1. VGG16模型的使用
我们以 VGG16 为例,该网络模型是用于大规模图像识别的超深度卷积神经网络,官方文档:VGG16。
该网络模型主要有以下参数:
weights:可以设置成torchvision.models.VGG16_Weights.DEFAULT,DEFAULT表示自动使用最新的数据。老版本为pretrained,如果为 True,表示使用预先训练好的权重,在官网可以看到这个权重是在ImageNet-1K数据集训练的,默认为不使用预先训练好的权重。progress:如果为 True,则显示下载的进度条,默认为 True。
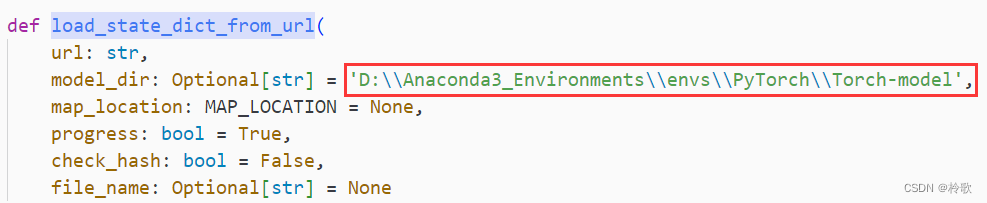
注意,下载网络时默认的下载路径是 C:\Users\<username>\.cache,因此在下载模型前,我们需要修改路径:打开 D:\Anaconda3_Environments\envs\PyTorch\Lib\site-packages\torch 中的 hub.py 文件,搜索 load_state_dict_from_url,然后修改 model_dir 即可:
然后我们输出一下这个网络模型:
import torchvision
vgg = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT)
print(vgg)
# VGG(
# (features): Sequential(
# (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (1): ReLU(inplace=True)
# (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (3): ReLU(inplace=True)
# (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (6): ReLU(inplace=True)
# (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (8): ReLU(inplace=True)
# (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (11): ReLU(inplace=True)
# (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (13): ReLU(inplace=True)
# (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (15): ReLU(inplace=True)
# (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (18): ReLU(inplace=True)
# (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (20): ReLU(inplace=True)
# (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (22): ReLU(inplace=True)
# (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (25): ReLU(inplace=True)
# (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (27): ReLU(inplace=True)
# (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
# (29): ReLU(inplace=True)
# (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
# )
# (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
# (classifier): Sequential(
# (0): Linear(in_features=25088, out_features=4096, bias=True)
# (1): ReLU(inplace=True)
# (2): Dropout(p=0.5, inplace=False)
# (3): Linear(in_features=4096, out_features=4096, bias=True)
# (4): ReLU(inplace=True)
# (5): Dropout(p=0.5, inplace=False)
# (6): Linear(in_features=4096, out_features=1000, bias=True)
# )
# )
可以看到这个模型的分类结果为1000类,那么假如我们需要分类 CIFAR10 该如何应用这个网络模型呢?一种方法就是直接将最后一层 Linear 的 out_features 改为10,还有一种方法就是再添加一层,in_features=1000, out_features=10:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torchvision
import torch.nn as nn
import torch.optim as optim
vgg = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT)
vgg.classifier.add_module('add_linear', nn.Linear(in_features=1000, out_features=10)) # 在 classifier 中加一层 Linear
# vgg.classifier[6] = nn.Linear(in_features=4096, out_features=10) # 修改 classifier 的最后一层 Linear
test_set = datasets.CIFAR10('dataset/CIFAR10', train=False, transform=transforms.ToTensor())
data_loader = DataLoader(test_set, batch_size=64)
loss = nn.CrossEntropyLoss()
optimizer = optim.SGD(vgg.parameters(), lr=0.01)
for epoch in range(20):
total_loss = 0.0
for step, data in enumerate(data_loader):
imgs, targets = data
output = vgg(imgs)
output_loss = loss(output, targets)
total_loss += output_loss
optimizer.zero_grad()
output_loss.backward()
optimizer.step()
print(total_loss)
可以看到效果是比之前自己构建的网络模型好很多的:

2. 模型的保存与读取
我们在对某些模型进行修改后可能想将其保存下来,方便以后用到时无需再构建一遍网络,可以按以下的方式将整个模型保存到路径 models/CIFAR10_VGG16.pth:
import torchvision
import torch.nn as nn
import torch
vgg = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights.DEFAULT)
vgg.classifier.add_module('add_linear', nn.Linear(in_features=1000, out_features=10)) # 在 classifier 中加一层 Linear
vgg.classifier.add_module('add_softmax', nn.Softmax(dim=1))
torch.save(vgg, 'models/CIFAR10_VGG16.pth')
其对应的加载模型的方式为:
model = torch.load('models/CIFAR10_VGG16.pth')
还有一种保存方式是将模型中的参数保存成字典的形式:
torch.save(vgg.state_dict(), 'models/CIFAR10_VGG16_STATE.pkl')
其对应的加载模型的方式为:
model = torchvision.models.vgg16()
model.load_state_dict(torch.load('models/CIFAR10_VGG16_STATE.pkl'))
注意如果是保存自己构建的网络模型,需要在模型的类的源代码中将该类导入进来,例如在 test_save.py 中用以下代码保存自己的网络:
import torch.nn as nn
import torch
class MyNetwork(nn.Module):
def __init__(self):
super(MyNetwork, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3)
def forward(self, input):
output = self.conv1(input)
return output
my_network = MyNetwork()
torch.save(my_network, 'models/My_Network.pth')
在 test_load.py 中导入时需要这样写:
import torch
from test_save import MyNetwork
model = torch.load('models/My_Network.pth')
print(model)