来自:甲骨文华育兴业(IT培训网) http://www.oraclewdp-china.com/
数据本地化可以对Spark任务的性能产生重大影响。如果数据和操作数据的代码在一块,计算通常会很快。但是如果数据和代码不在一起,就必须将一方移动到另一方。通常,将序列化的代码块从一个地方发送到另一个地方要比发送数据更快,因为代码的大小比数据要小得多(这也是大数据计算核心思想之一:计算向数据移动)。Spark围绕这个数据本地化的一般原则构建它的调度。
数据本地化是指数据与运行代码之间的距离。根据数据的当前位置,有几个本地化级别。从近到远:
· PROCESS_LOCAL 数据位于与运行代码相同的JVM中。这是最好的地方。

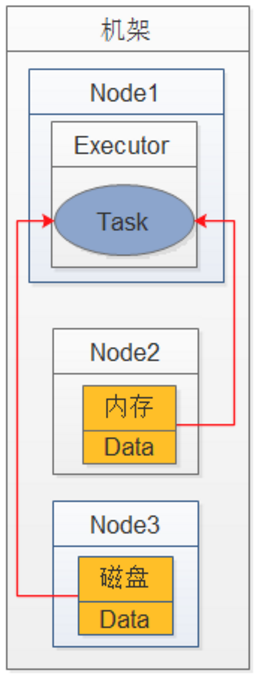
· NODE_LOCAL 数据位于同一节点上。示例:可能在同一个节点上的HDFS中,或者在同一个节点上的另一个executor中。这比PROCESS_LOCAL稍微慢一些,因为数据必须在进程之间来回移动。

· NO_PREF 数据在任何地方都可以同样快速地访问,并且没有本地偏好。
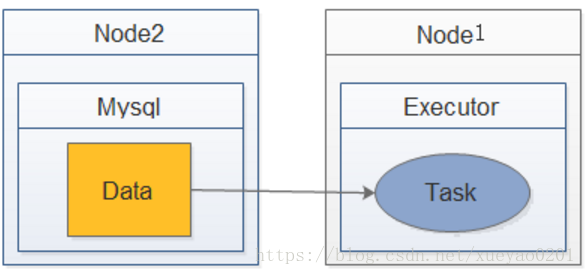
· RACK_LOCAL 数据位于同一台服务器上。数据在同一机架上的不同服务器上,所以需要通过网络发送,通常是通过一个交换机。

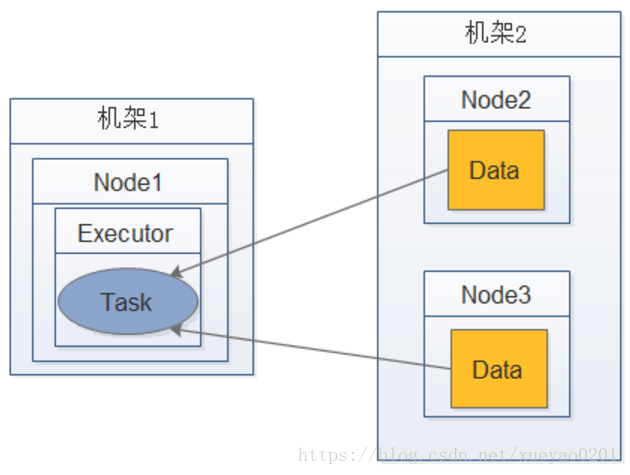
· ANAY 数据在网络上的其他地方,而不是在同一个机架上。
Spark倾向于将所有任务都安排在最佳的本地化级别,但这并不总是可行的。在没有任何空闲的executor来处理未处理数据的情况下,Spark将切换到较低的本地化级别。有两种选择:a)等到一个繁忙的CPU释放出来,在同一台服务器上启动一个数据任务,或者,b)立即在一个需要移动数据的较远的地方启动一个新的任务。
Spark通常做的是等待一个繁忙的CPU释放的希望。一旦超时过期,它就开始将数据从远处移动到空闲CPU。每个级别之间的等待超时时间可以单独配置,也可以全部在一个参数中;有关详细信息,请参阅配置页面上关于spark.locality参数的说明。如果您的任务运行时间很长,并且看到了不好的本地化级别,您应该增加这些设置(即增加每个级别间的超时时间),但是默认情况下通常很好。
如何查看本地化级别
1、通过Task日志查看
2、我常用的方法是从yarn的RM Web UI界面找到对应的任务,进入任务的明细界面。

何时需要调节
观察日志或者WebUI,查看Task数据本地化的级别,如果大部分都是PROCESS_LOCAL,则不需要调节。如果大部分都是NODE_LOCAL、ANY,RACK_LOCAL那最好提高数据本地化级别。
调节是一个反复尝试的过程,每次调节完以后,再来运行,观察日志。
看看大部分的task的本地化级别有没有提升;看看,整个spark作业的运行时间有没有缩短。
如何调节数本地化级别
通过改变数据本地化级别之间的超时等待时间。Spark官网对相关配置项有详细的介绍。
spark.locality.wait 默认3s
spark.locality.wait.process 默认与spark.locality.wait保持一致,可以单独指定
spark.locality.wait.node 默认与spark.locality.wait保持一致,可以单独指定
spark.locality.wait.rack 默认与spark.locality.wait保持一致,可以单独指定
注意:
修改的等待时间不能太长,因为时间太长,虽然每个Task的本地化级别提高了,但是整个Application的执行时间会由于等待时间过长而大大加长,从而失去了调节本地化级别的意义。
原理
Driver端的TaskScheduler在分发任务前,都会通过MapOutputTracker查询Task任务所需数据的位置信息,优先将Task发送到资源充足且数据所在节点的Executor的线程池中。Task在线程池中排队等待执行,如果等待时间超过3s(默认值,可能更长),重试5次,依然无法执行的话,TaskScheduler就认为这个节点没有计算能力(即资源被其他任务占完了)。TaskScheduler会降低数据本地化级别,将Task按照NODE_LOCAL重新发送,如果还无法执行,就继续降低数据本地化级别。