Kafka作为存储、性能兼备的消息队列,适用场景很多,伸缩性也很强。如何调节kafka的配置参数,以及设计专题、分区的数量、物理位置,很大程度上影响到整个架构的成败。很多文章是站在数据中心的角度来谈kafka的配置,而对于小团队,往往只希望把Kafka作为一个跨进程、可追溯的隔离器来使用,取代繁琐的文件或者自定义TCP/UDP接口。此时,单独讨论这种场景就显得有必要了。
- 少量的物理服务器,甚至只有1台。
- 单股光纤甚至千兆网。
本文先试图通过调优,来允许kafka队列在有限资源下发挥更大作用;而后,介绍一种折中的架构设计,引入车联网的eCAL解决问题。
1. 磁盘与网络是最重要的两个瓶颈
无论是集群还是单机,磁盘与网络都是最重要的瓶颈。不管Kafka用了0拷贝等各种加速策略,底层的物理设备都会影响到架构的可用性。
1.1 固态硬盘与机械盘阵
根据我的测试,在机械硬盘情况下,若并发读写的会话足够多,机械硬盘照样会遇到并发陷阱——由缓存命中失败导致的频繁机械磁头巡道。这种情况在多个大流量topic同时读写的情况下尤其显著,特别是在消费的数据时间上间隔较远的时刻下。
典型的现象就是写入延迟很大,磁盘占用100%。明明网络带宽没用完,但是写不进去了。遇到这种情况,需要仔细分析,对症下药。
- 查看 server.properties文件,关注参数“num.io.threads”
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
如果没有修改过这个值,应该是8. 建议把这个值缩小到2,观察一下情况有无好转。对于机械硬盘来说,限制并发读写的会话,会提高一部分效率。
- 若在虚拟机中使用kafka,打开“使用主机缓存”选项,可能有助于提高吞吐率。
- 使用SSD
如果上述情况都无法缓解磁盘的延迟问题,果断上SSD。在大量并发随机读写的情况下,一个机械盘阵要比一块16TB的企业级SSD 慢很多。
1.2 网络带宽
kafka是一种TCP协议的消息队列。这种消息队列的出口带宽与消费者组的个数是 xN的关系。如果1个专题-分区的入口带宽为10MBps,开100个消费者组,则是 1000MBps, 基本就必须要上光纤解决问题了。所以,要非常重视消费者组的数目。当必须要维持消费者组的数目时,解决问题的策略有以下几条。
- 启用 zstd压缩
近期版本的kafka支持zstd压缩,比gzip的CPU开销小。可以在生产者方启动 zstd压缩,一般能够达到超过2倍的压缩率
if (rd_kafka_conf_set(conf, "compression.type", "zstd", errstr,
sizeof(errstr)) != RD_KAFKA_CONF_OK) {
cbprintf( "%s\n", errstr);
rd_kafka_conf_destroy(conf);
return false;
}
if (rd_kafka_conf_set(conf, "compression.level", "9", errstr,
sizeof(errstr)) != RD_KAFKA_CONF_OK) {
cbprintf( "%s\n", errstr);
rd_kafka_conf_destroy(conf);
return false;
}
但此时要注意的是,compression.level 会显著提高生产者的CPU占用。如果来不及,需要降低compression.level。
- 双网卡分流
使用2张网卡,为1个broker提供物理传输,能够进行分流。broker可以在2个IP地址监听,这样,物理上把消费者的流量引导到不同的网卡上。
2. 并行计算策略的调整
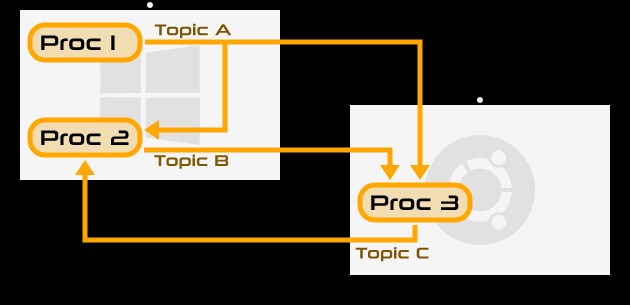
对于捉襟见肘的计算存储资源而言,可能需要更为底层手段控制流量和磁盘的开销。对于TCP承载的消息队列,消费数据要聚焦。尤其要避免浪费带宽。比如,3个算法消费者组共视一份数据,则需要的流量是x3的。如果是针对1份数据的3种处理,必须放在3个消费者组里(1个组里的不同消费者看到的数据不同,不满足需求),则建议使用1个消费者+3个处理子模块的方式,而不是都直接从kafka消费数据。这相当于使用一个消费者进行第二层分包。这种区别如下图所示:
上图中,模拟的是双分区的集群。算法1、算法2、算法3都是消费者,直接连接在集群。因此,他们总共会消费3次完整的数据。如果我们在算法与集群之间,添加一个管理者,统一消费数据,则可以只消费1份数据量,如下图所示:
3.同时使用2种消息队列
在上图中,我们引入了管理者来降低吞吐量。但这带来了显著的复杂度,有坑。有没有一种节省带宽和磁盘的局部消息队列可以完成这个功能呢?
我们可以使用一种局部的消息队列,或者一个本地kafka实例、一个本地的数据库来完成这个功能。一个典型的高速局部消息队列就是 eCAL。
https://eclipse-ecal.github.io/ecal/
eCAL是用于可靠直连局域网的跨平台M2M消息队列,初衷是在车载智能电路上实现稳定可靠的传感器交互。值得注意的是,这种交互使用的是UDP组播协议。这种协议的好处是接收本身就是1对多的。只要确保局域网环境的稳定,UDP也基本不会丢包。
如此一来,消费者管理算法模块的时候,就可以选择把数据从Kafka下载到本地交换机,而后用eCAL组播给算法模块。
需要注意的问题是确保 连续性。需要有计数器检验数据的连续性,以防止UDP的丢包。
====
有了gpt,我已经不太想继续写Blog了。发现我以前踩的坑,一问就全解决了,不需要再用Blog来固化知识了。