RT-Thread线程管理以及内核裁剪
1. RTOS概述
1.1 RTOS的定义
实时操作系统(Real-time operating system, RTOS),又称即时操作系统,它会按照排序运行、管理系统资源,并为开发应用程序提供一致的基础。
实时操作系统与一般的操作系统相比,最大的特色就是“实时性”,如果有一个任务需要执行,实时操作系统会马上(在较短时间内)执行该任务,不会有较长的延时。这种特性保证了各个任务的及时执行。
实时运算(Real-time computing)是计算机科学中对受到“实时约束”的计算机硬件和计算机软件系统的研究,实时约束像是从事件发生到系统回应之间的最长时间限制。实时程序必须保证在严格的时间限制内响应。
教科书操作系统分类:
- 批处理操作系统
- 分时操作系统
- 实时操作系统
- 个人操作系统
- 网络操作系统
1.2 主流RTOS
FreeRTOS、UCOS、RT-Thread,这三种RTOS为国内市场占有率最高的三种通用型RTOS。
目前国内也有很多的RTOS,如华为的Lite-OS等
RT-Thread与Lite-OS简要对比如下:
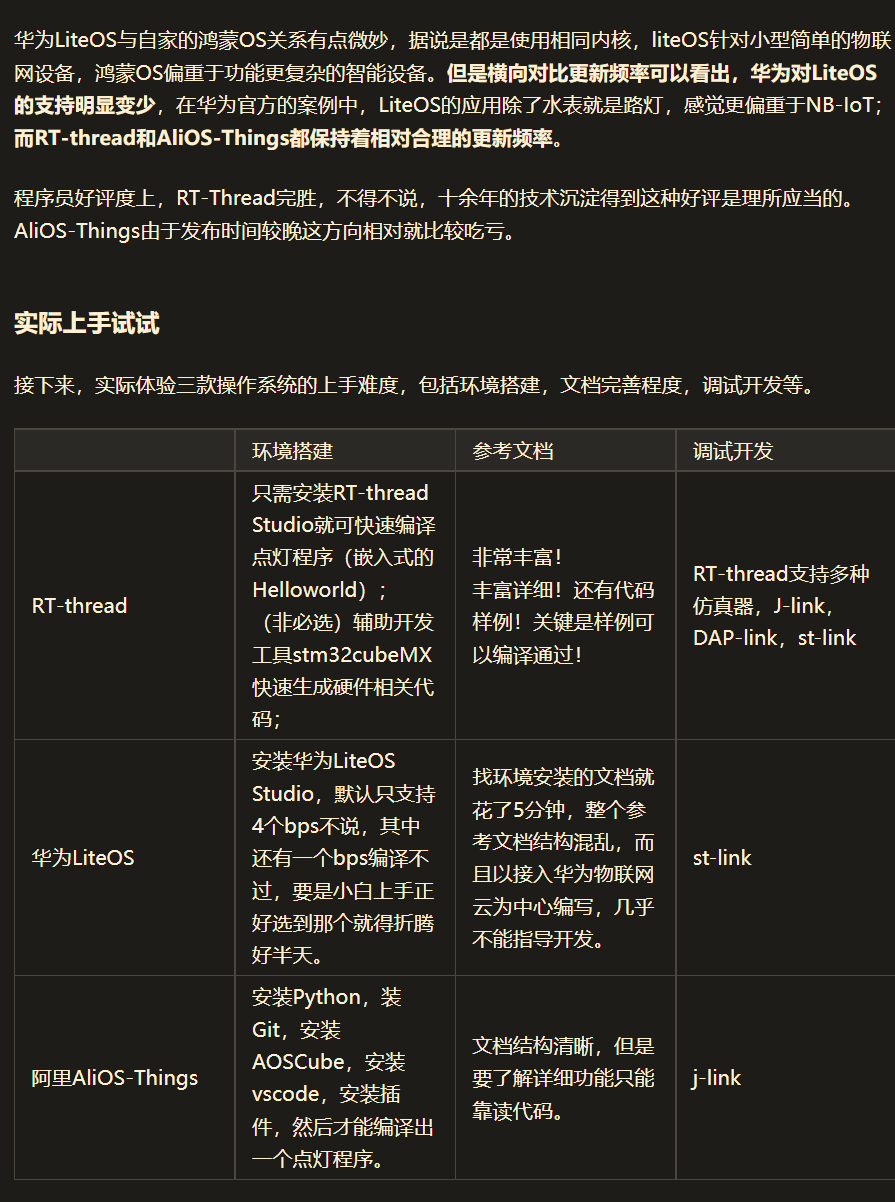
2. RT-Thread架构
RT-Thread 与其他很多 RTOS 如 FreeRTOS、uC/OS 的主要区别之一是,它不仅仅是一个实时内核,还具备丰富的中间层组件
-
内核层:RT-Thread 内核,是 RT-Thread 的核心部分,包括了内核系统中对象的实现,例如多线程及其调度、信号量、邮箱、消息队列、内存管理、定时器等;libcpu/BSP(芯片移植相关文件 / 板级支持包)与硬件密切相关,由外设驱动和 CPU 移植构成。
-
组件与服务层:组件是基于 RT-Thread 内核之上的上层软件,例如虚拟文件系统、FinSH 命令行界面、网络框架、设备框架等。采用模块化设计,做到组件内部高内聚,组件之间低耦合。
-
RT-Thread 软件包:运行于 RT-Thread 物联网操作系统平台上,面向不同应用领域的通用软件组件,由描述信息、源代码或库文件组成。RT-Thread 提供了开放的软件包平台,这里存放了官方提供或开发者提供的软件包,该平台为开发者提供了众多可重用软件包的选择,这也是 RT-Thread 生态的重要组成部分。软件包生态对于一个操作系统的选择至关重要,因为这些软件包具有很强的可重用性,模块化程度很高,极大的方便应用开发者在最短时间内,打造出自己想要的系统。RT-Thread 已经支持的软件包数量已经达到 400+。
其中与我们实验室应用最密切的相关软件包有,Paho MQTT、EasyLogger、RTGUI、SQLite
3. RT-Thread内核模型
3.1 内核概述
内核是一个操作系统的核心,是操作系统最基础也是最重要的部分。它负责管理系统的线程、线程间通信、系统时钟、中断及内存等。下图为 RT-Thread 内核架构图,可以看到内核处于硬件层之上,内核部分包括内核库、实时内核实现。这个过程其实就是将硬件抽象的过程,这种抽象的思想就是基础的数据结构与算法的实现,这里就是一个为实体建模的过程,前后端反映为为接收的entity建立类模型,后端为数据建模可以联想我们的DAO与数据流过程,哪怕是我们的运维,也可以考虑网络适配器与配置文件的关系。

3.2 内核静态对象和动态对象
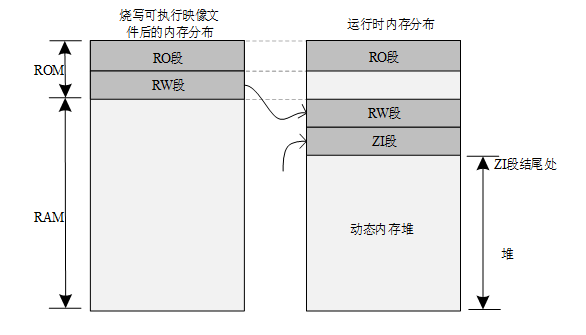
RT-Thread 内核采用面向对象的设计思想进行设计,系统级的基础设施都是一种内核对象,例如线程,信号量,互斥量,定时器等。内核对象分为两类:静态内核对象和动态内核对象,静态内核对象通常放在 RW 段和 ZI 段中,在系统启动后在程序中初始化;动态内核对象则是从内存堆中创建的,而后手工做初始化。
那么这个过程其实相当于一个trade off,后端可以联想我们数据库连接池机制,前端可以联想我们的懒加载机制,持久化方面的非关系型数据库的设计理念,运维方面有负载均衡机制。
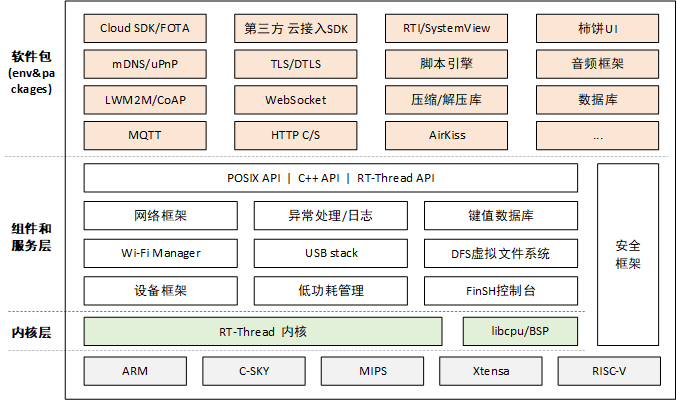
一般 MCU 包含的存储空间有:片内 Flash 与片内 RAM,RAM 相当于内存,Flash 相当于硬盘。编译器会将一个程序分类为好几个部分,分别存储在 MCU 不同的存储区。
- Code:代码段,存放程序的代码部分;
- RO-data:只读数据段,存放程序中定义的常量;
- RW-data:读写数据段,存放初始化为非 0 值的全局变量;
- ZI-data:0 数据段,存放未初始化的全局变量及初始化为 0 的变量;
RO 段中保存了 Code、RO-data 的数据,RW 段保存了 RW-data 的数据,由于 ZI-data 都是 0,所以未包含在映像文件中。STM32 在上电启动之后默认从 Flash 启动,启动之后会将 RW 段中的 RW-data(初始化的全局变量)搬运到 RAM 中,但不会搬运 RO 段,即 CPU 的执行代码从 Flash 中读取,另外根据编译器给出的 ZI 地址和大小分配出 ZI 段,并将这块 RAM 区域清零。
此处可以联想我们本科学过的内存分块机制,也是经典面试题。(补充)
例程代码
/* 线程 1 的对象和运行时用到的栈 */
static struct rt_thread thread1;
static rt_uint8_t thread1_stack[512];
/* 线程 1 入口 */
void thread1_entry(void* parameter)
{
int i;
while (1)
{
for (i = 0; i < 10; i ++)
{
rt_kprintf("%d\n", i);
/* 延时 100ms */
rt_thread_mdelay(100);
}
}
}
/* 线程 2 入口 */
void thread2_entry(void* parameter)
{
int count = 0;
while (1)
{
rt_kprintf("Thread2 count:%d\n", ++count);
/* 延时 50ms */
rt_thread_mdelay(50);
}
}
/* 线程例程初始化 */
int thread_sample_init()
{
rt_thread_t thread2_ptr;
rt_err_t result;
/* 初始化线程 1 */
/* 线程的入口是 thread1_entry,参数是 RT_NULL
* 线程栈是 thread1_stack
* 优先级是 200,时间片是 10 个 OS Tick
*/
result = rt_thread_init(&thread1,
"thread1",
thread1_entry, RT_NULL,
&thread1_stack[0], sizeof(thread1_stack),
200, 10);
/* 启动线程 */
if (result == RT_EOK) rt_thread_startup(&thread1);
/* 创建线程 2 */
/* 线程的入口是 thread2_entry, 参数是 RT_NULL
* 栈空间是 512,优先级是 250,时间片是 25 个 OS Tick
*/
thread2_ptr = rt_thread_create("thread2",
thread2_entry, RT_NULL,
512, 250, 25);
/* 启动线程 */
if (thread2_ptr != RT_NULL) rt_thread_startup(thread2_ptr);
return 0;
}
在这个例子中,thread1 是一个静态线程对象,而 thread2 是一个动态线程对象。thread1 对象的内存空间,包括线程控制块 thread1 与栈空间 thread1_stack 都是编译时决定的,因为代码中都不存在初始值,都统一放在未初始化数据段中。thread2 运行中用到的空间都是动态分配的,包括线程控制块(thread2_ptr 指向的内容)和栈空间。
静态对象会占用 RAM 空间,不依赖于内存堆管理器,内存分配时间确定。动态对象则依赖于内存堆管理器,运行时申请 RAM 空间,当对象被删除后,占用的 RAM 空间被释放。这两种方式各有利弊,可以根据实际环境需求选择具体使用方式。
3.3 内核对象管理架构
RT-Thread 采用内核对象管理系统来访问 / 管理所有内核对象,内核对象包含了内核中绝大部分设施,这些内核对象可以是静态分配的静态对象,也可以是从系统内存堆中分配的动态对象。
通过这种内核对象的设计方式,RT-Thread 做到了不依赖于具体的内存分配方式,系统的灵活性得到极大的提高。
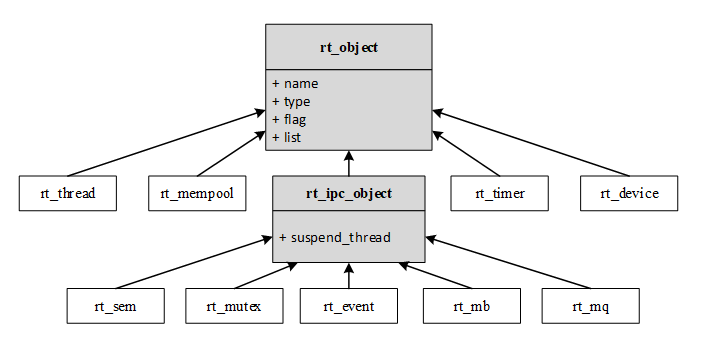
RT-Thread 内核对象包括:线程,信号量,互斥量,事件,邮箱,消息队列和定时器,内存池,设备驱动等。对象容器中包含了每类内核对象的信息,包括对象类型,大小等。对象容器给每类内核对象分配了一个链表,所有的内核对象都被链接到该链表上,RT-Thread 的内核对象容器及链表如下图所示:
内核对象容器数据结构
struct rt_object_information
{
/* 对象类型 */
enum rt_object_class_type type;
/* 对象链表 */
rt_list_t object_list;
/* 对象大小 */
rt_size_t object_size;
};
下图则显示了 RT-Thread 中各类内核对象的派生和继承关系。对于每一种具体内核对象和对象控制块,除了基本结构外,还有自己的扩展属性(私有属性),例如,对于线程控制块,在基类对象基础上进行扩展,增加了线程状态、优先级等属性。这些属性在基类对象的操作中不会用到,只有在与具体线程相关的操作中才会使用。因此从面向对象的观点,可以认为每一种具体对象是抽象对象的派生,继承了基本对象的属性并在此基础上扩展了与自己相关的属性。
这种设计方法的优点有:
(1)提高了系统的可重用性和扩展性,增加新的对象类别很容易,只需要继承通用对象的属性再加少量扩展即可。
(2)提供统一的对象操作方式,简化了各种具体对象的操作,提高了系统的可靠性。
4. RT-Thread线程管理
4.1 线程概述
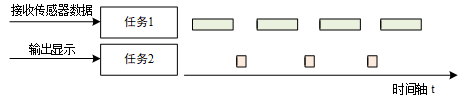
在多线程操作系统中,也同样需要开发人员把一个复杂的应用分解成多个小的、可调度的、序列化的程序单元,当合理地划分任务并正确地执行时,这种设计能够让系统满足实时系统的性能及时间的要求。例如让嵌入式系统执行这样的任务,系统通过传感器采集数据,并通过显示屏将数据显示出来,在多线程实时系统中,可以将这个任务分解成两个子任务,如下图所示,一个子任务不间断地读取传感器数据,并将数据写到共享内存中,另外一个子任务周期性的从共享内存中读取数据,并将传感器数据输出到显示屏上。
在 RT-Thread 中,与上述子任务对应的程序实体就是线程,线程是实现任务的载体,它是 RT-Thread 中最基本的调度单位,它描述了一个任务执行的运行环境,也描述了这个任务所处的优先等级,重要的任务可设置相对较高的优先级,非重要的任务可以设置较低的优先级,不同的任务还可以设置相同的优先级,轮流运行。
当线程运行时,它会认为自己是以独占 CPU 的方式在运行,线程执行时的运行环境称为上下文,具体来说就是各个变量和数据,包括所有的寄存器变量、堆栈、内存信息等。
4.2 系统线程
系统线程是指由系统创建的线程,用户线程是由用户程序调用线程管理接口创建的线程,在 RT-Thread 内核中的系统线程有空闲线程和主线程。
空闲线程
空闲线程(idle)是系统创建的最低优先级的线程,线程状态永远为就绪态。当系统中无其他就绪线程存在时,调度器将调度到空闲线程,它通常是一个死循环,且永远不能被挂起。另外,空闲线程在 RT-Thread 也有着它的特殊用途:
若某线程运行完毕,系统将自动删除线程:自动执行 rt_thread_exit() 函数,先将该线程从系统就绪队列中删除,再将该线程的状态更改为关闭状态,不再参与系统调度,然后挂入 rt_thread_defunct 僵尸队列(资源未回收、处于关闭状态的线程队列)中,最后空闲线程会回收被删除线程的资源。
主线程
在系统启动时,系统会创建 main 线程,它的入口函数为 main_thread_entry(),用户的应用入口函数 main() 就是从这里真正开始的,系统调度器启动后,main 线程就开始运行,过程如下图,用户可以在 main() 函数里添加自己的应用程序初始化代码。

4.3 线程调度
系统中总共存在两类线程,分别是系统线程和用户线程,系统线程是由 RT-Thread 内核创建的线程,用户线程是由应用程序创建的线程,这两类线程都会从内核对象容器中分配线程对象,当线程被删除时,也会被从对象容器中删除,如下图所示,每个线程都有重要的属性,如线程控制块、线程栈、入口函数等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6aw0PN1q-1681282794660)(imgs/04Object_container.png)]
线程控制块数据结构:
/* 线程控制块 */
struct rt_thread
{
/* rt 对象 */
char name[RT_NAME_MAX]; /* 线程名称 */
rt_uint8_t type; /* 对象类型 */
rt_uint8_t flags; /* 标志位 */
rt_list_t list; /* 对象列表 */
rt_list_t tlist; /* 线程列表 */
/* 栈指针与入口指针 */
void *sp; /* 栈指针 */
void *entry; /* 入口函数指针 */
void *parameter; /* 参数 */
void *stack_addr; /* 栈地址指针 */
rt_uint32_t stack_size; /* 栈大小 */
/* 错误代码 */
rt_err_t error; /* 线程错误代码 */
rt_uint8_t stat; /* 线程状态 */
/* 优先级 */
rt_uint8_t current_priority; /* 当前优先级 */
rt_uint8_t init_priority; /* 初始优先级 */
rt_uint32_t number_mask;
......
rt_ubase_t init_tick; /* 线程初始化计数值 */
rt_ubase_t remaining_tick; /* 线程剩余计数值 */
struct rt_timer thread_timer; /* 内置线程定时器 */
void (*cleanup)(struct rt_thread *tid); /* 线程退出清除函数 */
rt_uint32_t user_data; /* 用户数据 */
};
RT-Thread 的线程调度器是抢占式的,主要的工作就是从就绪线程列表中查找最高优先级线程,保证最高优先级的线程能够被运行,最高优先级的任务一旦就绪,总能得到 CPU 的使用权。
其中 init_priority 是线程创建时指定的线程优先级,在线程运行过程当中是不会被改变的(除非用户执行线程控制函数进行手动调整线程优先级)。cleanup 会在线程退出时,被空闲线程回调一次以执行用户设置的清理现场等工作。最后的一个成员 user_data 可由用户挂接一些数据信息到线程控制块中,以提供一种类似线程私有数据的实现方式。
五态图

| 状态 | 描述 |
|---|---|
| 初始状态 | 当线程刚开始创建还没开始运行时就处于初始状态;在初始状态下,线程不参与调度。此状态在 RT-Thread 中的宏定义为 RT_THREAD_INIT |
| 就绪状态 | 在就绪状态下,线程按照优先级排队,等待被执行;一旦当前线程运行完毕让出处理器,操作系统会马上寻找最高优先级的就绪态线程运行。此状态在 RT-Thread 中的宏定义为RT_THREAD_READY |
| 运行状态 | 线程当前正在运行。在单核系统中,只有 rt_thread_self() 函数返回的线程处于运行状态;在多核系统中,可能就不止这一个线程处于运行状态。此状态在 RT-Thread 中的宏定义为 RT_THREAD_RUNNING |
| 挂起状态 | 也称阻塞态。它可能因为资源不可用而挂起等待,或线程主动延时一段时间而挂起。在挂起状态下,线程不参与调度。此状态在 RT-Thread 中的宏定义为 RT_THREAD_SUSPEND |
| 关闭状态 | 当线程运行结束时将处于关闭状态。关闭状态的线程不参与线程的调度。此状态在 RT-Thread 中的宏定义为 RT_THREAD_CLOSE |
赛跑运动员例子,以赛场运动员为例,那么传统三态图相当于运动员来了就跑,到终点停止计时,分散地记录运动员的成绩,而五态图在就绪之前还有个初始态,相当于参赛运动员可以提前准备,一批运动员在同一起跑线听信号竞赛。两种方式各有优劣。
RT-Thread 提供一系列的操作系统调用接口,使得线程的状态在这五个状态之间来回切换。线程通过调用函数 rt_thread_create/init() 进入到初始状态(RT_THREAD_INIT);初始状态的线程通过调用函数 rt_thread_startup() 进入到就绪状态(RT_THREAD_READY);就绪状态的线程被调度器调度后进入运行状态(RT_THREAD_RUNNING);当处于运行状态的线程调用 rt_thread_delay(),rt_sem_take(),rt_mutex_take(),rt_mb_recv() 等函数或者获取不到资源时,将进入到挂起状态(RT_THREAD_SUSPEND);处于挂起状态的线程,如果等待超时依然未能获得资源或由于其他线程释放了资源,那么它将返回到就绪状态。挂起状态的线程,如果调用 rt_thread_delete/detach() 函数,将更改为关闭状态(RT_THREAD_CLOSE);而运行状态的线程,如果运行结束,就会在线程的最后部分执行 rt_thread_exit() 函数,将状态更改为关闭状态。
时间片
每个线程都有时间片这个参数,但时间片仅对优先级相同的就绪态线程有效,这一点与分时操作系统有着本质上的不同。系统对优先级相同的就绪态线程采用时间片轮转的调度方式进行调度时,时间片起到约束线程单次运行时长的作用,其单位是一个系统节拍(OS Tick)假设有 2 个优先级相同的就绪态线程 A 与 B,A 线程的时间片设置为 10,B 线程的时间片设置为 5,那么当系统中不存在比 A 优先级高的就绪态线程时,系统会在 A、B 线程间来回切换执行,并且每次对 A 线程执行 10 个节拍的时长,对 B 线程执行 5 个节拍的时长,如下图。

4.4 线程函数的设计准则
-
入口函数(线程实现预期功能的函数。线程的入口函数由用户设计实现)
-
无限循环模式
void thread_entry(void* paramenter) { while (1) { /* 等待事件的发生 */ /* 对事件进行服务、进行处理 */ } }用户设计这种无限循环的线程的目的,就是为了让这个线程一直被系统循环调度运行,永不删除。
线程看似没有什么限制程序执行的因素,似乎所有的操作都可以执行。但是作为一个实时系统,一个优先级明确的实时系统,如果一个线程中的程序陷入了死循环操作,那么比它优先级低的线程都将不能够得到执行。所以在实时操作系统中必须注意的一点就是:线程中不能陷入死循环操作,必须要有让出 CPU 使用权的动作,如循环中调用延时函数或者主动挂起。
-
顺序执行或有限次循环模式
static void thread_entry(void* parameter) { /* 处理事务 #1 */ … /* 处理事务 #2 */ … /* 处理事务 #3 */ }如简单的顺序语句、do while() 或 for()循环等,此类线程不会循环或不会永久循环,可谓是 “一次性” 线程,一定会被执行完毕。在执行完毕后,线程将被系统自动删除。
-
-
空闲进程钩子函数
空闲线程也提供了接口来运行用户设置的钩子函数,在空闲线程运行时会调用该钩子函数,适合处理功耗管理、看门狗喂狗等工作。空闲线程必须有得到执行的机会,即其他线程不允许一直while(1)死卡,必须调用具有阻塞性质的函数;否则例如线程删除、回收等操作将无法得到正确执行。 -
调度器钩子函数
在整个系统的运行时,系统都处于线程运行、中断触发 - 响应中断、切换到其他线程,甚至是线程间的切换过程中,或者说系统的上下文切换是系统中最普遍的事件。请仔细编写你的钩子函数,稍有不慎将很可能导致整个系统运行不正常(在这个钩子函数中,基本上不允许调用系统 API,更不应该导致当前运行的上下文挂起)
4.5 中断与线程的联系与不同
本节抛开中断的具体实现不谈,谈谈RTOS中的中断与线程的区别与应用场景。
线程:一个线程携带一个任务,多个线程可以由优先级作为判断进行打断,转而进行线程切换。
中断:简单的解释就是系统正在处理某一个正常事件,忽然被另一个需要马上处理的紧急事件打断,系统转而处理这个紧急事件,待处理完毕,再恢复运行刚才被打断的事件。
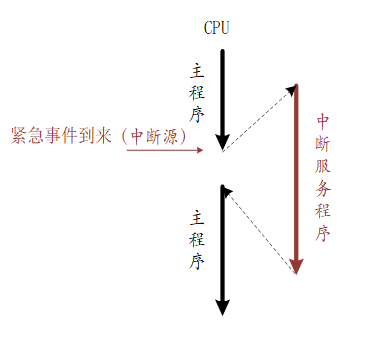
中断与线程的相似之处:
都可以“夹带私货”,我们可以指定自己的任务,线程有用户设定的钩子函数,而中断有中断服务程序。
中断与线程的纽带:
当一个中断发生时,中断服务程序需要取得相应的硬件状态或者数据。如果中断服务程序接下来要对状态或者数据进行简单处理,比如 CPU 时钟中断,中断服务程序只需对一个系统时钟变量进行加一操作,然后就结束中断服务程序。这类中断需要的运行时间往往都比较短。但对于另外一些中断,中断服务程序在取得硬件状态或数据以后,还需要进行一系列更耗时的处理过程,通常需要将该中断分割为两部分,即上半部分(Top Half)和底半部分(Bottom Half)。在上半部分中,取得硬件状态和数据后,打开被屏蔽的中断,给相关线程发送一条通知(可以是 RT-Thread 所提供的信号量、事件、邮箱或消息队列等方式),然后结束中断服务程序;而接下来,相关的线程在接收到通知后,接着对状态或数据进行进一步的处理,这一过程称之为底半处理。
在Linux内核中底半部分就是下半部,在Linux内核中,硬中断称为上半部,软中断称为下半部。
例子:
为了详细描述底半处理在 RT-Thread 中的实现,我们以一个虚拟的网络设备接收网络数据包作为范例,如下代码,并假设接收到数据报文后,系统对报文的分析、处理是一个相对耗时的,比外部中断源信号重要性小许多的,而且在不屏蔽中断源信号情况下也能处理的过程。
这个例子的程序创建了一个 nwt 线程,这个线程在启动运行后,将阻塞在 nw_bh_sem 信号上,一旦这个信号量被释放,将执行接下来的 nw_packet_parser 过程,开始 Bottom Half 的事件处理。
/*
* 程序清单:中断底半处理例子
*/
/* 用于唤醒线程的信号量 */
rt_sem_t nw_bh_sem;
/* 数据读取、分析的线程 */
void demo_nw_thread(void *param)
{
/* 首先对设备进行必要的初始化工作 */
device_init_setting();
/*.. 其他的一些操作..*/
/* 创建一个 semaphore 来响应 Bottom Half 的事件 */
nw_bh_sem = rt_sem_create("bh_sem", 0, RT_IPC_FLAG_PRIO);
while(1)
{
/* 最后,让 demo_nw_thread 等待在 nw_bh_sem 上 */
rt_sem_take(nw_bh_sem, RT_WAITING_FOREVER);
/* 接收到 semaphore 信号后,开始真正的 Bottom Half 处理过程 */
nw_packet_parser (packet_buffer);
nw_packet_process(packet_buffer);
}
}
int main(void)
{
rt_thread_t thread;
/* 创建处理线程 */
thread = rt_thread_create("nwt",demo_nw_thread, RT_NULL, 1024, 20, 5);
if (thread != RT_NULL)
rt_thread_startup(thread);
}
接下来让我们来看一下 demo_nw_isr 中是如何处理 Top Half,并开启 Bottom Half 的,如下例。
void demo_nw_isr(int vector, void *param)
{
/* 当 network 设备接收到数据后,陷入中断异常,开始执行此 ISR */
/* 开始 Top Half 部分的处理,如读取硬件设备的状态以判断发生了何种中断 */
nw_device_status_read();
/*.. 其他一些数据操作等..*/
/* 释放 nw_bh_sem,发送信号给 demo_nw_thread,准备开始 Bottom Half */
rt_sem_release(nw_bh_sem);
/* 然后退出中断的 Top Half 部分,结束 device 的 ISR */
}
从上面例子的两个代码片段可以看出,中断服务程序通过对一个信号量对象的等待和释放,来完成中断 Bottom Half 的起始和终结。由于将中断处理划分为 Top 和 Bottom 两个部分后,使得中断处理过程变为异步过程。这部分系统开销需要用户在使用 RT-Thread 时,必须认真考虑中断服务的处理时间是否大于给 Bottom Half 发送通知并处理的时间。
中断与线程的区别:
RT-Thread 不对中断服务程序所需要的处理时间做任何假设、限制,但如同其他实时操作系统或非实时操作系统一样,用户需要保证所有的中断服务程序在尽可能短的时间内完成(中断服务程序在系统中相当于拥有最高的优先级,会抢占所有线程优先执行)。这样在发生中断嵌套,或屏蔽了相应中断源的过程中,不会耽误嵌套的其他中断处理过程,或自身中断源的下一次中断信号。
信号量也能够方便地应用于中断与线程间的同步,例如一个中断触发,中断服务例程需要通知线程进行相应的数据处理。这个时候可以设置信号量的初始值是 0,线程在试图持有这个信号量时,由于信号量的初始值是 0,线程直接在这个信号量上挂起直到信号量被释放。当中断触发时,先进行与硬件相关的动作,例如从硬件的 I/O 口中读取相应的数据,并确认中断以清除中断源,而后释放一个信号量来唤醒相应的线程以做后续的数据处理。例如 FinSH 线程的处理方式,如下图所示。

信号量的值初始为 0,当 FinSH 线程试图取得信号量时,因为信号量值是 0,所以它会被挂起。当 console 设备有数据输入时,产生中断,从而进入中断服务例程。在中断服务例程中,它会读取 console 设备的数据,并把读得的数据放入 UART buffer 中进行缓冲,而后释放信号量,释放信号量的操作将唤醒 shell 线程。在中断服务例程运行完毕后,如果系统中没有比 shell 线程优先级更高的就绪线程存在时,shell 线程将持有信号量并运行,从 UART buffer 缓冲区中获取输入的数据。
中断与线程间的互斥不能采用信号量(锁)的方式,而应采用开关中断的方式。
5. RT-Thread部署
5.1 内核裁剪
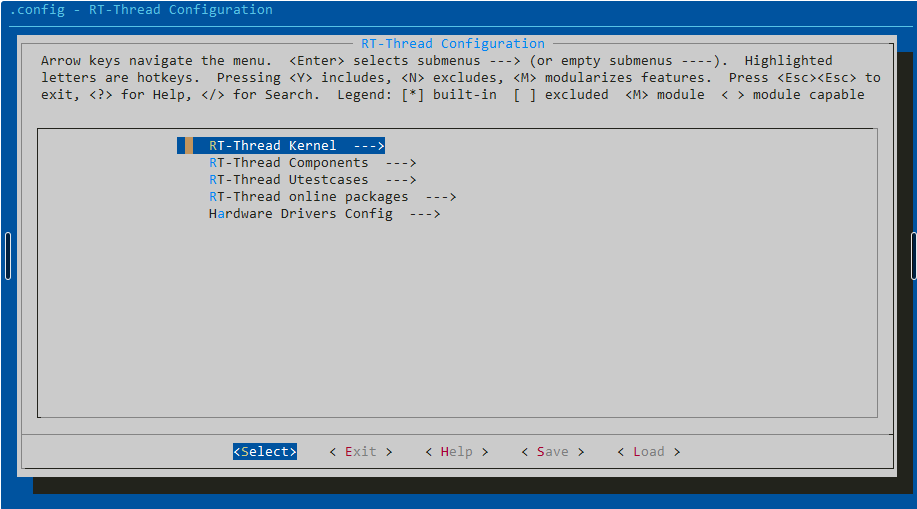
硬件的程序设计最需要考虑的是资源,一个嵌入式微型计算机面对的业务大小不一,我们需要面向需求进行选型和程序安排,RT-Thread等一众RTOS都有他们完整的生态组件,而我们的应用场景往往并不会全部用到,假设我们有块板子的外设传感器只有SPI、IIC总线协议,那么我们的内核保留CAN模块是空占用内存,这个时候我们完全可以按照我们的需求去将内核中没有用到的模块进行裁剪,以移植到我们的微型计算机上,对于硬件设备来说1KB的空间都是异常宝贵的。

官方内核裁剪图形化工具

5.2 编译器选项
rtconfig.py 是一个 RT-Thread 标准的编译器配置文件,控制了大部分编译选项,是一个使用 python 语言编写的脚本文件,主要用于完成以下工作:
- 指定编译器(从支持的多个编译器中选择一个你现在使用的编译器)。
- 指定编译器参数,如编译选项、链接选项等。
当我们使用 scons 命令编译工程时,就会按照 rtconfig.py 的编译器配置选项编译工程。下面的代码为 stm32f10x-HAL BSP 目录下 rtconfig.py 的部分代码。
rtconfig.py
import os
# toolchains options
ARCH='arm'
CPU='cortex-m3'
CROSS_TOOL='gcc'
if os.getenv('RTT_CC'):
CROSS_TOOL = os.getenv('RTT_CC')
# cross_tool provides the cross compiler
# EXEC_PATH is the compiler execute path, for example, CodeSourcery, Keil MDK, IAR
if CROSS_TOOL == 'gcc':
PLATFORM = 'gcc'
EXEC_PATH = '/usr/local/gcc-arm-none-eabi-5_4-2016q3/bin/'
elif CROSS_TOOL == 'keil':
PLATFORM = 'armcc'
EXEC_PATH = 'C:/Keilv5'
elif CROSS_TOOL == 'iar':
PLATFORM = 'iar'
EXEC_PATH = 'C:/Program Files/IAR Systems/Embedded Workbench 6.0 Evaluation'
if os.getenv('RTT_EXEC_PATH'):
EXEC_PATH = os.getenv('RTT_EXEC_PATH')
BUILD = 'debug'
if PLATFORM == 'gcc':
# toolchains
PREFIX = 'arm-none-eabi-'
CC = PREFIX + 'gcc'
AS = PREFIX + 'gcc'
AR = PREFIX + 'ar'
LINK = PREFIX + 'gcc'
TARGET_EXT = 'elf'
SIZE = PREFIX + 'size'
OBJDUMP = PREFIX + 'objdump'
OBJCPY = PREFIX + 'objcopy'
DEVICE = '-mcpu=cortex-m3 -mthumb -ffunction-sections -fdata-sections'
CFLAGS = DEVICE
AFLAGS = '-c' + DEVICE + '-x assembler-with-cpp'
LFLAGS = DEVICE + '-Wl,--gc-sections,-Map=rtthread-stm32.map,-cref,-u,Reset_Handler -T stm32_rom.ld'
5.3 选择优化等级
RT-Thread-Studio 使用的是 GCC 编译器,GCC 编译器对代码的编译优化有一系列的配置项,大体分为五个优化等级:-O0、-O1、-O2、-O3 和 -Os。
-O0:关闭所有优化选项,是 GCC 默认的等级,目的是让编译器减少编译时间并使调试产生预期的结果。在 RT-Thread-Studio 中,默认也是配置的该选项,如果编译的代码尺寸较大,我们建议更换优化等级(一般我们会选择 O2 等级)。
-O1:这是最基本的优化等级。编译器会在不花费太多编译时间的同时试图生成更快更小的代码。这些优化是非常基础的,但一般这些任务肯定能顺利完成。
-O2:O1 的进阶。这是推荐的优化等级,除非你有特殊的需求。O2 会比 O1 启用更多的优化选项。当设置了 O2 等级后,编译器会试图增加编译的时间和提升生成代码的性能(我们一般选用此优化等级完成编译任务)。
-O3:这是最高的优化等级,O3 开启了 O2 指定的所有优化,并启用了更多的优化选项。例如构建用于保存变量的伪寄存器网络(使得调试更加困难)、优化循环执行过程等。开启 O3 优化不一定会减少代码尺寸,有可能会为了减少代码执行时间反而增加代码体积。一般我们不使用此优化等级。
-Os:该这个等级用来优化代码尺寸。其中启用了 O2 中不增加目标文件大小的优化选项。这对于磁盘空间极其紧张或者 CPU 缓存较小的机器非常有用。一般使用 O2 等级之后发现生成的目标文件尺寸偏大,可以尝试使用 Os 等级进一步的优化。下表是GCC优化等级列表。
| option | optimization level | execution time | code size | memory usage | compile time |
|---|---|---|---|---|---|
| -O0 | optimization for compilation time (default) | + | + | - | - |
| -O1 or -O | optimization for code size and execution time | - | - | + | + |
| -O2 | optimization more for code size and execution time | – | + | ++ | |
| -O3 | optimization more for code size and execution time | — | + | +++ | |
| -Os | optimization for code size | – | ++ | ||
| -Ofast | O3 with fast none accurate math calculations | — | + | +++ |