文章目录
前言
怎么才能看出使用cuda编程,提高了程序的性能,一般都是通过比较程序运行的时间来验证。所以熟悉程序的运行时间的计时,可以查看优化的性能效果。
1.CUDA的计时程序
cuda提供了一种基于cuda事件的计时方式,在cuda编程书中介绍了如下的计时程序:
// 定义变量
cudaEvent_t start, stop;
// cudaEventCreate初始化变量
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
// 在计时的代码块之前要记录一个代表开始的事件
CHECK(cudaEventRecord(start));
// 需要添加cudaEventQuery操作刷新队列,才能促使前面的操作在GPU上执行
cudaEventQuery(start); // 不用CHECK,返回值不对但不代表程序出错
// 需要计时的代码块
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
// 在计时的代码块结束要记录一个代表结束的事件
CHECK(cudaEventRecord(stop));
// 要让主机等待事件stop被记录完毕
CHECK(cudaEventSynchronize(stop));
// 计算程序执行的时间差
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
// 销毁start和stop事件
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
2.CUDA程序的计时
重复计时10次,计算平均值和误差。忽略第一次.第一次机器在CPU或者GPU上可能处于预热状态,测得的时间往往偏大.
在前面数组相加的程序里修改:
float t_sum = 0;
float t2_sum = 0;
for (int repeat = 0; repeat <= NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
add<<<grid_size, block_size>>>(d_x, d_y, d_z, N);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
// 忽略第一次.第一次机器可能处于预热状态,测得的时间往往偏大.
if (repeat > 0)
{
t_sum += elapsed_time;
t2_sum += elapsed_time * elapsed_time;
}
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
这里在使用nvcc编译的时候,要在命令行添加-O3指令,是一个优化等级,表示三等级的优化,能够提升c++程序运行的性能。使用优化指令和不用相差比较大,大概2-3倍的样子。
影响GPU加速的关键
在上面的使用计时程序对cuda的核函数计时中,在使用单精度和双精度来对比运行时间,发现在GeForce RTX2080Ti上,双精度是单精度运行时间的差不多两倍关系。
定义使用双精度和单精度浮点数计算的程序:
// 在源程序中使用条件编译,定义双精度和单精度
#ifdef USE_DP
typedef double real; // 给double和float类型取别名,方便直接使用real,后面统一做类型的修改
const real EPSILON = 1.0e-15;
#else
typedef float real;
const real EPSILON = 1.0e-6f;
#endif
在编译时,使用命令行输入-D USE_UP可以指定选择使用双精度浮点数进行计算
使用单精度:
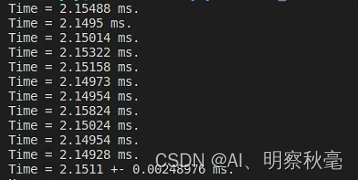
使用双精度:
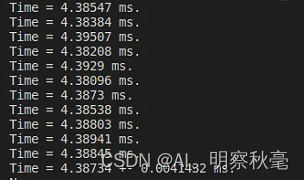
上面的仅仅是计算的核函数里程序的运行时间,没有计算相对于c++程序里的内存分配和数据传递的时间。使用单精度,如果将数据传输的时候开始计时,发现cuda程序耗时显著增加。
运行时间:
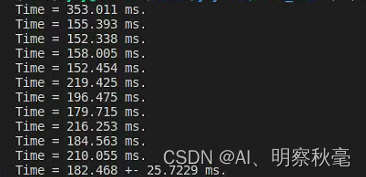
而单单使用cpu的程序,运行时间:
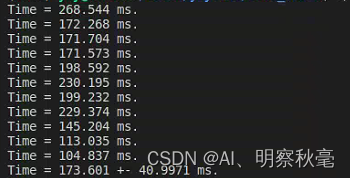
可以发现:
- cuda程序里,数组相加,使用核函数所占的时间比很小,基本都是数据传输消耗了较多的时间。相对于直接使用cpu来说,可能性能得不到提升。
在cuda工具箱中,可以使用nvprof指令,去查看程序各部分执行时间的消耗情况:
 很直观的可以分析出数据传输占据了主要的执行时间,核函数最大消耗的时间才用了2.1864ms占总的时间的0.81%。
很直观的可以分析出数据传输占据了主要的执行时间,核函数最大消耗的时间才用了2.1864ms占总的时间的0.81%。
综上可以发现,数据在主机和设备之间的传输消耗的时间比较大。那为什么说使用cuda性能能得到提升呢?
- 通过核函数的时间对比,可知在GPU上存在很多核心,计算速度要比CPU上快的多。而应该是数组相加这个操作太简单了,所以在直观上体现不了cuda的加速情况。后面通过使用较为复杂的浮点数运算,证明cuda能够很大程度的提升程序的性能。还有就是既然数据传输占总的时间很大,只要在复杂的操作中,开始进行一次的传输,后面尽量避免大数据的传输,就可以获得可观的性能提升。
这里总结一下,影响GPU加速的关键就是两点:
(1)数据传输的比例:多在GPU上进行计算,避免过多的数据传输,数据经过PCIe传递。
(2)浮点数计算的算术强度:复杂的浮点运算选择在GPU上进行。
书中还提到了,不同型号的GPU在单精度和双精度上两者执行时间的比值,对于算术强度较高的问题,在使用双精度浮点运算时,Tesla系列的GPU相对于GeForce系列的GPU更具有优势。在单精度上都产不多,GeForce系列的GPU更具有性价比。
总结
cuda程序执行的计时方式和GPU性能加速的分析
参考:
如博客内容有侵权行为,可及时联系删除!
CUDA 编程:基础与实践
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming