四 Redis 解决session共享[刚需]
4.1 session共享问题
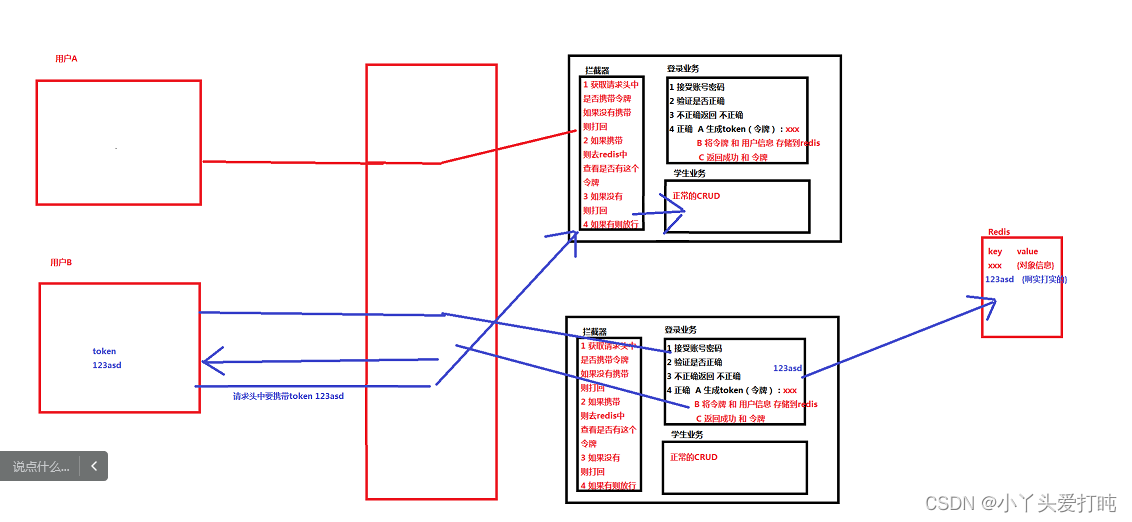
我们之前都是单点项目,对于用户的信息存储都是使用session进行存储。但是在集群环境中,此时session就会有问题:
例如登录成功之后 用户信息存储到session中,但是由于nginx负载均衡,此时有可能轮训到其他服务器 此时另一个服务器的session中没有用户信息 判定没有登录 其实已经登录。核心原因是 session 服务器存储 不能共享
1 创建一个数据库表 t_login
id username password nickname telephone
1 123 123 张三 15199996666
2 456 456 李四 18977776666
2 登录业务
@RequestMapping("user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@Autowired
private HttpSession session;
@PostMapping("login")
public AjaxResult login(@RequestBody TLogin login){
TLogin user = userService.login(login);
if(user == null){
return AjaxResult.fail("账号或密码不正确");
}
//用户信息存储到session
session.setAttribute("user",user);
return AjaxResult.success();
}
}
3 登录拦截
@Component
public class LoginInterceptor implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new HandlerInterceptor() {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
Object user = request.getSession().getAttribute("user");
if(user == null){
response.getWriter().write("must login!!!!");
return false;
}
return true;
}
}).addPathPatterns("/**").excludePathPatterns("/user/login").excludePathPatterns("/doc.html");
}
}
4 此时我们项目开发完成 打包到服务器
4.2 令牌机制解决问题
4.3boot整合Redis
注意 需要存储到redis中的类 都需要实现序列化接口
1 导入jar包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
#2 添加配置文件
spring.redis.host=192.168.150.130
spring.redis.port=6379
spring.redis.database=0
spring.redis.password=
spring.redis.timeout=10s
# 连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
# 连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=8
# 连接池的最大数据库连接数
spring.redis.lettuce.pool.max-active=8
# #连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.lettuce.pool.max-wait=-1ms
3 添加配置类
@Configuration
@EnableCaching
public class RedisConfig extends CachingConfigurerSupport
{
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory)
{
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(connectionFactory);
// 使用StringRedisSerializer来序列化和反序列化redis的key值
template.setKeySerializer(new StringRedisSerializer());
template.setValueSerializer(new JdkSerializationRedisSerializer());
// Hash的key也采用StringRedisSerializer的序列化方式
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new JdkSerializationRedisSerializer());
template.afterPropertiesSet();
return template;
}
}
4 添加工具类
@Component
public class RedisCache
{
@Autowired
public RedisTemplate redisTemplate;
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
*/
public <T> void setCacheObject(final String key, final T value)
{
redisTemplate.opsForValue().set(key, value);
}
/**
* 缓存基本的对象,Integer、String、实体类等
*
* @param key 缓存的键值
* @param value 缓存的值
* @param timeout 时间
* @param timeUnit 时间颗粒度
*/
public <T> void setCacheObject(final String key, final T value, final Integer timeout, final TimeUnit timeUnit)
{
redisTemplate.opsForValue().set(key, value, timeout, timeUnit);
}
/**
* 设置有效时间
*
* @param key Redis键
* @param timeout 超时时间
* @return true=设置成功;false=设置失败
*/
public boolean expire(final String key, final long timeout)
{
return expire(key, timeout, TimeUnit.SECONDS);
}
/**
* 设置有效时间
*
* @param key Redis键
* @param timeout 超时时间
* @param unit 时间单位
* @return true=设置成功;false=设置失败
*/
public boolean expire(final String key, final long timeout, final TimeUnit unit)
{
return redisTemplate.expire(key, timeout, unit);
}
/**
* 获取有效时间
*
* @param key Redis键
* @return 有效时间
*/
public long getExpire(final String key)
{
return redisTemplate.getExpire(key);
}
/**
* 判断 key是否存在
*
* @param key 键
* @return true 存在 false不存在
*/
public Boolean hasKey(String key)
{
return redisTemplate.hasKey(key);
}
/**
* 获得缓存的基本对象。
*
* @param key 缓存键值
* @return 缓存键值对应的数据
*/
public <T> T getCacheObject(final String key)
{
ValueOperations<String, T> operation = redisTemplate.opsForValue();
return operation.get(key);
}
/**
* 删除单个对象
*
* @param key
*/
public boolean deleteObject(final String key)
{
return redisTemplate.delete(key);
}
/**
* 删除集合对象
*
* @param collection 多个对象
* @return
*/
public boolean deleteObject(final Collection collection)
{
return redisTemplate.delete(collection) > 0;
}
/**
* 缓存List数据
*
* @param key 缓存的键值
* @param dataList 待缓存的List数据
* @return 缓存的对象
*/
public <T> long setCacheList(final String key, final List<T> dataList)
{
Long count = redisTemplate.opsForList().rightPushAll(key, dataList);
return count == null ? 0 : count;
}
/**
* 获得缓存的list对象
*
* @param key 缓存的键值
* @return 缓存键值对应的数据
*/
public <T> List<T> getCacheList(final String key)
{
return redisTemplate.opsForList().range(key, 0, -1);
}
/**
* 缓存Set
*
* @param key 缓存键值
* @param dataSet 缓存的数据
* @return 缓存数据的对象
*/
public <T> BoundSetOperations<String, T> setCacheSet(final String key, final Set<T> dataSet)
{
BoundSetOperations<String, T> setOperation = redisTemplate.boundSetOps(key);
Iterator<T> it = dataSet.iterator();
while (it.hasNext())
{
setOperation.add(it.next());
}
return setOperation;
}
/**
* 获得缓存的set
*
* @param key
* @return
*/
public <T> Set<T> getCacheSet(final String key)
{
return redisTemplate.opsForSet().members(key);
}
/**
* 缓存Map
*
* @param key
* @param dataMap
*/
public <T> void setCacheMap(final String key, final Map<String, T> dataMap)
{
if (dataMap != null) {
redisTemplate.opsForHash().putAll(key, dataMap);
}
}
/**
* 获得缓存的Map
*
* @param key
* @return
*/
public <T> Map<String, T> getCacheMap(final String key)
{
return redisTemplate.opsForHash().entries(key);
}
/**
* 往Hash中存入数据
*
* @param key Redis键
* @param hKey Hash键
* @param value 值
*/
public <T> void setCacheMapValue(final String key, final String hKey, final T value)
{
redisTemplate.opsForHash().put(key, hKey, value);
}
/**
* 获取Hash中的数据
*
* @param key Redis键
* @param hKey Hash键
* @return Hash中的对象
*/
public <T> T getCacheMapValue(final String key, final String hKey)
{
HashOperations<String, String, T> opsForHash = redisTemplate.opsForHash();
return opsForHash.get(key, hKey);
}
/**
* 获取多个Hash中的数据
*
* @param key Redis键
* @param hKeys Hash键集合
* @return Hash对象集合
*/
public <T> List<T> getMultiCacheMapValue(final String key, final Collection<Object> hKeys)
{
return redisTemplate.opsForHash().multiGet(key, hKeys);
}
/**
* 删除Hash中的某条数据
*
* @param key Redis键
* @param hKey Hash键
* @return 是否成功
*/
public boolean deleteCacheMapValue(final String key, final String hKey)
{
return redisTemplate.opsForHash().delete(key, hKey) > 0;
}
/**
* 获得缓存的基本对象列表
*
* @param pattern 字符串前缀
* @return 对象列表
*/
public Collection<String> keys(final String pattern)
{
return redisTemplate.keys(pattern);
}
}
4.4 通过token+redis实现session共享
1 登录业务
@RequestMapping("user")
@RestController
public class UserController {
@Autowired
private UserService userService;
@Autowired
private RedisCache redisCache;
@PostMapping("login")
public AjaxResult login(@RequestBody TLogin login){
TLogin user = userService.login(login);
if(user == null){
return AjaxResult.fail("账号或密码不正确");
}
// 1 生成token
String token = UUID.randomUUID().toString();
// 2 将token 存储到redis中 按理说应该是 25-30之间随机
redisCache.setCacheObject(token,user,60, TimeUnit.SECONDS);
// 3 返回token
return AjaxResult.success(token);
}
}
@Component
public class LoginInterceptor implements WebMvcConfigurer {
@Autowired
private RedisCache redisCache;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new HandlerInterceptor() {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1 请求头中查看是否有 token
String token = request.getHeader("token");
if(token == null){
PrintWriter out = response.getWriter();
out.write("sorry must have token");
return false;
}
Object cacheObject = redisCache.getCacheObject(token);
if(cacheObject == null){
PrintWriter out = response.getWriter();
out.write("sorry time out , login again");
return false;
}
return true;
}
}).addPathPatterns("/**").excludePathPatterns("/user/login").excludePathPatterns("/doc.html");
}
}
五 Redis解决数据缓存[时序]
5.1 为什么需要缓存
当我们项目中遇到 查询非常频繁 但是增删改查非常少的情况 为了提高性能 需要添加缓存
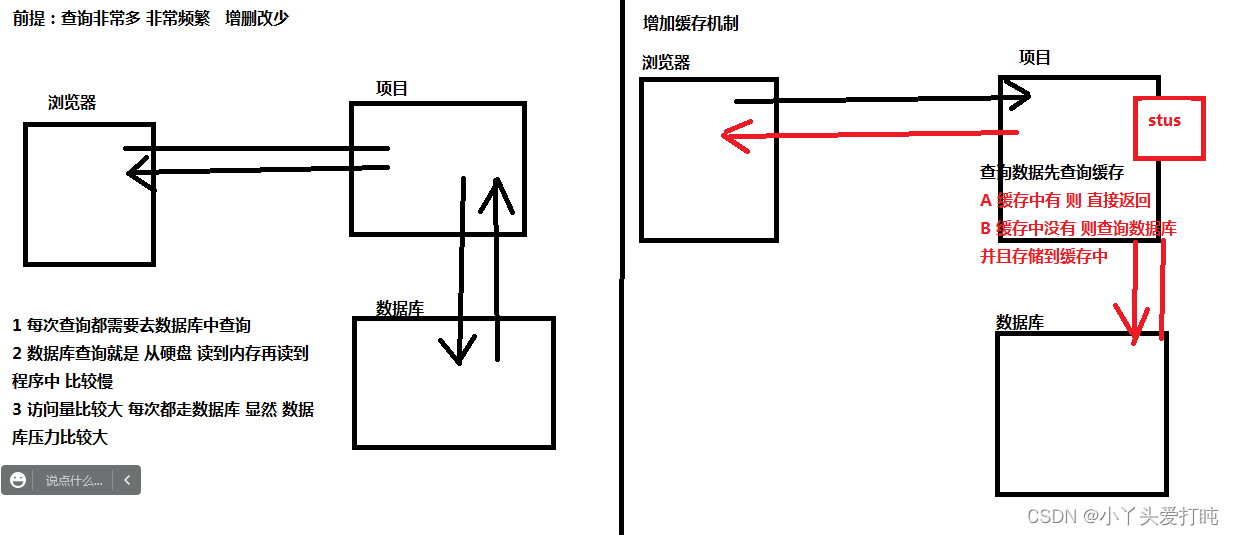
增删改会造成数据和缓存不一致 所以需要清除缓存 增删改比较多的情况下 涉及到一直清缓存 所以缓存的存在不仅没有提高性能 反而损耗较大
5.2 mybatis的缓存:一级缓存
mybatis一级缓存 默认是开启状态 ,他是基于 同一个 SQLsession的 在web环境中 可以理解成 一次请求
例如:
@Override
@Transactional // 必须加 不然也不走缓存
public List<Student> listAllStudent() {
List<Student> students1 = studentMapper.listAllStudent();
List<Student> students2 = studentMapper.listAllStudent();
List<Student> students3 = studentMapper.listAllStudent();
List<Student> students4 = studentMapper.listAllStudent();
return studentMapper.listAllStudent();
}
我们发送了 两波请求 每波 请求查询所有学生 四次。
第一波
第一次走缓存但是缓存没有 所以走数据库 第二次--第四次走缓存 缓存中有数据 所有走 缓存 此时请求结束缓存销毁
第二波
第一次走缓存但是缓存没有 所以走数据库 第二次--第四次走缓存 缓存中有数据 所有走 缓存 此时请求结束
5.3 mybatis的缓存:二级缓存
mybatis 二级缓存默认是关闭的 如果想要开启 则在mapper中添加 <cache />标签
mybatis的二级缓存是基于 mapper 的。 同一个mapper的查询是缓存的
@Autowired
private StudentMapper studentMapper;
@Autowired
private HahaMapper hahaMapper;
@Override
@Transactional
public List<Student> listAllStudent() {
List<Student> students1 = studentMapper.listAllStudent();
List<Student> students2 = studentMapper.listAllStudent();
List<Student> students3 = hahaMapper.listAllStudent();
List<Student> students4 = hahaMapper.listAllStudent();
return studentMapper.listAllStudent();
}
StudentMapper 和 HahaMapper 是不一样的mapper 但是里面的 listAllStudent方法的sql是一样的 查出来的数据也是一样的。
此时我们发送了两波请求 每波 不同的mapper查询两次
第一波时候:
第一次 studentmapper走缓存 没有则进行查询 第二次 走缓存 发现有 直接获取
第三次 hahamapper 走缓存 没有则进行查询 第四次 走缓存 发现有 直接获取
第二波时候:
第一次 studentmapper走缓存 有直接获取 第二次 走缓存 发现有 直接获取
第三次 hahamapper 走缓存 有直接获取 第四次 走缓存 发现有 直接获取
mybatis一级缓存 默认开启 基于sqlsession 请求结束 缓存没有
mybatis二级缓存 需要xml配置<cache>开启 基于同一个mapper 只要缓存则多次请求可以共享使用
5.4 缓存的特点与局限性
MyBatis 内置了一个强大的事务性查询缓存机制,它可以非常方便地配置和定制。 为了使它更加强大而且易于配置,我们对 MyBatis 3 中的缓存实现进行了许多改进。
默认情况下,只启用了本地的会话缓存,它仅仅对一个会话中的数据进行缓存。 要启用全局的二级缓存,只需要在你的 SQL 映射文件中添加一行:
<cache/>
基本上就是这样。这个简单语句的效果如下:
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象(无论查询方法返回哪种)的 1024 个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
提示 缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
这些属性可以通过 cache 元素的属性来修改。比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
可用的清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
提示 二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
但是 mybatis 自带的二级缓存 我们平时 需要缓存的时候 也不用它 因为在集群环境中 无法共享 就会产生脏数据
例如 我们开启二级缓存 测试一下
5.5 Redis实现mybatis的自定义缓存
除了上述自定义缓存的方式,你也可以通过实现你自己的缓存,或为其他第三方缓存方案创建适配器,来完全覆盖缓存行为。
<cache type="com.domain.something.MyCustomCache"/>
这个示例展示了如何使用一个自定义的缓存实现。type 属性指定的类必须实现 org.apache.ibatis.cache.Cache 接口,且提供一个接受 String 参数作为 id 的构造器。 这个接口是 MyBatis 框架中许多复杂的接口之一,但是行为却非常简单。
public interface Cache {
String getId();
int getSize();
void putObject(Object key, Object value);
Object getObject(Object key);
boolean hasKey(Object key);
Object removeObject(Object key);
void clear();
}
为了对你的缓存进行配置,只需要简单地在你的缓存实现中添加公有的 JavaBean 属性,然后通过 cache 元素传递属性值,例如,下面的例子将在你的缓存实现上调用一个名为 setCacheFile(String file) 的方法:
A 创建一个类 实现Cache接口
package com.aaa.haha.cache;
import com.aaa.haha.util.ApplicationContextHolder;
import com.aaa.haha.util.RedisCache;
import org.apache.ibatis.cache.Cache;
import java.util.Collection;
public class MyRedisCache implements Cache {
private final String id;
private RedisCache cache;
public RedisCache getRedisCache(){
RedisCache bean = ApplicationContextHolder.getBean(RedisCache.class);
return bean;
}
/*
@Autowired
RedisCache cache;
此时我们不能通过依赖注入的形式 获取 RedisCache对象
因为 MyRedisCache 类 是 mybatis创建并且管理的
@Autowired 只能是spring管理的对象 进行依赖注入
我们在非bean中 获取bean对象 就需要自己手动从工厂中获取
*/
public MyRedisCache(String id){
this.id = id;
}
@Override
public String getId() {
return id;
}
@Override
public void putObject(Object key, Object value) {
// 当mybatis 需要缓存数据的时候 就会调用这个函数 我们只需要在这个函数中 将数据存储到redis
RedisCache redisCache = getRedisCache();
redisCache.setCacheObject( key.toString() , value );
}
@Override
public Object getObject(Object key) {
// 当mybatis 需要获取缓存数据的时候 就会调用这个函数 我们只需要在这个函数中 从redis中获取对应的数据即可
RedisCache redisCache = getRedisCache();
return redisCache.getCacheObject( key.toString());
}
@Override
public Object removeObject(Object key) {
RedisCache redisCache = getRedisCache();
redisCache.expire( key.toString(), 0);
return null;
}
@Override
public void clear() {
// 增删改的时候 需要清空缓存 我们之可以清除 mybatias的缓存 不能清除其他的 例如 token
RedisCache redisCache = getRedisCache();
Collection<String> bean = redisCache.keys("*Bean");
bean.forEach(s -> {
redisCache.expire( s , 0);
});
}
@Override
public int getSize() {
RedisCache redisCache = getRedisCache();
Collection<String> bean = redisCache.keys("*Bean");
return bean.size();
}
}
@Component
public class ApplicationContextHolder implements ApplicationContextAware {
private static ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
ApplicationContextHolder.applicationContext = applicationContext;
}
public static <T> T getBean(Class<T> c){
T bean = ApplicationContextHolder.applicationContext.getBean(c);
return bean;
}
}
B 在mapper中 指定使用的 缓存类是什么
<cache type="com.aaa.haha.cache.MyRedisCache"></cache>
六 Redis主从模式
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NLcUo5Oj-1666013686045)(…/…/课件/144/框架/redis/assets/image-20201229145817420.png)]
6.1 搭建集群并配置主从
| IP地址 | 服务 | 角色 |
|---|---|---|
| 192.168.150.130:8001 | redis | 主 master |
| 192.168.239.131:8003 | redis | 从 slave |
克隆一台有redis的linux系统 修改ip地址 修改hostname 重启 xshell连接
修改主redis配置文件: vim /usr/local/redis/bin/redis.conf
:69 bind 192.168.239.110 让redis开启远程访问
:92 port 8001 端口
:136 daemonize yes 守护进程
修改从redis配置文件: vim /usr/local/redis/bin/redis.conf
:69 bind 192.168.239.111
:92 port 8003
:136 daemonize yes
:70 slaveof 192.168.239.130 8001
启动两台redis服务
连接redis: ./redis-cli -h 192.168.239.160 -p 8001 -c
连接redis: ./redis-cli -h 192.168.239.161 -p 8003 -c
测试主从 在主redis中添加数据 set aaa bbb set bbb cccc
在从redis中获取数据 get aaa get bbb
测试读写 在从redis中添加数据
192.168.239.161:8003> set hahahaha hehehehe
(error) READONLY You can't write against a read only replica.
得到结论 从redis 不允许写操作
6.2 redis的主从原理
实现主从复制(Master-Slave Replication)的工作原理:Slave从节点服务启动并连接到Master之后,它将主动发送一个SYNC命令。Master服务主节点收到同步命令后将启动后台存盘进程,同时收集所有接收到的用于修改数据集的命令,在后台进程执行完毕后,Master将传送整个数据库文件到Slave,以完成一次完全同步。而Slave从节点服务在接收到数据库文件数据之后将其存盘并加载到内存中。此后,Master主节点继续将所有已经收集到的修改命令,和新的修改命令依次传送给Slaves,Slave将在本次执行这些数据修改命令,从而达到最终的数据同步。 如果Master和Slave之间的链接出现断连现象,Slave可以自动重连Master,但是在连接成功之后,一次完全同步将被自动执行
主从复制配置:
第一步:修改从节点的配置文件:slaveof <masterip> <masterport>
第二步:如果设置了密码,就要设置:masterauth <master-password>
6.3 redis主从特点
读写分离,提高效率
数据热备份,提供多个副本
Redis的Replication的特点和缺点:
主节点故障,集群则无法进行工作,可用性比较低,从节点升主节点需要人工手动干预
单点容易造成性能低下
主节点的存储能力受到限制
主节点的写受到限制(只有一个主节点)
全量同步可能会造成毫秒或者秒级的卡顿现象
单点问题压力大,故障之后无法主动切换需要人为操作。即使再加redis也是 一主多从, 主节点一旦挂掉,此时无法正常写操作。
哨兵就是一个监控平台,redis中自带哨兵机制。能实现主从切换。例如 一主两从, 如果主节点宕机,哨兵会重新选举新的主节点。
七 Redis哨兵模式
7.1 什么是哨兵
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sVD761On-1666013686046)(…/…/课件/144/框架/redis/assets/image-20201229154657215.png)]
7.2 哨兵的作用
A Master状态检测
B 如果Master异常,则会进行Master-Slave切换,将其中一个Slave作为Master,将之前的Master作为Slave。
C Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
7.3 哨兵的流程
1)每个Sentinel(哨兵也可以搭建集群)以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个PING命令。
2)如果一个实例(instance)距离最后一次有效回复PING命令的时间超过 own-after-milliseconds 选项所指定的值,则这个实例会被Sentinel标记为主观下线。
3)如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
4)当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态,则Master会被标记为客观下线。
5)在一般情况下,每个Sentinel 会以每10秒一次的频率向它已知的所有Master,Slave发送 INFO 命令。
6)当Master被Sentinel标记为客观下线时,Sentinel 向下线的 Master 的所有Slave发送 INFO命令的频率会从10秒一次改为每秒一次。
7)若没有足够数量的Sentinel同意Master已经下线,Master的客观下线状态就会被移除。 若 Master重新向Sentinel 的PING命令返回有效回复,Master的主观下线状态就会被移除。
简单的说****故障切换(failover)*的过程。假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为*主观下线*。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行failover操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为*客观下线****。这样对于客户端而言,一切都是透明的。
https://www.cnblogs.com/kevingrace/p/9004460.html
7.4 redis哨兵搭建
克隆一台redis 搭建一主双从
192.168.239.130:8001 主
192.168.239.131:8003 从
192.168.239.132:8005 从
修改132的redis配置信息: vim /usr/local/redis/bin/redis.conf
:69 bind 192.168.239.162
:92 port 8005
搭建一台sentinel哨兵进程
找到130下的sentinel文件拷贝到bin目录下
cp /home/redis/redis-5.0.9/sentinel.conf /usr/local/redis/bin/
修改我们的sentinel配置文件 :
vim /usr/local/redis/bin/sentinel.conf
:17 protected-mode no 默认为yes 不能进行远程连接所以改为no
:26 daemonize yes 开启守护
:84 sentinel monitor mymaster 192.168.239.160 8001 1
:103 sentinel auth-pass mymaster 123
启动redis一主双从集群
启动哨兵:./redis-sentinel sentinel.conf
通过命令连接每一台redis:./redis-cli -h 192.168.239.161 -p 8003 -c
输入info查看当前主从信息
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.239.161,port=8003,state=online,offset=14269,lag=0
slave1:ip=192.168.239.162,port=8005,state=online,offset=14269,lag=0
测试:干掉主节点shutdown save 通过info 查看新的主节点
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.239.161,port=8003,state=online,offset=32341,lag=0
slave1:ip=192.168.239.160,port=8001,state=online,offset=32341,lag=0
7.5 redis的进化史
redis最开始使用主从模式做集群,若master宕机需要手动配置slave转为master;后来为了高可用提出来哨兵模式,该模式下有一个哨兵监视master和slave,若master宕机可自动将slave转为master,但它也有一个问题,就是不能动态扩充;所以在3.x提出cluster集群模式。
在哨兵模式下,还是一主多从,好处是主挂掉了之后不需要手动配置 哨兵会自动主从切换。但是依然存单 单主压力过大问题。
八 cluster集群模式
8.1 redis集群设计
Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RyNEvQSU-1666013686046)(…/…/课件/144/框架/redis/assets/wps3.jpg)]
其结构特点:
1、所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
2、节点的fail是通过集群中超过半数的节点检测失效时才生效。
3、客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
4、redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
5、Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
| *主机名称* | *IP地址* | *redis版本和角色说明* |
|---|---|---|
| redis130 | 192.168.239.130:8001 | redis 5.0.9(?) |
| redis131 | 192.168.239.131:8003 | redis 5.0.9(?) |
| redis132 | 192.168.239.132:8005 | redis 5.0.9(?) |
| redis130 | 192.168.239.130:8002 | redis 5.0.9(?) |
| redis131 | 192.168.239.131:8004 | redis 5.0.9(?) |
| redis132 | 192.168.239.132:8006 | redis 5.0.9(?) |
8.2 搭建三主三从
Redis130操作:
在redis目录下创建一个文件夹: mkdir /usr/local/redis/conf
在conf中创建8001 8002两个文件夹分别存放不同端口的配置文件
将配置文件拷贝到conf文件夹下: cp /home/redis/redis-5.0.9/redis.conf /usr/local/redis/conf/8001/
进入到8001修改配置文件:vim /usr/local/redis/conf/8001/redis.conf
:69 bind 192.168.239.130 修改ip地址为当前主机的ip地址
:92 port 8001 修改端口号
:136 daemonize yes 守护进程
:158 pidfile /var/run/redis_8001.pid 当前redis运行的进行id
:699 appendonly yes aof日志开启
:832 cluster-enabled yes 开启集群模式
:840 cluster-config-file nodes-8001.conf 集群配置文件
:846 cluster-node-timeout 15000 超时时间
将当前配置文件拷贝到6388文件夹下:cp /usr/local/redis/conf/8001/redis.conf /usr/local/redis/conf/8002/redis.conf
修改8002配置文件 底行模式 : :%s/8001/8002/g
Redis161操作:
在redis目录下创建一个文件夹: mkdir /usr/local/redis/conf
在conf中创建8003 8004两个文件夹分别存放不同端口的配置文件
[root@redis161 conf]# scp 192.168.239.160:/usr/local/redis/conf/8001/redis.conf /usr/local/redis/conf/8003
修改配置文件注意 此时要修改ip地址
Redis162操作:同reids161
scp 192.168.239.160:/usr/local/redis/conf/8001/redis.conf /usr/local/redis/conf/8005
启动所有的redis 我们统一进入到redis目录: cd /usr/local/redis/
./bin/redis-server conf/8001/redis.conf
[root@redis- redis]# ./bin/redis-server conf/8001/redis.conf
1727:C 29 Dec 2020 17:15:01.438 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1727:C 29 Dec 2020 17:15:01.438 # Redis version=5.0.9, bits=64, commit=00000000, modified=0, pid=1727, just started
1727:C 29 Dec 2020 17:15:01.438 # Configuration loaded
[root@redis- redis]# ./bin/redis-server conf/8002/redis.conf
1732:C 29 Dec 2020 17:15:08.104 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1732:C 29 Dec 2020 17:15:08.104 # Redis version=5.0.9, bits=64, commit=00000000, modified=0, pid=1732, just started
1732:C 29 Dec 2020 17:15:08.104 # Configuration loaded
启动redis集群配置,在任意机器中输入
./redis-cli --cluster create 192.168.150.130:8001 192.168.150.130:8002 192.168.150.131:8003 192.168.150.131:8004 192.168.150.132:8005 192.168.150.132:8006 --cluster-replicas 1
注意 -cluster-replicas 1 代表副本的数量 1 六台机器 每个人有一个副本 就是三主三从 如果六台机器 每个人有两个副本 就是 两主四从
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.239.161:8004 to 192.168.239.160:8001
Adding replica 192.168.239.162:8006 to 192.168.239.161:8003
Adding replica 192.168.239.160:8002 to 192.168.239.162:8005
M: 6a79309d782c21aa06adfc9bf374462b090ae13f 192.168.239.160:8001
slots:[0-5460] (5461 slots) master
S: 69bce9ba42c959847cf864e69c088cc557fe0a96 192.168.239.160:8002
replicates ddfd8fe75b195a3508e76ffebd9a39ab8e597b13
M: 3de6074a2f5f512b22be96dfc59b6efcfd184107 192.168.239.161:8003
slots:[5461-10922] (5462 slots) master
S: 39cd007836652c2b8f816f4dcfd146336082e56a 192.168.239.161:8004
replicates 6a79309d782c21aa06adfc9bf374462b090ae13f
M: ddfd8fe75b195a3508e76ffebd9a39ab8e597b13 192.168.239.162:8005
slots:[10923-16383] (5461 slots) master
S: ece09c5682cf47edd28315f6bafb99b9f26df4d4 192.168.239.162:8006
replicates 3de6074a2f5f512b22be96dfc59b6efcfd184107
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
....
>>> Performing Cluster Check (using node 192.168.239.160:8001)
M: 6a79309d782c21aa06adfc9bf374462b090ae13f 192.168.239.160:8001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: ddfd8fe75b195a3508e76ffebd9a39ab8e597b13 192.168.239.162:8005
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 69bce9ba42c959847cf864e69c088cc557fe0a96 192.168.239.160:8002
slots: (0 slots) slave
replicates ddfd8fe75b195a3508e76ffebd9a39ab8e597b13
M: 3de6074a2f5f512b22be96dfc59b6efcfd184107 192.168.239.161:8003
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: ece09c5682cf47edd28315f6bafb99b9f26df4d4 192.168.239.162:8006
slots: (0 slots) slave
replicates 3de6074a2f5f512b22be96dfc59b6efcfd184107
S: 39cd007836652c2b8f816f4dcfd146336082e56a 192.168.239.161:8004
slots: (0 slots) slave
replicates 6a79309d782c21aa06adfc9bf374462b090ae13f
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
连接其中一个节点:./bin/redis-cli -h 192.168.239.130 -p 8001 -c
查看节点信息:CLUSTER NODES
查看节点运行信息:CLUSTER INFO
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7kkaYABJ-1666013686047)(…/…/课件/144/框架/redis/assets/image-20201229172536566.png)]
1 主从模式: 读写分离 提高效率 缺点 不能高可用
2 哨兵+主从模式: 主从 读写分离 提高效率 哨兵负责主单点故障 缺点 单主压力过大
3 集群模式: 读写分离 提高效率 将主分到16384槽 缺点 一组如果集体挂掉 此时少槽
九 Redis分布式锁专题
9.1 为什么要是用分布式锁
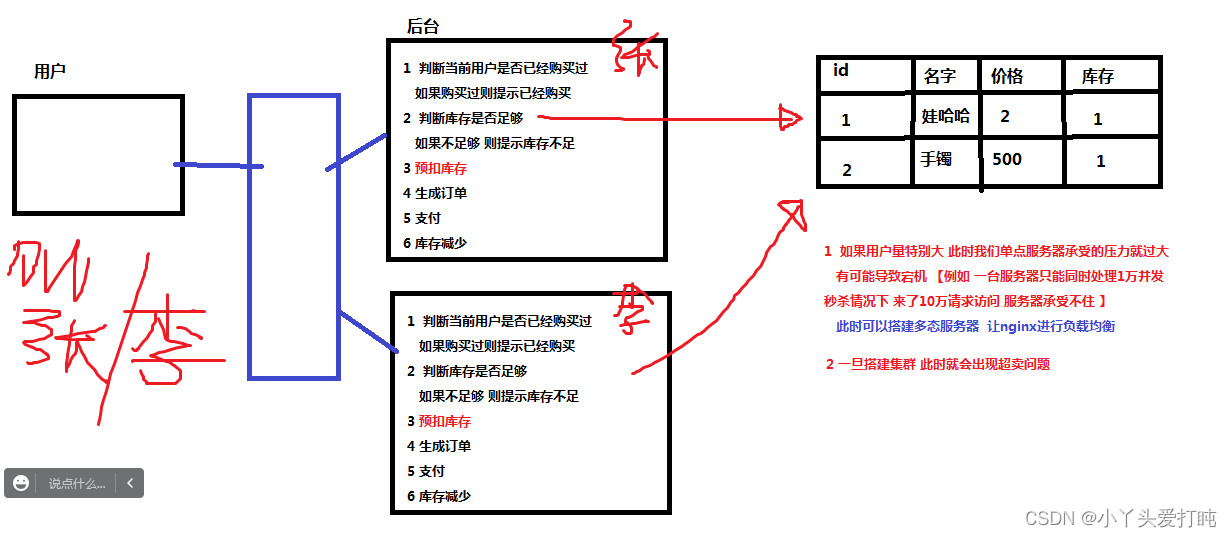
为了解决分布式集群项目 对同一资源 的竞争问题。例如: 秒杀减少库存 就要使用分布式锁 避免超卖现象
在分布式系统中,由于redis分布式锁相对于更简单和高效,成为了分布式锁的首先,被我们用到了很多实际业务场景当中。但不是说用了redis分布式锁,就可以高枕无忧了,如果没有用好或者用对,也会引来一些意想不到的问题。
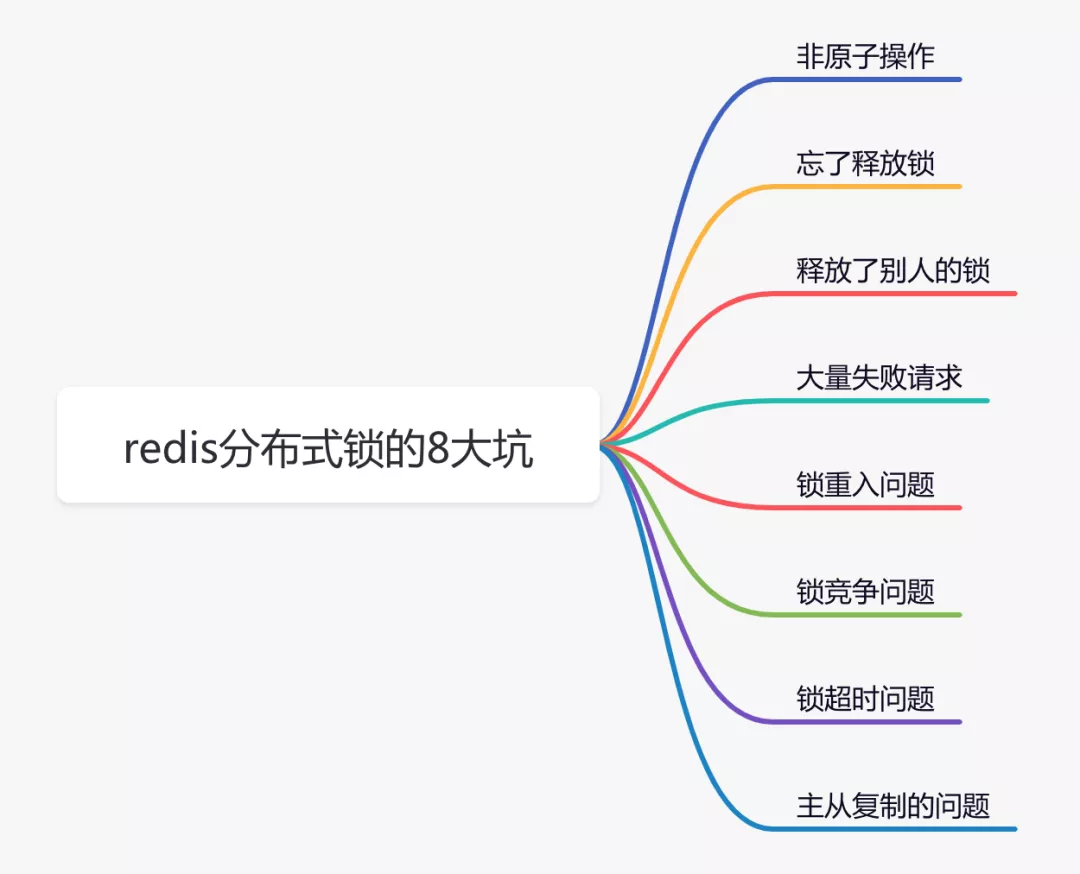
1 非原子操作
使用redis的分布式锁,我们首先想到的可能是setNX命令。
if (jedis.setnx(lockKey, val) == 1) {
jedis.expire(lockKey, timeout);
}
容易,三下五除二,我们就可以把代码写好。
这段代码确实可以加锁成功,但你有没有发现什么问题?
加锁操作和后面的设置超时时间是分开的,并非原子操作。
假如加锁成功,但是设置超时时间失败了,该lockKey就变成永不失效。假如在高并发场景中,有大量的lockKey加锁成功了,但不会失效,有可能直接导致redis内存空间不足。
那么,有没有保证原子性的加锁命令呢?
答案是:有,请看下面。
2 忘了释放锁
上面说到使用setNx命令加锁操作和设置超时时间是分开的,并非原子操作。
而在redis中还有set命令,该命令可以指定多个参数。
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
其中:
- lockKey:锁的标识
- requestId:请求id
- NX:只在键不存在时,才对键进行设置操作。
- PX:设置键的过期时间为 millisecond 毫秒。
- expireTime:过期时间
set命令是原子操作,加锁和设置超时时间,一个命令就能轻松搞定。
nice
使用set命令加锁,表面上看起来没有问题。但如果仔细想想,加锁之后,每次都要达到了超时时间才释放锁,会不会有点不合理?
加锁后,如果不及时释放锁,会有很多问题。
分布式锁更合理的用法是:
- 手动加锁
- 业务操作
- 手动释放锁
- 如果手动释放锁失败了,则达到超时时间,redis会自动释放锁。
大致流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ak6XW9zX-1666013686050)(https://p26.toutiaoimg.com/origin/tos-cn-i-qvj2lq49k0/e0dd3fde16bf4f99b5075de15d6340f0?from=pc)]
那么问题来了,如何释放锁呢?
伪代码如下:
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
} finally {
unlock(lockKey);
}
需要捕获业务代码的异常,然后在finally中释放锁。换句话说就是:无论代码执行成功或失败了,都需要释放锁。
此时,有些朋友可能会问:假如刚好在释放锁的时候,系统被重启了,或者网络断线了,或者机房断点了,不也会导致释放锁失败?
这是一个好问题,因为这种小概率问题确实存在。
但还记得前面我们给锁设置过超时时间吗?即使出现异常情况造成释放锁失败,但到了我们设定的超时时间,锁还是会被redis自动释放。
但只在finally中释放锁,就够了吗?
3 释放了别人的锁
做人要厚道,先回答上面的问题:只在finally中释放锁,当然是不够的,因为释放锁的姿势,还是不对。
哪里不对?
答:在多线程场景中,可能会出现释放了别人的锁的情况。
有些朋友可能会反驳:假设在多线程场景中,线程A获取到了锁,但如果线程A没有释放锁,此时,线程B是获取不到锁的,何来释放了别人锁之说?
答:假如线程A和线程B,都使用lockKey加锁。线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间。这时候,redis会自动释放lockKey锁。此时,线程B就能给lockKey加锁成功了,接下来执行它的业务操作。恰好这个时候,线程A执行完了业务功能,接下来,在finally方法中释放了锁lockKey。这不就出问题了,线程B的锁,被线程A释放了。
我想这个时候,线程B肯定哭晕在厕所里,并且嘴里还振振有词。
那么,如何解决这个问题呢?
不知道你们注意到没?在使用set命令加锁时,除了使用lockKey锁标识,还多设置了一个参数:requestId,为什么要需要记录requestId呢?
答:requestId是在释放锁的时候用的。
伪代码如下:
if (jedis.get(lockKey).equals(requestId)) {
jedis.del(lockKey);
return true;
}
return false;
在释放锁的时候,先获取到该锁的值(之前设置值就是requestId),然后判断跟之前设置的值是否相同,如果相同才允许删除锁,返回成功。如果不同,则直接返回失败。
换句话说就是:自己只能释放自己加的锁,不允许释放别人加的锁。
这里为什么要用requestId,用userId不行吗?
答:如果用userId的话,对于请求来说并不唯一,多个不同的请求,可能使用同一个userId。而requestId是全局唯一的,不存在加锁和释放锁乱掉的情况。
此外,使用lua脚本,也能解决释放了别人的锁的问题:
if redis.call('get', KEYS[1]) == ARGV[1] then
return redis.call('del', KEYS[1])
else
return 0
end
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
jedis.set("inventory", "15");
String luaScript = " local count = redis.call('get', KEYS[1]) " +
" local currentCount = tonumber(count) " +
" local wantCount = tonumber(ARGV[1]) " +
" if currentCount >= wantCount then " +
" redis.call('set', KEYS[1], currentCount-wantCount )" +
" return 1 " +
" end " +
" return 0 ";
Object result = jedis.eval(luaScript, Arrays.asList("inventory") , Arrays.asList("10") );
if(result == 1){
}
lua脚本能保证查询锁是否存在和删除锁是原子操作,用它来释放锁效果更好一些。
说到lua脚本,其实加锁操作也建议使用lua脚本:
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
这是redisson框架的加锁代码,写的不错,大家可以借鉴一下。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.16.8</version>
</dependency>
7 锁超时问题
我在前面提到过,如果线程A加锁成功了,但是由于业务功能耗时时间很长,超过了设置的超时时间,这时候redis会自动释放线程A加的锁。
有些朋友可能会说:到了超时时间,锁被释放了就释放了呗,对功能又没啥影响。
答:错,错,错。对功能其实有影响。
通常我们加锁的目的是:为了防止访问临界资源时,出现数据异常的情况。比如:线程A在修改数据C的值,线程B也在修改数据C的值,如果不做控制,在并发情况下,数据C的值会出问题。
为了保证某个方法,或者段代码的互斥性,即如果线程A执行了某段代码,是不允许其他线程在某一时刻同时执行的,我们可以用synchronized关键字加锁。
但这种锁有很大的局限性,只能保证单个节点的互斥性。如果需要在多个节点中保持互斥性,就需要用redis分布式锁。
做了这么多铺垫,现在回到正题。
假设线程A加redis分布式锁的代码,包含代码1和代码2两段代码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6mDSoBc0-1666013686051)(https://p26.toutiaoimg.com/origin/tos-cn-i-qvj2lq49k0/583bd0df025d42f6a0a048efa055093a?from=pc)]
由于该线程要执行的业务操作非常耗时,程序在执行完代码1的时,已经到了设置的超时时间,redis自动释放了锁。而代码2还没来得及执行。
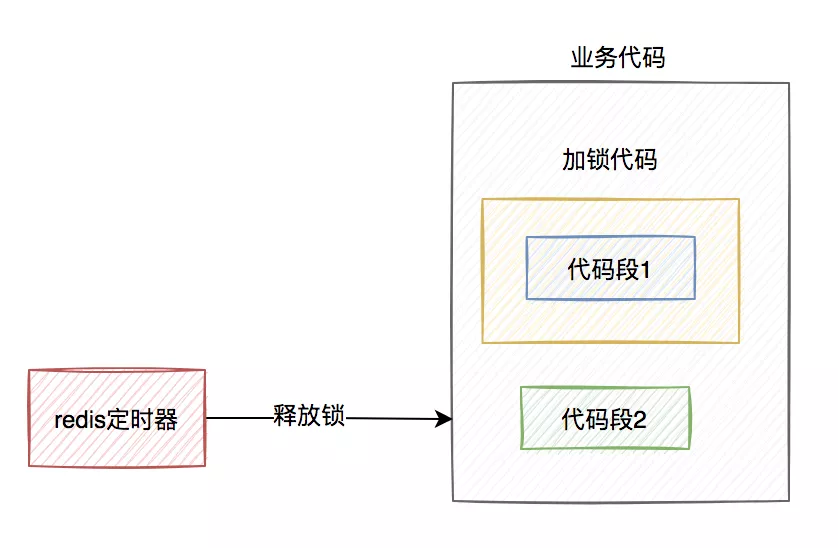
此时,代码2相当于裸奔的状态,无法保证互斥性。假如它里面访问了临界资源,并且其他线程也访问了该资源,可能就会出现数据异常的情况。(PS:我说的访问临界资源,不单单指读取,还包含写入)
那么,如何解决这个问题呢?
答:如果达到了超时时间,但业务代码还没执行完,需要给锁自动续期。
我们可以使用TimerTask类,来实现自动续期的功能:
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//自动续期逻辑
}
}, 10000, TimeUnit.MILLISECONDS);
获取锁之后,自动开启一个定时任务,每隔10秒钟,自动刷新一次过期时间。这种机制在redisson框架中,有个比较霸气的名字:watch dog,即传说中的看门狗。
当然自动续期功能,我们还是优先推荐使用lua脚本实现,比如:
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end;
return 0;
需要注意的地方是:在实现自动续期功能时,还需要设置一个总的过期时间,可以跟redisson保持一致,设置成30秒。如果业务代码到了这个总的过期时间,还没有执行完,就不再自动续期了。
自动续期的功能是获取锁之后开启一个定时任务,每隔10秒判断一下锁是否存在,如果存在,则刷新过期时间。如果续期3次,也就是30秒之后,业务方法还是没有执行完,就不再续期了。
4 大量失败请求–自旋锁
上面的加锁方法看起来好像没有问题,但如果你仔细想想,如果有1万的请求同时去竞争那把锁,可能只有一个请求是成功的,其余的9999个请求都会失败。
在秒杀场景下,会有什么问题?
答:每1万个请求,有1个成功。再1万个请求,有1个成功。如此下去,直到库存不足。这就变成均匀分布的秒杀了,跟我们想象中的不一样。
如何解决这个问题呢?
此外,还有一种场景:
比如,有两个线程同时上传文件到sftp,上传文件前先要创建目录。假设两个线程需要创建的目录名都是当天的日期,比如:20210920,如果不做任何控制,直接并发的创建目录,第二个线程必然会失败。
这时候有些朋友可能会说:这还不容易,加一个redis分布式锁就能解决问题了,此外再判断一下,如果目录已经存在就不创建,只有目录不存在才需要创建。
伪代码如下:
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
一切看似美好,但经不起仔细推敲。
来自灵魂的一问:第二个请求如果加锁失败了,接下来,是返回失败,还是返回成功呢?
主要流程图如下:
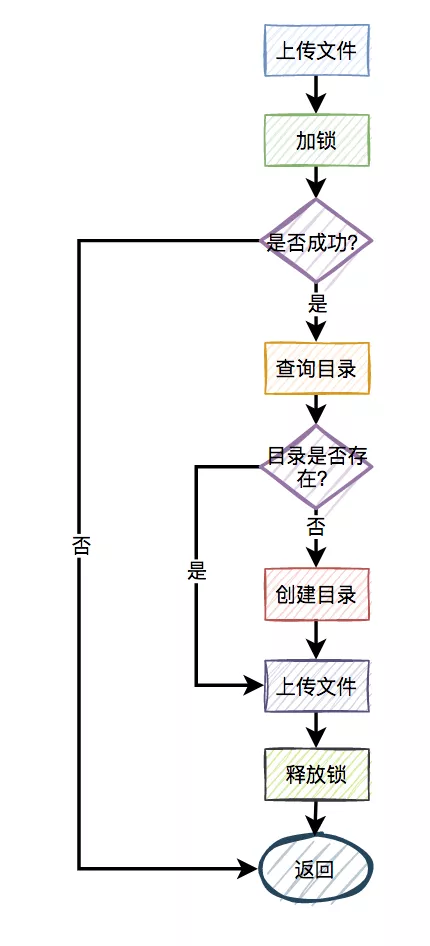
显然第二个请求,肯定是不能返回失败的,如果返回失败了,这个问题还是没有被解决。如果文件还没有上传成功,直接返回成功会有更大的问题。头疼,到底该如何解决呢?
答:使用自旋锁。
try {
Long start = System.currentTimeMillis();
while(true) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(!exists(path)) {
mkdir(path);
}
return true;
}
long time = System.currentTimeMillis() - start;
if (time>=timeout) {
return false;
}
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} finally{
unlock(lockKey,requestId);
}
return false;
在规定的时间,比如500毫秒内,自旋不断尝试加锁(说白了,就是在死循环中,不断尝试加锁),如果成功则直接返回。如果失败,则休眠50毫秒,再发起新一轮的尝试。如果到了超时时间,还未加锁成功,则直接返回失败。
5 锁重入问题–可重入锁
我们都知道redis分布式锁是互斥的。假如我们对某个key加锁了,如果该key对应的锁还没失效,再用相同key去加锁,大概率会失败。
没错,大部分场景是没问题的。
为什么说是大部分场景呢?
因为还有这样的场景:
假设在某个请求中,需要获取一颗满足条件的菜单树或者分类树。我们以菜单为例,这就需要在接口中从根节点开始,递归遍历出所有满足条件的子节点,然后组装成一颗菜单树。
需要注意的是菜单不是一成不变的,在后台系统中运营同学可以动态添加、修改和删除菜单。为了保证在并发的情况下,每次都可能获取最新的数据,这里可以加redis分布式锁。
加redis分布式锁的思路是对的。但接下来问题来了,在递归方法中递归遍历多次,每次都是加的同一把锁。递归第一层当然是可以加锁成功的,但递归第二层、第三层…第N层,不就会加锁失败了?
递归方法中加锁的伪代码如下:
private int expireTime = 1000;
public void fun(int level,String lockKey,String requestId){
try{
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
if(level<=10){
this.fun(++level,lockKey,requestId);
} else {
return;
}
}
return;
} finally {
unlock(lockKey,requestId);
}
}
如果你直接这么用,看起来好像没有问题。但最终执行程序之后发现,等待你的结果只有一个:出现异常。
因为从根节点开始,第一层递归加锁成功,还没释放锁,就直接进入第二层递归。因为锁名为lockKey,并且值为requestId的锁已经存在,所以第二层递归大概率会加锁失败,然后返回到第一层。第一层接下来正常释放锁,然后整个递归方法直接返回了。
这下子,大家知道出现什么问题了吧?
没错,递归方法其实只执行了第一层递归就返回了,其他层递归由于加锁失败,根本没法执行。
那么这个问题该如何解决呢?
答:使用可重入锁。
我们以redisson框架为例,它的内部实现了可重入锁的功能。
古时候有句话说得好:为人不识陈近南,便称英雄也枉然。
我说:分布式锁不识redisson,便称好锁也枉然。哈哈哈,只是自娱自乐一下。
由此可见,redisson在redis分布式锁中的江湖地位很高。
伪代码如下:
private int expireTime = 1000;
public void run(String lockKey) {
RLock lock = redisson.getLock(lockKey);
this.fun(lock,1);
}
public void fun(RLock lock,int level){
try{
lock.lock(5, TimeUnit.SECONDS);
if(level<=10){
this.fun(lock,++level);
} else {
return;
}
} finally {
lock.unlock();
}
}
上面的代码也许并不完美,这里只是给了一个大致的思路,如果大家有这方面需求的话,以上代码仅供参考。
接下来,聊聊redisson可重入锁的实现原理。
加锁主要是通过以下脚本实现的:
if (redis.call('exists', KEYS[1]) == 0)
then
redis.call('hset', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
return redis.call('pttl', KEYS[1]);
其中:
- KEYS[1]:锁名
- ARGV[1]:过期时间
- ARGV[2]:uuid + “:” + threadId,可认为是requestId
- 先判断如果锁名不存在,则加锁。
- 接下来,判断如果锁名和requestId值都存在,则使用hincrby命令给该锁名和requestId值计数,每次都加1。注意一下,这里就是重入锁的关键,锁重入一次值就加1。
- 如果锁名存在,但值不是requestId,则返回过期时间。
释放锁主要是通过以下脚本实现的:
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0)
then
return nil
end
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
if (counter > 0)
then
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil
- 先判断如果锁名和requestId值不存在,则直接返回。
- 如果锁名和requestId值存在,则重入锁减1。
- 如果减1后,重入锁的value值还大于0,说明还有引用,则重试设置过期时间。
- 如果减1后,重入锁的value值还等于0,则可以删除锁,然后发消息通知等待线程抢锁。
再次强调一下,如果你们系统可以容忍数据暂时不一致,有些场景不加锁也行,我在这里只是举个例子,本节内容并不适用于所有场景。
6 锁竞争问题
如果有大量需要写入数据的业务场景,使用普通的redis分布式锁是没有问题的。
但如果有些业务场景,写入的操作比较少,反而有大量读取的操作。这样直接使用普通的redis分布式锁,会不会有点浪费性能?
我们都知道,锁的粒度越粗,多个线程抢锁时竞争就越激烈,造成多个线程锁等待的时间也就越长,性能也就越差。
所以,提升redis分布式锁性能的第一步,就是要把锁的粒度变细。
6.1 读写锁
众所周知,加锁的目的是为了保证,在并发环境中读写数据的安全性,即不会出现数据错误或者不一致的情况。
但在绝大多数实际业务场景中,一般是读数据的频率远远大于写数据。而线程间的并发读操作是并不涉及并发安全问题,我们没有必要给读操作加互斥锁,只要保证读写、写写并发操作上锁是互斥的就行,这样可以提升系统的性能。
我们以redisson框架为例,它内部已经实现了读写锁的功能。
读锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.readLock();
try {
rLock.lock();
//业务操作
} catch (Exception e) {
log.error(e);
} finally {
rLock.unlock();
}
写锁的伪代码如下:
RReadWriteLock readWriteLock = redisson.getReadWriteLock("readWriteLock");
RLock rLock = readWriteLock.writeLock();
try {
rLock.lock();
//业务操作
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
将读锁和写锁分开,最大的好处是提升读操作的性能,因为读和读之间是共享的,不存在互斥性。而我们的实际业务场景中,绝大多数数据操作都是读操作。所以,如果提升了读操作的性能,也就会提升整个锁的性能。
下面总结一个读写锁的特点:
- 读与读是共享的,不互斥
- 读与写互斥
- 写与写互斥
6.2 锁分段
此外,为了减小锁的粒度,比较常见的做法是将大锁:分段。
在java中ConcurrentHashMap,就是将数据分为16段,每一段都有单独的锁,并且处于不同锁段的数据互不干扰,以此来提升锁的性能。
放在实际业务场景中,我们可以这样做:
比如在秒杀扣库存的场景中,现在的库存中有2000个商品,用户可以秒杀。为了防止出现超卖的情况,通常情况下,可以对库存加锁。如果有1W的用户竞争同一把锁,显然系统吞吐量会非常低。
为了提升系统性能,我们可以将库存分段,比如:分为100段,这样每段就有20个商品可以参与秒杀。
在秒杀的过程中,先把用户id获取hash值,然后除以100取模。模为1的用户访问第1段库存,模为2的用户访问第2段库存,模为3的用户访问第3段库存,后面以此类推,到最后模为100的用户访问第100段库存。
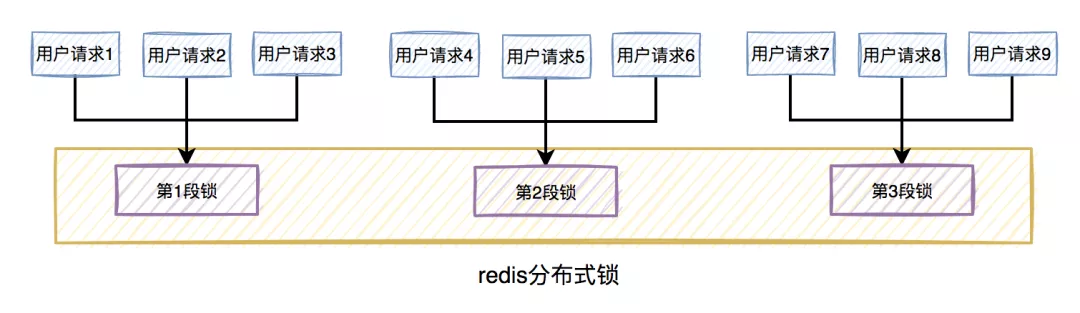
如此一来,在多线程环境中,可以大大的减少锁的冲突。以前多个线程只能同时竞争1把锁,尤其在秒杀的场景中,竞争太激烈了,简直可以用惨绝人寰来形容,其后果是导致绝大数线程在锁等待。现在多个线程同时竞争100把锁,等待的线程变少了,从而系统吞吐量也就提升了。
需要注意的地方是:将锁分段虽说可以提升系统的性能,但它也会让系统的复杂度提升不少。因为它需要引入额外的路由算法,跨段统计等功能。我们在实际业务场景中,需要综合考虑,不是说一定要将锁分段。
8 主从复制的问题
上面花了这么多篇幅介绍的内容,对单个redis实例是没有问题的。
but,如果redis存在多个实例。比如:做了主从,或者使用了哨兵模式,基于redis的分布式锁的功能,就会出现问题。
具体是什么问题?
假设redis现在用的主从模式,1个master节点,3个slave节点。master节点负责写数据,slave节点负责读数据。
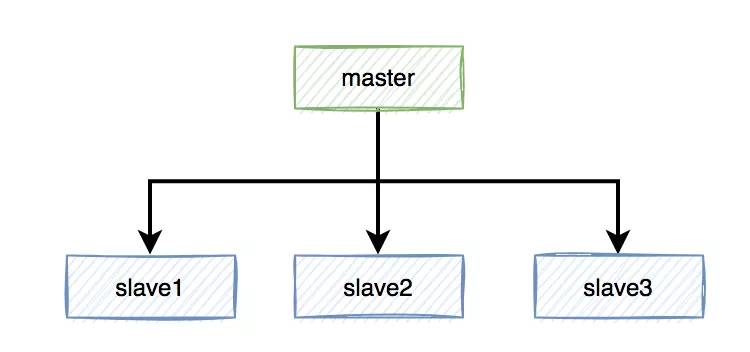
本来是和谐共处,相安无事的。redis加锁操作,都在master上进行,加锁成功后,再异步同步给所有的slave。
突然有一天,master节点由于某些不可逆的原因,挂掉了。
这样需要找一个slave升级为新的master节点,假如slave1被选举出来了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Wb68bW6-1666013686054)(https://p26.toutiaoimg.com/origin/tos-cn-i-qvj2lq49k0/eeff81ead61543a69bca2237ce21ffb0?from=pc)]
如果有个锁A比较悲催,刚加锁成功master就挂了,还没来得及同步到slave1。
这样会导致新master节点中的锁A丢失了。后面,如果有新的线程,使用锁A加锁,依然可以成功,分布式锁失效了。
那么,如何解决这个问题呢?
答:redisson框架为了解决这个问题,提供了一个专门的类:RedissonRedLock,使用了Redlock算法。
RedissonRedLock解决问题的思路如下:
- 需要搭建几套相互独立的redis环境,假如我们在这里搭建了5套。
- 每套环境都有一个redisson node节点。
- 多个redisson node节点组成了RedissonRedLock。
- 环境包含:单机、主从、哨兵和集群模式,可以是一种或者多种混合。
在这里我们以主从为例,架构图如下:
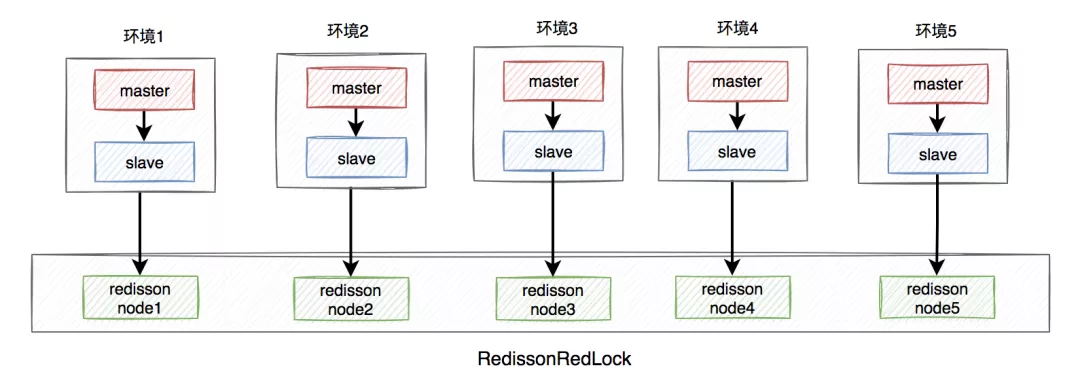
RedissonRedLock加锁过程如下:
- 获取所有的redisson node节点信息,循环向所有的redisson node节点加锁,假设节点数为N,例子中N等于5。
- 如果在N个节点当中,有N/2 + 1个节点加锁成功了,那么整个RedissonRedLock加锁是成功的。
- 如果在N个节点当中,小于N/2 + 1个节点加锁成功,那么整个RedissonRedLock加锁是失败的。
- 如果中途发现各个节点加锁的总耗时,大于等于设置的最大等待时间,则直接返回失败。
从上面可以看出,使用Redlock算法,确实能解决多实例场景中,假如master节点挂了,导致分布式锁失效的问题。
但也引出了一些新问题,比如:
- 需要额外搭建多套环境,申请更多的资源,需要评估一下成本和性价比。
- 如果有N个redisson node节点,需要加锁N次,最少也需要加锁N/2+1次,才知道redlock加锁是否成功。显然,增加了额外的时间成本,有点得不偿失。
由此可见,在实际业务场景,尤其是高并发业务中,RedissonRedLock其实使用的并不多。
在分布式环境中,CAP是绕不过去的。
CAP指的是在一个分布式系统中:
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)
这三个要素最多只能同时实现两点,不可能三者兼顾。
如果你的实际业务场景,更需要的是保证数据一致性。那么请使用CP类型的分布式锁,比如:zookeeper,它是基于磁盘的,性能可能没那么好,但数据一般不会丢。
如果你的实际业务场景,更需要的是保证数据高可用性。那么请使用AP类型的分布式锁,比如:redis,它是基于内存的,性能比较好,但有丢失数据的风险。
其实,在我们绝大多数分布式业务场景中,使用redis分布式锁就够了,真的别太较真。因为数据不一致问题,可以通过最终一致性方案解决。但如果系统不可用了,对用户来说是暴击一万点伤害。