介绍
假钞很容易成为小型和大型企业的问题。当这些钞票不是真的时,能够识别这些钞票是非常重要的。对于日常与现金打交道的商务人士和个人而言,此过程可能非常耗时。这就需要通过自动化来实现这一目标。
因此,我们认为有必要开发一种自动机器学习假钞检测模型,即使是非专业人士也可以使用它来检测这些钞票的真伪。
本文介绍了一个实际项目,我们在该项目中开发了一个深度学习和图像分类在银行业中的应用的真实原型。目标是使用现实生活中的问题场景完成机器学习演示。我们将从数据采集和深度清理/预处理到简单地部署经过训练的模型。
我们将使用一些合适的评估指标来确保模型的性能及其学习的恰当程度。由于这是一个银行系统,我们希望确保预测准确无误。
目录
设置环境
导入依赖项
读取和加载数据集
数据转换
数据可视化
TensorBoard
模型构建
可视化预测
微调卷积网络
训练和评估
使用TensorBoard报告学习到的矩阵
模型测试
保存训练后的模型工件
本地部署
部署到云端(Streamlit Cloud)
问题陈述
如引言所述,大多数人都很难区分假钞和真钞。大多数人在这方面没有任何技能,很容易被骗子用假钞换取他们的真钞。我们将通过使用专业提供的用于研究的哥伦比亚真假银行钞票来解决这个问题的挑战。

完成此项目的先决条件是机器学习模型管道的知识、jupyter notebooks 的基本经验,以及进一步深入学习的兴趣。即使这是你第一次接触图像处理,你也不必担心,因为每一个步骤都易于掌握。
数据集描述
该数据集由 Universidad Militar Nueva Granada 在 CC BY 4.0 许可下于 2020 年提供。该数据集可用于实时检查系统,以检测纸币的面额和伪造品。就大小和图像数量而言,该数据集很大,由专业捕获的假类和真类图像组成。让我们看看下面的亮点:
该数据集包含 20800 张图像,包含 13 个类别,其中 6 个对应于原始钞票,另外 6 个对应于伪造钞票,另外 1 个对应于背景类别。
它包含纸币的照明变化、旋转和局部视图。包含3个文件夹,每个文件夹20800张图片,分别对应ds1、ds2、ds3。
每个文件夹都包含一个包含图像的训练、验证和测试子文件夹。
所有类别的图像数量都是平衡的。
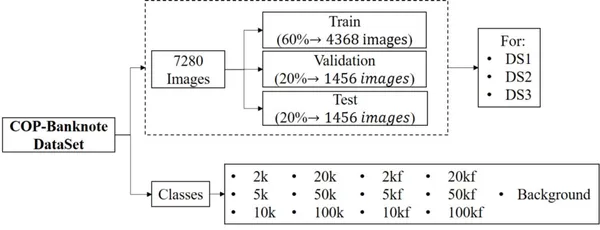
项目管道
除了掌握我们将要涵盖的所有内容之外,我还概述了下面详细开发的模型的各个步骤:
设置环境
导入依赖项
读取并加载数据集
数据转换
数据可视化
TensorBoard
模型构建
可视化预测
微调卷积网络
训练和评估
使用 TensorBoard 报告学习矩阵
模型测试
保存训练好的模型工件
本地部署
部署到云端(Streamlit Cloud)
注意:为了跟进练习,我建议你使用 Google Colab 重现这项工作,尤其是当你的计算机上没有本地 GPU 或显卡时。深度学习的一个挑战是计算环境,但感谢提供免费 GPU 的 Google Colab,我将向你展示如何使用它。
第 1 步:设置环境
话不多说,让我们开始写一些代码吧。
我们将使用 Google Colab 作为开发环境。现在你可以轻松地在线搜索 Google Colaboratory 或访问:https://colab.research.google.com/。它具有与 jupyter 相同的界面,因此你只需要一个 google 帐户就可以轻松掌握。主页如下所示:
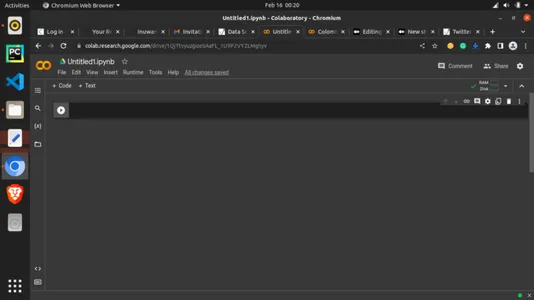
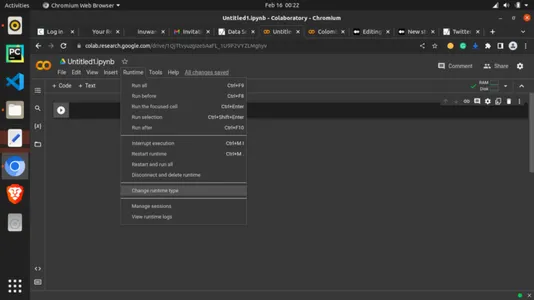
现在让我们通过将免费 GPU 添加到运行时来使用它。单击“Runtime”选项卡并选择“Change runtime type”,如下所示。
在“Hardware accelerator”下,单击下拉菜单并选择“GPU”,如下所示。
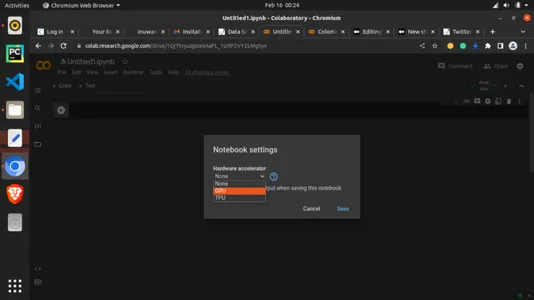
现在你已连接 GPU。我们现在可以继续编码了。
在我们开始导入依赖项之前,我们需要做最后一件事情,即使用下面的命令设置matplotlib以便为输出或图形组织提供帮助。
#magic function for matplotlib graphs. Graphs will be included in notebook next to the code.
%matplotlib inline第 2 步:导入依赖
#importing dependencies
from __future__ import print_function, division
from datetime import datetime
from PIL import Image
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
from torchvision.datasets import ImageFolder
import torchvision.transforms as T
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
import time
import os
import copy
plt.ion() # interactive mode第 3 步:加载数据集
你可以在本文末尾或从本文随附的公共 GitHub 存储库中找到指向数据集的链接。下载数据集后,你可以将其上传到你的谷歌驱动器以方便使用。我已经有了数据集,只需加载驱动程序并运行单元格。
from google.colab import drive
drive.mount('/content/drive')
#Dataset from drive
DATA_FILE = "/content/drive/MyDrive/MLProjects/dataset/COP"
train_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Train/"
val_dataset_location = "/content/drive/MyDrive/Datasets/dataset/COP/Validation/"注意:对于上面的代码片段,你必须将路径替换为你自己的 google drive 文件路径。
第 4 步:数据转换
#changing the format and structure of the data.
data_transforms = {
'Train': transforms.Compose([
transforms.Resize((224, 224)),# resizing the image dimention
transforms.RandomHorizontalFlip(),# generating different possible image position
transforms.ToTensor(), # tensors are like the data type for deep learning images
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # normalizes the tensor image for each channel regards mean and SD
]),
'Validation': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'Test': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = DATA_FILE
data_types = ['Train', 'Validation', 'Test'] # grouping into the various sets
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in data_types}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in data_types}
dataset_sizes = {x: len(image_datasets[x]) for x in data_types}
class_names = image_datasets['Train'].classes
#checking for available processor
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")第 5 步:数据可视化
借助数据可视化,我们可以从图像中看到数据的外观以及我们正在处理的内容。
# Reasigning images for visualization
image_size = 300
batch_size = 128
# converting to Tensors for visualization purpose
train_dataset = ImageFolder(data_dir+'/Train', transform=ToTensor())
val_dataset = ImageFolder(data_dir+'/Validation', transform=ToTensor())
img, label = val_dataset[13]
print(img.shape, label)
img上面的代码向我们展示了索引 13 处的一个 val_datasets 的张量版本。
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(dataloaders['Train']))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out, title=[class_names[x] for x in classes])
# attempting to show the image classes and directories
print("List of Directories:", os.listdir(data_dir))
classes = os.listdir(data_dir + "/Train")
print("List of classes:", classes)目录列表: [‘Validation,’ ‘Test,’ ‘Train’]
类列表:[‘2k’, ‘20k’, ‘50kf’, ‘20kf’, ‘5kf’, ‘Background’, ‘5k’, ‘50k’, ‘10k’, ‘10kf’, ‘100k’, ‘2kf’, ‘100kf’]
# carrying out more visualization
import matplotlib.pyplot as plt
def show_example(img, label):
print('Label: ', train_dataset.classes[label], "("+str(label)+")")
plt.imshow(img.permute(1, 2, 0))
import random
random_value = random.randint(1, 2000)# getting random images
show_example(*train_dataset[2000])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
random_value = random.randint(1, 2000)
show_example(*train_dataset[random_value])
第 6 步:TensorBoard
TensorBoard 是进行机器学习训练的好方法,这样你以后就可以直观地看到各种参数是如何变化的。它是一种在机器学习工作流程中以可视化形式提供测量变化的工具。它可以看作是一种参数记录。我们将在这里使用它来跟踪最后一次运行的损失、准确性,甚至异常值。
代码输入:
#tensorboard logging
#to track various metrics such as accuracy and log loss on training or validation set
from torch.utils.tensorboard import SummaryWriter
TB_DIR = f'runs/exp_{datetime.now().strftime("%Y%m%d-%H%M%S")}'
tb_train_writer = SummaryWriter(f'{TB_DIR}/Train')
tb_val_writer = SummaryWriter(f'{TB_DIR}/Validation')
%load_ext tensorboard第 7 步:模型构建
让我们用我们想要的所有参数和设置构建一个辅助函数,我们可以稍后调用它。
代码输入:
# helper function
def train_model(model, criterion, optimizer, scheduler, num_epochs=4):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['Train', 'Validation']:
if phase == 'Train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'Train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'Train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'Train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
if phase == 'Train':
tb_writer = tb_train_writer
else:
tb_writer = tb_val_writer
tb_writer.add_scalar(f'Loss', epoch_loss, epoch)
tb_writer.add_scalar(f'Accuracy', epoch_acc, epoch)
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
if phase == 'Validation' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
tb_train_writer.close()
tb_val_writer.close()
# load best model weights
model.load_state_dict(best_model_wts)
return model第 8 步:可视化预测
我们还要编写另一个辅助函数来进行预测。
代码:
def visualize_model(model, dataset, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders[dataset]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images//2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {}'.format(class_names[preds[j]]))
imshow(inputs.cpu().data[j])
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)第 9 步:微调 Convnet
我们将加载预训练模型并重置最终的全连接层。这种做法被称为迁移学习。我们从已经训练的模型中借用一些知识,而不是依赖于我们对参数所做的设置。这是一个称为 ResNet18 的残差网络。
残差网络:深度学习由多种人工神经网络组成,残差神经网络就是其中之一。
代码输入:
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to number of classes.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, len(class_names))
model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)第 10 步:训练和评估
最后,我们开始训练模型。我们调用之前编写的辅助函数并设置训练参数。我们将 epochs 设置为 13。13个 epochs 意味着它会在这里执行 13 次,但你可以尝试其他更高或更低的值。
代码输入:
# setting the number of epochs and other key parametersp
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=13)输出:
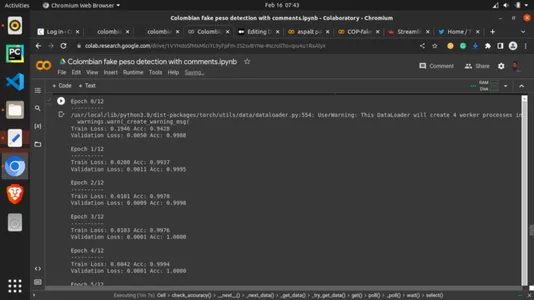
第 11 步:显示学习指标的 TensorBoard
代码输入:
# calling the tensorboard
%tensorboard --logdir='./runs'第 12 步:保存训练好的模型
最后,我们将使用 torch 的save方法和PyTorch的.pt扩展名保存模型。等待一会儿,然后在左侧栏中检查保存的模型,右键单击它,选择“download”。该模型将下载到你的计算机中。这被称为工件。我们将在下一节中使用此工件。
代码输入:
torch.save(model_ft, 'model100.pt')
第 13 步:在本地部署保存的模型
我们将尝试在GUI中实时查看我们的模型进行预测。在这里,我们将为Streamlit框架创建一个Python脚本。代码的详细信息在附带本文的GitHub存储库中。
Streamlit是一个轻量级框架,旨在将机器学习框架部署到本地或云中。我们将首先看到本地版本,然后是云版本。
在你选择的任何代码编辑器中创建一个文件,并将其保存为Python .py扩展名,并编写下面的代码。
代码输入:
# importing dependencies
import io
from PIL import Image
import streamlit as st
import torch
from torchvision import transforms
import base64
# setting background
def add_bg_from_local(image_file):
with open(image_file, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
st.markdown(
f"""
<style>
.stApp {
{
background-image: url(data:images/{"jpg"};base64,{encoded_string.decode()});
background-size: cover
}}
</style>
""",
unsafe_allow_html=True
)
add_bg_from_local('images/bg2.jpg')
# importing model
MODEL_PATH = 'model/model100.pt'
# importing class names
LABELS_PATH = 'model/model_classes.txt'
# image picker
def load_image():
uploaded_file = st.file_uploader(label='Pick a banknote to test')
if uploaded_file is not None:
image_data = uploaded_file.getvalue()
st.image(image_data)
return Image.open(io.BytesIO(image_data))
else:
return None
def load_model(model_path):
model = torch.load(model_path, map_location='cpu')
model.eval()
return model
def load_labels(labels_file):
with open(labels_file, "r") as f:
categories = [s.strip() for s in f.readlines()]
return categories
def predict(model, categories, image):
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
all_prob, all_catid = torch.topk(probabilities, len(categories))
for i in range(all_prob.size(0)):
st.write(categories[all_catid[i]], all_prob[i].item())
def main():
st.title('Colombian Pesu banknote Detection')
model = load_model(MODEL_PATH)
categories = load_labels(LABELS_PATH)
image = load_image()
result = st.button('Predict image')
if result:
st.write('Checking...')
predict(model, categories, image)
if __name__ == '__main__':
main()注意:随着模型一起导入的类文件也必须被创建。要创建这个文件,创建一个名为“model_classes.txt”的文本文件。保存它,然后将模型下载到名为“model”的文件夹中,该文件夹与python脚本位于同一目录中。
另外,你必须注意,类名必须根据他们的训练方式。你可以从我们打印上面的类和目录的地方找到它。让每个类占据单独的一行,因为模型将一行一行地读取文本文件,如下所示。
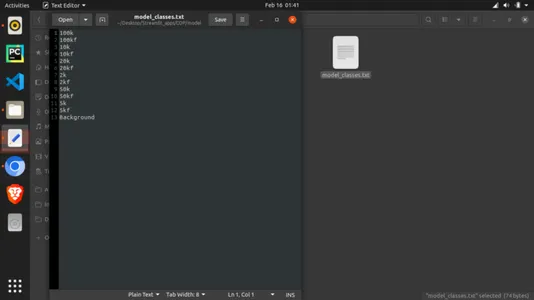
要运行 python 脚本,你必须安装一些软件包(如果你还没有)。以下是依赖项,你可以在 repo 中找到它们:
streamlit
torch
torchvision
在安装完所需的依赖之后,在你的脚本所在目录中打开终端,输入以下命令来运行 Streamlit 应用程序:
streamlit run filename.py希望这将显示你的应用程序如下:
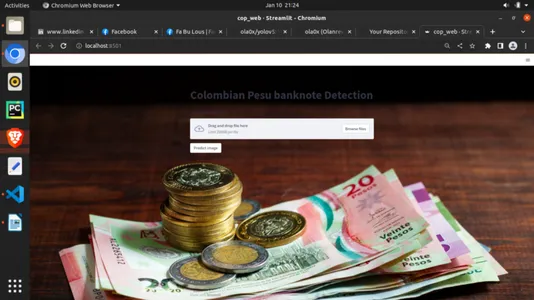
第 14 步:部署到云端
也许你想与其他人分享你的机器学习应用程序,这可以通过云基础设施来完成。你必须将你的工作目录移动到 GitHub 等在线代码管理平台,以将存储库与 Streamlit Cloud 连接。
使用 Git 推送你的目录,然后转到:https://streamlit.io/cloud
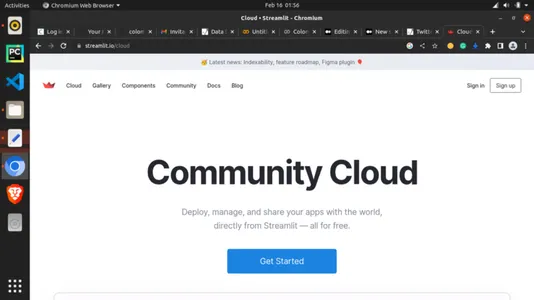
注册并点击“Get Started”。你需要注册,这完全免费!注册后选择你的 GitHub 仓库并选择它。选择部署并等待你的应用程序完成!现在你可以复制链接分享了。
结论
本文演示了如何使用深度学习训练、保存和部署一个检测假钞的机器学习模型。我们使用了 Streamlit 轻量级框架,展示了如何在本地和云端部署模型。最终我们在第三个 epoch 取得了 100% 的准确率。
要点
假钞很容易成为银行业的问题,使用深度学习进行辨别可以有效解决这个问题。
我们开发了一个自动化机器学习的假钞检测模型,即使对于非专业人士也能够判断钞票的真伪。
我们使用了适当的评估指标,包括损失和准确率,并取得了 100% 的准确率。
我们使用深度学习在本地和云端部署了该模型。
参考
Pachon Suescun, Cesar; Ballesteros, Dora Maria; Renza, Diego (2020), “Original and counterfeit Colombian peso banknotes”, Mendeley Data, V1, doi: 10.17632/tj8kvrbfz6.1
链接
公共 GitHub 存储库: https://github.com/inuwamobarak/Deep-learning-in-Banking
数据集: https: //data.mendeley.com/datasets/tj8kvrbfz6/1
Streamlit:https://streamlit.i o/
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
