1. Convolution Layers
由于图像是二维的,因此基本上最常用到的就是二维的卷积类:torch.nn.Conv2d,官方文档:torch.nn.Conv2d。
Conv2d 的主要参数有以下几个:
in_channels:输入图像的通道数,彩色图像一般都是三通道。out_channels:通过卷积后产生的输出图像的通道数。kernel_size:可以是一个数或一个元组,表示卷积核的大小,卷积核的参数是从数据的分布中采样得到的,这些数是多少无所谓,因为在神经网络训练的过程中就是对这些参数进行不断地调整。stride:步长。padding:填充。padding_mode:填充模式,有zeros、reflect、replicate、circular,默认为zeros。dilation:可以是一个数或一个元组,表示卷积核各个元素间的距离。group:一般设置为1,基本用不到。bias:偏置,一般设置为 True。
例如以下代码构建了一个只有一层卷积层的神经网络,该卷积层的输入和输出通道数都为三通道,卷积核大小为3*3,步长为1,无填充,然后用 CIFAR10 测试数据集进行测试:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=64)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, padding=0)
def forward(self, input):
output = self.conv1(input)
return output
network = Network()
print(network) # Network((conv1): Conv2d(3, 6, kernel_size=(3, 3), stride=(1, 1)))
writer = SummaryWriter('logs')
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
writer.add_images('input', imgs, step)
writer.add_images('output', output, step)
writer.close()
测试结果如下:
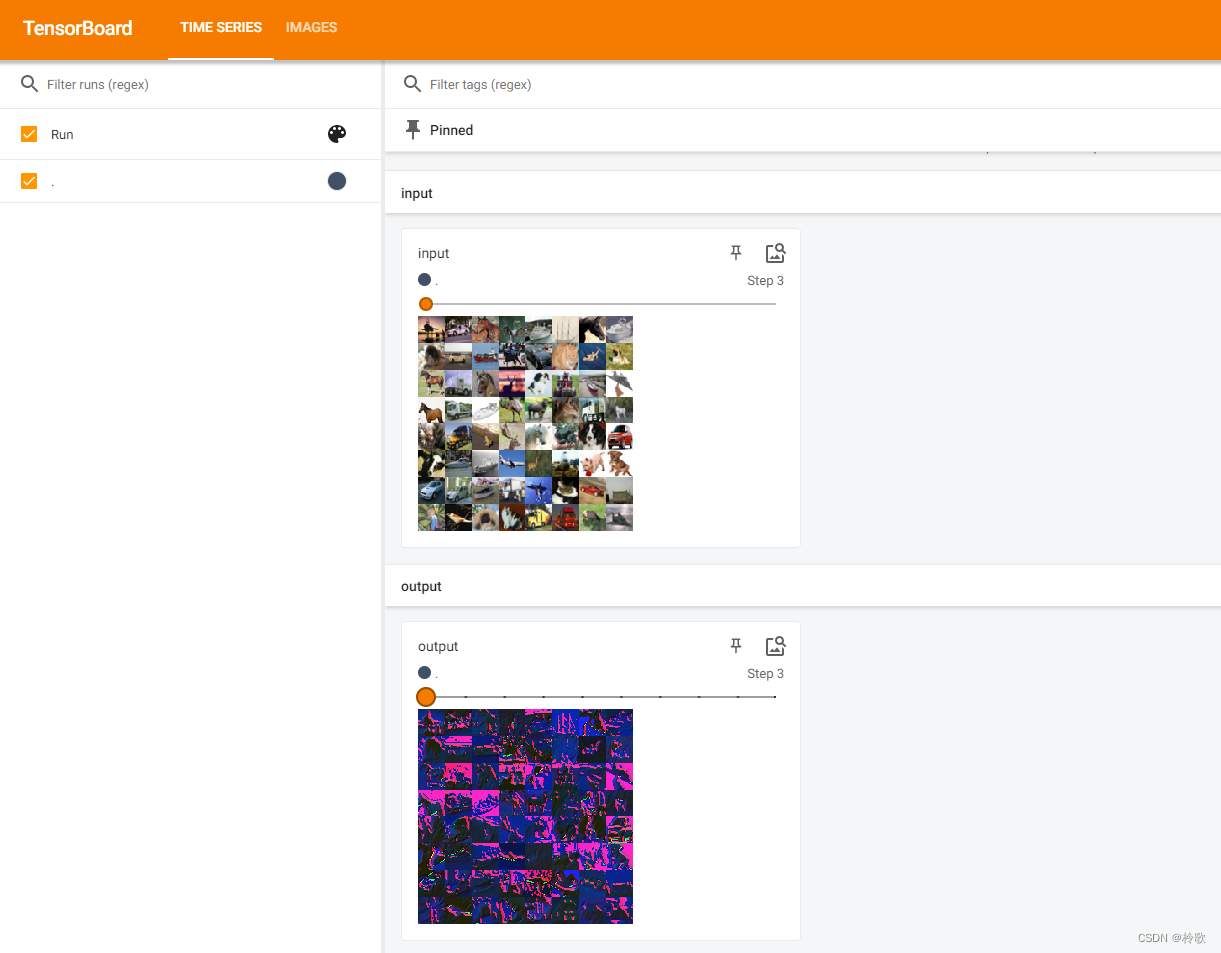
可以看到卷积运算能够提取输入图像的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。
2. Pooling Layers
Pooling Layers 相关函数介绍的官方文档:Pooling Layers。
其中的 MaxPool 表示最大池化,也称上采样;MaxUnpool 表示最小池化,也称下采样;AvgPool 表示平均池化。其中最常用的为 MaxPool2d,官方文档:torch.nn.MaxPool2d。
最大池化的步骤如下图所示:
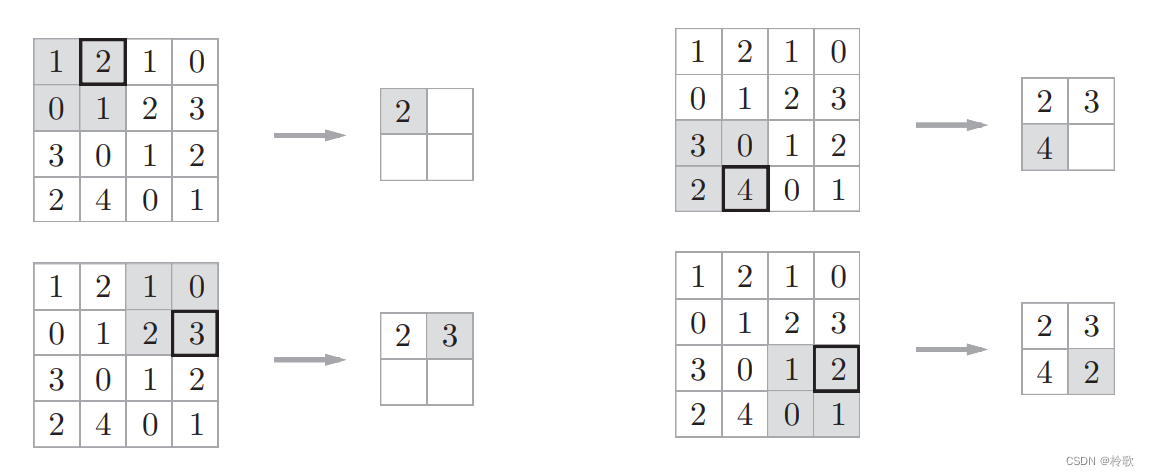
MaxPool2d 的主要参数有以下几个:
kernel_size:用来取最大值的窗口(池化核)大小,和之前的卷积核类似。stride:步长,注意默认值为kernel_size。padding:填充,和Conv2d一样。dilation:池化核中各个元素间的距离,和Conv2d一样。return_indices:如果为 True,表示返回值中包含最大值位置的索引。注意这个最大值指的是在所有窗口中产生的最大值,如果窗口产生的最大值总共有5个,就会有5个返回值。ceil_mode:如果为 True,表示在计算输出结果形状的时候,使用向上取整,否则默认向下取整。
输出结果形状的计算公式如下:

接下来我们用代码实现这个池化层:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
import torch
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
def forward(self, input):
output = self.maxpool1(input)
return output
input = torch.tensor([
[1, 2, 1, 0],
[0, 1, 2, 3],
[3, 0, 1, 2],
[2, 4, 0, 1]
], dtype=torch.float32) # 注意池化层读入的数据需要为浮点型
input = torch.reshape(input, (1, 1, 4, 4))
network = Network()
print(network) # Network((maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))
output = network(input)
print(output)
# tensor([[[[2., 3.],
# [4., 2.]]]])
我们用图像来试试效果:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=64)
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
def forward(self, input):
output = self.maxpool1(input)
return output
network = Network()
writer = SummaryWriter('logs')
for step, data in enumerate(data_loader):
imgs, targets = data
output = network(imgs)
writer.add_images('input', imgs, step)
writer.add_images('output', output, step)
writer.close()
测试结果如下:
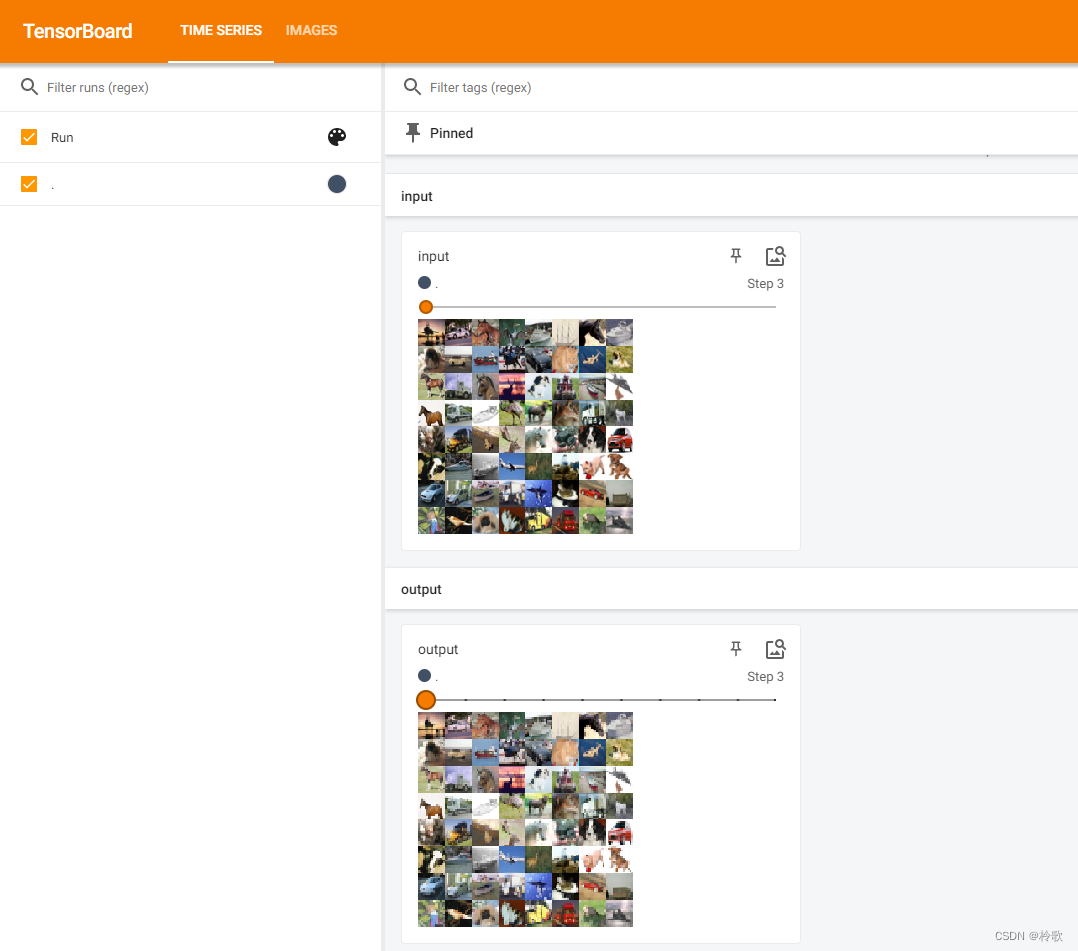
可以看到最大池化的目的是保留输入数据的特征,同时减小特征的数据量。