本文将详细讲解如何自制数据集,并复习上一篇博客中训练部署的相关步骤,希望大家能熟练运用,真正掌握 数据及制作-训练-检测推断 这一基本流程。
数据集制作
建立文件夹
新建一个结构如下的文件夹
dataset
├── images
│ ├── train(用来放训练集图片)
│ ├── val(用来放验证集张图片)
│
├── labels
│ ├── train(用来放训练集图片的标签)
│ ├── val(用来放验证集图片的标签)
│
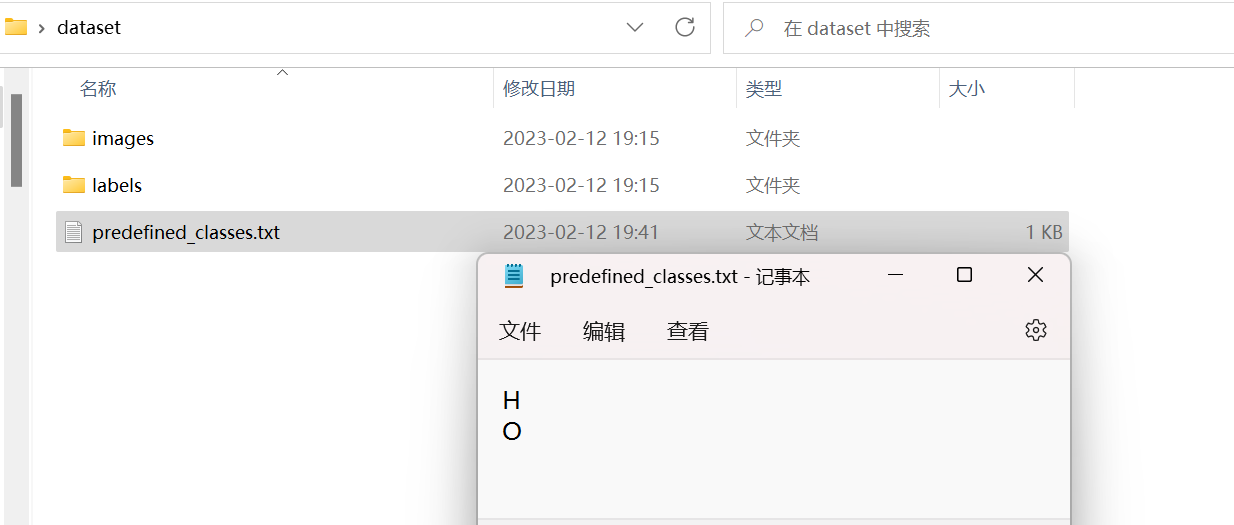
│ ├── predefined_classes.txt 定义自己要标注的所有类别图像采集
可以直接拍摄图片,也可以用无人机拍一段视频,用视频切片代码切成图片集。这里为了演示方便,我直接用电脑摄像头拍了一些照片(别学我,实际项目中数据集采集是非常关键的步骤,会直接影响最终目标检测效果)。然后将图片全部放到dataset/images/train目录下(图片名称随意)。
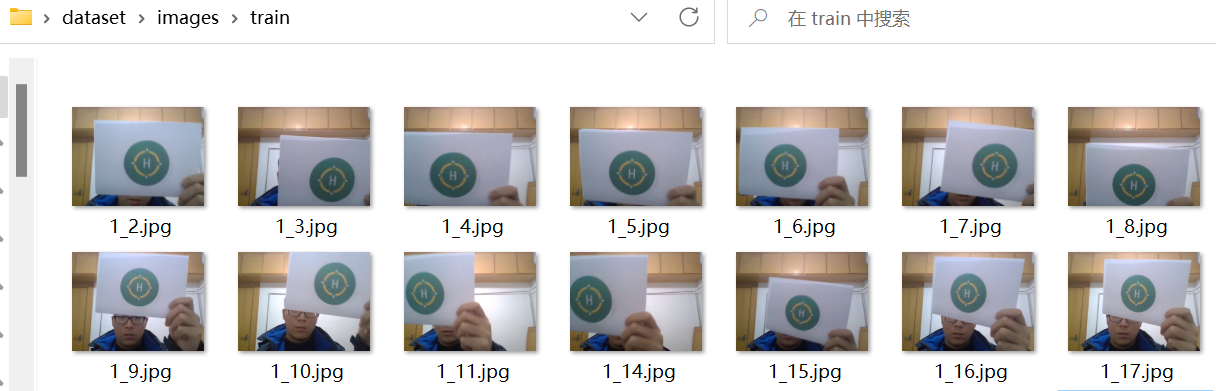
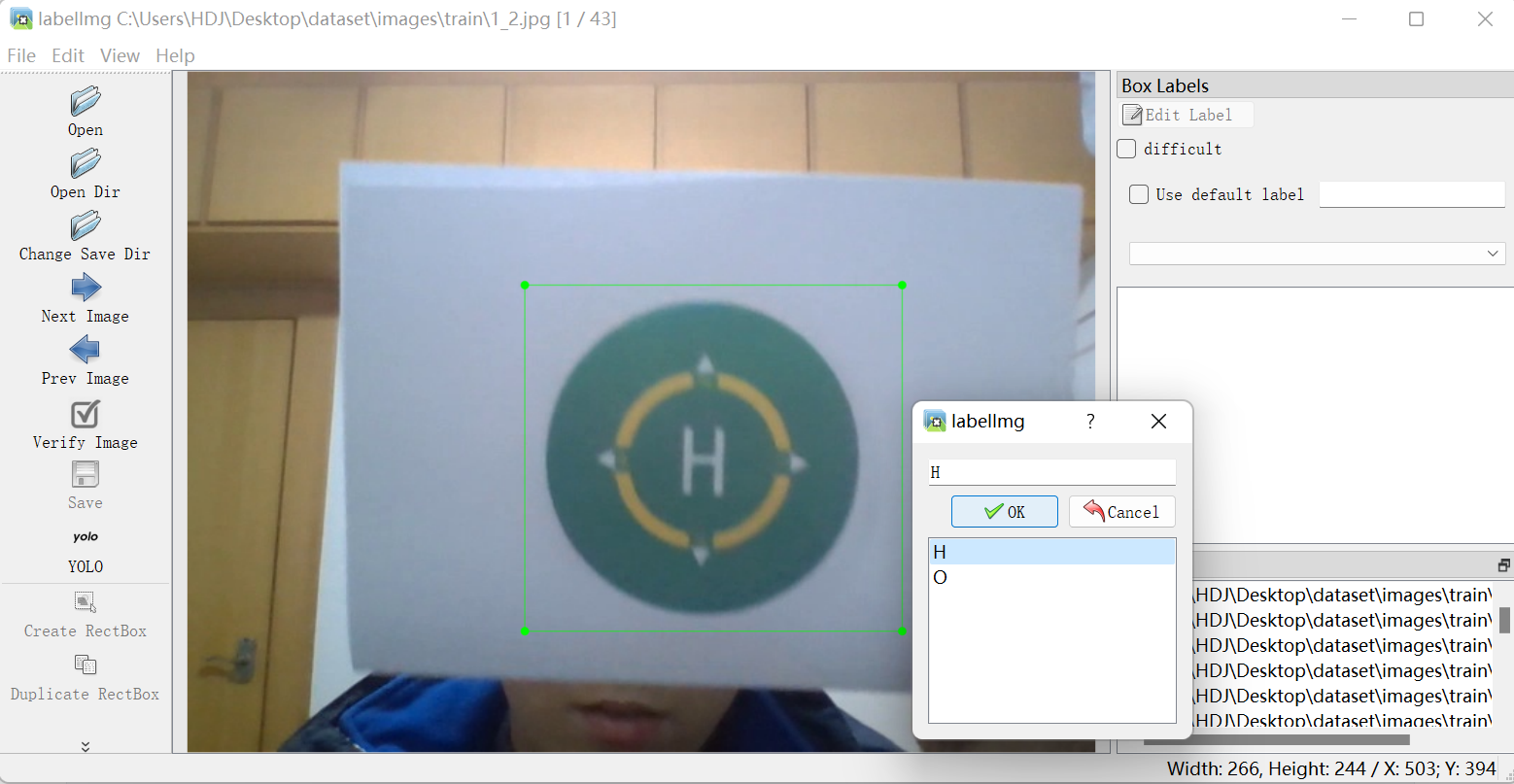
我要识别的标志有两个,分别命名为H、O,因此在predefined_classes.txt中填入H、O(中间用换行),如果有其他类别也要像这样每个类别占一行,这样标注的时候会很方便。

左边的命名为H,右边的命名为O
使用labeling工具进行标注(存储为yolo格式)
在windows终端(快捷键:win+R,在其中输入cmd打开)中安装labeling工具
pip install labelimg -ihttps://pypi.tuna.tsinghua.edu.cn/simple安装完成后终端进入dataset路径(注意,路径改成自己的)
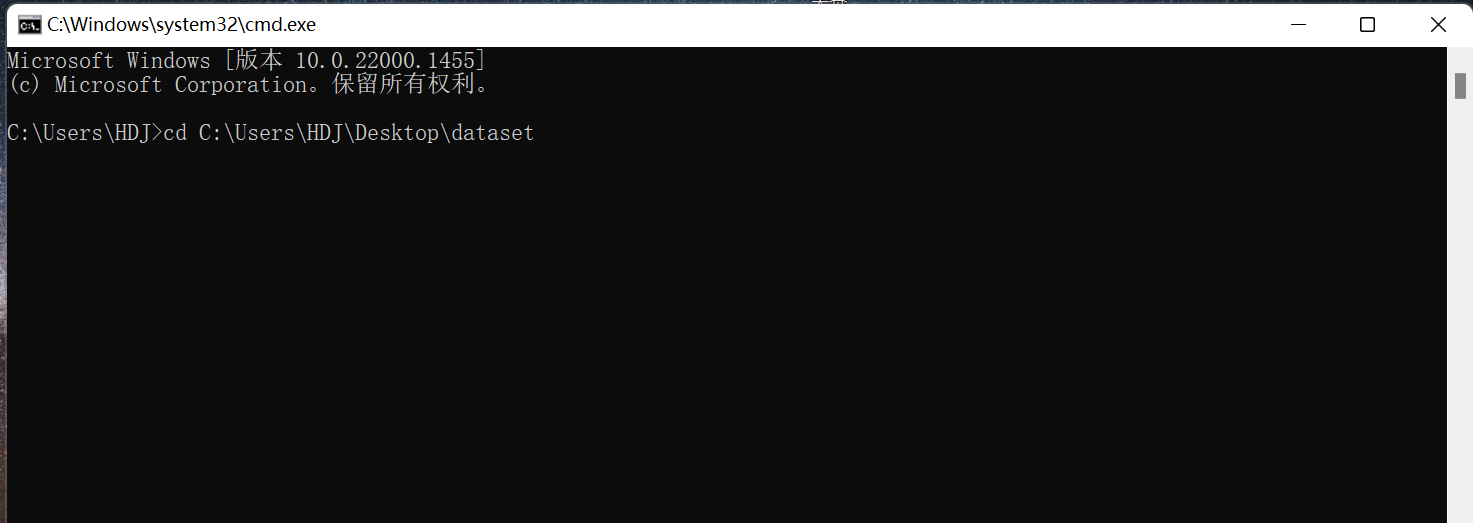
cd C:\Users\HDJ\Desktop\dataset输入labelimg images predefined_classes.txt 打开标记软件
labelimg images predefined_classes.txt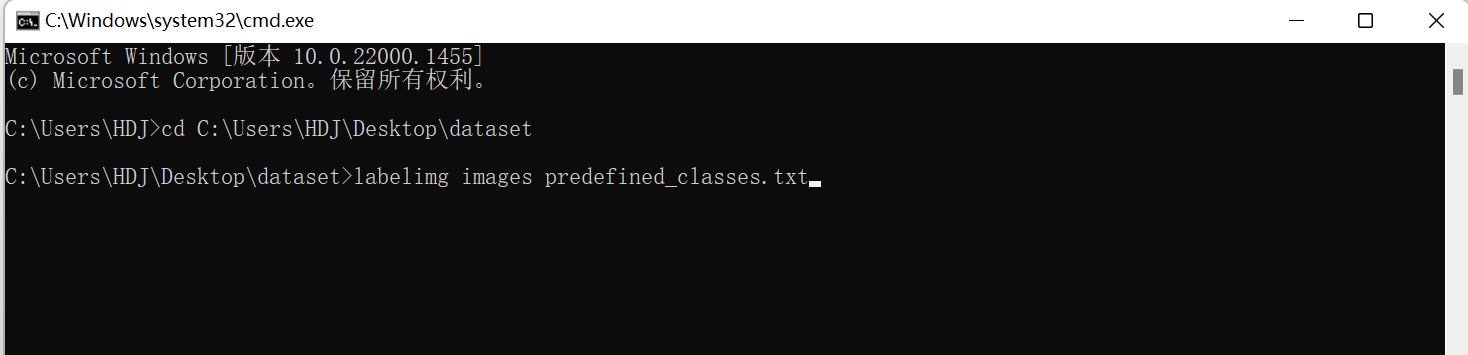
打开后会出现下面界面(没有出现图片也不要紧,按照下面步骤设置完成后就有了)

Open Dir选择路径dataset\images\train
Change Save Dir 选择路径 dataset\labels\train
第三条红线必须选YOLO格式(否则后面还要调回YOLO格式)
在最上方菜单栏的view选项下,选择下面几个模式(方便标注)
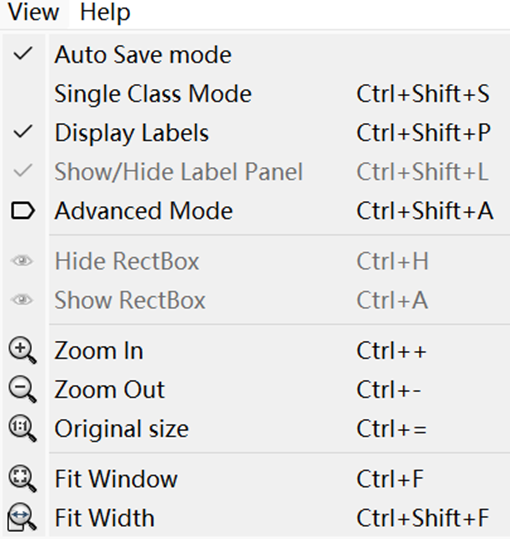
开始进行标注
操作:W(调出标注十字架)—鼠标框住要识别物体—选对应标签—D(切换到下一张图片)
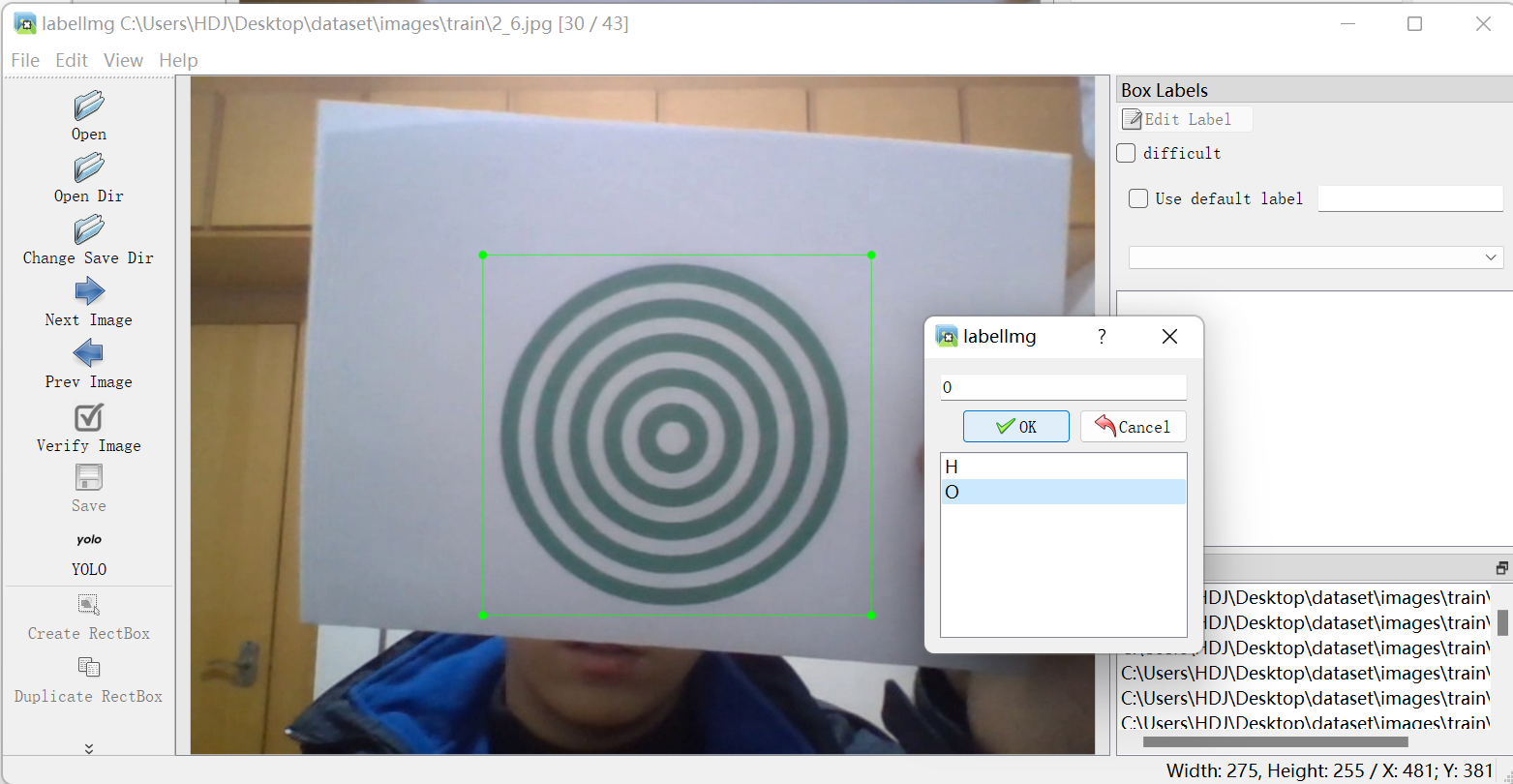
循环操作直到完成所有图片标注,这个时候进入dataset\labels\train目录可以看到所有图片对应的标签
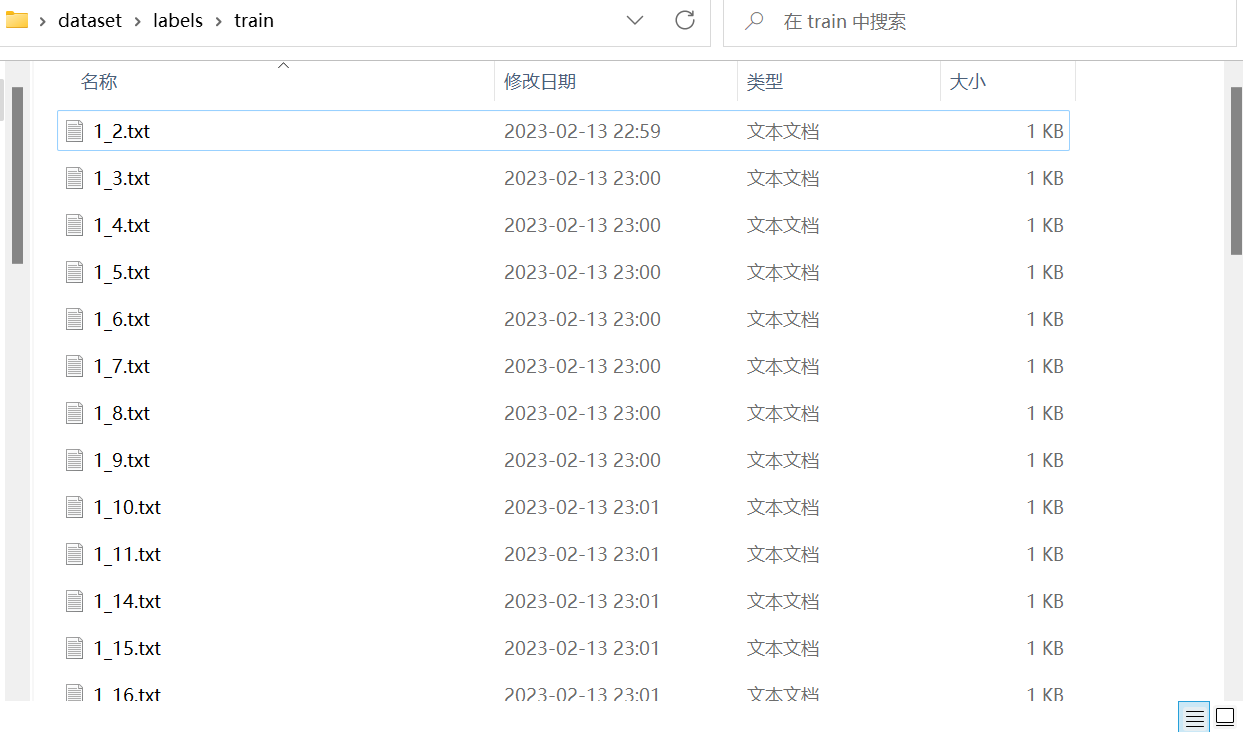
训练预处理
使用下面代码将训练集的部分划归到验证集中(记住路径修改成自己的)然后将dataset文件夹放到yolo工程中。
import os, random, shutil
def moveimg(fileDir, tarDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.2 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
print(sample)
for name in sample:
shutil.move(fileDir + name, tarDir + "\\" + name)
return
def movelabel(file_list, file_label_train, file_label_val):
for i in file_list:
if i.endswith('.jpg'):
filename = file_label_train + "\\" + i[:-4] + '.txt'
if os.path.exists(filename):
shutil.move(filename, file_label_val)
print(i + "处理成功!")
if __name__ == '__main__':
fileDir = r"C:\Users\HDJ\Desktop\dataset\images\train" + "\\" # 图片训练集文件夹
tarDir = r'C:\Users\HDJ\Desktop\dataset\images\val' # 标签验证集文件夹
moveimg(fileDir, tarDir)
file_list = os.listdir(tarDir)
file_label_train = r"C:\Users\HDJ\Desktop\dataset\labels\train" # 图片训练集文件夹
file_label_val = r"C:\Users\HDJ\Desktop\dataset\labels\val" # 标签验证集文件夹
movelabel(file_list, file_label_train, file_label_val)
训练部署实现
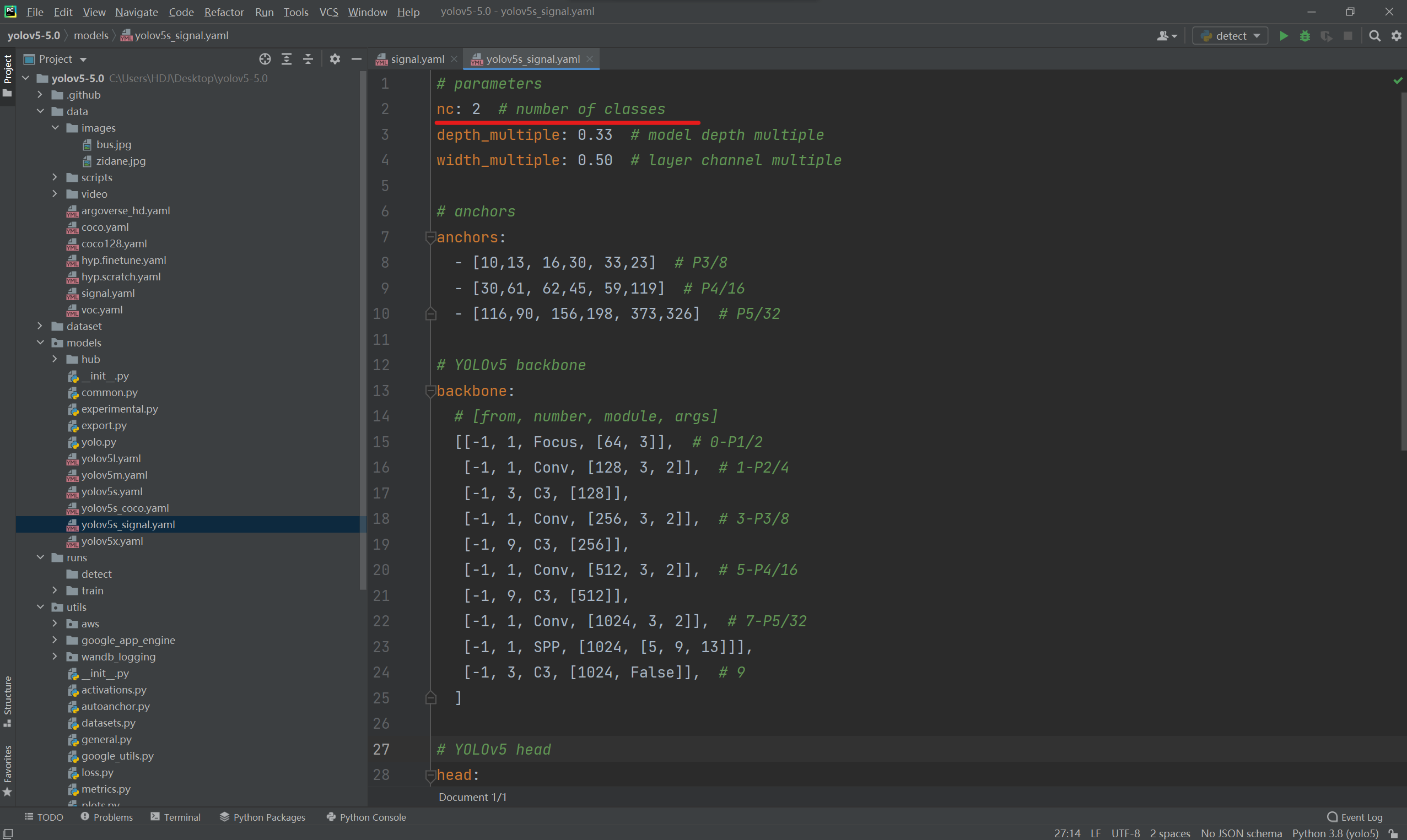
找到data目录下的coco128.yaml文件,将该文件复制一份,将复制的文件重命名为signal.yaml,在signal.yaml文件中先注释掉一行代码再修改参数,train改成训练集所在路径;val改成验证集所在路径(必须要用绝对路径),因为我训练标注的只有两个标志,所以nc改成2,names改成[H,O].

在models目录将yolov5s.yaml文件复制一份,将其重命名为yolov5_signal.yaml。在yolov5_signal.yaml文件中将类型数修改为2
在train.py的(1)(2)中修改默认yaml文件,在(3)中更改训练轮数(这里我用50轮)
parser.add_argument('--epochs',type=int, default=50)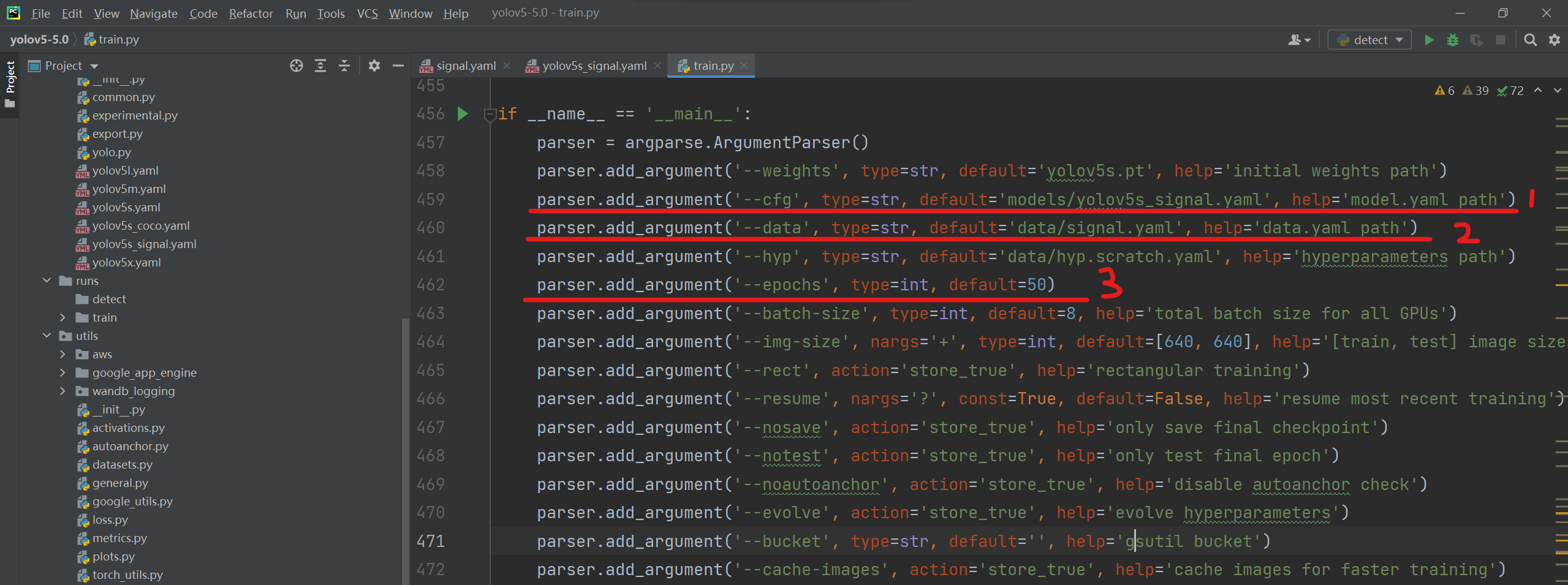
点击运行,可能会出现页面文件太小,无法完成操作的报错,详见常见下方“报错与解决”
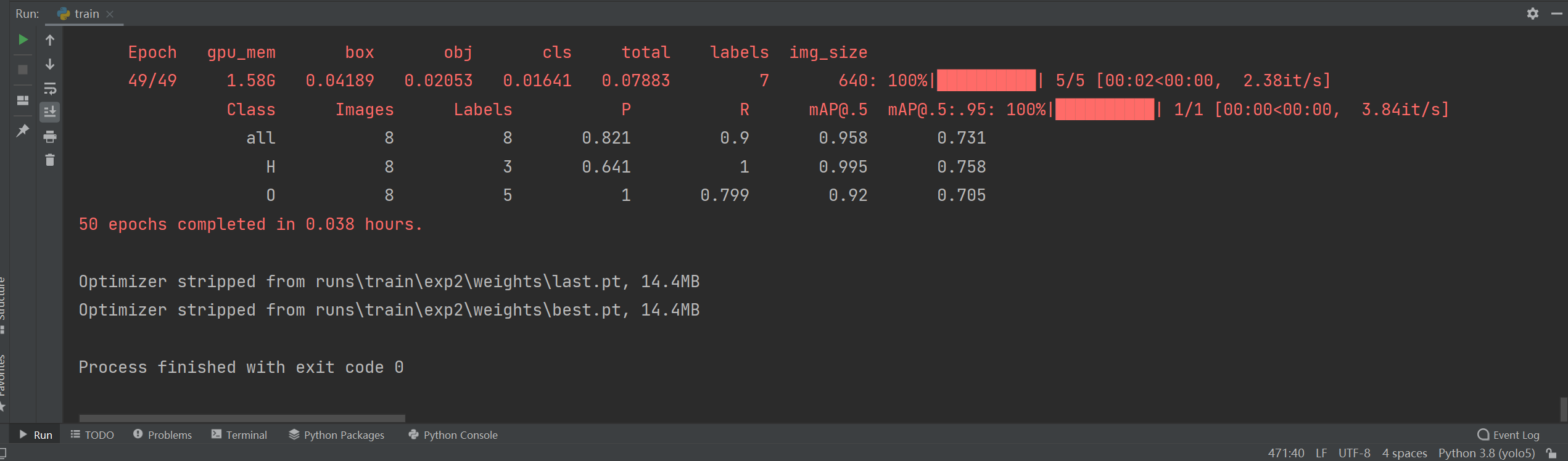
训练成功
训练完成后会在runs/train中产生exp2文件(exp是上一篇博客训练得到的,没删)
在detect.py中将推断使用的权重模型改成训练得到的模型,运行即可实现自训练模型目标识别
我的路径为
C:/Users/HDJ/Desktop/yolov5-5.0/runs/train/exp2/weights/best.pt
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp2/weights/best.pt', help='model.pt path(s)')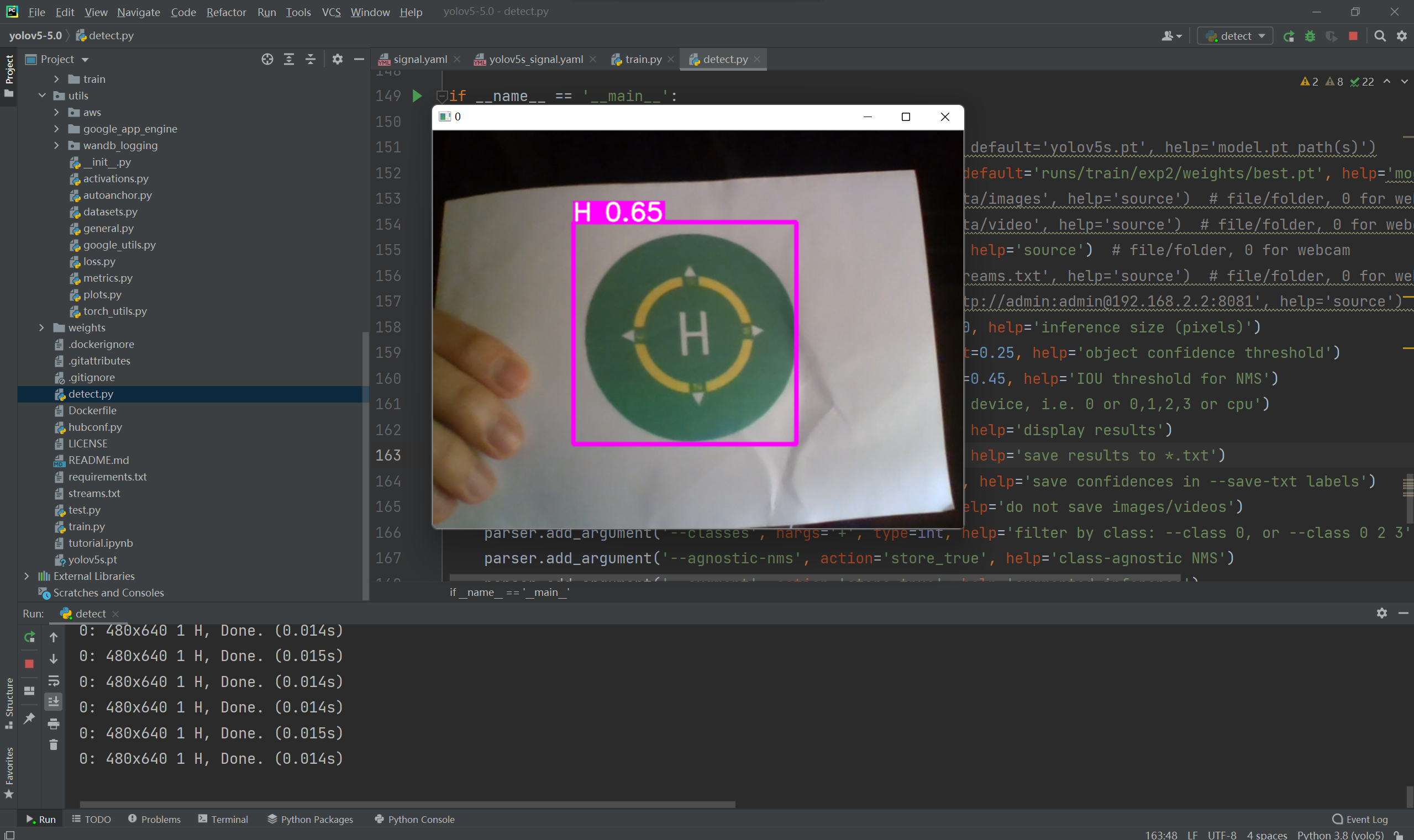
实时检测效果
常见报错与解决
1、OSError: [WinError 1455] 页面文件太小,无法完成操作。
这是由于pycharm虚拟内存不够,在utils路径下找到datasets.py这个文件,将里面的第81行里面的参数nw改为0

2、AssertionError:Image Not Found D:\PycharmProjects\yolov5-hat\VOCdevkit\images\train\000000.jpg
在另一台电脑上训练时,要先把标签文件的.cache删掉(这两个文件是在训练中产生的)
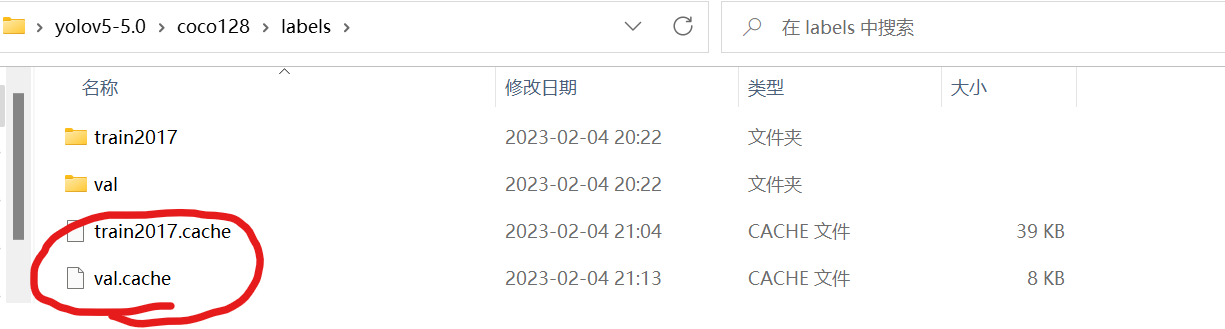
不然会报“找不到图片0”的错(可以理解为由于这两个文件的存在,把训练的路径锁成了之前训练的路径)
3、OMP:Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll alreadyinitialized
是numpy库的一个小bug
在train.py文件的顶头部分添加
importos
os.environ['KMP_DUPLICATE_LIB_OK']='True'
求学路上,你我共勉(๑•̀ㅂ•́)و✧