一、 hashcode是什么?
在HashMap的底层源码实现中,我们常常会看到hashcode,那么这个hashcode到底是什么?
不论是在jdk1.7还是1.8中,计算hash值时都会用到该方法。它是Object类的一个native方法,可以理解为一个底层方法,主要用于返回对象的哈希码,该码与对象存储在jvm的堆地址有关。也就是不重写该方法,不同对象所得到的值不同,源码如下:
public native int hashCode();
二、hash函数是什么?
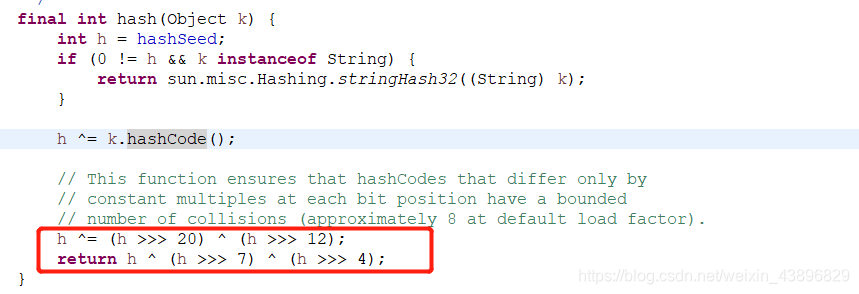
1.jdk1.7的hash函数:
通过源码我们可以看到hash值是与hashcode值进行异或运算,并且通过一系列移位运算所得出来的,这样能得到散列性较好的哈希值
2.jdk1.8的hash函数
从行数就可以看到,jdk1.8中的hash函数简化了不少,其利用hashcode值和移位运算算出hash值

三、如何确定hashmap中的数组下标
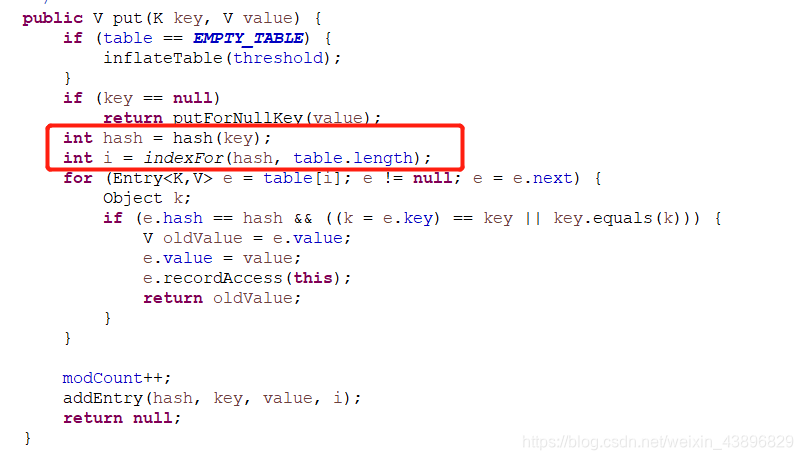
1.先来看看jdk1.7的put函数
数组下标i值的确定是由hash值和indexFor函数共同决定,而在indexFor函数中用的是hash值和数组长度-1的&计算而来

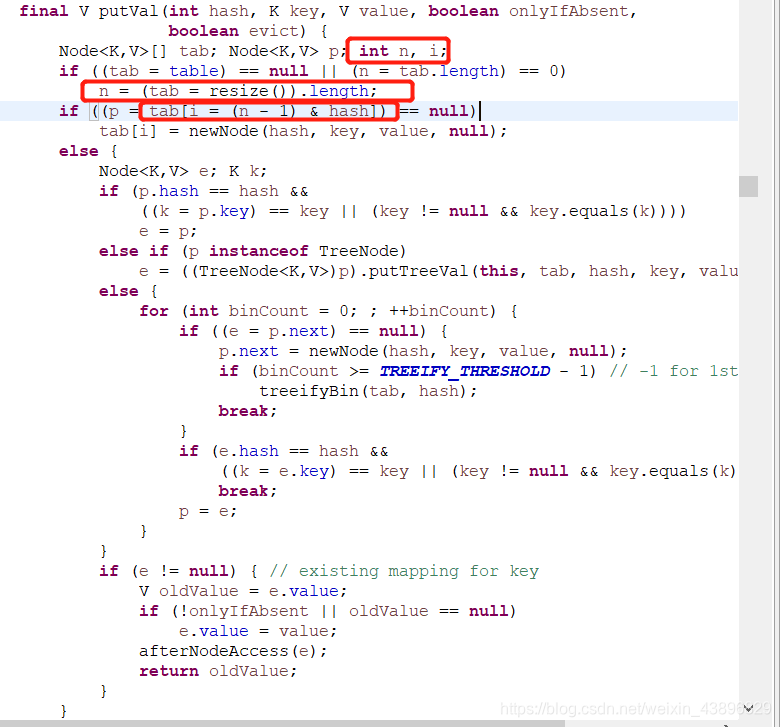
2.jdk1.8的put函数
jdk1.8中调用了putVal函数,其中处理和1.7类似,也是求得数组的长度,后-1与hash值进行&运算得出数组下标
四、那么为什么在计算hash值的时候要用异或(^)运算,不用(&)运算符呢?
在计算hash值的时候我们应该保证hash值越散列越好,试想一下,如果用&运算会怎么?只要该位上是0,那么进行&运算符后得到的结果该位上也一定会是0,那么就会导致一部分数是取不到的,所以散列性会有所下降。
五、为什么要用&(length-1)取得数组下标
我们知道,在HashMap中的容量为2的幂次,那么换算为二进制则最后一位肯定为0,那么length-1则能保证该二进制为高位为0,低位均为1(如16:0001 0000 (16-1):0000 1111)所以按位与能保证hashcode值低位的散列性,从而使整个数组,对象的存储更能利用整个数组,减少hash冲突。而且使用&,能保证算出来的下标不越界,因为数组长度转换为二进制高位都为0,进行&运算后,得到的数高位也一定为0,这就保证了数组不越界。
六、为什么进行移位运算?
移位是为了让hashcode的高位也参与运算,从而让整个结果的散列性更好。
七、那么问题又来了,既然这么绞尽脑汁地留下hashcode值的散列性,为什么不直接用hashcode参与运算计算数组下标,而还要用hashcode值计算hash值后再去求数组下标呢?
别忘了,HashMap的容量可不是一尘不变的,当HashMap扩容的时候,我们需要充分地利用新数组地空间,那么也就是要求数组中地元素重新分布,由于hashcode地值与存储地址有关,那么只要元素不变,那么他们在数组中的位置也就不会变化,而加入数组长度来来计算hash值,则是为了让扩容时,数组容量改变,hash值也就改变,进而元素在数组中的位置也就会重新变化。
总结:
jdk1.7HashMap底层实现使用数组+链表,而jdk1.8底层实现使用数组+链表+红黑树(链表长度为8时转为红黑树)
jdk1.7HashMap在添加链表时用的是头插法,jdk1.8使用的是尾插法
