统简介
推荐系统 (Recommender Systems - RS) 一直是淘宝业务增长的最重要技术。淘宝平台有10亿+用户,20亿+商品,最关键的问题是如何帮助用户快速找到感兴趣的商品。为了实现这一目标,推荐系统也成为其发展的关键技术,它用于根据用户的喜好为用户推荐有效的商品,然而实际推荐场景下,RS 面临如下三个挑战:
• 可扩展性
尽管许多现有的推荐方法在较小规模的数据集(如数百万用户和商品)上运行良好,但在淘宝的更大规模数据集 (如10亿用户和20亿商品) 上却失败了。
• 稀疏性
由于用户倾向于只与少量商品进行交互,因此训练一个准确的推荐模型是极其困难的,特别是对于交互数量相当少的用户或商品。这通常被称为“稀疏性”问题。
• 冷启动
在淘宝,每小时都有数百万个新商品被持续上传。这些项没有用户行为。处理这些项目或预测用户对这些项目的偏好是具有挑战性的,这就是所谓的“冷启动”问题。为了解决这些问题,淘宝在技术平台设计了两阶段的推荐框架分别为 Matching 匹配和 Raning 排序,可以理解为推荐场景下的召回和排序,不同阶段下面对的问题也不同,本文主要用于解决 Matching 即匹配召回侧的问题。
2.BGE、GES、EGES 简介

文中提出了三种匹配阶段的实现方法,分别为:
• BGE / Base Graph Embedding
• GES / Graph Embedding with Side Information
• EGES / Enhanced Graph Embedding with Side Information
三种方法可以理解为一种递进的、不断迭代的实现过程,每一个算法都在上一个算法的实现基础上进行了新的修改。
2.1 用户行为序列构建
匹配方法从用户行为出发,详细阐述项目图的构建。在现实中,用户在淘宝上的行为往往是顺序的,如图中 U1、U2... 所示。以往基于 CF 的方法只考虑商品的共现性,而忽略了顺序信息可以更准确地反映用户的偏好。
• 不使用用户完整历史行为
1) 计算用户完整历史行为的计算与空间成本太高
2) 用户的兴趣会随着时间的推移而变化
兴趣变化这个很好理解,用户在不同时间段要购买的商品可能存在很大差异,这其实是一类兴趣迁移的问题,阿里巴巴的另一个推荐系统 DIEN 主要就是解决这个问题,其对应的是 Ranking 阶段,后续有机会介绍。言归正题,为了解决用户兴趣迁移的问题,这里设置一个时间窗口并在构建 Item-Graph 时只选择窗口内的用户行为,我们称之为基于 Session 会话的用户行为。Session Window 这个概念其实也不陌生,在 Flink 的 Window 类型中,除了滚动和滑动窗口外,第三种就是 Session 窗口。根据阿里巴巴实战经验,窗口的持续时间为 1 小时。
以 U2 为例,这样做与传统 DeepWalk 的区别在于序列生成的方式,传统方法下会基于 "BEDEF" 序列进行随机游走,而修改后的方法会基于 "BE"、"DEF" 两个短序列游走,由于生成的是有向带权图,因此前者有 E -> D 的 Edge 边,而后者则不存在这样的边,相对应的 ItemI 到 ItemJ 的转移概率也会有所不同。该方法主要考虑为用户单次 Session 行为下的多个 Item 可能拥有更高的相似度,从而通过单 Session 生成序列强化 Item 之间的相似性,用于未来 Matching 阶段匹配商品。
• 异常数据过滤
在提取用户行为序列之前,我们还需要过滤掉无效数据和异常行为,以消除所提方法的噪声。目前在我们的系统中,以下行为被视为噪音:
1) 非置信正样本
如果点击后的停留时间小于1秒,则该点击可能是无意的,需要删除,这里其实针对的是用户误点击或者误触造成的不置信的正样本。
2) 过度活跃样本
淘宝有一些 "过度活跃" 的用户,他们实际上是垃圾用户。根据我们在淘宝的长期观察,如果一个用户在不到 3 个月的时间里购买了1000 件商品或者总点击量超过 3500 次,那么这个用户很有可能是一个垃圾用户。我们需要过滤掉这些用户的行为。这里我觉得其实也谈不上垃圾用户,如果一个用户能够短期内购买 1000 件商品或者每天都在端内活跃的话其实对 APP 活跃生态来说还是不错的,不过其过长的序列或者涉猎过广的行为倒确实可能引入噪声影响模型训练。
3) 高频更新样本
淘宝上的零售商不断更新商品的详细信息。在极端的情况下,一件商品在经过长时间的更新后,在淘宝上的同一个标识符可能会变成完全不同的商品。因此,我们删除了同一个标识下不断更新的 Item,以免其语义变化对模型推理引入噪声。
2.2 BGE / Base Graph Embedding

BGE 与传统的 DeepWalk 方法基本一致,关于 DeepWalk 我们在之前的 graphEmbedding 中也有提及:DeepWalk 图文详解,有兴趣的同学可以参考。其步骤如下:
• 通过用户行为序列构建有向带权图,这里记为 G = (V,E)
• 根据图中 I -> J 的转移概率进行随机游走获取多个行为序列
• 使用 Skip-Gram 算法计算每个 Node 的词嵌入,从图中的 N-Negative、Positive 可以看出这里使用了负采样的优化方法
BGE 与 DeepWalk 主要差别在于用 Session 区分了用户的多次行为序列。
2.3 GES / Graph Embedding with Side Information
通过 BGE 我们可以学习淘宝中所有商品的嵌入,以捕捉用户行为序列中 Item 的高阶相似性,这是之前基于 CF 的方法所忽略的。然而,学习 "冷启动" 项目(即那些没有用户交互的项目)的精确嵌入仍然具有挑战性。为了解决冷启动问题,我们建议使用附加在冷启动项上的侧信息即 SideInformation 来增强BGE。
在电子商务RSs的语境中,侧信息是指商品的品类、店铺、价格等,这些信息在排名阶段即Ranking 阶段被广泛应用为关键特征,但在匹配阶段应用较少。我们可以通过在图嵌入中加入边信息来缓解冷启动问题。例如,来自优衣库(同一商店 ShopId)的两件帽衫(同一品类 ClassId)可能看起来很像,喜欢尼康镜头的人可能也对佳能相机(类似品类和类似品牌 BrandId)感兴趣。这意味着具有相似边信息的项目在嵌入空间中应该更接近。
基于这一假设,我们提出了GES方法,这里其实也用到了协同的思想,通过相关品类的 Side-Infomation,丰富冷启动商品的 Emb 嵌入,就像上篇文章学到的三国关系一样,如果新出现一个吴国的人物,基于现有经验,我们大概率认为其降维后 Emb 会落入红框所示的吴国区域:

为了清楚起见,这里用 W 代表项目或边信息的嵌入矩阵,其中 表示 Item V 的嵌入,而
则代表附加在项目 V 上的第 S 类边信息的嵌入,对于拥有 N 类边信息的 Item V,我们共有 N+1 个 K 维 Emb。最终采用池化的方式得到隐层的向量:
其中 是Item V 的聚合嵌入。这样,我们合并边信息,使得边信息相似的项在嵌入空间中更接近。这将导致冷启动项的嵌入更精准,从而提高离线和在线推荐效果。
2.4 EGES / Enhanced Graph Embedding with Side Information
尽管使用 GES 效果得到一定提升,但在嵌入过程中集成不同种类的边信息时仍然存在一个问题。在聚合项 的计算过程中,我们默认 SideInfo 之间是等权的,且 SideInfo 与原始 Item 向量之间也是等权的,但在实际场景中可能并不是这样,不同种类的边信息对最终嵌入的贡献可能是不相等的。
例如,用户购买了iPhone后,会因为 "Apple" 这个品牌而倾向于查看 Macbook 或 iPad,而用户在淘宝上可能会为了方便和更低的价格在同一家店购买不同品牌的衣服。因此,不同类型的侧信息对项目在用户行为中共现的贡献是不同的。
• 模型结构
为了解决这个问题,模型在原基础上引入了可 Train 的 标识不同向量对
的贡献程度:
为了保证权重的非负以及训练中参数更好的数学性质,这里采用 e 指数并且归一化权重系数来生成最终的聚合项 。

图中 S1 0 代表 Item 本身的向量,其余代表 S1 N 代表 N 类 Side Info 侧信息,聚合后使用负采样进行 Skip-Gram 的训练。在 GES 模型下,图中的 均为 1。

再回首传统的 Skip-Gram 模型,EGES 主要就是在红框处加入的 Side-Info 及其 Emb 表征,从而细致了 H 的表现形式。
• 算法伪代码
输入信息 G = (V, ε)为有向带权图,边信息为 S,游走节点 w,随机游走步长 l,窗口 Size K 以及负采样的样本数以及嵌入维度,EGES 根据 G 中随机游走得到的序列执行 WeightedSkipGram。

Weighted Skip-Gram 伪代码中给出了前向传播的方式以及反向传播更新参数的公式。

三.模型试验
1.离线评估
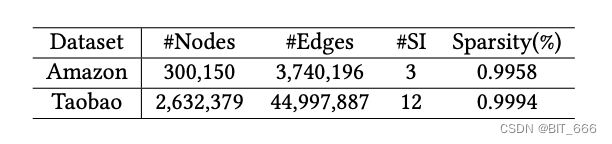
试验通过两个数据集验证模型效果,一个是 Amazon Electronics2 即为 Amazon,另一个是淘宝 App 获取的信息,即为 Taobao。对于 Amazon 的数据集基于 "共同购买" 构建商品图并添加 3 类 Side Info 包括类别、子类别和品牌,而对于淘宝数据结构则加入 12 类侧信息包含零售商、品牌、购买水平、年龄、性别、风格等。实验比较了 BGE、LINE、GES、EGES 四种方法。LINE 用于捕获图嵌入中的一阶和二阶接近性,之前也有提及 Line 图文详解。我们使用作者提供的实现,并使用一阶和二阶接近度来运行它,分别表示为 LINE(1st) 和 LINE(2nd)。我们实现了其他三个方法。所有方法的嵌入维数都设置为 d=160。对于我们的 BGE、GES 和 EGES,随机游走的长度是10,每个节点的游走次数是20,上下文窗口是5。
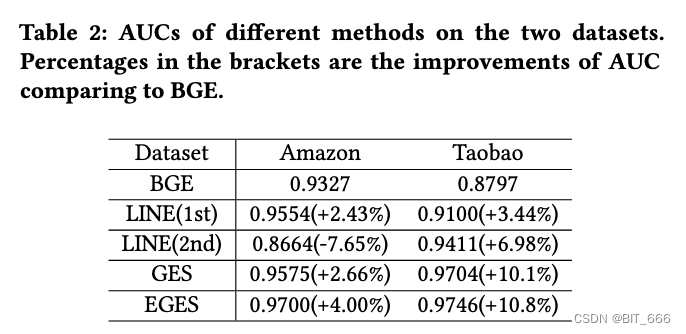
离线主要使用不同模型对数据集统计 AUC 表现,AUC 计算可以参考:Spark - AUC 理论与实战。
我们认为这是由于淘宝数据集中使用了大量有效且信息量大的侧面信息。对比 GES 和 EGES,我们可以看到亚马逊上的性能增益比淘宝上的要大。这可能是因为在淘宝上的表现已经很好了,也就是0.97。因此,EGES 的改善并不突出。
在 Amazon 数据集上,EGES 的 AUC 显著优于 GES。基于这些结果,我们可以观察到合并边信息对于图嵌入非常有用,并且可以通过对各种边信息的嵌入进行加权聚合来进一步提高精度。
2.在线评估
我们在 A/B 测试框架下进行在线实验。实验目标是手机淘宝App首页的点击率(CTR)。我们实现上述图形嵌入方法,然后为每个商品生成若干相似商品作为推荐候选商品。最终的淘宝首页推荐结果由 Ranking 引擎生成,排名引擎基于深度神经网络模型实现。我们使用同样的方法对实验中的候选项目进行排名。综上所述,相似商品的质量直接影响推荐结果。因此,推荐绩效即 CTR 可以表示不同方法在匹配阶段的有效性。
我们将这四种方法部署在A/B测试框架中,2017年11月7天的测试结果下图所示。注意,“Base”表示一种基于商品的 CF 方法,在图嵌入方法部署之前,这种方法在淘宝上已经被广泛使用。它根据项目共现和用户投票权重计算两个项目之间的相似度。相似度测量是经过精心调整的,适合淘宝的业务。从图中我们可以看到,EGES 和 GES在 CTR 方面始终优于 BGE 和 Base,这说明了在图嵌入中加入边信息的有效性。此外,Base 的 CTR 大于 BGE。这意味着基于优化 CF 的方法可以击败简单的嵌入方法,因为在实践中已经开发了大量手工制作的启发式策略。另一方面,EGES 的性能始终优于 GES,这与上面的离线实验结果一致。进一步证明加权边信息聚合优于平均边信息聚合。

3.Case 分析
在本节中,我们将介绍淘宝上的一些真实案例,以说明所提出方法的有效性。从三个方面对案例进行了分析:
• EGES嵌入的可视化

从图 7 (a)中,我们可以看到不同类别的鞋子在不同的集群中。在这里,一种颜色代表一类鞋,如羽毛球鞋、乒乓球鞋或足球鞋。它证明了嵌入边信息的有效性,即具有相似边信息的项目在嵌入空间中应该更接近。从图 7 (b)中,我们进一步分析了羽毛球、乒乓球、足球三种鞋的嵌入情况。观察到在嵌入空间中,羽毛球鞋和乒乓球鞋的距离更近,而足球鞋的距离更远,这是非常有趣的。这可以用一个现象来解释,在中国,喜欢乒乓球的人和喜欢羽毛球的人有很多重叠。然而,喜欢足球的人与喜欢室内运动(如乒乓球和羽毛球)的人有很大的不同。从这个意义上说,向看过乒乓球鞋的人推荐羽毛球鞋,比推荐足球鞋要好得多。向量可视化采用了 PCA 降维,有兴趣的同学可以参考:向量降维与可视化。
• 冷启动项

在这一部分中,我们展示了冷启动项目的嵌入质量。对于淘宝上新更新的商品,从商品图中无法学到嵌入,之前基于 CF 的方法在处理冷启动商品时也会失败。因此,我们用其侧信息的平均嵌入表示冷启动项。然后,基于两个项的内嵌点积,从现有项中检索最相似的项。结果如上图所示。我们可以看到,尽管缺少了两个冷启动项的用户行为,但可以利用不同的侧信息来有效地学习它们的嵌入。就质量而言,同类项目名列前茅。在图中,我们为每个相似项注释了连接到冷启动项的侧信息类型。我们可以看到,物品的商店对于测量两个物品的相似度是非常有信息性的
• EGES中的权重

在这一部分中,我们可视化了不同项目的不同类型侧信息的权重。选择不同类别的8个项目,从学习的权重矩阵 a 中提取与这些项目相关的所有侧信息的权重,结果如下图所示,其中每行记录一个项目的结果。有几个观察结果值得注意:
1) 不同项目的权重分布不同
这与我们的假设一致,即不同的侧信息对最终表示的贡献不同。从矩阵中的颜色深浅可以区分其重要性。
2) "Item" 的权重始终大于其他所有侧信息的权重
Item 的权重表示该项本身的嵌入量,对应传统 Skip-Gram 的原始向量表征。它证实了这样的直觉,即商品本身的嵌入仍然是用户行为的主要来源,而侧面信息为推断用户行为提供了额外的线索。
3) 除 "Item" 外 "Shop"的权重始终大于其他侧信息的权重
这与用户在淘宝上的行为是一致的,即用户倾向于在同一家商店购买商品,以方便和更低的价格。也就是常说的老客户了。
四.系统部署与实践
在本节中,我们将介绍所提出的图形嵌入方法在淘宝中的实现和部署。我们首先对整个淘宝推荐平台进行了高层次的介绍,然后详细介绍了与我们的嵌入方法相关的模块。

图中展示了淘宝推荐平台的架构。该平台由在线和离线两个子系统组成。
1.在线系统
在线子系统主要有下面两部分组成:
• 淘宝个性平台 TPP - Taobao Personality Platform
• 排名服务平台 RSP - Ranking Service Platform
当用户启动手机淘宝应用程序时,TPP 提取用户的最新信息,并从离线子系统检索一组候选商品,然后将其反馈给 RSP。RSP 使用经过微调的深度神经网络模型对候选项目集进行排名,并将排名结果返回给TPP。并最终将用户在淘宝的访问行为收集保存为离线子系统的日志数据。
2.离线系统
离线子系统实现并部署图嵌入方法的工作流程如下:
• Log Preparing
数据准备工作在在线系统的呼端、网页端已经完成
• Item-Graph Construction
检索包含用户行为的日志并基于用户行为构建 Item 图。在实际操作中,我们选择最近三个月的日志。在生成基于会话的用户行为序列之前,对数据进行反垃圾邮件处理。剩余的日志包含大约6000亿个条目。
• Random Walk
为了运行我们的图嵌入方法,我们采用了两种实用的解决方案:
1) 将整个图分割成许多子图,这些子图可以在淘宝的开放数据处理服务(ODPS)分布式平台上并行处理。每个子图中大约有5000万个节点。
2) 为了生成图中的随机游走序列,我们使用了ODPS 中基于迭代的分布式图框架。随机游走生成的序列总数约为1500亿。
• XTF
为了实现所提出的嵌入算法,我们的 XTF 平台使用了100 个 gpu。在部署的平台上,1500 亿个样本,离线子系统的所有模块,包括日志检索、反垃圾邮件处理、项目图构建、随机游走序列生成、嵌入、项目间相似度计算、地图生成等,都可以在 6 小时内完成。因此,我们的推荐服务可以在很短的时间内响应用户的最新行为。
3.离线、在线系统交互
• I2I Similarity Map
构建 Item 的相似 Map,这里采用向量内积的方式,获取的 I2I 的候选集 Map 会在 User Trigger 触发逻辑后作为 Candicate 候选集返回到 TPP,再由 TPP 通过 RSP 实现排序,从而完成离线与在线系统的结合。这里是一种经典的离线训练在线预测推理的模式,Facebook 的 GBDT+LR 一文中也提到了类似的在线训练架构,有机会可以回顾一下。
五.总结
• 论文整理
淘宝的十亿级数据 (十亿用户和20亿件商品) 在可扩展性、稀疏性和冷启动方面给 RS 推荐系统带来了巨大的压力。文中提出了基于图嵌入的方法来解决这些挑战。为了解决稀疏性和冷启动问题,我们建议在图嵌入中加入边信息。通过离线实验验证了边信息在提高推荐准确率方面的有效性。在线 CTRs 的报告也证明了我们提出的方法在淘宝现场生产的有效性和可行性。通过对实际案例的分析,突出了我们提出的图嵌入方法在使用用户行为历史聚类相关项和使用边信息处理冷启动项方面的优势。最后,为了解决我们提出的解决方案在淘宝上的可扩展性和部署问题,我们详细介绍了用于训练我们的图嵌入方法的平台和淘宝推荐平台的整体工作流程。
• 冷启动思考
文中提高 Emb 表征与推荐效果除了创新性的引入 Session 外,主要功劳还是基于 Side-Info 侧信息提供,这也让作者想到了推荐场景下非常 Common 的几种冷启动推荐方法
1) 协同推荐
对于 App 的新户,我们可能只有用户的 Gender、Age 等基础统计信息,这时候可以基于 Gender、Age 的榜单为用户推荐,这里 Gender、Age 其实就是两种侧信息。例如注册用户为 90s + Male 则我们可以构建 Age + Gender 的混合榜单,理论上随着侧信息种类 N 的增加,我们的榜单可以逐步交叉细化,当侧信息足够多时,说明 UserFeat 已经达到一定水平,此时就不再是冷启动问题了,就可以调用 Rank 模块的排序模型进行排序推荐了。
2) 热度推荐
上面主要针对 User 进行协同,当然也可以基于 Item 协同,此时比较的是 Item 的热度,我们可以构造 Item 热度榜单,至于热度的定义可以由开发者自己斟酌,高点击、高下发、高互动... 都可以作为热度的评估指标,随后构建倒排过已读已发推荐即可。
• 未来方向
论文中也给出了未来的发展方向,首先是在我们的图嵌入方法中利用注意机制,即 Attention,这在后续的开源算法 DIN、DIEN 中已经实现,它可以提供更多的灵活性来学习不同边信息的权重,本质上也是学习用户的兴趣迁移过程并将序列的次序信息让模型学习。第二个方向是将文本信息纳入我们的方法中,以利用淘宝上附在商品上的大量评论,这其实是一种基于 NLP 特征的模型特征丰富,传统场景下我们认为用户发生评论行为即为喜欢当前 Item,而引入 NLP 情感分析后,我们可以通过当前评论是正向还是负向,从而评估 User 对 Item 到底是正向还是负向态度。
参考:
Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
日常感慨大佬们的算法改进,经典且好用,继续搬砖学习 ing ......
