随着企业数据量的增多,为了配合企业的业务分析、商业智能等应用场景,从而驱动数据化的商业决策,分析型数据库诞生了。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算来提升它的数据处理能力。本篇文章将详细介绍 MPP 数据库的概念,解决的问题、典型的厂商以及它的技术架构和未来的发展方向。

— MPP数据库简介—
分析型数据库是数据库的一个分支,主要设计目标是存储、管理和分析数据,一般存储的数据类型多,时间维度长,主要配合企业的业务分析、商业智能等应用场景,驱动数据化的商业决策。由于数据分析一般涉及的数据量大,计算复杂,分析型数据库一般都是采用大规模并行计算或者分布式计算来提升它的数据处理能力。行业内从1984年开始推出基于多个关系数据库(Postgres为主)组成的MPP数据库方式来提升计算能力,代表性的产品有Teradata、Netezza、Vertica等。MPP全称为Massive Parallel Processing,是一种并行化的编程模型,其思想是通过管理来协调的,由多个处理单元并行处理一个程序中的不同部分,从而最终完成整个程序的计算模式。每个处理单元有自己独立的运行环境和资源。MPP数据库中每个处理单元就是一个关系数据库,通过大规模并行的关系数据库的协同来提升数据库能够处理的数据的量级和性能。基本上每个主流的关系数据库厂商都有自己的MPP版本,另外也有一些主要开发MPP的数据库厂商和开源的MPP数据库,国内近几年也涌现了不少的MPP数据库。
| 厂商 | 数据库名称 | 介绍 |
| Teradata | Teradata Database | 1984年推出的首个MPP数据库,采用列式存储加速分析性能,以一体机方式交付 |
| HP | Vertica | 图灵奖得主Michael Stonebraker创立的首个真正意义上采用列式存储的MPP数据库,可运行在标准硬件上 |
| Pivotal | Greenplum | 开源的MPP数据库,数据库实例采用PostgreSQL,可运行在标准硬件上 |
| 华为 | GaussDB | 基于Postgres-XC深度自研的分析型数据库,可运行在标准硬件上,可扩展性较好 |
— 总体架构 —
MPP数据库一般会包含多个控制节点和多个计算节点,控制节点负责计算任务的编译、执行计划的生成和计算结果的聚合,而计算节点负责计算划分到具体数据库实例的计算任务。为了更好的可扩展性,MPP数据库一般采用Shared-nothing架构,每个数据库节点之间没有数据共享。MPP数据库一般可以通过增加数据库计算能力,此外因为多个实例,数据库总体的数据加载性能相比较单实例数据库也有很高的提升。

数据分片是能够实现并行化计算的核心,MPP数据库有多种数据分片方式,主要包括3大类:
- Hash模式
一般适用于事实表或大表,根据一条记录的某个字段或组合字段的hash值将数据分散到某个节点上,hash函数可以有多种方式。通过根据对给定字段的hash值来做数据分布,一个大表可以均匀的分散到MPP数据库的多个节点上,当对这个表查询时,MPP数据库编译器可以根据SQL中相应的检索字段将查询快速定位到某个或几个相关的数据库节点并将SQL下发,对应的数据库节点就可以快速响应查询结果。Hash模式在真实生产中使用的比较多,不过它也有几个较明显的问题:一是Hash取值一般是跟数据库节点数量密切相关,如果数据库添加或者减少节点后,那么已经存在的数据的Hash分布就不再正确,因此需要做数据库的数据重分布,带来较大的运维成本;二是在实际操作中需要根据业务特点来设计或选择Hash字段,否则容易出现性能热点等影响数据库整体性能的问题。

- 均匀分布模式
一般适用于一些过程中的临时表,在对表的数据的持久化过程中按照均匀分布的方式在每个数据库节点上均匀写入数据。这个模式下数据库的IO吞吐可以得到最大化利用,无论是读取还是写入,仅适合表只做一次读写的场景。
- 全复制模式
一般适合记录数比较少的表,一般情况下在各个数据库节点都完整的存储一份数据。这类表一般情况下用于大量的分析类场景,事务类操作比较少,因此虽然存储上有明显的浪费,但是在分析性场景下不再需要将这个表在多个数据库节点上传输或复制,从而提升分析性能。
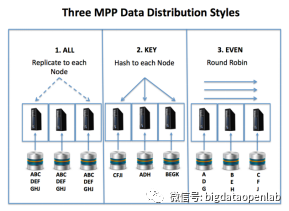
基于数据分片的方式实现了数据无共享架构,因此可以通过增加数据库实例的方式来提升数据库的性能,因此与早期的SMP共享架构数据库(典型代表Oracle RAC)相比,MPP数据库的分析性能要远远超出。此外数据库的整体并发响应,以及数据库的读写吞吐量,MPP数据库都能够通过有效的业务优化达到一个很高的水平。在MPP数据库的可扩展性方面,从中国信通院的相关测试来看,开源的MPP数据库能够支持一百节点左右的集群规模,而一些商业MPP数据库通过更好的软硬件结合已经可以实现单集群达到五百个节点。
— 开源MPP数据库Greenplum —
Greenplum是以PostgreSQL为单实例的MPP数据库,于2003年诞生,在2012年之后演进成为Pivotal Greenplum Database。Greenplum用于存储、处理海量的数据,主要用于OLAP业务。Greenplum采用MPP架构,底层的逻辑数据库采用PostgreSQL,客户端支持psql和ODBC。

Greenplum集群中有三种角色组件,Master、Segment、Interconnect。数据的分片方式以及SQL计算的分解/聚合和通用的MPP数据库原理基本一致,在此不做赘述。Master是Greenplum数据库系统的入口,接受客户端连接及提交的SQL语句,将工作负载分发给其它数据库实例(segment实例),由它们存储和处理数据。Master也负责持久化和查询系统级元数据,负责认证用户连接,接收来自客户端的SQL处理请求,最终汇总Segments的结果并返回客户端。Master Server本身采用主备方式来保证高可用。Segment是独立的PostgreSQL数据库,负责数据存储和分析的具体执行,集群中的数据分布在各个Segment上,用户不直接与Segment通信,而是通过Master交互。每个Segment的数据冗余存放在另一个Segment上,数据实时同步,当Primary Segment失效时,Mirror Segment将自动提供服务。Interconnect负责不同PostgreSQL实例之间的通信,它默认使用UDP协议以提供更好的网络性能,并通过对数据包的检验来保证可靠性。从2019年中国信通院组织的分析数据库基准测试结果来看,一共有14个产品通过测试,其中6个产品是基于Greenplum来二次开发的,这说明了Greenplum是开源MPP数据库的最受欢迎项目。除了本身开源以外,Greenplum在以下几方面也比较独特:
- SQL兼容度:由于Greenplum基于PostgreSQL内核,因此其本身保持了关系数据库的特性以及SQL的兼容性,以及与PostgreSQL相似的安全和权限模型。此外,Greenplum支持完整的分布式事务操作和MVCC,因此在事务相关操作上也兼容标准SQL语义。
- 分析性能:在SQL优化方面, GPORCA优化器是基于代价的优化器的一个出色的开源项目,为各种复杂的分析SQL有个极佳的执行计划。
- 并行数据加载:Greenplum提供了并行加载的技术,其自带的gpfdist工具能够直接和每个Segment交互做并行导入。
- 开放式的架构:由于PostgreSQL能够支持插件化的方式来自定义数据类型、函数、存储过程等能力,Greenplum也自然继承了这一特点,因此社区的开发者先后贡献了包括地理时空数据处理、机器学习、图分析、文本分析等在内的多个扩展模块,以及支持了JSON、XML等半结构化数据类型。
由于Greenplum数据库仍然是基于典型的MPP架构,因此MPP数据库的规模问题(单个集群规模在200节点以内)、多租户资源隔离问题、落后者问题等仍然存在,因此在支撑大型企业的多个业务场景时存在较大的技术挑战。由于其比较良好的SQL兼容、分布式事务、优秀的优化器等能力,Greenplum可以比较好的支持一些中小型企业的结构化数据分析任务。Greenplum自身也在努力和云计算结合来解决多租户资源隔离问题,其已经和多个公有云厂商合作推出云上的数据库服务。另外,Greenplum也在更加紧密的与PostgreSQL社区合作,积极的跟进其最新的功能。
— MPP数据库的架构问题与未来发展方向 —
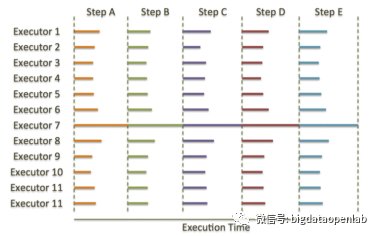
MPP数据库通过并行计算来解决了很多的数据分析的能力问题,不过也有它的架构缺陷,主要包括以下几个问题:数据的分布对业务的性能影响极大:在选择数据分布算法以及对应的分片字段的时候,不仅要考虑数据分布的均匀问题,还需要考虑到业务中对这个表的使用特点。如果多个业务的使用方式有明显差异,往往很难选择一个非常好的表分片字段,因此会导致一些因为数据或业务不均匀分布或跨节点数据shuffle可能引起的性能问题。落后者问题(又称Straggler Node Problem)是MPP数据库的一个重要架构问题。工作负载节点(对GPDB而言是Segment节点)是完全对称的,数据均匀的存储在这些节点,处理过程中每个节点(即该节点上的Executor)使用本地的CPU、内存和磁盘等资源完成本地的数据加工。当某个节点出现问题导致速度比其他节点慢时,该节点会成为Straggler。此时,无论集群规模多大,批处理的整体执行速度都由Straggler决定,其他节点上的任务执行完毕后则进入空闲状态等待Straggler,而无法分担其工作,如下图所示Executor 7即为落后者并最终拖慢了整个集群。当集群规模达到一定程度时,故障会频繁出现使straggler成为一个常规问题。
集群规模问题:由于MPP的“完全对称性”,即当查询开始执行时,每个节点都在并行执行完全相同的任务,这意味着MPP支持的并发数和集群的节点数完全无关。在大数据时代,对于联机查询的并发能力要求增加非常迅速,也极大的挑战了MPP架构本身。此外,MPP架构中的Master节点承担了一定的工作负载,所有联机查询的数据流都要经过该节点,这样Master也存在一定的性能瓶颈。因此很多MPP数据库在集群规模上是存在一定限制的。多租户资源隔离问题是MPP数据库一个非常难解决的一个架构问题。由于一个企业的MPP数据库一般支撑多个业务或多个租户,假如某个业务的部分SQL分析在数据库节点Node 1上产生了热点并占用了该节点绝大部分的资源,从而拖慢了所有的可能使用Node 1的其他租户或业务,导致整体业务服务能力恶化。从我们对行业的一些大型企业客户的调研结果看,这个问题是非常致命的问题,只能通过运维的手段来检测并关闭类似的热点SQL来缓解。更好的支撑AI程序处理半结构化或非结构化数据是MPP数据库的一个重要挑战,尤其是在人工智能相关的需求爆发后,NLP、智能识别等技术都需要有效的半结构化或非结构化数据的存储、检索和计算需求,而这些都不是关系数据库擅长的能力。随着硬件技术的快速发展,尤其是SSD和网络性能的大幅度提升,MPP数据库厂商都开始基于这些新硬件技术来解决当前的软件架构问题,如采用更高速的网络来提升总体的可扩展性,解决集群规模存在上限的问题。另外部分MPP数据库重新设计其执行模式,调整其计算架构同时支持MPP和DAG模式,通过更加的执行计划和Lazy Evaluation方式来解决常见的“落后者”问题。此外,近几年MPP数据库厂商都在推动存算分离架构,让底层可以直接依赖云存储等方式,从而实现云化服务,并以此来实现多租户隔离等管理能力。
— 小结—
本文介绍了分析型数据库MPP数据库,它通过大规模并行的关系数据库的协同来提升数据库能够处理的数据的量级和性能。那么,分析型数据库的另外一个发展方向是以分布式技术来代替MPP的并行计算,一方面比MPP有更好的可扩展性,另一方面可以解决MPP数据库的几个关键架构问题,下篇我们将介绍分布式分析型数据库。