Apache Druid系列博客
- Apache Druid简介
- Apache Druid设计
官方英文原文:Design · Apache Druid
Druid具有分布式的架构,旨在对云友好且易于操作。您能够对服务独立进行配置和扩展,从而在集群操作上面拥有最大的灵活性。这样的设计具有增强的容错能力,一个组件的中断不会立即影响其它的组件。
Druid架构
下图展示了组成Druid架构的服务,包括它们组织成服务器的形式、查询和数据流经架构的方式:
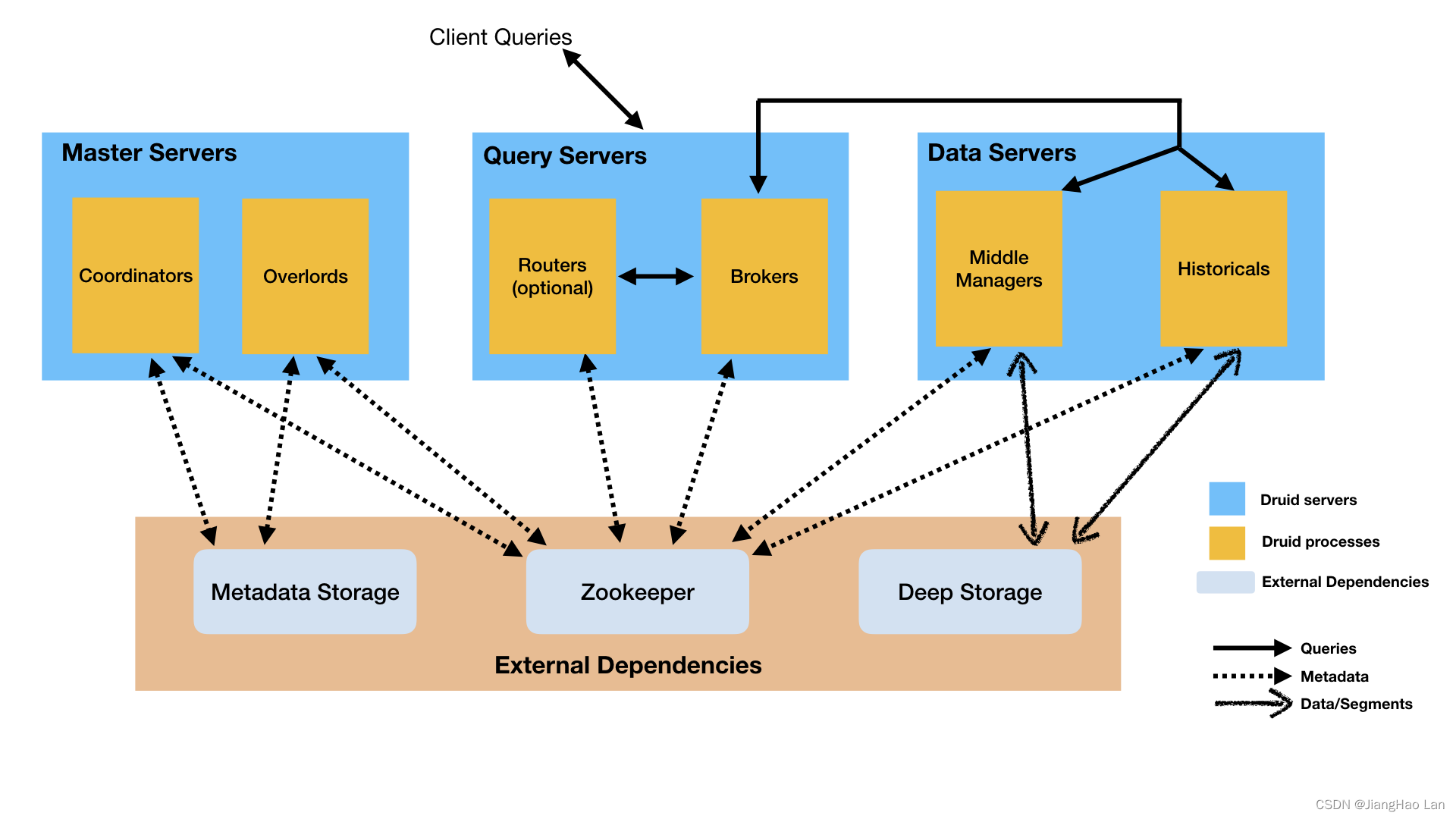
以下部分描述了此架构的组件。
Druid服务
Druid的服务(service)有以下几种类型:
- Coordinator服务:管理集群上数据的可用性
- Overlord服务:控制数据摄取工作负载分配
- Broker服务:处理来自外部客户端的查询
- Router服务:可选的,路由请求到Borker、Coordinator和Overlord。
- Historical服务:存储可查询的数据
- MiddleManager服务:摄取数据
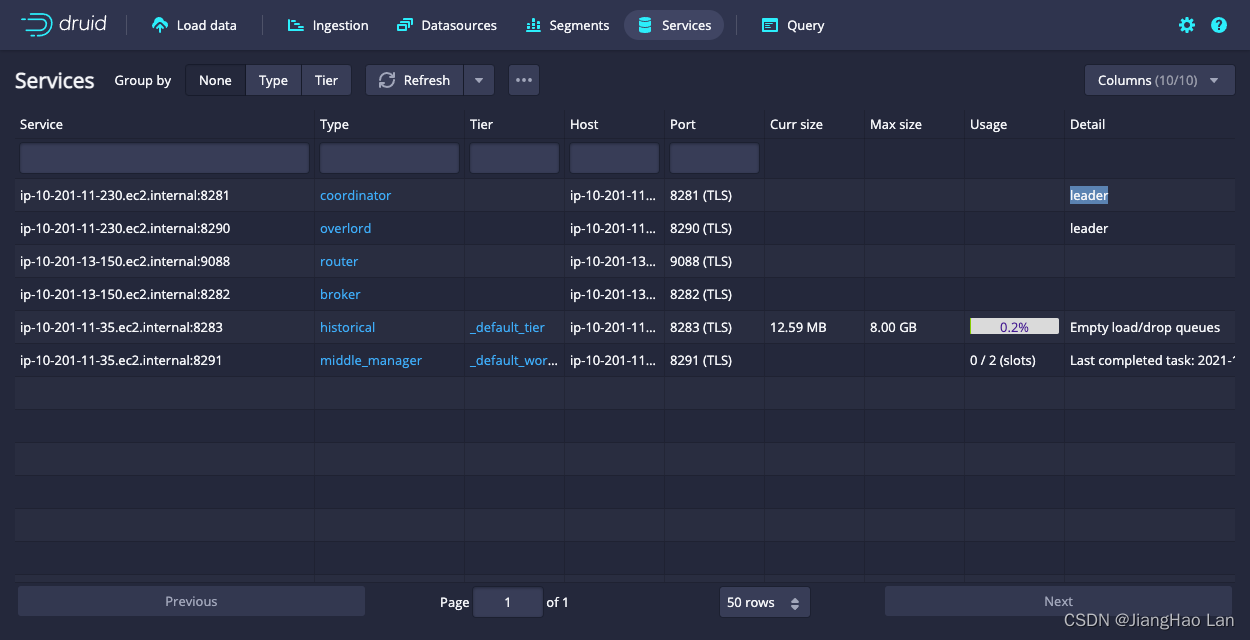
您可以在 Web 控制台的“服务”选项卡中查看服务:
Druid服务器
Druid服务能够以任意方式部署,但为了简单,官方推荐以这三种服务器类型组织它们:Master、Query和Data。
- Master:运行Coordinator和Overlord进程,管理数据的可用性和摄取。
- Query:运行Broker和可选的Router进程,处理来自外部客户端的查询。
- Data:运行Historical和MiddleManager进程,执行摄取的工作负载并存储所有可查询的数据。
可以在 Web 控制台的“服务”选项卡中查看服务:
有关进程和服务器组织的更多详细信息,请参阅 Druid进程和服务器。
外部依赖
除了其内置的进程类型之外,Druid也有三个外部依赖(External dependencies),分别为:深度存储(Deep storage)、元数据存储(Metadata storage)、Zookeeper,这些是为了能够利用现有的基础设施。
深度存储
Druid用深度存储(Deep storage)来存放被摄取到系统中的任意数据。深度存储是能被任何一个Druid服务器访问的共享文件存储。在集群部署中,这通常是分布式对象存储,如S3、HDFS或网络安装的文件系统。
Druid仅将深度存储用作数据的备份,并作为在Druid进程之间在后台传输数据的一种方式。 Druid将数据存放的文件称为段(segment)。Historical进程将数据段缓存在本地磁盘上,并为来自该缓存和内存中缓存的查询提供服务。这就意味着Druid在查询期间不再需要访问深度存储,从而达到最佳的查询延迟。这也意味着在深度存储和所有Historical服务器中都必须有足够的磁盘空间来存储要加载的数据。
深度存储是Druid弹性和容错设计的重要组成部分。即使每一个数据服务器都丢失并重新配置,Druid 也会从深层存储中引导。
有关详细信息,请参阅 深度存储 页面。
元数据存储
元数据存储(Metadata storage)保存各种共享系统元数据,如段使用信息和任务信息。在集群部署中,这通常是传统的关系数据库管理系统(RDBMS),如PostgreSQL或MySQL;在单机部署中,这通常是本地存储的Apache Derby数据库。
有关详细信息,请参阅 元数据存储 页面。
ZooKeeper
用于内部服务发现、协作(coordination)以及选主(leader election)。
有关详细信息,请参阅 ZooKeeper 页面。
Apache Druid系列博客
- Apache Druid简介
- Apache Druid设计