A Review of Speaker Diarization- Recent Advances with Deep Learning 综述 ——简化&翻译
论文:A Review of Speaker Diarization- Recent Advances with Deep Learning
Speaker Diarization:SD
- 定义:SD 的目标(任务)是,用于与说话人身份相对应的类别标记音频或视频记录,简而言之,是一项识别“谁在何时说话”的任务
- 本文:
- 回顾 SD 技术的历史发展和基于神经网络的SD最新进展
- 讨论 SD 和 下游任务如 ASR 进行集成
Introduction
在 Diarization 的过程中,音频数据将被分割和聚类成具有相同说话者身份/标签的语音段组,通常此过程不需要任何关于说话人的先验知识。
传统的 SD 由多个独立子模块构成:
前端处理包括 语音增强、去混响、语音分离、目标说话人提取等,VAD 用于分离静音段,然后将原始音频转换成声学特征或embedding向量,在聚类阶段,转换后的语音段用于分组和加标签,然后进行精调,上面的每个子模块都独立训练优化。
SD 的历史发展
- 早期使用广义似然比 GRL、贝叶斯信息准则二(BIC)用于说话人改变点检测和聚类语音片段之间的距离
- 改进的方法包括 波束成形、信息瓶颈聚类(IBC)、变分贝叶斯(VB)、联合因子分析(JFA)等
- i-vector 提出以后,成功取代了 MFCC等特征,并和 PCA、VB-GMM、PLDA等进行结合
- 往后就是用神经网络进行说话人embedding 的提取,如 d-vector、x-vector等
- 端到端的 neural diarization 将传统的 SD 的各个模块用一个神经网络来替代,很有前景
动机
论文 An overview of automatic speaker diarization systems(2016),概述了广播新闻和 CTS数据中的不同的SD系统和子任务,cover 了 1990s 和 2000s 早期这一时间段。
论文 Speaker diarization: A review of recent research(2012)重点更多地放在会议演讲的 SD 及其各自的挑战上。
本文更重视在会议环境下,缓解问题的一些技术。在会议环境中,参与者通常比广播新闻或CTS数据多,并且多模态数据经常可用。
SD 概述和分类
基于两个标准进行四分类: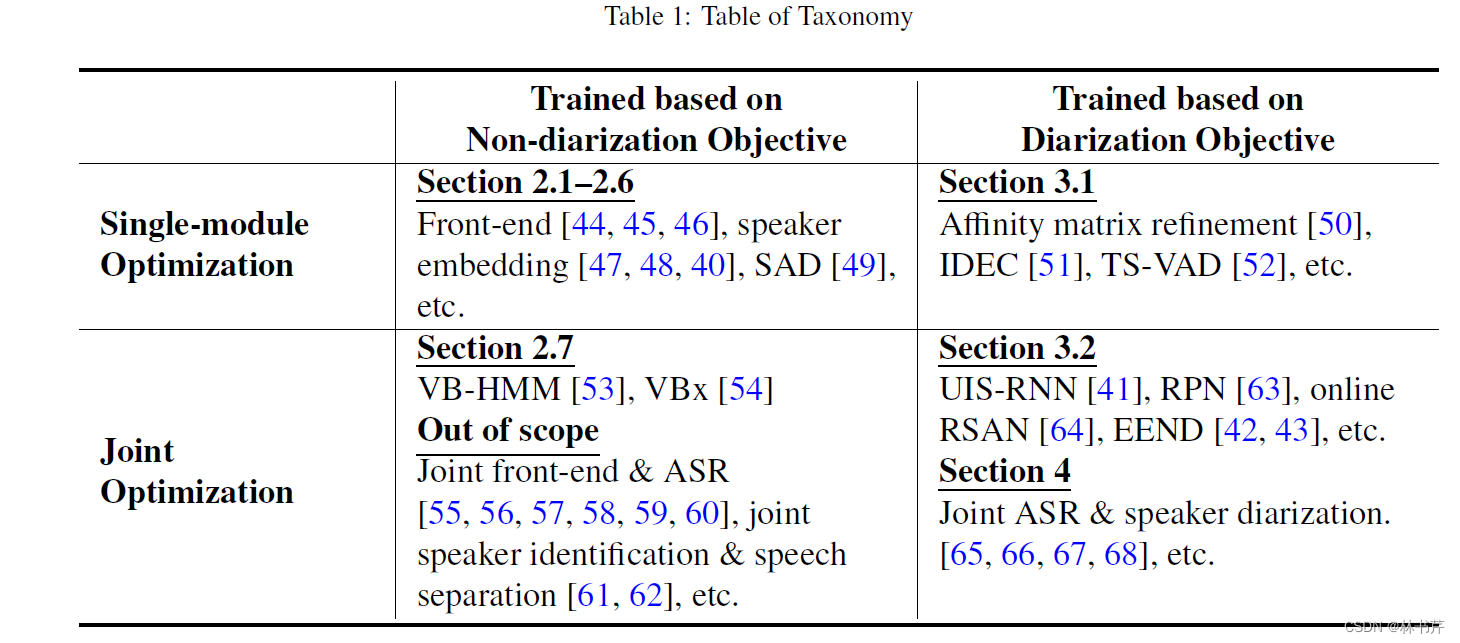
标准1:SD 模型是否基于 SD 目标函数进行训练
标准2:多个模块是否针对某个目标函数联合优化
Diarization 评估指标
- Diarization Error Rate: D E R = FA + Missed + Speaker-Confusion Total Duration of Time \mathbf{D E R}=\frac{\text { FA }+\text { Missed }+\text { Speaker-Confusion }}{\text { Total Duration of Time }} DER= Total Duration of Time FA + Missed + Speaker-Confusion 为了实现一对一的映射,采用了 Hungarian 算法。
- Jaccard Error Rate: J E R = 1 N ∑ i N ref F A i + M I S S i T O T A L i \mathbf{J E R}=\frac{1}{N} \sum_i^{N_{\text {ref }}} \frac{\mathrm{FA}_{\mathrm{i}}+\mathrm{MISS}_{\mathrm{i}}}{\mathrm{TOTAL}_{\mathrm{i}}} JER=N1i∑Nref TOTALiFAi+MISSi首先计算每个说话人的错误率,然后取平均值以计算JER.
DER 可能超过 100%。JER 不可能。
- Word-level Diarization Error Rate:测量在词汇方面引起的错误
SD 系统的各个模块
本节概述了属于在非 SD 目标下训练的 SD 算法。也就是每个独立模块的原理啦~
前端处理
首先设 s i , f , t ∈ C s_{i, f, t} \in \mathbb{C} si,f,t∈C 是说话人 i i i 在频率 bin f f f 和时间 t t t 下的 STFT 特征,则噪声可以表示为源信号、脉冲响应 h i , f , t ∈ C h_{i, f, t} \in \mathbb{C} hi,f,t∈C 和加性噪声 n t , f ∈ C n_{t, f} \in \mathbb{C} nt,f∈C 的混合: x t , f = ∑ i = 1 K ∑ τ h i , f , τ s i , f , t − τ + n t , f x_{t, f}=\sum_{i=1}^K \sum_\tau h_{i, f, \tau} s_{i, f, t-\tau}+n_{t, f} xt,f=i=1∑Kτ∑hi,f,τsi,f,t−τ+nt,f其中, K K K 表示音频中说话人的数量。
前端处理的目标是,给定观测信号 X = ( { x t , f } f ) t \mathbf{X}=\left(\left\{x_{t, f}\right\}_f\right)_t X=({ xt,f}f)t 来估计原始信号 x ^ i , t \hat{\mathbf{x}}_{i, t} x^i,t : x ^ i , t = FrontEnd ( X ) , i = 1 , … , K \hat{\mathbf{x}}_{i, t}=\operatorname{FrontEnd}(\mathbf{X}), \quad i=1, \ldots, K x^i,t=FrontEnd(X),i=1,…,K其中, x ^ i , t ∈ C D \hat{\mathbf{x}}_{i, t} \in \mathbb{C}^D x^i,t∈CD 表示第 i i i 个说话人的估计 STFT 特征。
语音增强和降噪
语音增强用于抑制含噪语音的噪声分量,基于 LSTM 的语音增强法为: x ^ t = LSTM ( X ) \hat{\mathbf{x}}_t=\operatorname{LSTM}(\mathbf{X}) x^t=LSTM(X)这是一种基于回归的方法,通过最小化 L M S E = ∥ s t − x ^ t ∥ 2 \mathcal{L}_{\mathrm{MSE}}=\left\|\mathbf{s}_t-\hat{\mathbf{x}}_t\right\|^2 LMSE=∥st−x^t∥2 来实现, s t \mathbf{s}_t st 通常是对数似然谱。
去混响
去混响是基于统计信号处理方法实现的。最广泛使用的方法是基于加权预测误差(WPE)的去混响,通过将原始信号 分解成早期响应和后期混响两个部分: x t , f = ∑ τ h f , τ s f , t − τ = x t , f early + x t , f late x_{t, f}=\sum_\tau h_{f, \tau} s_{f, t-\tau}=x_{t, f}^{\text {early }}+x_{t, f}^{\text {late }} xt,f=τ∑hf,τsf,t−τ=xt,fearly +xt,flate WPE 估计滤波器系数 h ^ f , t w p e ∈ C \hat{h}_{f, t}^{\mathrm{wpe}} \in \mathbb{C} h^f,twpe∈C ,基于 MLE 保留早期响应同时压缩后期混响: x ^ t , f e a r l y = x t , f − ∑ τ = Δ L h ^ f , τ w p e x f , t − τ \hat{x}_{t, f}^{\mathrm{early}}=x_{t, f}-\sum_{\tau=\Delta}^L \hat{h}_{f, \tau}^{\mathrm{wpe}} x_{f, t-\tau} x^t,fearly=xt,f−τ=Δ∑Lh^f,τwpexf,t−τ其中, Δ \Delta Δ 表示要分离的帧数, L L L 表示滤波器的大小。
WPE 的优点在于,他基于线性滤波,不会引入信号失真,可以放心地用在下游任务中。
语音分离
基于波束成形的多通道语音分离的有效性已得到广泛证实。如,在CHiME-6挑战中,基于引导源分离(GSS)的多通道语音提取技术实现了最佳结果。
而单通道的语音分离现实的多说话人场景中通常没有表现出任何显著的效果。单声道语音分离系统通常为非重叠区域产生冗余的非语音或重复的语音信号,因此音频的“泄漏”导致许多误警。
有论文提出了一种泄漏过滤方法来解决该问题,采用该方法后,观察到 SD的性能显著提高。
VAD
VAD: 将语音与背景噪声等非语音区分开来。
SAD系统主要由两个主要部分组成。一是前端特征提取,常用声学特征,如过零率、音调、信号能量、线性预测编码残差域中的高阶统计量或MFCC等。二是分类器,预测输入帧是否包含语音。分类器有传统的基于GMM、HMM的模型,也有基于 DNN、CNN、LSTM 的模型。
VAD 的性能很大程度上影响了 SD 的性能,因为它可能会产生大量的假阳性静音段(就是明明是静音段但是没有判别出来)或丢失一些语音片段。
SD 任务中常见的做法是,使用“oracle VAD”的设置来报告DER,表明系统输出是使用和 GT 相同的 VAD 的输出。
分割
SD 的背景下,语音分割是将输入音频分成多个片段以获得说话人统一的片段。因此,SD 系统的输出单元通过分割过程来确定,用于 SD 的语音分割分为两大类:
- Segmentation by speaker-change point detection 基于说话人变化点检测的分割
- uniform segmentation 均匀分割
基于说话人变化点检测的分割是早期 SD 系统的标准。通过两个假设来检测说话人的变化点:H0 假设左和右语音窗口来自同一说话人,而H1假设来自不同的说话人。采用基于测度的方法进行假设检验,首先认为语音特征符合高斯分布 N ( μ , Σ ) \mathcal{N}(\mu, \Sigma) N(μ,Σ) ,则两个假设可以表示为: H 0 : x 1 ⋯ x N ∼ N ( μ , Σ ) H 1 : x 1 ⋯ x i ∼ N ( μ 1 , Σ 1 ) x i + 1 ⋯ x N ∼ N ( μ 2 , Σ 2 ) \begin{aligned} H_0: & \mathbf{x}_1 \cdots \mathbf{x}_N \sim \mathcal{N}(\mu, \Sigma) \\ H_1: & \mathbf{x}_1 \cdots \mathbf{x}_i \sim \mathcal{N}\left(\mu_1, \Sigma_1\right) \\ & \mathbf{x}_{i+1} \cdots \mathbf{x}_N \sim \mathcal{N}\left(\mu_2, \Sigma_2\right) \end{aligned} H0:H1:x1⋯xN∼N(μ,Σ)x1⋯xi∼N(μ1,Σ1)xi+1⋯xN∼N(μ2,Σ2)其中, ( x i ∣ i = 1 , ⋯ , N ) \left(\mathbf{x}_i \mid i=1, \cdots, N\right) (xi∣i=1,⋯,N) 为语音特征序列。那么可用的测度包括 Kullback-Leibler(KL)距离、广义似然比(GLR)和 BIC。
其中 BIC 最常用,来自两个假设的两个模型之间的BIC值表示如下: B I C ( i ) = N log ∣ Σ ∣ − N 1 log ∣ Σ 1 ∣ − N 2 log ∣ Σ 2 ∣ − λ P B I C(i)=N \log |\Sigma|-N_1 \log \left|\Sigma_1\right|-N_2 \log \left|\Sigma_2\right|-\lambda P BIC(i)=Nlog∣Σ∣−N1log∣Σ1∣−N2log∣Σ2∣−λP其中, P P P 为惩罚项, P = 1 2 ( d + 1 2 d ( d + 1 ) ) log N P=\frac{1}{2}\left(d+\frac{1}{2} d(d+1)\right) \log N P=21(d+21d(d+1))logN , d d d 表示特征的维度, N = N 1 + N 2 N=N1+N2 N=N1+N2 分别代表帧长, λ = 1 \lambda=1 λ=1 ,当下式为成立时,位置 i i i 被认为是变化点: { max i B I C ( i ) } > 0 \left\{\max _i B I C(i)\right\}>0 {
imaxBIC(i)}>0
通常来说,采用基于说话人变化点检测的分割段的长度不一致。
而随着 x-vector 和基于 DNN 的 embedding 的提出,逐渐采用了 均匀分割 方法。因为通过分割长度不同的话,这种差异可能降低说话人表征的“保真度”。
在均匀分割中,给定的音频输入以固定的窗口长度和重叠长度进行分割。但是不同分割段的长度的选取是一个需要权衡考虑的问题:
- 需要足够短,以至于不会包含多个说话人
- 但是又不能太短导致无法捕获到足够的声学特从而无法提取可靠的说话人表示
说话人表征和相似度测量
说话人表征对于SD系统测量语音段之间的相似性起着至关重要的作用
基于测度的相似性度量
用于语音分割的方法也被用在了测量语音段的相似度上,如 KL距离、GLR、BIC等。
与分段的情况一样,基于BIC的方法,其中两个分段之间的相似性也由上面的式子算,由于其有效性和易实现性,是最广泛使用的度量之一。
基于测度的相似性度量通常和基于说话人变化点检测的分割方法一起使用。
联合因子分析(JFA) i-vector 和 PLDA
GMM-UBM 之前被成功应用于说话人验证任务中。UBM 由一个很大的 GMM 组成,训练后用于表示声学特征的说话人相关分布。但基于GMM-UBM的说话人验证系统存在会话间的可变性问题。
JFA 通过单独建模说话人间可变性和信道可变性来补偿可变问题。JFA 采用 GMM 超向量,是自适应GMM的 concatenated mean,例如,说话人独立的 GMM 均值向量 m c ∈ R F × 1 m_c \in \mathbb{R}^{F\times 1} mc∈RF×1 ,则 超向量(supervector) M M M 为: M = [ m 1 t , m 2 t , … , m C t ] t \mathbf{M}=\left[m_1^t, m_2^t, \ldots, m_C^t\right]^t M=[m1t,m2t,…,mCt]t
在 JFA 中,GMM超向量被分解为说话人无关、说话人相关、信道相关和残差分量四个部分: M J = m J + V y + U x + D z \mathbf{M}_J=\mathbf{m}_J+\mathbf{V} \mathbf{y}+\mathbf{U} \mathbf{x}+\mathbf{D} \mathbf{z} MJ=mJ+Vy+Ux+Dz其中, m J \mathbf{m}_J mJ 是说话人无关的超向量, V V V 为说话人相关矩阵, U U U 为信道相关矩阵, D D D 为说话人相关残差矩阵,向量 y \mathbf{y} y 表示说话人因子, x \mathbf{x} x 表示信道因子, z \mathbf{z} z 表示特定说话人的残差因子,所有的向量都满足 N ( 0 , 1 ) N(0,1) N(0,1) 的先验分布。
Dehak等人提出了一种通过总变化矩阵将信道和说话人空间组合成组合变化空间,并将其记为 T \mathbf{T} T ,对应的权重向量 w \mathbf{w} w 被称为 i-vector,被认为是说话人表征向量,此时 M \mathbf{M} M 可以表示为: M I = m I + T w \mathbf{M}_I=\mathbf{m}_I+\mathbf{T} \mathbf{w} MI=mI+Tw其中, m I \mathbf{m}_I mI 为说话人独立和信道独立的超向量。
提取 i-vector 的过程为 MAP 估计问题,使用UBM、平均超向量和从EM算法中训练的总变化矩阵 T \mathbf{T} T 提取的Baum–Welch统计量作为参数。
i-vector 不仅被用于说话人识别研究,还被用于许多 SD 研究,并且与基于测度的方法(如BIC、GLR和KL)相比,表现出了优越的性能。
使用后端处理(如线性判别分析(LDA)和类内协方差归一化(WCCN))进一步补偿了 i-vector 方法中的 Intersession variability,然后计算余弦相似度得分,后来又被概率 LDA(PLDA)模型取代。
G-PLDA 应用 i-vector 高斯化并在 PLDA 中生成高斯假设,最初是被用于说话人验证的。 通常,PLDA 对第 j j j 条语音(会话)中的第 i i i 个说话人的表征 ϕ i j \phi_{ij} ϕij 建模如下: ϕ i j = μ + F h i + G w i j + ϵ i j \phi_{i j}=\mu+\mathbf{F h}_i+\mathbf{G w}_{i j}+\epsilon_{i j} ϕij=μ+Fhi+Gwij+ϵij其中, μ \mathbf{\mu} μ 是均值向量, F \mathbf{F} F 为说话人变化矩阵, G \mathbf{G} G 为信道变化矩阵, ϵ i j \epsilon_{ij} ϵij 代表残差成分。 h i , w i j \mathbf{h}_i, \mathbf{w}_{ij} hi,wij 为符合高斯分布的隐变量,训练过程中, μ , Σ , F , G \mu, \boldsymbol{\Sigma}, \mathbf{F}, \mathbf{G} μ,Σ,F,G 使用 EM 算法进行估计,同时检验两个假设:
- H 0 H_0 H0 两个样本来自相同的说话人
- H 1 H_1 H1 两个样本来自不同的说话人
在假设 H 0 H_0 H0 下,两个本的说话人表征 ϕ 1 , ϕ 2 \phi_1,\phi_2 ϕ1,ϕ2 通过公共隐变量 h 12 \mathbf{h}_{12} h12 建模为: [ ϕ 1 ϕ 2 ] = [ μ μ ] + [ F G 0 F 0 G ] [ h 12 w 1 w 2 ] + [ ϵ 1 ϵ 2 ] \left[\begin{array}{l} \phi_1 \\ \phi_2 \end{array}\right]=\left[\begin{array}{l} \boldsymbol{\mu} \\ \boldsymbol{\mu} \end{array}\right]+\left[\begin{array}{lll} \mathbf{F} & \mathbf{G} & 0 \\ \mathbf{F} & 0 & \mathbf{G} \end{array}\right]\left[\begin{array}{l} \mathbf{h}_{12} \\ \mathbf{w}_1 \\ \mathbf{w}_2 \end{array}\right]+\left[\begin{array}{l} \epsilon_1 \\ \epsilon_2 \end{array}\right] [ϕ1ϕ2]=[μμ]+[FFG00G]⎣⎡h12w1w2⎦⎤+[ϵ1ϵ2]
在假设 H 1 H_1 H1 下,则通过不同的隐变量 h 1 , h 2 \mathbf{h}_1,\mathbf{h}_2 h1,h2 建模: [ ϕ 1 ϕ 2 ] = [ μ μ ] + [ F G 0 0 0 0 F G ] [ h 1 w 1 h 2 w 2 ] + [ ϵ 1 ϵ 2 ] \left[\begin{array}{l} \phi_1 \\ \phi_2 \end{array}\right]=\left[\begin{array}{l} \boldsymbol{\mu} \\ \boldsymbol{\mu} \end{array}\right]+\left[\begin{array}{cccc} \mathbf{F} & \mathbf{G} & \mathbf{0} & 0 \\ 0 & 0 & \mathbf{F} & \mathbf{G} \end{array}\right]\left[\begin{array}{c} \mathbf{h}_1 \\ \mathbf{w}_1 \\ \mathbf{h}_2 \\ \mathbf{w}_2 \end{array}\right]+\left[\begin{array}{c} \epsilon_1 \\ \epsilon_2 \end{array}\right] [ϕ1ϕ2]=[μμ]+[F0G00F0G]⎣⎢⎢⎡h1w1h2w2⎦⎥⎥⎤+[ϵ1ϵ2]
在 G-PLDA 中,假设 ϕ \phi ϕ 来自于高斯分布,从而有: p ( ϕ ∣ h , w ) = N ( ϕ ∣ μ + F h + G w , Σ ) p(\phi \mid \mathbf{h}, \mathbf{w})=\mathbf{N}(\phi \mid \boldsymbol{\mu}+\mathbf{F h}+\mathbf{G} \mathbf{w}, \mathbf{\Sigma}) p(ϕ∣h,w)=N(ϕ∣μ+Fh+Gw,Σ)
基于上面这些公式,计算对数似然比为: s ( ϕ 1 , ϕ 2 ) = log p ( ϕ 1 , ϕ 2 ∣ H 0 ) − log p ( ϕ 1 , ϕ 2 ∣ H 1 ) s\left(\phi_1, \phi_2\right)=\log p\left(\phi_1, \phi_2 \mid H_0\right)-\log p\left(\phi_1, \phi_2 \mid H_1\right) s(ϕ1,ϕ2)=logp(ϕ1,ϕ2∣H0)−logp(ϕ1,ϕ2∣H1)
在说话人验证中,通过判断似然比的正负来选择接受假设 H 0 H_0 H0 还是 H 1 H_1 H1 。在 SD 中, s ( ϕ 1 , ϕ 2 ) s\left(\phi_1, \phi_2\right) s(ϕ1,ϕ2) 检查两个聚类之间的相似度。
基于神经网络的说话人表征
DNN 在不指定任何因子的情况下自动学习映射,其可解释性不如 JFA。
基于 DNN 提取说话人表征不需要预定义模型(如 GMM-UBM)。
在推理阶段效率比 JFA 的高,不涉及矩阵求逆操作。
最经典的是 d-vector 方法,采用包括上下文帧作为输入特征的堆叠滤波器组特征,使用交叉熵损失训练多个全连接层,从最后一个全连接层获得 d-vector: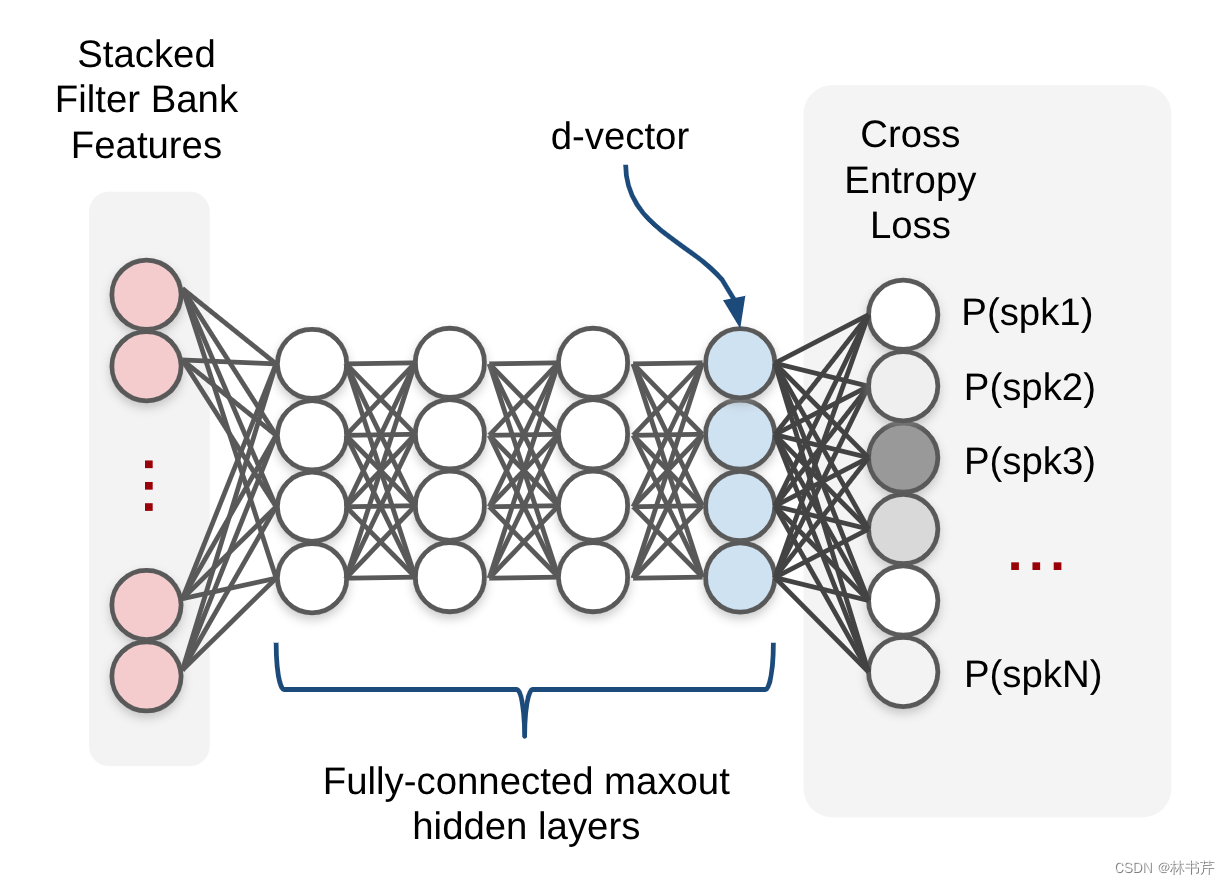
x-vector 进一步改进了说话人表征。时延架构和 statistics pooling 层将 x-vector与d-vector 区分开来。statistics pooling 层聚合前一层的帧级输出,并计算其平均值和标准差,传递给下一层。因此,它可以允许从可变长度输入中提取x-vector:
聚类
聚类算法基于前一节中得到的说话人表征和相似性度量对语音片段进行聚类
聚合层次聚类(AHC)
是一个自底向上的聚类,从单个数据开始,每一步合并相似度最高的聚类,迭代进行合并: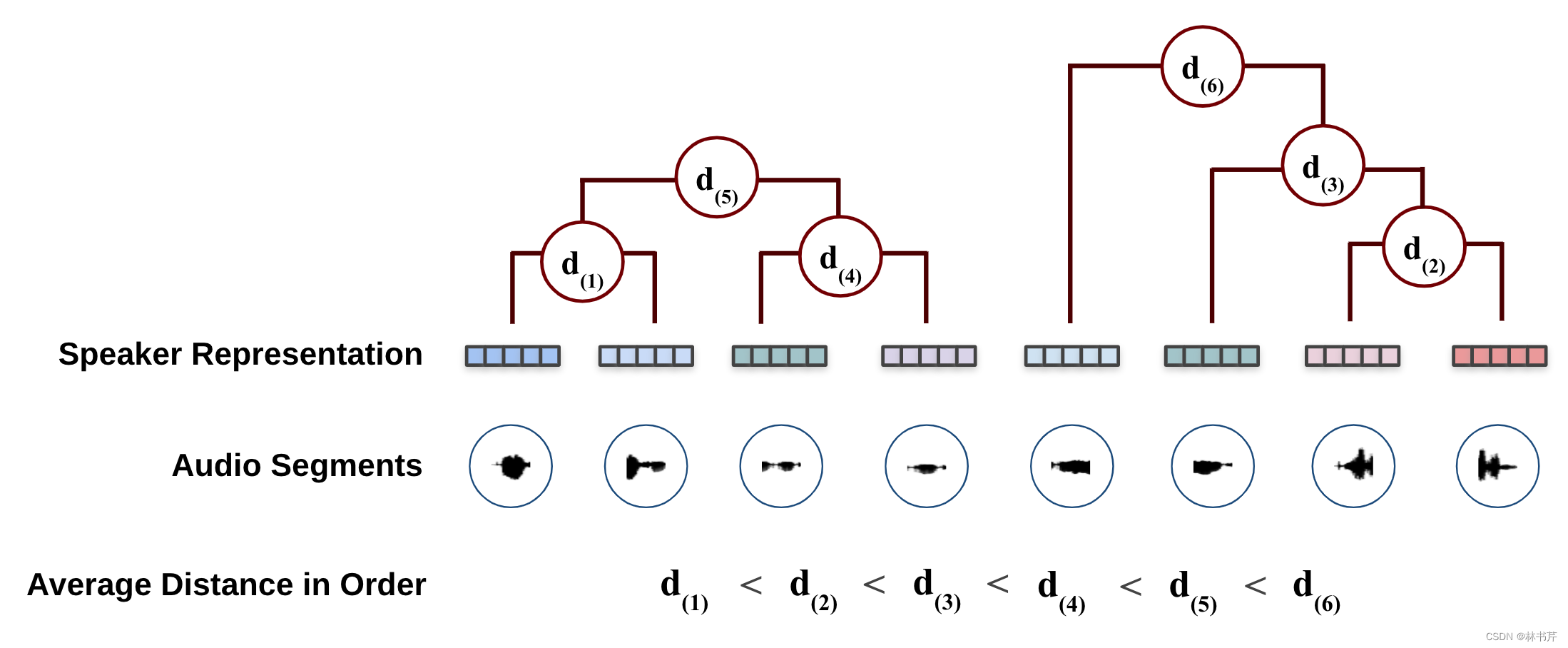
对于 SD 任务,AHC 的迭代终止条件可以使用相似性阈值或目标聚类数。
如果使用PLDA作为距离度量,则AHC过程应在 s ( ϕ 1 , ϕ 2 ) = 0 s(\phi_1,\phi_2)=0 s(ϕ1,ϕ2)=0 时停止,但是当说话人的数量是已知的时候,则 AHC 的聚类数等于说话人数时停止迭代。
谱聚类
谱聚类遵循以下步骤:
- 计算相似矩阵:原始的相似值 d d d 通过核 exp ( − d 2 / σ 2 ) \exp \left(-d^2 / \sigma^2\right) exp(−d2/σ2) 进行计算,其中 σ \sigma σ 是缩放参数。
- 计算拉普拉斯矩阵:图拉普拉斯矩阵又两种计算方式:归一化和非归一化。度矩阵 D D D 为对角阵,且 d i = ∑ j = 1 n \boldsymbol{d}_{\boldsymbol{i}}=\sum_{j=1}^n di=∑j=1n ,其中 a i j a_{ij} aij 是相似矩阵 A A A 的元素。
- 归一化: L = D − 1 / 2 A D − 1 / 2 \mathrm{L}=\mathrm{D}^{-1 / 2} \mathrm{AD}^{-1 / 2} L=D−1/2AD−1/2
- 非归一化: L = D − A \mathbf{L}=\mathbf{D}-\mathbf{A} L=D−A
- 特征值分解: L = X Λ X ⊤ \mathbf{L}=\mathbf{X} \mathbf{\Lambda} \mathbf{X}^{\top} L=XΛX⊤
- 二次归一化(可选):对 X \mathbf{X} X 进行行归一化,使得 y i j = x i j / ( ∑ j x i j 2 ) 1 / 2 y_{i j}=x_{i j} /\left(\sum_j x_{i j}^2\right)^{1 / 2} yij=xij/(∑jxij2)1/2
- 说话人数量:通过寻找最大的 eigengap 来估计说话人的数量
- 谱嵌入聚类: k k k 个最小的特征值和对应的特征向量进行拼接,构造矩阵 U ∈ R n × k U \in \mathbf{R}^{n\times k} U∈Rn×k , U U U 的行向量称为 k k k 维谱嵌入,最后使用聚类算法对谱嵌入进行聚类(如 k-means 聚类)。
谱聚类有许多变体,NJW 通常用于 SD 任务。与 AHC 不同,谱聚类主要采用余弦距离。此外,基于LSTM的相似性测度与谱聚类也有一定竞争力。取决于不同数据集,余弦距离+谱聚类的方法优于 LPDA+AHC。
其他聚类算法
- k-means
- mean-shift 聚类,在 SD 任务中,和 KL 距离搭配使用
后处理
重分割
重分割是一种一种细化说话人边界的过程。
基于BaumWelch算法的维特比重排方法:交替应用与每个说话人对应的 GMM 的估计和使用估计的说话人GMM的基于维特比算法的重新分割
基于变分贝叶斯的隐马尔可夫模型(VB-HMM):效果优于 维特比重分割,详见后面的章节。
系统融合
多个 SD 系统进行融合可以提高精度。
在 SD 系统融合中,有一些特殊的问题:
-
说话人标签在不同的SD系统中并不标准化(也就是同一个说话人可能被打上不同的标签)
-
估计的说话人的数量可能不同
-
估计的时间边界也可能在多个 SD 系统中不同
解决办法有: -
将来自每个 SD 系统的记录结果序列 视为一个待聚类的对象,采用 AHC 对结果集合进行聚类,最终聚类成两个簇。在大簇中,距其他的记录结果最近的作为最终的记录结果。
-
通过找到两个说话人簇之间的匹配,然后基于匹配结果重排,来组合两个 SD 系统。
-
DOVER 方法:以基于投票的方案组合多个 SD 的结果,同时对标签进行对齐:

-
DOVER方法有一个隐含的假设,即没有重叠语音(每个时间索引最多只一个说话人),为了将该方法与重叠说话人相结合,有两种方法:
- 将不同 diarization 结果中的说话人标签与根假设对齐,并基于每个说话人对每个小段的加权投票得分来估计每个说话人的语音活动。
- 通过加权k分图匹配来对齐多个假设的说话人,并且基于多个系统的加权平均来估计每个小段的说话者数量k,以选择前k个投票的说话人标签。
分割和聚类联合优化
本节介绍了一种基于 VB-HMM 的 SD 技术,可被视为分割和聚类的联合优化。
VB-HMM 是 基于 VB 的说话人聚类的拓展,他引入 HMM 来约束说话人转换。假设语音特征 X = ( x t ∣ t = 1 , … , T ) \mathbf{X} = (\mathbf{x}_t|t=1,\dots,T) X=(xt∣t=1,…,T) 为语音特征,其中每个HMM状态都对应于 K K K 个可能的说话人之一。假设有 M M M 个状态,引入 M M M 维变量 Z = ( z t ∣ 1 , … , T ) \mathbf{Z}=(\mathbf{z}_t|1,\dots,T) Z=(zt∣1,…,T) 表示第 k k k 个说话人在时间 T T T 说话时, z t \mathbf{z}_t zt 的第 k k k 个元素为1,其余为0。同时基于隐变量 Y = ( y k ∣ k = 1 , … , K ) \mathbf{Y} = (\mathbf{y}_k|k=1,\dots,K) Y=(yk∣k=1,…,K) 对 x t \mathbf{x}_t xt 的分布进行建模,其中 y k \mathbf{y}_k yk 表示第 k k k 个说话人的低维向量,则 X , Y , Z \mathbf{X},\mathbf{Y},\mathbf{Z} X,Y,Z 的联合分布为: P ( X , Z , Y ) = P ( X ∣ Z , Y ) P ( Z ) P ( Y ) P(\mathbf{X}, \mathbf{Z}, \mathbf{Y})=P(\mathbf{X} \mid \mathbf{Z}, \mathbf{Y}) P(\mathbf{Z}) P(\mathbf{Y}) P(X,Z,Y)=P(X∣Z,Y)P(Z)P(Y)其中, P ( X ∣ Z , Y ) P(\mathbf{X} \mid \mathbf{Z}, \mathbf{Y}) P(X∣Z,Y) 是 GMM 建模的发射概率(也就是 HMM 的观测概率 B B B),其平均向量由 Y \mathbf{Y} Y 表示, P ( Z ) P(\mathbf{Z}) P(Z) 是 HMM 的转移概率, P ( Y ) P(\mathbf{Y}) P(Y) 是 Y \mathbf{Y} Y 的先验分布。
那么 SD 问题可以表述为,最大化后化后验分布 P ( Z ∣ X ) = ∫ P ( Z , Y ∣ X ) d Y P(\mathbf{Z} \mid \mathbf{X})=\int P(\mathbf{Z}, \mathbf{Y} \mid \mathbf{X}) d \mathbf{Y} P(Z∣X)=∫P(Z,Y∣X)dY 。
但是直接求解这个问题比较困难,所以使用变分贝叶斯来近似 P ( Z , Y ∣ X ) P(\mathbf{Z}, \mathbf{Y} \mid \mathbf{X}) P(Z,Y∣X) 模型参数。
基于 x-vector 的简化VB-HMM,称为 VBx,使用基于 PLDA 模型的 x-vector 来计算 P ( X ∣ Z , Y ) P(X \mid Z, Y) P(X∣Z,Y) 。原始的 VB-HMM 是帧级别的,而 VBx 是基于 x-vector,因此可以看成是一种联合聚类方法。
VB-HMM 通常被用于 SD 系统的最后步骤。
基于深度学习的SD的进展
首先介绍将DNN用于前面的一些独立模块的方法,然后介绍了将SD的几个部分统一为单个网络的方法。
基于 DNN 的 SD 概述:
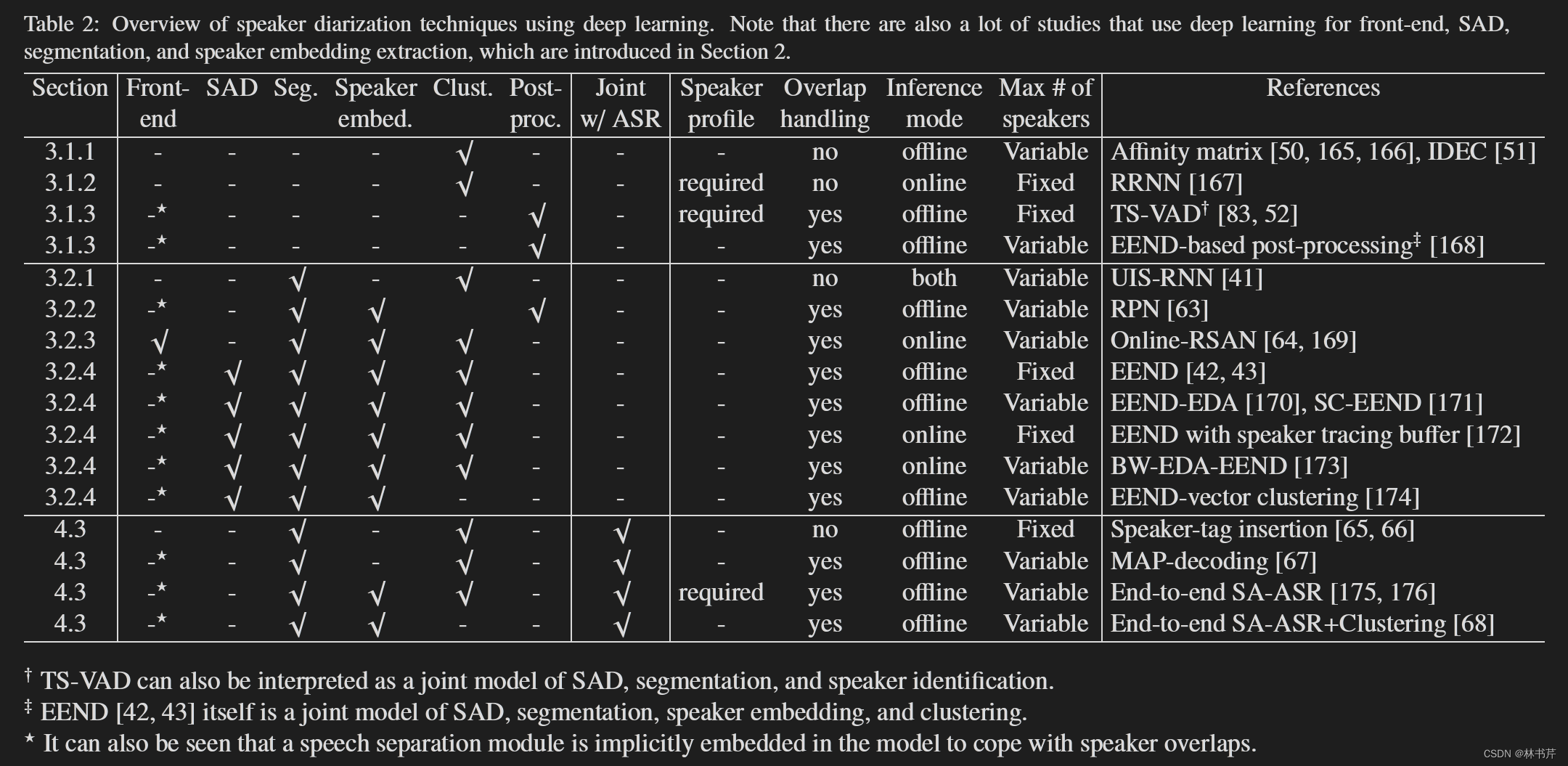
单模块优化
基于深度学习的说话人聚类增强
Speaker diarization with session-level speaker embedding refinement
using graph neural networks 论文中提出了一种基于 GNN 的方法: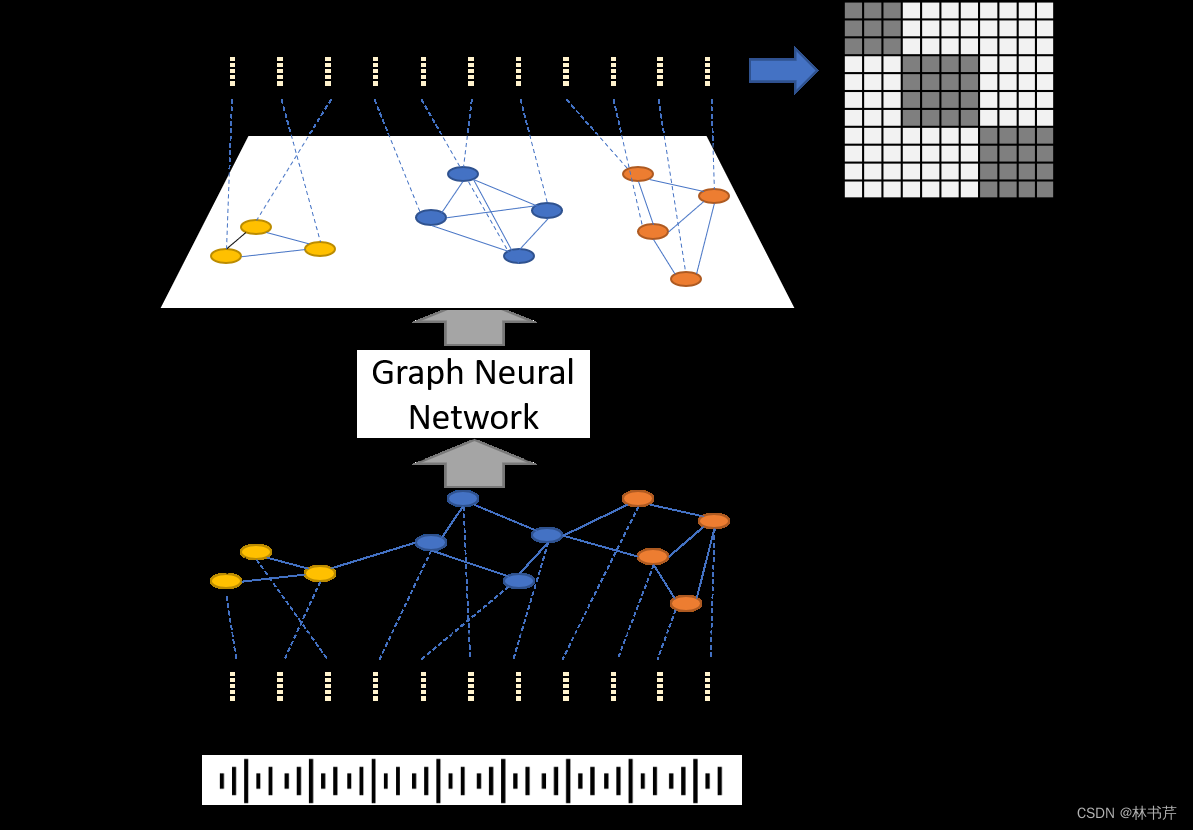
该方法旨在提纯谱聚类中的相似度矩阵。假设说话人 embedding 序列 { e 1 , … e N } \left\{\mathbf{e}_1, \ldots \mathbf{e}_N\right\} { e1,…eN} 其中 N N N 为序列长度,GNN 的输入 x i 0 \mathbf{x}^0_i xi0 为: { x i 0 = e i ∣ i = 1 , … , N } \left\{\mathbf{x}_i^0=\mathbf{e}_i \mid i=1, \ldots, N\right\} { xi0=ei∣i=1,…,N} ,第 p p p 层的输出为: x i ( p ) = σ ( W ∑ j L i , j x j ( p − 1 ) ) x_i^{(p)}=\sigma\left(\mathbf{W} \sum_j \mathbf{L}_{i, j} x_j^{(p-1)}\right) xi(p)=σ(Wj∑Li,jxj(p−1))其中, L L L 为归一化的相似矩阵(加上了自环连接), W W W 为第 p p p 层的待训练的权值矩阵, σ ( ⋅ ) \sigma(\cdot) σ(⋅) 为非线性函数,通过最小化参考和估计相似矩阵之间的距离进行训练。且采用直方图损失和核范数组合计算距离。
论文 Self-attentive similarity measurement strategies in speaker diarization 引入了基于自注意力的神经网络模型,以直接从说话人 embedding 序列中生成相似性矩阵。Multi-scale speaker diarization with neural affnity score fusion 基于神经网络将几个不同时间分辨率的 相似矩阵 融合成单个 相似矩阵。
Unsupervised deep embedding for clustering analysis 提出 深度 embedding 聚类(DEC),其目标是变换 embedding,使其更容易分离。为了使簇可分,为每个embedding i i i 计算“属于”第 j j j 个说话人簇的概率 q i , j q_{i,j} qi,j: q i j = ( 1 + ∥ z i − μ j ∥ 2 / a ) − a + 1 a ∑ l ( 1 + ∥ z i − μ l ∥ 2 / a ) − a + 1 a , p i j = q i j 2 / f i ∑ l q i l 2 / f l q_{i j}=\frac{\left(1+\left\|z_i-\mu_j\right\|^2 / a\right)^{-\frac{a+1}{a}}}{\sum_l\left(1+\left\|z_i-\mu_l\right\|^2 / a\right)^{-\frac{a+1}{a}}}, \quad p_{i j}=\frac{q_{i j}^2 / f_i}{\sum_l q_{i l}^2 / f_l} qij=∑l(1+∥zi−μl∥2/a)−aa+1(1+∥zi−μj∥2/a)−aa+1,pij=∑lqil2/flqij2/fi其中, z i z_i zi 为 bottleneck 特征, a a a 为 t 分布的自由度。 μ i \mu_i μi 为第 i i i 个簇的质心, f i = ∑ q i j f_i=\sum q_{i j} fi=∑qij,使用自编码器来估计 bottleneck 特征, 基于目标分布进行迭代。
改进 DEC(IDEC)通过在自编码器的输出和输入特征之间添加重建损失来保留数据的局部结构,提高了 SD 的准确性。IDEC 的损失函数包括四个部分:
- 原始 DEC 中的聚类误差 L c L_c Lc
- 重构误差 L r L_r Lr
- uniform “speaker airtime” distribution loss L u L_u Lu
- 测量 bottleneck 特征距质心的距离的损失 L M S E L_{MSE} LMSE
总损失为: L = α L c + β L r + γ L u + δ L M S E L=\alpha L_c+\beta L_r+\gamma L_u+\delta L_{M S E} L=αLc+βLr+γLu+δLMSE前面的系数代表权重。
学习距离估计器
本节介绍了一种使用可训练的距离函数的新方法
基于 关系RNN(RRNN),模型学习一系列输入特征之间的关系(远近关系),而 SD 问题可以大致被视作这类问题,因为 dairization 的最终结果取决于语音段和说话人质心之间的距离。
限制 SD 系统准确性的问题:
- 说话人embedding 片段的持续时间,需要在时间分辨率和鲁棒性之间进行权衡
- 说话人embedding 提取器没有被明确训练为 SD 提供最佳表示
- 距离度量通常基于启发式方法和/或依赖于某些不一定成立的假设
- 音频处理过程中忽略了上下文信息
上述问题可以归因于距离度量函数,并且大多数问题可以用RRNN解决。
有论文提出了 一种学习说话人簇质心与embedding之间关系的方法,SD 被认为是对已经分割的音频的分类任务,也就是对提取的每个 embedding x j x_j xj 和所有的说话人的质心进行比较,最小化基于距离的损失函数来为此音频段分配标签。
基于深度学习的后处理
Medennikov 提出 目标说话人 VAD(TS-VAD),在有许多说话人重叠的噪声条件下,也能实现准确的 SD。
TS-VAD 假设已知了每个说话人的 i-vector, E = { e k ∈ R f ∣ k = 1 , … , K } \mathcal{E}=\left\{\mathbf{e}_k \in \mathbb{R}^f \mid k=1,\dots,K\right\} E={
ek∈Rf∣k=1,…,K} ,其中 f f f 是i-vector的维度, K K K 是说话人的数量,如图: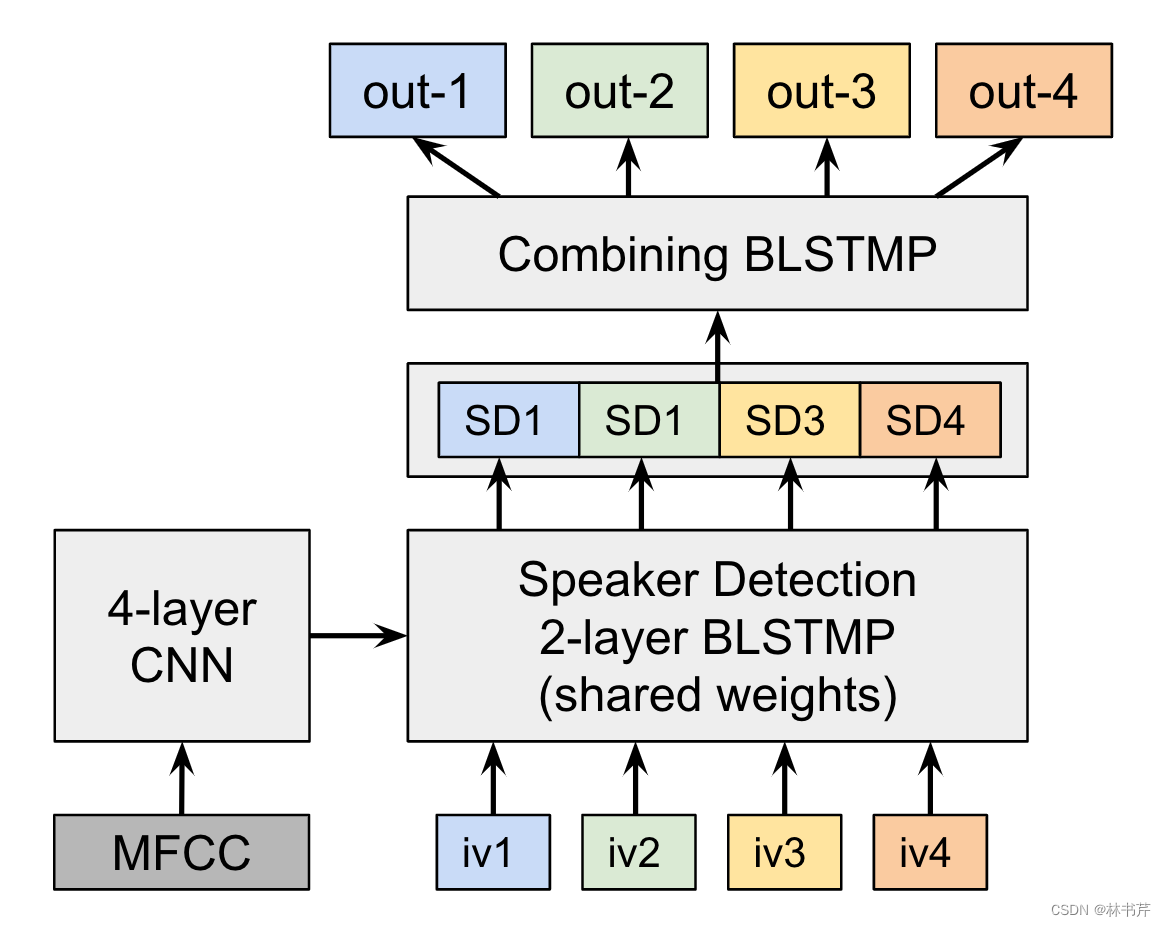
TS-VAD 的输入为 MFCC 特征 X \mathbf{X} X+ i-vector E \mathcal{E} E,模型的输出 k k k 维向量序列 O ⊨ ( o t ∈ R K ∣ t = 1 , … , T ) \mathbf{O} \models\left(\mathbf{o}_t \in \mathbb{R}^K \mid t=1, \ldots, T\right) O⊨(ot∈RK∣t=1,…,T) ,其中 o t \mathbf{o}_t ot 的第 k k k 个元素表示在时间帧 t t t 对应于 e k e_k ek 的说话人语音活动的概率(也就是如果说话人 e k \mathbf{e}_k ek 在时间 t t t 说话了,则 0 t \mathbf{0}_t 0t 的第 k k k 个元素为1,其他为0)。
整个模型的流程为:
- 实现基于聚类的 diarization
- 给定上述 diarization 的结果,估计每个说话人的 i-vector
- 重复以下:
- 根据i-vector 执行 TS-VAD
- 更新 i-vector
TS-VAD 的缺点在于,模型可以处理的说话人的最大数量受到输出向量的维数的限制。
Horiguchi等人提出了一种不同的方法,采用 EEND 模型来更新基于聚类的 SD 结果。 基于聚类的SD方法可以处理大量说话人,但不能处理重叠语音。EEND具有相反的特性。两者可以互补:首先采用传统聚类方法,然后对每对检测到的说话人迭代应用EEND模型,以细化重叠区域的时间边界。
SD 联合优化
联合分割和聚类
unbounded interleaved-state recurrent neural networks (UIS-RNN) 模型使用一个可训练的模型替代分割和聚类方法。给定输入 embedding 序列 X = ( x t ∈ R d ∣ t = 1 , … , T ) \mathbf{X}=\left(\mathbf{x}_t \in \mathbb{R}^d \mid t=1, \ldots, T\right) X=(xt∈Rd∣t=1,…,T) ,UIS-RNN 产生 diarization 的结果 Y = ( y t ∈ N ∣ t = 1 , … , T ) \mathbf{Y}=\left(y_t \in \mathbb{N} \mid t=1, \ldots, T\right) Y=(yt∈N∣t=1,…,T) 作为每个时间帧的说话人索引。 X , Y \mathbf{X},\mathbf{Y} X,Y 的联合概率可以通过链式规则分解为: P ( X , Y ) = P ( x 1 , y 1 ) ∏ t = 2 T P ( x t , y t ∣ x 1 : t − 1 , y 1 : t − 1 ) P(\mathbf{X}, \mathbf{Y})=P\left(\mathbf{x}_1, y_1\right) \prod_{t=2}^T P\left(\mathbf{x}_t, y_t \mid \mathbf{x}_{1: t-1}, y_{1: t-1}\right) P(X,Y)=P(x1,y1)t=2∏TP(xt,yt∣x1:t−1,y1:t−1)
为了建模说话人改变的分布,UIS-RNN 引入隐变量 Z = ( z t ∈ { 0 , 1 } ∣ t = 2 , … , T ) \mathbf{Z}=\left(z_t \in\{0,1\} \mid t=2, \ldots, T\right) Z=(zt∈{
0,1}∣t=2,…,T) ,当说话人在时刻 t − 1 t-1 t−1 和时刻 t t t 不同时, z t z_t zt 为 1 1 1,反之为 0 0 0。联合概率为: P ( X , Y , Z ) = P ( x 1 , y 1 ) ∏ t = 2 T P ( x t , y t , z t ∣ x 1 : t − 1 , y 1 : t − 1 , z 1 : t − 1 ) P(\mathbf{X}, \mathbf{Y}, \mathbf{Z})=P\left(\mathbf{x}_1, y_1\right) \prod_{t=2}^T P\left(\mathbf{x}_t, y_t, z_t \mid \mathbf{x}_{1: t-1}, y_{1: t-1}, z_{1: t-1}\right) P(X,Y,Z)=P(x1,y1)t=2∏TP(xt,yt,zt∣x1:t−1,y1:t−1,z1:t−1)
式 P ( x t , y t , z t ∣ x 1 : t − 1 , y 1 : t − 1 , z 1 : t − 1 ) P\left(\mathbf{x}_t, y_t, z_t \mid \mathbf{x}_{1: t-1}, y_{1: t-1}, z_{1: t-1}\right) P(xt,yt,zt∣x1:t−1,y1:t−1,z1:t−1) 可以进一步分解成三个部分: P ( x t , y t , z t ∣ x 1 : t − 1 , y 1 : t − 1 , z 1 : t − 1 ) = P ( x t ∣ x 1 : t − 1 , y 1 : t ) P ( y t ∣ z t , y 1 : t − 1 ) P ( z t ∣ z 1 : t − 1 ) P\left(\mathbf{x}_t, y_t, z_t \mid \mathbf{x}_{1: t-1}, y_{1: t-1}, z_{1: t-1}\right)=P\left(\mathbf{x}_t \mid \mathbf{x}_{1: t-1}, y_{1: t}\right) P\left(y_t \mid z_t, y_{1: t-1}\right) P\left(z_t \mid z_{1: t-1}\right) P(xt,yt,zt∣x1:t−1,y1:t−1,z1:t−1)=P(xt∣x1:t−1,y1:t)P(yt∣zt,y1:t−1)P(zt∣z1:t−1)其中, P ( x t ∣ x 1 : t − 1 , y 1 : t ) P\left(\mathbf{x}_t \mid \mathbf{x}_{1: t-1}, y_{1: t}\right) P(xt∣x1:t−1,y1:t) 表示序列生成概率,通过基于 GRU 的 RNN 建模。 P ( y t ∣ z t , y 1 : t − 1 ) P\left(y_t \mid z_t, y_{1: t-1}\right) P(yt∣zt,y1:t−1) 表示说话人分配概率,通过 distance-dependent Chinese
restaurant process 建模。 P ( z t ∣ z 1 : t − 1 ) P\left(z_t \mid z_{1: t-1}\right) P(zt∣z1:t−1) 表示说话人改变概率,由伯努利分布建模。UIS-RNN 可以通过最大化 log P ( X , Y , Z ) \log P(\mathbf{X}, \mathbf{Y}, \mathbf{Z}) logP(X,Y,Z) 来训练最优参数。推理过程可以通过基于束搜索的方法来找到给定 X \mathbf{X} X 使得 log P ( X , Y ) \log P(\mathbf{X}, \mathbf{Y}) logP(X,Y) 最大的 Y \mathbf{Y} Y 来实现。
联合分割、embedding 提取和重分割
基于 RPN 的方法可以联合进行分割、说话人 embedding 提取和重分割。
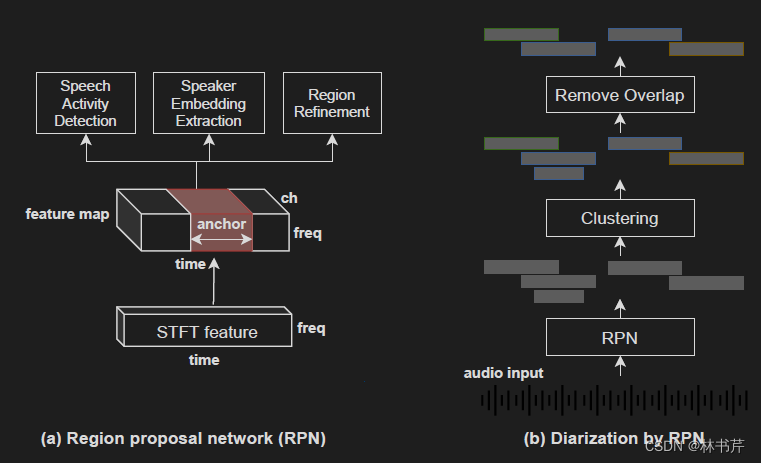
RPN 网络如上图左,STFT 特征首先被转换成 feature map(也就是增加了信道维度),然后用三个神经网络在时间轴上施加不同大小的滑动窗口(锚),对于每个锚,三个神经网络分别执行 VAD、embedding 提取和 region refinement。
- VAD 用于估计锚存在中语音活动的概率
- embedding 提取锚中的说话人特征
- region refinement 用于估计锚的持续时间和中心位置
推理过程如图右,RPN 首先得到语音活动高于阈值的锚,然后计算每个锚的说话人 embedding,使用传统聚类方法对锚进行聚类,最后去掉经过 region refinement 后重叠过多的锚。
基于 RPN 的 SD 系统具有处理可能有任意数量说话人的重叠语音的优点。
联合语音分离和 Diarization
Kounades-Bastian 提出基于NFM的spatial covariance model 来合并语音活动检测模型到语音分离中,采用 EM 算法从多通道重叠语音中估计分离出的语音和每个说话人的语音活动,该方法完全基于统计建模。
Neumann 提出 online Recurrent Selective Attention Network (online RSAN) 模型,基于单个模型来联合语音分离、说话人计数 和 SD。网络输入 语谱 X b ∈ R T × F \mathbf{X}_b \in \mathbb{R}^{T \times F} Xb∈RT×F 、一个残差掩膜矩阵 R b , i − 1 ∈ R T × F \mathbf{R}_{b, i-1} \in \mathbb{R}^{T \times F} Rb,i−1∈RT×F 和一个 说话人 embedding e b − 1 , i ∈ R d \mathbf{e}_{b-1, i} \in \mathbb{R}^d eb−1,i∈Rd ,其中 b , i , T , F b,i,T,F b,i,T,F 分别为音频块的索引、说话人索引、音频块的长度、最大 frequency bin。输出语音掩膜 M b , i ∈ R T × F \mathbf{M}_{b, i} \in \mathbb{R}^{T \times F} Mb,i∈RT×F 和对应于说话人 e b , i \mathbf{e}_{b,i} eb,i 的更新的说话人 embedding。对于每个音频块 b b b 和说话人 i i i,神经网络以迭代的方式进行:
Repeat (a) and (b) for b = 1 , 2 , … b=1,2, \ldots b=1,2,…
(a) R b , 0 = 1 \mathbf{R}_{b, 0}=1 Rb,0=1
(b) Repeat (i)-(iii) for i = 1 , 2 , … i=1,2, \ldots i=1,2,… until being stopped at (iii).
i. M b , i , e b , i = N N ( X b , R b , i − 1 , e b − 1 , i ) \mathbf{M}_{b, i}, \mathbf{e}_{b, i}=\mathrm{NN}\left(\mathbf{X}_b, \mathbf{R}_{b, i-1}, \mathbf{e}_{b-1, i}\right) Mb,i,eb,i=NN(Xb,Rb,i−1,eb−1,i)
(e e b − 1 , i \boldsymbol{e}_{b-1, i} eb−1,i is set to 0 if it was not calculated previously)
ii. R b , i = max ( R b , i − 1 − M b , i , 0 ) \mathbf{R}_{b, i}=\max \left(\mathbf{R}_{b, i-1}-\mathbf{M}_{b, i}, \mathbf{0}\right) Rb,i=max(Rb,i−1−Mb,i,0)
iii. If 1 T F ∑ t , f R b , i ( t , f ) < \frac{1}{T F} \sum_{t, f} \mathbf{R}_{b, i}(t, f)< TF1∑t,fRb,i(t,f)< threshold, stop iteration.
说话人 i i i 在语音块 b b b 的分离语音可以通过 M b , i ⊙ X b \mathbf{M}_{\boldsymbol{b}, i} \odot \mathbf{X}_{\boldsymbol{b}} Mb,i⊙Xb 获得,其中 ⊙ \odot ⊙ 为 element-wise 的乘法。说话人 embedding e b , i \mathbf{e}_{b,i} eb,i 被用于追踪说话人邻近的块。
得益于迭代方法,神经网络可以联合执行语音分离和SD的同时处理可变数量的说话人。
全端到端的神经 Diarization
EEND 框架基于单个网络实现整个 SD 流程,网络结构如图: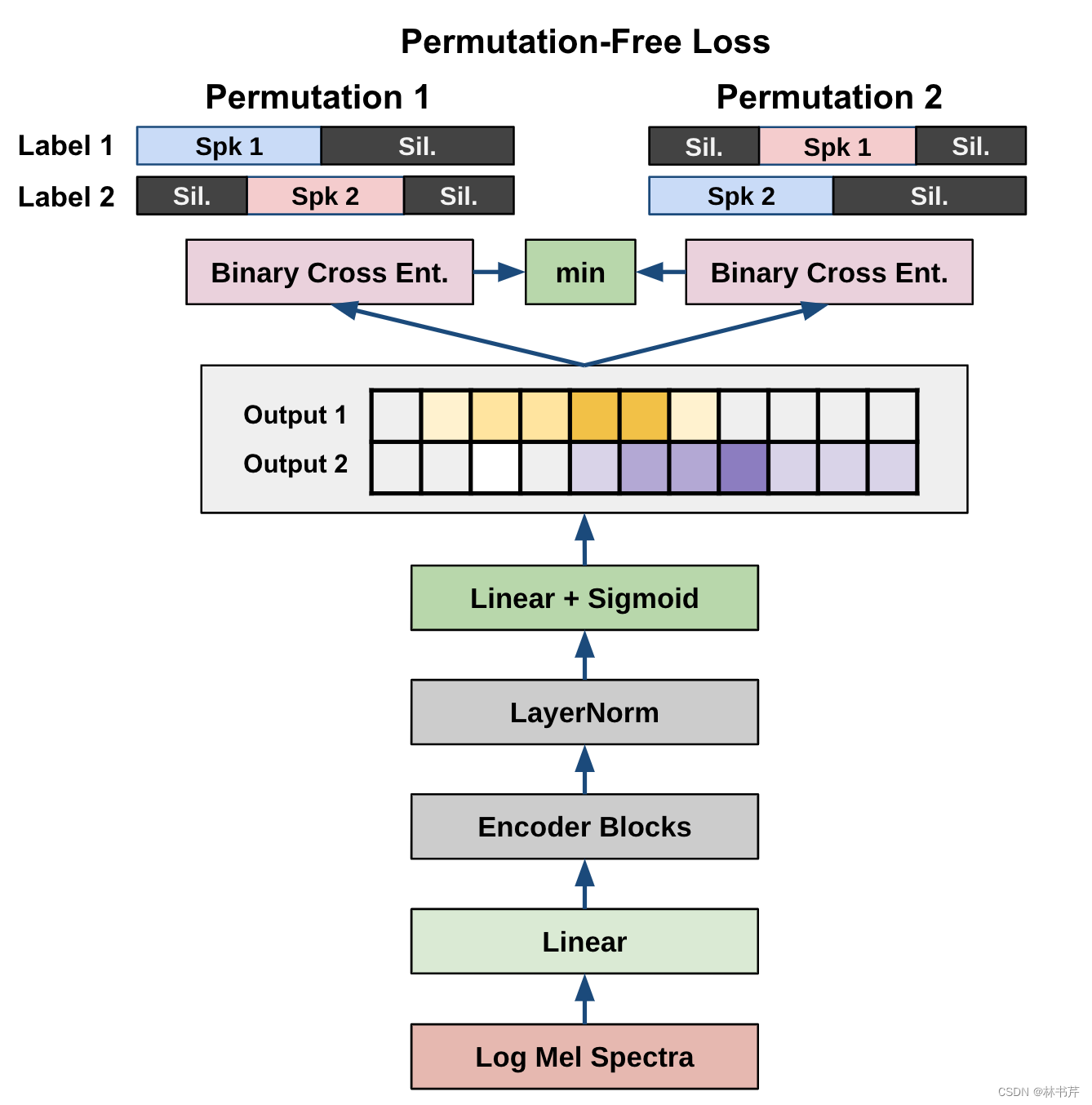
EEND 的输入为长为 T T T 的声学特征 X = ( x t ∈ R F ∣ t = 1 , … , T ) \mathbf{X}=\left(\mathbf{x}_t \in \mathbb{R}^F \mid t=1, \ldots, T\right) X=(xt∈RF∣t=1,…,T) ,神经网络输出对应的说话人标签序列 Y = ( y t ∣ t = 1 , … , T ) \mathbf{Y}=\left(\mathbf{y}_t \mid t=1, \ldots, T\right) Y=(yt∣t=1,…,T),其中 y t = [ y t , k ∈ { 0 , 1 } ∣ k = 1 , … , K ] \mathbf{y}_t=\left[y_{t, k} \in\{0,1\} \mid k=1, \ldots, K\right] yt=[yt,k∈{ 0,1}∣k=1,…,K] 当 y t , k = 1 y_{t, k}=1 yt,k=1 时,表示在时间帧 t t t 说话人 k k k 有语音活动,并且对于不同的 k , k ′ k,k^\prime k,k′, y t , k y_{t, k} yt,k 和 y t , k ′ y_{t, k^{\prime}} yt,k′ 可以都是 1 1 1,表明两个说话人同时说话了(也就是重叠)。
假设输出 y t , k y_{t, k} yt,k 独立,网络通过最大化条件分布 log P ( Y ∣ X ) ∼ ∑ t ∑ k log P ( y t , k ∣ X ) \log P(\mathbf{Y} \mid \mathbf{X}) \sim \sum_t \sum_k \log P\left(y_{t, k} \mid \mathbf{X}\right) logP(Y∣X)∼∑t∑klogP(yt,k∣X) 进行训练。交换说话人索引会产生多个标签候选,所以对所有可能的参考标签计算损失函数,并将损失最小的参考标签用于误差反向传播。
EEND 最初使用 BLSTM,后面拓展都注意力网络。
EEND 的优点有:
- 可以以声音的方式处理重叠语音
- 直接通过最大化 diarization accuracy 进行优化
- 输入标签即可由真实数据重新训练
EEND 的限制有: - 模型架构限制了可处理的最大说话人数量
- 无法进行 online 处理
- 容易过拟合
因此,EEND 的拓展有:
- Horiguchi 提出了使用基于编码器的 attractor(EDA)扩展EEND 。该方法在EEND的输出上应用基于LSTM的编解码器生成多个attractor 直到其存在的概率小于阈值。然后,每个 attractor 乘以EEND生成的 embedding,以计算每个说话人的语音活动。
Fujita 等人通过使用条件说话人链式规则,以此输出语音活动。该方法中,神经网络用于产生后验概率 P ( y k ∣ y 1 , … , y k − 1 , X ) P\left(\mathbf{y}_k \mid \mathbf{y}_1, \ldots, \mathbf{y}_{k-1}, \mathbf{X}\right) P(yk∣y1,…,yk−1,X),其中 y k = ( y t , k ∈ { 0 , 1 } ∣ t = 1 , … , T ) y_k=\left(y_{t, k} \in\{0,1\} \mid t=1, \ldots, T\right) yk=(yt,k∈{
0,1}∣t=1,…,T) 为第 k k k 个说话人的语音活动向量。然后采用链式规则计算联合概率: P ( y 1 , … , y K ∣ X ) = ∏ k = 1 K P ( y k ∣ y 1 , … , y k − 1 , X ) P\left(\mathbf{y}_1, \ldots, \mathbf{y}_K \mid \mathbf{X}\right)=\prod_{k=1}^K P\left(\mathbf{y}_k \mid \mathbf{y}_1, \ldots, \mathbf{y}_{k-1}, \mathbf{X}\right) P(y1,…,yK∣X)=k=1∏KP(yk∣y1,…,yk−1,X)
在推理阶段,通过重复计算直到最后估计的 y k y_k yk 接近 0 0 0。
Kinoshita 提出一种结合EEND和说话人聚类的方法,神经网络被训练以生成说话人 embedding 和语音活动的概率,受EEND估计的语音活动约束的说话人聚类被应用在不同处理块之间来对齐被估计的说话者。
也有一些方法将 EEND 拓展以实现 online 的处理。
ASR背景下的 SD
一般认为,SD 是 ASR 的预处理步骤。本节讨论如何在 ASR 的背景下开发 SD 系统。
早期工作
来自 ASR 的lexical 信息可以通过以下方式用于 SD 系统:
- RT03评估:使用单词边界信息进行分割(首次尝试使用 ASR 的输出来改进 SD 性能)
- RT07评估:把 ASR 的结果用于改进 VAD,以减少误警,从而提高SD系统的聚类性能。
- Silovsky 等人:在分割时使用了 ASR 的单词对齐,ASR输出的单词被分割结果截断,因为分割结果和解码的单词序列没有对齐
- Canseco-Rodriguez 等人:创造了一个字典(用于广播新闻数据),词典中的短语提供了广播新闻场景中谁在讲话、谁将讲话以及谁讲过话 的身份
尽管早期的的 SD 研究没有充分利用 lexical 信息大幅改进 DER,但很多研究整合了 ASR 的输出信息来改进 SD 的输出。
使用来自 ASR 的lexical 信息
最近的研究中,SD 系统使用了 DNN 来捕获 ASR 的输出。
- Flemotomos 等人:提出了一种将语言信息用于 SD 任务的方法:
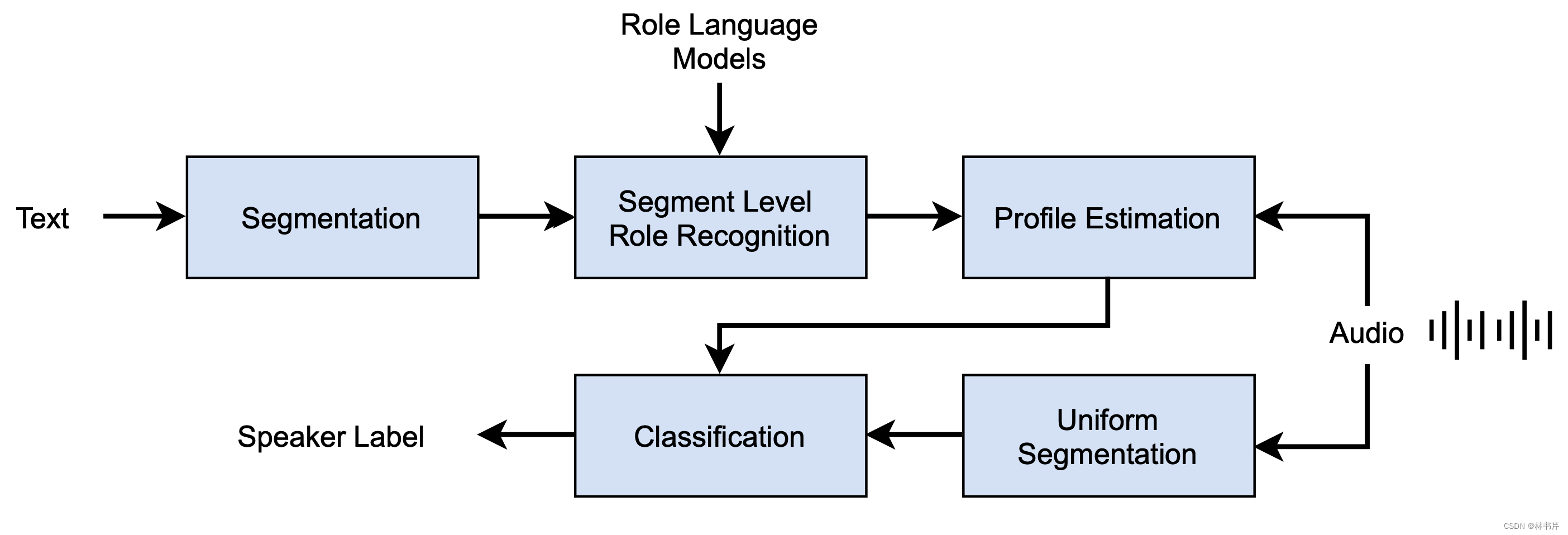
系统采用了基于神经文本的说话人变化检测和基于文本的角色识别,同时使用语言和声学信息来提高 DER。
2. Park 等人:通过采用 Seq2Seq 模型输出 speaker turn tokens,将 ASR 的 lexical 信息用于说话人分割,然后基于 speaker turn 进行分割
3. Park 等人:使用集成邻接矩阵结合 lexical 信息和语音段聚类。邻接矩阵是 max of 声学信息和 lexical 信息: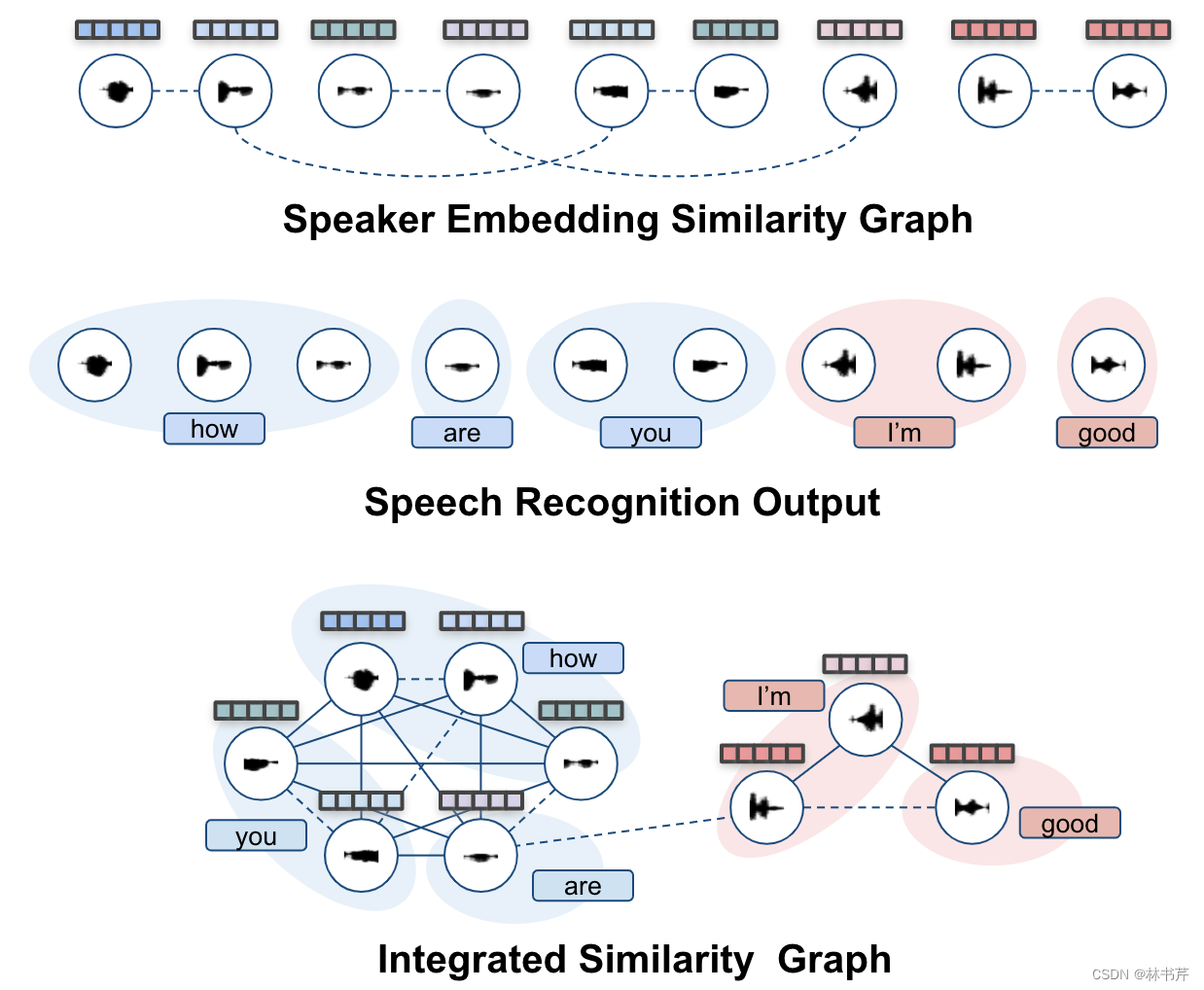
基于深度学习联合 ASR 和 SD
方法1:在端到端的 ASR 中引入说话人标签: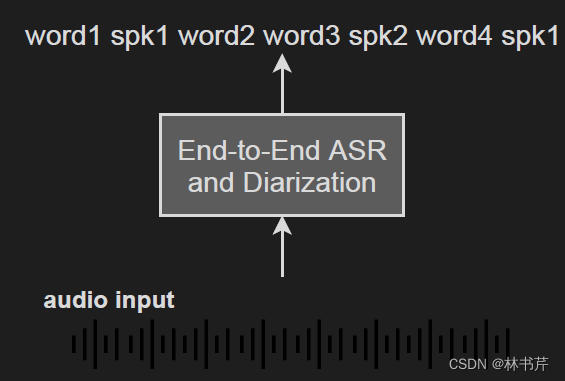
- Shafey 等人在 RNN-T 的 ASR系统的输出中插入说话人角色标签
- Mao 等人提出将说话人身份标签插入到基于注意力的encoder-decoder ASR系统的输出中
这两个研究表明,插入说话人标签是联合ASR和SD的一种简单而有前景的方法。但是优于说话人角色或说话人身份标签需要在训练期间确定且固定。这种方法很难处理任意数量的说话人。
方法2:基于 MAP 的联合解码。
Kanda 等人将ASR和SD进行联合解码,如图:
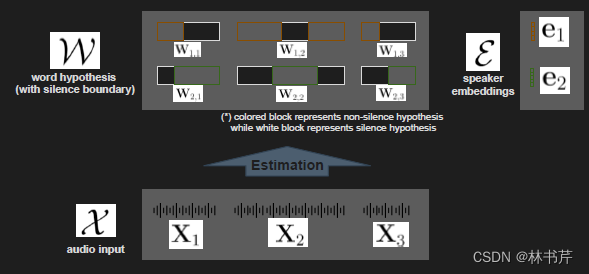
假设观测序列 X = { X 1 , … , X U } X=\left\{\mathbf{X}_1, \ldots, \mathbf{X}_U\right\} X={
X1,…,XU} ,其中 U U U 表示分段数, X u \mathbf{X}_u Xu 就表示第 u u u 段的声学特征,具有时间边界的单词假设为 W = { W 1 , … , W U } W=\left\{\mathbf{W}_1, \ldots, \mathbf{W}_U\right\} W={
W1,…,WU} 其中, W u \mathbf{W}_u Wu 为段 u u u 对应 的语音识别假设。且 W u = ( W 1 , u , … , W K , u ) \mathbf{W}_u=\left(\mathbf{W}_{1, u}, \ldots, \mathbf{W}_{K, u}\right) Wu=(W1,u,…,WK,u) 包含了段 u u u 的所有说话人假设( K K K 表示说话人的数量),说话人 embedding E = ( e 1 , … , e K ) \mathcal{E}=\left(\mathbf{e}_1, \ldots, \mathbf{e}_{\boldsymbol{K}}\right) E=(e1,…,eK) ,其中 e j ∈ R d \mathbf{e}_j \in \mathbb{R}^d ej∈Rd 为第 k k k 个说话人的 d d d 维向量。则多说话人ASR和SD联合解码问题变成求解最可能的 W ^ \hat{W} W^: W ^ = argmax W P ( W ∣ X ) = argmax W { ∑ E P ( W , E ∣ X ) } ≈ argmax W { max E P ( W , E ∣ X ) } \begin{aligned} \hat{W} &=\underset{W}{\operatorname{argmax}} P(\mathcal{W} \mid X) \\ &=\underset{\mathcal{W}}{\operatorname{argmax}}\left\{\sum_{\mathcal{E}} P(\mathcal{W}, \mathcal{E} \mid X)\right\} \\ & \approx \underset{\mathcal{W}}{\operatorname{argmax}}\left\{\max _{\mathcal{E}} P(\mathcal{W}, \mathcal{E} \mid X)\right\} \end{aligned} W^=WargmaxP(W∣X)=Wargmax{
E∑P(W,E∣X)}≈Wargmax{
EmaxP(W,E∣X)}最后一个方程使用了 维特比近似。方程可进一步分解成两个迭代问题: W ^ ( i ) = argmax W P ( W ∣ E ^ ( i − 1 ) , X ) , E ^ ( i ) = argmax E P ( E ∣ W ^ ( i ) , X ) , \begin{gathered} \hat{\mathcal{W}}^{(i)}=\underset{\mathcal{W}}{\operatorname{argmax}} P\left(\boldsymbol{W} \mid \hat{\mathcal{E}}^{(i-1)}, \mathcal{X}\right), \\ \hat{\mathcal{E}}^{(i)}=\underset{\mathcal{E}}{\operatorname{argmax}} P\left(\mathcal{\mathcal { E }} \mid \hat{\mathcal{W}}^{(i)}, \mathcal{X}\right), \end{gathered} W^(i)=WargmaxP(W∣E^(i−1),X),E^(i)=EargmaxP(E∣W^(i),X),其中, i i i 表示迭代索引。
方法3:端到端说话人属性建模(SA-ASR)用以联合进行说话人计数、多说话人 ASR 和 说话人识别。和前两种方法相反,端到端 SA-ASR 模型额外输入 speaker profile 并且基于注意力机制识别 speaker profile: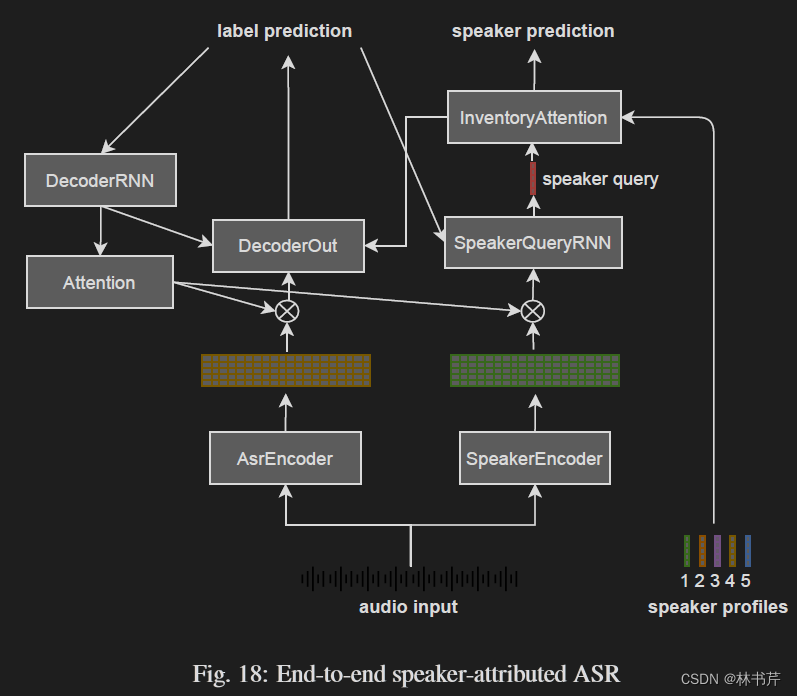
由于基于串行输出训练的注意机制,模型可以处理的说话人数量没有限制。推理时,提供相关的 speaker profile,端到端 SA-ASR 可以自动转录语音且识别每个话语的说话人。
Evaluation Series 和 数据集
本节描述了用于 SD 评估的 Evaluation Series 和 数据集,数据集总结如下:
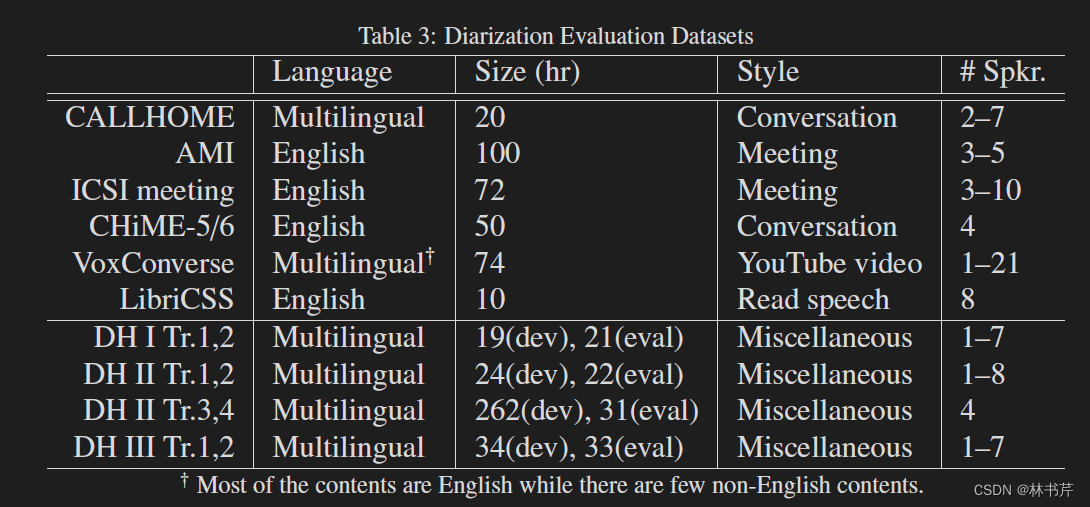
- CALLHOME:SD 论文中用的最广泛的数据集
- AMI:用于评估与ASR模块集成的说话人分类系统的一个合适的数据集
- ICSI:会议音频
- CHiME-5/6 挑战和数据集:多说话人日常对话的 ASR 挑战
- VoxSRC挑战和VoxConverse语料库:说话人识别挑战,包含重叠语音
- LibriCSS:为研究语音分离、ASR 和 SD 而设计,包含重叠语音
- DIHARD 挑战和数据集:关注最先进的 SD 系统的性能差距,挑战性较大
- Rich Transcription Evaluation Series:RT Evaluation 旨在对与ASR相关的SD进行更深入的研究
- 其他数据集:略
应用场景
- 会议记录,需要克服的一些技术挑战包括
- 重叠语音 ASR,背景噪声、混响等问题
- 模块化的框架,能够处理多模态且通道数可变的场景而不损失性能
- 实现 online 或者 streaming ASR 时,需要进行很多音频预处理操作,导致整个流程效率很低
- 多设备捕获音频来提高会议转录质量
- 对话交互分析和行为建模:主要就是提取特定说话人的语音信息
- 音频索引:基于内容的音频索引、采用 ASR 转录本理解语音内容、说话人摘要等等
- 对话式 AI
SD 的挑战和未来
- SD 在线(online)处理:注重实时性
- 域不匹配:在特定域中的数据上训练的模型在另一个域的数据上效果不佳
- 说话人重叠:重叠在多说话人场景中不可避免,但是传统的方法(尤其是基于聚类的系统)只关注非重叠区。
- 与 ASR 集成:许多应用需要ASR结果以及SD结果,确定SD和ASR任务的最佳系统架构仍然是一个悬而未决的问题
- 视听建模:视觉信息为识别说话人提供了强有力的线索。例如,鱼眼相机捕获的视频用于提高会议转录任务中SD的准确性