文章目录
参考:
教你如何阅读HashMap源码~吊打面试官 - 腾讯云开发者社区-腾讯云 (tencent.com) 有一些面试题
Map - HashSet & HashMap 源码解析 | Java 全栈知识体系 (pdai.tech)
HashMap源码&底层数据结构分析 | JavaGuide(Java面试+学习指南)
hashmap头插法和尾插法区别_一个跟面试官扯皮半个小时的HashMap_牧云君的博客-CSDN博客
HashMap简介
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一,是非线程安全的。
HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。 JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。并且, HashMap 总是使用 2 的幂作为哈希表的大小。
底层数据结构分析
JDK1.8 之前
JDK1.8 之前 HashMap 底层是 数组和链表 结合在一起使用也就是 链表散列。
HashMap在put(K key, V value) 的时候, 得到 key 的 hashCode经过扰动函数处理过后(右移16位)得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的数组(桶)位置(这里的 n 指的是数组的长度),如果数组在当前位置存在元素的话,就判断该元素与要插入元素的key 是否相同,如果相同的话,直接覆盖;不相同就通过拉链法解决冲突。
所谓扰动函数指的就是 HashMap 的 hash() 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法, 换句话说使用扰动函数之后可以减少碰撞。
JDK 1.8 HashMap 的 hash 方法源码:
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- key如果为空的话,直接返回hash为0
- key进行hashcode后得到一个32bit的int,在计算数组的下标时需要和n取余,那么当数组比较小时,只有高位不同的哈希值低位相同,很容易发生哈希碰撞,通过将32个bit中的高位右移16,然后将高位和低位进行异或,就能将高位的影响带给低位,在计算数组下标时高位和低位都可以参与进来,减少哈希碰撞的可能。
对比一下 JDK1.7 的 HashMap 的 hash 方法源码
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
所谓 “拉链法” 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突(已经是经过扰动的hash了),则将冲突的值加到链表中即可。
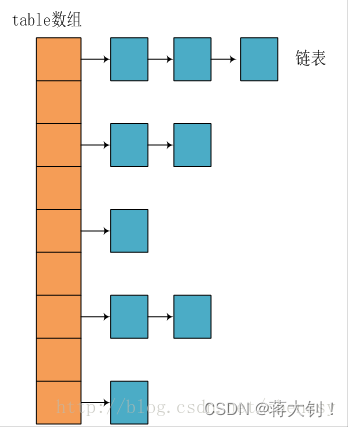
JDK 1.8之后
相比于之前的版本,JDK1.8 以后在解决哈希冲突时有了较大的变化。
当链表长度大于阈值(默认为 8)时,会首先调用 treeifyBin()方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 resize() 方法对数组扩容。相关源码这里就不贴了,重点关注 treeifyBin()方法即可!
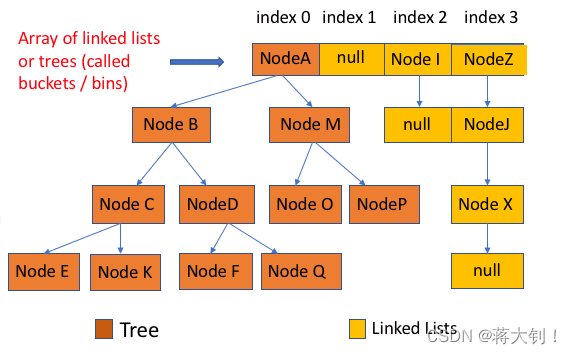
类的属性:
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的填充因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小容量
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值(容量*填充因子) 当实际大小超过临界值时,会进行扩容
int threshold;
// 加载因子
final float loadFactor;
}
- loadFactor 加载因子
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值。
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
- threshold
threshold = capacity * loadFactor,当 Size>=threshold的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 衡量数组是否需要扩增的一个标准。
Node 节点类源码:
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较
final K key;//键
V value;//值
// 指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() {
return key; }
public final V getValue() {
return value; }
public final String toString() {
return key + "=" + value; }
// 重写hashCode()方法
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写 equals() 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
树节点类源码:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
TreeNode<K,V> left; // 左
TreeNode<K,V> right; // 右
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 判断颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// 返回根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
JDK1.8源码分析
构造方法
指定容量和负载因子,数组仍然属于未赋值的状态null,直到第一次put时才创建数组
-
无参构造,指定默认的容量
DEFAULT_INITIAL_CAPACITY为16,默认的负载因子DEFAULT_LOAD_FACTOR为0.75f -
有参构造,按给定的参数指定,但是
tableSizeFor方法会将threshold设置为大于等于initialCapacity的最小二次幂,这也是后面resize方法创建新数组new Node[newCap]指定的大小。
它们分别如下:
// 默认构造函数。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“加载因子”的构造函数,
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
tableSizeFor 方法
指定容量大小initialCapacity的构造函数,将桶数组的大小初始化为大于等于initialCapacity的最小二次幂。
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
putMapEntries 方法:
/**
* Implements Map.putAll and Map constructor.
*
* @param m the map
* @param evict false when initially constructing this map, else true (relayed to method afterNodeInsertion).
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) {
// pre-size
// 未初始化,s为m的实际元素个数
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// 计算得到的t大于阈值,则初始化阈值
if (t > threshold)
threshold = tableSizeFor(t);
}
// 已初始化,并且m元素个数大于阈值,进行扩容处理
else if (s > threshold)
resize();
// 将m中的所有元素添加至HashMap中
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
put 方法
put方法总结下来就是:
- 构造方法只是指定容量和负载因子(空构造器默认容量为16,负载因子为0.75f),数组仍然为
null或者EMPTY_TABLE,直到第一次put时才创建数组。 - put方法要先判断数组是否初始化,未初始化的话先要创建新数组。然后针对其哈希到的tab位置,如果该位置上的链表元素key有和要插入的key完全相同的,直接覆盖,否则进行插入(jdk1.8插入尾部,jdk1.7插入头部)。jdk1.7在插入前判断扩容并重新哈希,jdk1.8在插入后要判断是否要转换成红黑树(不能转换成树就是扩容),然后再判断扩容并重新哈希。
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对 putVal 方法添加元素的分析如下:
-
tab未初始化或者长度为0,进行扩容
-
如果定位到的tab位置没有元素
p = tab[i = (n - 1) & hash]) == null,就直接插入tab[i] = newNode(hash, key, value, null) -
如果定位到的tab位置有元素,它就是数组这个桶中的第一个元素
p,拿它的key和要插入的 key 比较,如果 key 相同,将e = p,后面判断e!=null直接覆盖; -
如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)进入红黑树的处理。 -
如果不是红黑树,就遍历链表,在遍历的过程中找到和要插入的key 相同的元素,将
e = p并break,后面判断e!=null直接覆盖;或者到链表结尾还没找到e==null,那么就插入链表尾部。在此还要判断是否binCount >= TREEIFY_THRESHOLD - 1需要调用红黑树转换的函数treeifyBin(tab, hash)。 -
判断前面是否记录了和要插入key相同的元素,即
e!=null,有的话且onlyIfAbsent=false直接覆盖旧值然后return oldValue.否则就说明前面确实已经加入了一个元素。 -
然后判断整个哈希表的元素是否
size > threshold,如果是则进行扩容并重新哈希
参考:hashmap头插法和尾插法区别_一个跟面试官扯皮半个小时的HashMap_牧云君的博客-CSDN博客
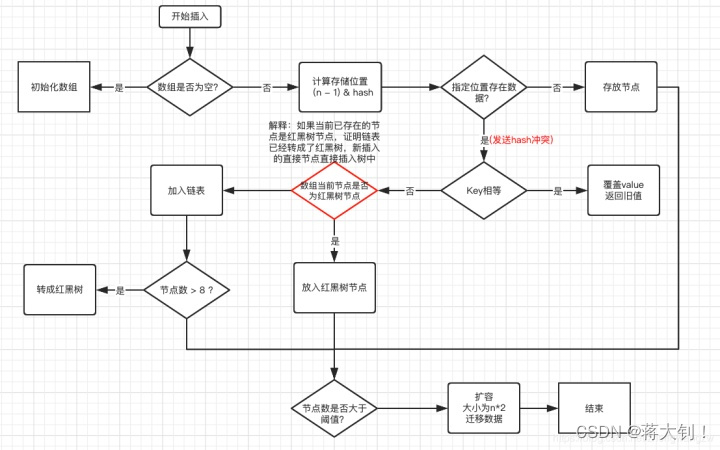
说明:上图有两个小问题:
- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行(issue#608open in new window)。
- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的
treeifyBin()方法(issue#1087open in new window)。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// p当前指向的是(n - 1) & hash后的数组位置,如果为空的话,新生成结点放入桶中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素(处理hash冲突)
else {
Node<K,V> e; K k;
// 先判断该位置的第一个数据和我们要插入的数据,key 是不是"相等",如果是,取出这个节点
// 相等为 扰动后的hash值相同(后面两个条件自动满足了)并且key指向同一对象||key的值相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 第一个数据与要插入的数据不想等,看后面的元素
// 如果该节点代表红黑树的节点,调用红黑树的插值方法
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 链表结点
else {
// 死循环,到链表结尾指甲加入然后break||找到相同的key,e!=null,break
for (int binCount = 0; ; ++binCount) {
// 插入到链表的最后面(Java7 是插入到链表的最前面)
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 插入节点后才转换,算上数组里的为-1也在链表里,链表长度大于8,执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st,0 for e = p.next 2st
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 如果还没到链表末尾,判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 此时 break,那么 e 为链表中[与要插入的新值的 key "相等"]的 node
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// e!=null 说明存在旧值的key与要插入的key"相等"
// 对于我们分析的put操作,下面这个 if 其实就是进行 "值覆盖",然后返回旧值
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null,值覆盖,onlyIfAbsent为true,不覆盖且返回旧值
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 直接返回旧值了,下面不走了
// 存在key相同的算覆盖,不会改变下面的size
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
我们再来对比一下 JDK1.7 put 方法的代码
其是先检查size >= threshold是否需要扩容和重新哈希,再采用头插法加入,而jdk1.8是先插入,当++size > threshold再进行扩容和重新哈希。
对于 put 方法的分析如下:
- 如果数组为空数组
table == EMPTY_TABLE,先采用inflateTable方法进行初始化。 - 然后定位到数组要插入的位置
table[i],遍历挂在它下面的链表。 - 以
table[i]这个元素为链表头,依次和要插入的 key 比较,如果存在 key 相同就直接覆盖并return oldValue; - 如果遍历链表结束都不存在key相同,就调用addEntry方法。
- addEntry方法首先会判断扩容
if ((size >= threshold) && (null != table[bucketIndex]))并重新哈希,再在冲突链表头部插入新的entry头。
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); // 初始化数组
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
// 遍历table[bucketIndex]下的链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
// 遍历这条链表
Object k;
// 如果链表中存在相同的key,覆盖并return oldValue
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
// 覆盖旧值
e.value = value;
e.recordAccess(this);
// 返回旧值
return oldValue;
}
}
modCount++;
// 如果没有相同的key,头部插入
addEntry(hash, key, value, i);
return null;
}
//addEntry()
void addEntry(int hash, K key, V value, int bucketIndex) {
//先扩容,并重新哈希
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = hash & (table.length-1);//hash%table.length
}
//再在冲突链表头部插入新的entry
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
get 方法
- 计算 key 的 hash 值,根据 hash 值找到对应数组下标: hash & (length-1)
- 判断数组该位置处的元素是否刚好就是我们要找的,如果不是,走第三步
- 判断该元素类型是否是 TreeNode,如果是,用红黑树的方法取数据,如果不是,走第四步
- 遍历链表,直到找到相等(==或equals)的 key
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个节点是不是就是需要的
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key); // 找相等
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null); // 找相等
}
}
return null;
}
resize 方法
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
参考 【实战重点】最新JDK18中HashMap的底层源码解析_哔哩哔哩_bilibili
// Cap对应数组buckets大小,newThr=newCap * loadFactor
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值大小对应也扩大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {
// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY; //16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 12
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
// 老数组重新哈希
if (oldTab != null) {
// 把老数组中的数据迁移,一个个遍历数组上的链表
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,直接计算新数组对应下标
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 如果是红黑树,具体我们就不展开了
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况
// 扩容能够将一个链表拆成两个短链表,放到新的数组中,并且保留原来的先后顺序
Node<K,V> loHead = null, loTail = null; // loHead、loTail 对应低位链表
Node<K,V> hiHead = null, hiTail = null; // hiHead、hiTail 对应高位链表
Node<K,V> next;
do {
next = e.next;
// 关键位上与
if ((e.hash & oldCap) == 0) {
// 原来链表上拆出来的低位链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e; // 先将loTail,loTail都指向e,然后loTail往下走
}
else {
// 原来链表上拆出来的高位链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 低位链表的头节点赋值给newTab[j]
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 高位链表的头节点赋值给newTab[j + oldCap]
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
红黑树的resize()
/**
* Splits nodes in a tree bin into lower and upper tree bins,
* or untreeifies if now too small. Called only from resize;
* see above discussion about split bits and indices.
*
* @param map the map
* @param tab the table for recording bin heads
* @param index the index of the table being split
* @param bit the bit of hash to split on
*/
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
// 要统计链表长度,可以整体迁移或者转换成链表
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
// 判断是否要从树变成链表
if (lc <= UNTREEIFY_THRESHOLD) // put和remove在8临界值附近操作的话,红黑树和链表转换太过频繁了
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead; // 如果hiHead == null说明新的高位上没有东西,那么直接把原来的红黑树移过去
if (hiHead != null) // 说明低位链表和原来的树不一样了,重新生成新的红黑树
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
JDK1.7源码与问题分析
Java7 中使用 Entry 来代表每个 HashMap 中的数据节点,Java8 中使用 Node,基本没有区别,都是 key,value,hash 和 next 这四个属性,不过,Node 只能用于链表的情况,红黑树的情况需要使用 TreeNode。
成员变量初始值
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* An empty table instance to share when the table is not inflated.
*/
static final Entry<?,?>[] EMPTY_TABLE = {
};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
基本数据结构
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
构造方法
指定容量和负载因子,数组仍然为EMPTY_TABLE,直到第一次put时才创建数组
-
无参构造,指定默认的容量
DEFAULT_INITIAL_CAPACITY为16,默认的负载因子DEFAULT_LOAD_FACTOR为0.75f -
有参构造,按给定的参数指定,但是后面put的时候
inflateTable(int toSize)方法会将capacity设置为大于等于toSize(initialCapacity)的最小二次幂,threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
init();
}
// 无参数构造
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
put方法
数组+链表的结构
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with <tt>key</tt>, or
* <tt>null</tt> if there was no mapping for <tt>key</tt>.
* (A <tt>null</tt> return can also indicate that the map
* previously associated <tt>null</tt> with <tt>key</tt>.)
*/
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold); // 初始化扩容
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
// 遍历table[bucketIndex]下的链表,判断是否有相同的key
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
// 返回oldValue
return oldValue;
}
}
modCount++;
// 如果不存在相同的key,则尝试头插法
addEntry(hash, key, value, i);
return null;
}
inflateTable函数
/**
* Inflates the table.
*/
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize); // 大于等于toSize(initialCapacity)的最小二次幂
// 如果new HashMap()为空,threshold刚开始为12
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
addEntry方法
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
// 总数目size >= threshold并且要放的位置table[bucketIndex]不为空
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); // resize扩容
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 头插法
createEntry(hash, key, value, bucketIndex);
}
/**
* Like addEntry except that this version is used when creating entries
* as part of Map construction or "pseudo-construction" (cloning,
* deserialization). This version needn't worry about resizing the table.
*
* Subclass overrides this to alter the behavior of HashMap(Map),
* clone, and readObject.
*/
// 头插法的实现
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex]; // 原来的table[bucketIndex]存放的地址
table[bucketIndex] = new Entry<>(hash, key, value, e); // 新元素的next地址为e,同时把新的赋值给table[bucketIndex]
size++;
}
resize方法
void resize(int newCapacity) {
//newCapacity= 2 * table.length
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 生成一个新的数组
Entry[] newTable = new Entry[newCapacity];
// 新旧数组转移
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 新的threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1)
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer方法
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
// 大部分rehash是false
int newCapacity = newTable.length;
// 双重循环转移
for (Entry<K,V> e : table) {
// 遍历数组
while(null != e) {
// 遍历链表
Entry<K,V> next = e.next; // 先记录链表的下一个元素,因为下面新index要改变原来的指向
if (rehash) {
// rehash因为hashSeed在initHashSeedAsNeeded已经被改变了
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity); // 用新数组容量算出来新index,1.8不会死算
e.next = newTable[i]; // 原来的newTable[i]地址给它
newTable[i] = e; // 往下移动
e = next;
}
}
}
initHashSeedAsNeeded方法
和rehash有关
/**
* Initialize the hashing mask value. We defer initialization until we
* really need it.
*/
final boolean initHashSeedAsNeeded(int capacity) {
boolean currentAltHashing = hashSeed != 0; // hashSeed默认为0 false
boolean useAltHashing = sun.misc.VM.isBooted() &&
//ALTERNATIVE_HASHING_THRESHOLD 需要自己在jdk配置,
//默认ALTERNATIVE_HASHING_THRESHOLD_DEFAULT = Integer.MAX_VALUE,很难触发
(capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);// 看数组的容量进行
boolean switching = currentAltHashing ^ useAltHashing; //XOR
if (switching) {
hashSeed = useAltHashing// hashSeed 只有这里改变
? sun.misc.Hashing.randomHashSeed(this)
: 0;
}
return switching;
}
hash方法
/**
* Retrieve object hash code and applies a supplemental hash function to the
* result hash, which defends against poor quality hash functions. This is
* critical because HashMap uses power-of-two length hash tables, that
* otherwise encounter collisions for hashCodes that do not differ
* in lower bits. Note: Null keys always map to hash 0, thus index 0.
*/
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
modCount
Remove()和put方法都会让modCount++,线程不安全
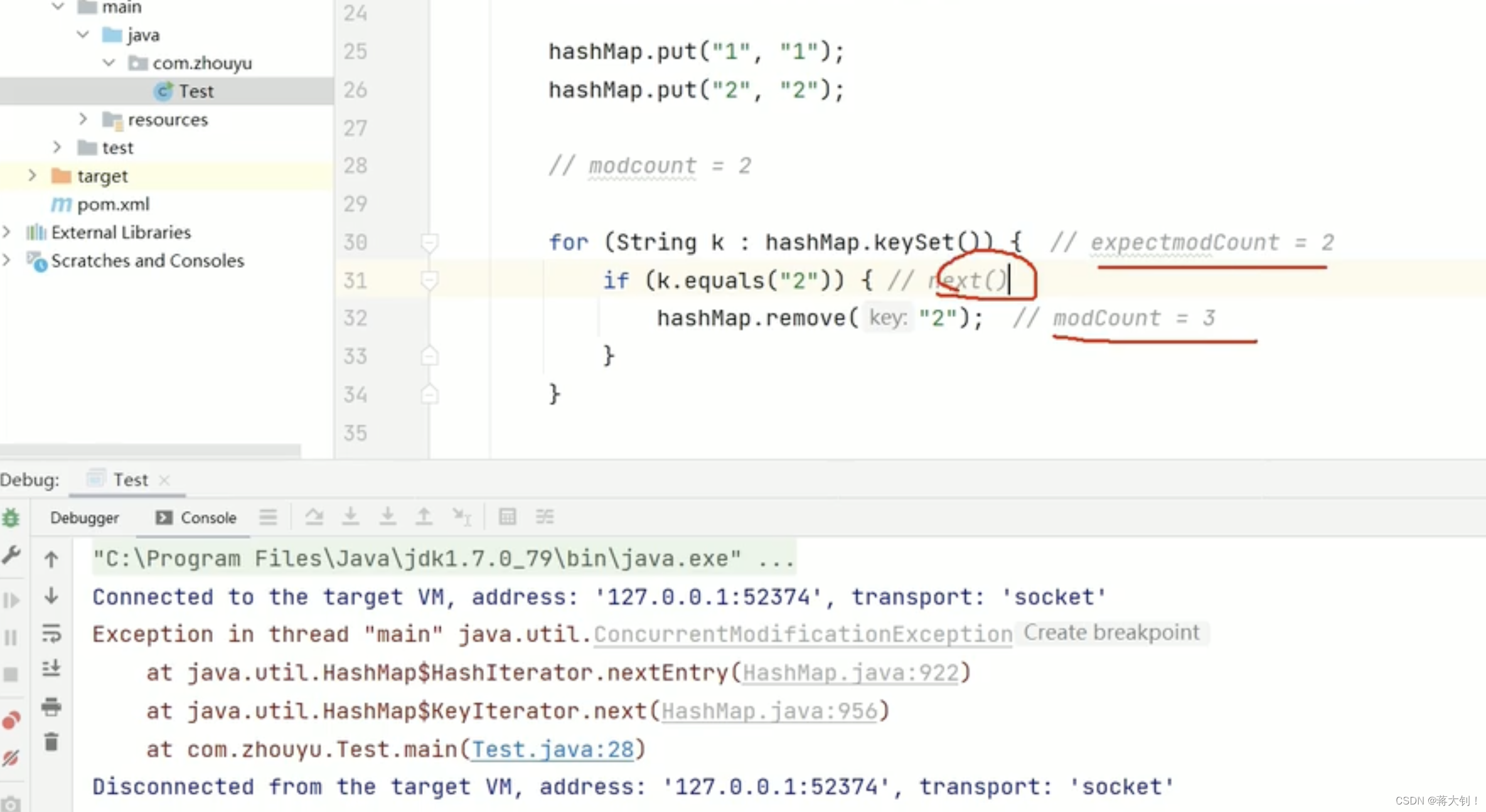
在HashIterator迭代器中
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount) // 该线程要保证modCount == expectedModCount,没有别的线程修改
throw new ConcurrentModificationException();
Entry<K,V> e = next;
if (e == null)
throw new NoSuchElementException();
if ((next = e.next) == null) {
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
current = e;
return e;
}
HashMap线程不安全问题
参考 HashMap为什么线程不安全 - 掘金 (juejin.cn)
JDK1.7
体现在:死循环,数据丢失
原因:JDK1.7 中,由于多线程对HashMap进行扩容,调用了HashMap#transfer(),具体原因:某个线程执行过程中,被挂起,其他线程已经完成数据迁移,等CPU资源释放后被挂起的线程重新执行之前的逻辑,数据已经被改变,造成死循环、数据丢失。
void transfer(Entry[] newTable, boolean rehash) {
// 大部分rehash是false
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
// 遍历数组
while(null != e) {
// 遍历链表
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //指向新容器的第一个元素
newTable[i] = e;//新容器链表头节点指向被迁移节点
e = next; //指向链表的下一个元素
}
}
}
假设现在有两个线程A、B同时对下面这个HashMap进行扩容操作:
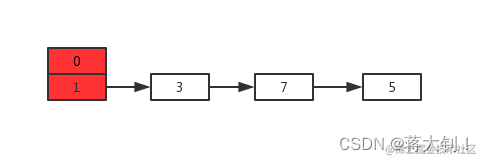
正常扩容后的结果是下面这样的:
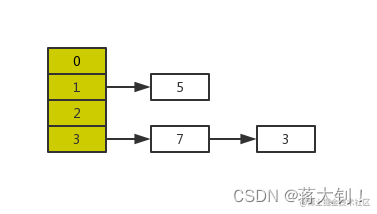
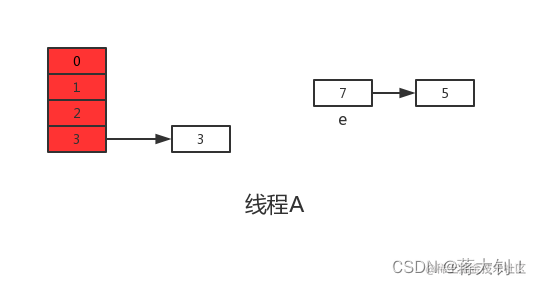
但是当线程A执行到上面transfer函数的第11行代码时,newTable[i] = e还未被执行,CPU时间片耗尽,线程A被挂起。
此时线程A中:e=3、next=7、e.next=null
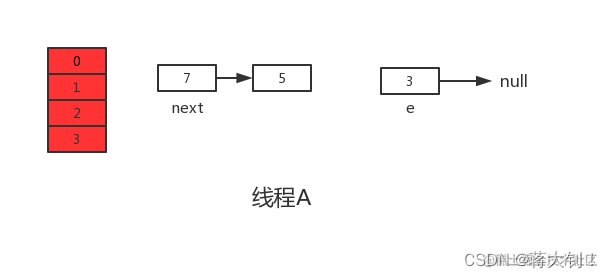
线程A的时间片耗尽后,CPU开始执行线程B,并在线程B中完成了全部的数据迁移
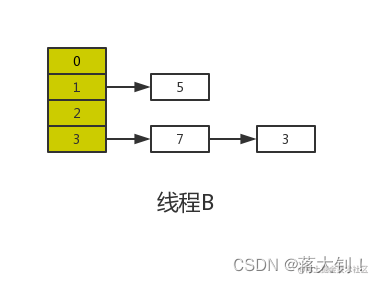
重点来了,根据Java内存模式可知,线程B执行完数据迁移后,此时主内存中newTable和table都是最新的,也就是说:7.next=3、3.next=null。,后面线程A都将用到这样的链表连接,将原来线程A中7.next=5覆盖了。
随后线程A获得CPU时间片继续执行newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
接着继续执行下一轮循环,此时e=7,从主内存中读取e.next时发现主内存中7.next=3,此时next=3,并将7采用头插法的方式放入新数组中,并继续执行完此轮循环,结果如下:
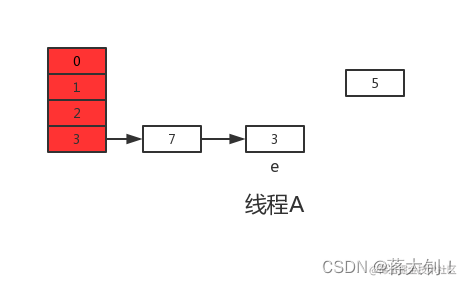
此时没任何问题。
上轮next=3,e=3,执行下一次循环可以发现,3.next=null,所以此轮循环将会是最后一轮循环。
接下来当执行完e.next=newTable[i]即3.next=7后,3和7之间就相互连接了,当执行完newTable[i]=e后,3被头插法重新插入到链表中,执行结果如下图所示:
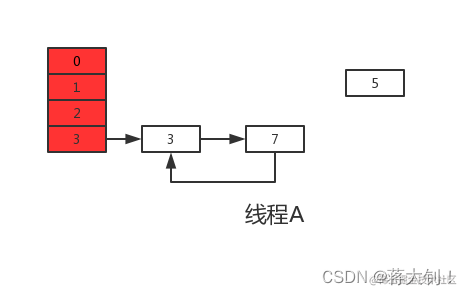
上面说了此时e.next=null即next=null,当执行完e=null后,将不会进行下一轮循环。到此线程A、B的扩容操作完成,很明显当线程A执行完后,HashMap中出现了环形结构,当在以后对该HashMap进行操作时会出现死循环。
并且从上图可以发现,元素5在扩容期间被莫名的丢失了,这就发生了数据丢失的问题。
改善:数据丢失、死循环已经在在JDK1.8中已经得到了很好的解决,如果你去阅读1.8的源码会发现找不到HashMap#transfer(),因为JDK1.8直接在HashMap#resize()中完成了数据迁移。
JDK1.8
体现在:数据覆盖
原因:JDK1.8 中,由于多线程对HashMap进行put操作,调用了HashMap#putVal(),具体原因:假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// p当前指向的是(n - 1) & hash后的数组位置,如果为空的话,新生成结点放入桶中
if ((p = tab[i = (n - 1) & hash]) == null) //多线同时执行完这里
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) // 多个线程走到这,可能重复 resize()
resize();
afterNodeInsertion(evict);
return null;
}
其中第六行代码是判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完第六行代码后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
除此之前,还有就是代码的第38行处有个++size,我们这样想,还是线程A、B,这两个线程同时进行put操作时,假设当前HashMap的zise大小为10,当线程A执行到第38行代码时,从主内存中获得size的值为10后准备进行+1操作,但是由于时间片耗尽只好让出CPU,线程B快乐的拿到CPU还是从主内存中拿到size的值10进行+1操作,完成了put操作并将size=11写回主内存,然后线程A再次拿到CPU并继续执行(此时size的值仍为10),当执行完put操作后,还是将size=11写回内存,此时,线程A、B都执行了一次put操作,但是size的值只增加了1,所以说还是由于数据覆盖又导致了线程不安全。