前言
cuda的内存组织,在使用GPU时尽可能提高性能,合理的使用设备的内存也是十分重要的。
CUDA的内存组织
如表所示:
| 内存类型 | 物理位置 | 访问权限 | 可见范围 | 生命周期 |
|---|---|---|---|---|
| 全局内存 | 在芯片外 | 可读可写 | 所有线程和主机端 | 由主机分配和释放 |
| 常量内存 | 在芯片外 | 仅可读 | 所有线程和主机端 | 由主机分配和释放 |
| 纹理和表面内存 | 在芯片外 | 一般仅可读 | 所有线程和主机端 | 由主机分配和释放 |
| 寄存器内存 | 在芯片内 | 可读可写 | 单个线程 | 所在线程 |
| 局部内存 | 在芯片外 | 可读可写 | 单个线程 | 所在线程 |
| 共享内存 | 在芯片内 | 可读可写 | 单个线程块 | 所在线程块 |
全局内存
定义:这里的全局内存,指的是核函数中所有线程都能访问到数据的内存。
作用:保存核函数提供数据,并在主机与设备及设备与设备之间传递数据。
不在GPU芯片上,所以为核函数提供数据时具有较高的延迟和较低的访问速度。
内存容量基本和GPU的显存差不多。
是可读可写的。
动态全局内存变量:前面cuda数组相加的程序中定义的d_x,d_y,d_z就是动态分配的,要先通过cudaMalloc()为其分配设备内存和cudaMemcpy()将主机上的数据传递到设备上,然后在核函数中访问分配的内存和改变其中的数值。
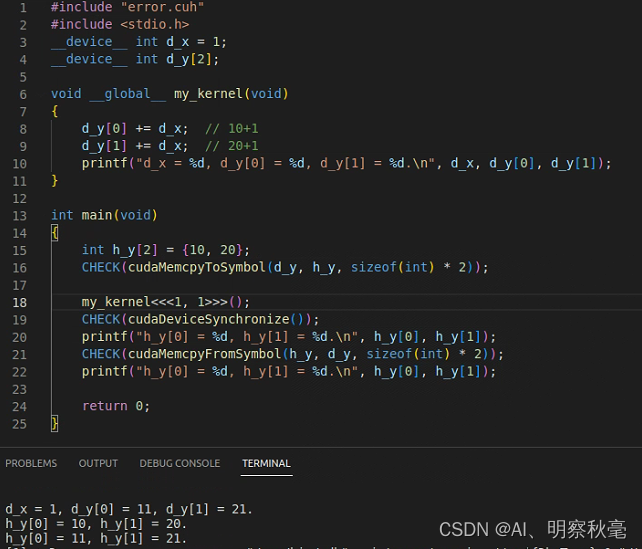
静态全局内存变量:使用cudaMemcpyToSymbol()进行主机与设备之间的数据传输和cudaMemcpyFromSymbol()进行设备与主机之间的数据传输。在核函数中,可直接对静态全局内存变量进行访问,并不需要将它们以参数的形式传给核函数。
由以下方式在函数外部定义
__device__ T x; // 单个变量
__device__ T y[N]; // 固定长度的数组
例子:
常量内存
定义:是有常量缓存的全局内存,数量有限,仅有64kb。
作用:和全局内存一样。
仅可读不可写,而且由于有缓存,常量内存的访问速度比全局内存要高。
使用:cuda数组相加的程序里的const int N,就是使用了常量内存的变量。
纹理内存和表面内存
定义:类似于常量内存
一般仅可读,表面内存也可写。对于计算能力不小于3.5的GPU来说,将某些只读全局内存数据用__ldg()函数通过只读数据缓存读取,既可以达到使用纹理内存的加速效果,又可使代码简洁。
寄存器
定义:在核函数中不加任何限定符的变量一般来说就存放于寄存器中(可能在局部内存中)。
寄存器可读可写。寄存器内存在芯片内,是所有内存中访问速度最高的,但其数量有限。
使用:cuda数组相加的程序里的 int n = blockDim.x * blockIdx.x + threadIdx.x;
其中n就是一个寄存器变量。在核函数中使用z[n] = x[n] + y[n],寄存器变量n并将赋值号右边计算出来的赋值给它。
生命周期与所属线程的生命周期一致,从定义它开始到线程结束。寄存器变量仅仅被一个线程可见,不同的线程中该寄存器变量名一样,但是变量的值是不同的,相当于另外创建了副本。
局部内存
定义:和寄存器几乎一样。
寄存器里放不下的变量可能放在局部内存里,这种判断是由编译器自动做。
共享内存
定义:与寄存器类似,但共享内存对整个线程块可见。
作用:减少对全局内存的访问,或者改善对全局内存的访问模式。
其生命周期与整个线程块一致。
使用:在核函数中要将一个变量定义为共享内存变量,就要在定义语句中加上一个限定符__shared__
__shared__ real s_y[128];
L1和L2缓存
从费米架构开始,有了SM层次的L1缓存(一级缓存)和设备层次的L2缓存(二级缓存)。
主要用来缓存全局内存和局部内存的访问,减少延迟。L1和L2缓存是不可编程的缓存(用户最多能引导编译器做一些选择)。
SM的构成
(1)一定数量的寄存器
(2)一定数量的共享内存
(3)常量内存的缓存
(4)纹理和表面内存的缓存
(5)L1缓存
(6)两个线程束调度器,用于在不同线程的上下文之间迅速切换及为准备就绪的线程束发出执行指令。
(7)执行核心:若干整型数运算的核心,若干单精度浮点数运算的核心,若干双精度浮点数运算的核心,若干单精度浮点数超越函数的特殊函数单元,若干混合精度的张量核心。
API函数查询设备
用一些cuda的api程序来查询设备的一些规格。
#include "error.cuh"
#include <stdio.h>
int main(int argc, char *argv[])
{
// 设置查询的设备编号.
int device_id = 0;
if (argc > 1) device_id = atoi(argv[1]);
// cudaSetDevice()函数将对所指定的设备进行初始化
CHECK(cudaSetDevice(device_id));
// 定义设备输出规格的一些结构体变量
cudaDeviceProp prop;
CHECK(cudaGetDeviceProperties(&prop, device_id)); // 得到了device_id设备的性质,存放在结构体变量中的prop中.
printf("Device id: %d\n",
device_id);
printf("Device name: %s\n",
prop.name);
printf("Compute capability: %d.%d\n",
prop.major, prop.minor);
printf("Amount of global memory: %g GB\n",
prop.totalGlobalMem / (1024.0 * 1024 * 1024));
printf("Amount of constant memory: %g KB\n",
prop.totalConstMem / 1024.0);
printf("Maximum grid size: %d %d %d\n",
prop.maxGridSize[0],
prop.maxGridSize[1], prop.maxGridSize[2]);
printf("Maximum block size: %d %d %d\n",
prop.maxThreadsDim[0], prop.maxThreadsDim[1],
prop.maxThreadsDim[2]);
printf("Number of SMs: %d\n",
prop.multiProcessorCount);
printf("Maximum amount of shared memory per block: %g KB\n",
prop.sharedMemPerBlock / 1024.0);
printf("Maximum amount of shared memory per SM: %g KB\n",
prop.sharedMemPerMultiprocessor / 1024.0);
printf("Maximum number of registers per block: %d K\n",
prop.regsPerBlock / 1024);
printf("Maximum number of registers per SM: %d K\n",
prop.regsPerMultiprocessor / 1024);
printf("Maximum number of threads per block: %d\n",
prop.maxThreadsPerBlock);
printf("Maximum number of threads per SM: %d\n",
prop.maxThreadsPerMultiProcessor);
return 0;
}
查询的一些设备设置:
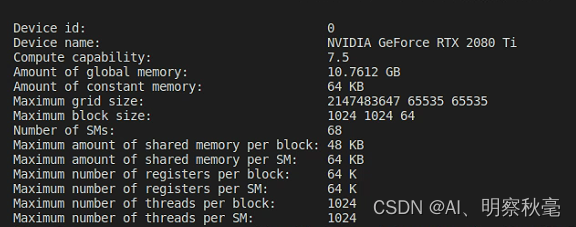
从这些输出可以看出GPU的内存组织,和所占各内存的最大容量大小。
总结
cuda程序执行的计时方式和GPU性能加速的分析
参考:
如博客内容有侵权行为,可及时联系删除!
CUDA 编程:基础与实践
https://docs.nvidia.com/cuda/
https://docs.nvidia.com/cuda/cuda-runtime-api
https://github.com/brucefan1983/CUDA-Programming