公众号:EDPJ
| 解释隐空间 | Interpreting the Latent Space of GANs for Semantic Face Editing |
| W+ 隐空间 | Image2stylegan: How to embed images into the stylegan latent space? |
| GAN 逆映射 | GAN Inversion: A Survey |
| CLIP | Learning transferable visual models from natural language supervision |
| CLIP & StyleGAN | StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators |
目录
1. (2020)Interpreting the Latent Space of GANs for Semantic Face Editing
2. (2019)Image2stylegan: How to embed images into the stylegan latent space?
3. (2022)GAN Inversion: A Survey
4. (2021)Learning Transferable Visual Models From Natural Language Supervision
5. (2022)StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
1. (2020)Interpreting the Latent Space of GANs for Semantic Face Editing
解释用于语义面部编辑(Semantic Face Editing)的GAN的隐空间(Latent Space)_EDPJ的博客-CSDN博客
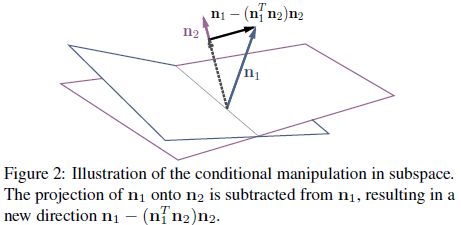
本文的主要思想是:
- 在隐空间中,有一个超平面将图像的各种属性(如年龄、性别、眼镜、头部姿势等)分开。
- 每个超平面的法向量就是每个属性对应的方向。
- 沿法线方向移动隐编码,相应的属性发生变化的同时,其他属性不受影响。
1.1 文中提到,“移动 latent code 会产生连续变化。此外,虽然训练集中缺乏足够的极端姿势数据,但 GAN 能够想象侧面脸应该是什么样子。”那么能否基于此生成视频?或者进行data augmentation?
1.2 因为属性的相关性,某个属性方向(如眼镜)上的向量会有其他属性方向(如年龄、性别)上的分量,通过投影减去这些方向上的分量之后,得到一个新的向量,在该方向上移动不会对其他属性产生影响。
1.3 W 空间是比 latent space Z 更高维的空间,该空间基于对 latent space Z 的映射而来(这让我想到了 normalizing flow,通过映射可以把简单分布变成更复杂的分布,或者把复杂的分布转换为更简单的分布)。
W 空间具有比 latent space Z 更好的属性解耦(分离)特性。直观地理解就是通过向更高维度的映射来对各种属性进行分离。在更高的维度中,会出现一些新的方向,这些方向就是通过 “减分量” 操作得到的新方向。该方向虽然无法用语言直接描述,但却是完全独立的一个方向(属性)
2. (2019)Image2stylegan: How to embed images into the stylegan latent space?
Image2StyleGAN:如何把图像嵌入StyleGAN的隐空间(latent space)_EDPJ的博客-CSDN博客

2.1 为获取相比于初始 latent space Z 和中间 latent space W 更好的性能,使用一个扩展的 latent space W+: 若 StyleGAN 总共有 L 层,则把 L 个不同的 latent code w 串联,并送入 StyleGAN 的每一层。如上图所示。StyleGAN 的层数由输出图像分辨率决定:L=2log2 R - 2。最大分辨率 1024*1024 对应 18 层的结构。
2.2 本文有一个有趣的发现:对于在人脸域预训练的 StyleGAN,除了实现人脸的嵌入,还能实现其它域的嵌入(例如,猫,狗,车)。这为之后的 few-shot learning 甚至是 zero-shot learning 打下了基础。
2.3 通过对图像的 latent code 进行插值(加权和)、交叉(嫁接)、加减等操作,分别实现两个图像的融合、风格转换、表情转换。
2.4 优化过程中,为衡量输入图像与生成图像的相似性,本文使用的损失函数是感知损失(使用提取特征的协方差统计来感知地测量图像之间的高层次(卷积层的特征输出,embedding)相似性)与像素级 MSE 损失的加权组合。之所以这样做是因为,单独使用 MSE 无法获得高质量的 embedding,所以需要感知损失作为正则化项,以引导优化向着 latent space 的正确区域。
3. (2022)GAN Inversion: A Survey
GAN逆映射(Inversion):综述_EDPJ的博客-CSDN博客
3.1 GAN 逆映射的核心思想:一种便捷的处理图像的方式就是,基于逆映射的方法,把图像和处理方式(基于文字、图像、视频、音频等多模态的引导)逆映射到隐空间(latent space)中获得相应的隐编码(latent code、embedding、latent representation)。通过对隐编码的处理来实现对图像的间接处理。
3.2 逆映射的方法有三种:
- 基于学习的方法(训练一个编码器)、
- 基于优化的方法(创建一个生成最优 latent code 的目标函数)、
- 基于前两者混合的方法(训练一个编码器预测一个大概的值,把该值当做优化的初始值)。
3.3 隐空间有七种:
- Z 空间:从简单分布中随机采样得到的空间。
- W 空间:使用由多层感知器构成的非线性映射网络把 Z 空间映射到 W 空间。相比于 Z 空间,可以缓解简单分布的限制。
- W+ 空间:把与网络层数对应数目的 latent code w 串联,然后送入每一层的 AdaIN,得到 W+ 空间。相比于 W 空间,属性有更高的解耦度。
- S 空间:通过对生成器的每一层使用不同的仿射变换,把 W 空间转换为 S 空间。相比于 W 空间,属性有更高的解耦度。
- P 空间:高维高斯分布的大部分密度靠近超球体的表面,(假设)latent code 的联合分布近似于多元高斯分布,则可以把图像嵌入到 Z 空间的超球体的表面,从而得到 P 空间。
- P_N 空间:通过 PCA 白化操作把 P 空间转换为 P_N 空间,从而消除依赖性和冗余。
- P_N+ 空间:对 P_N 空间空间进一步扩展可以得到 P_N+ 空间
3.4 本文综述了前两篇文章的内容
4. (2021)Learning Transferable Visual Models From Natural Language Supervision
基于自然语言监督学习可迁移视觉模型_EDPJ的博客-CSDN博客
4.1 基本原理
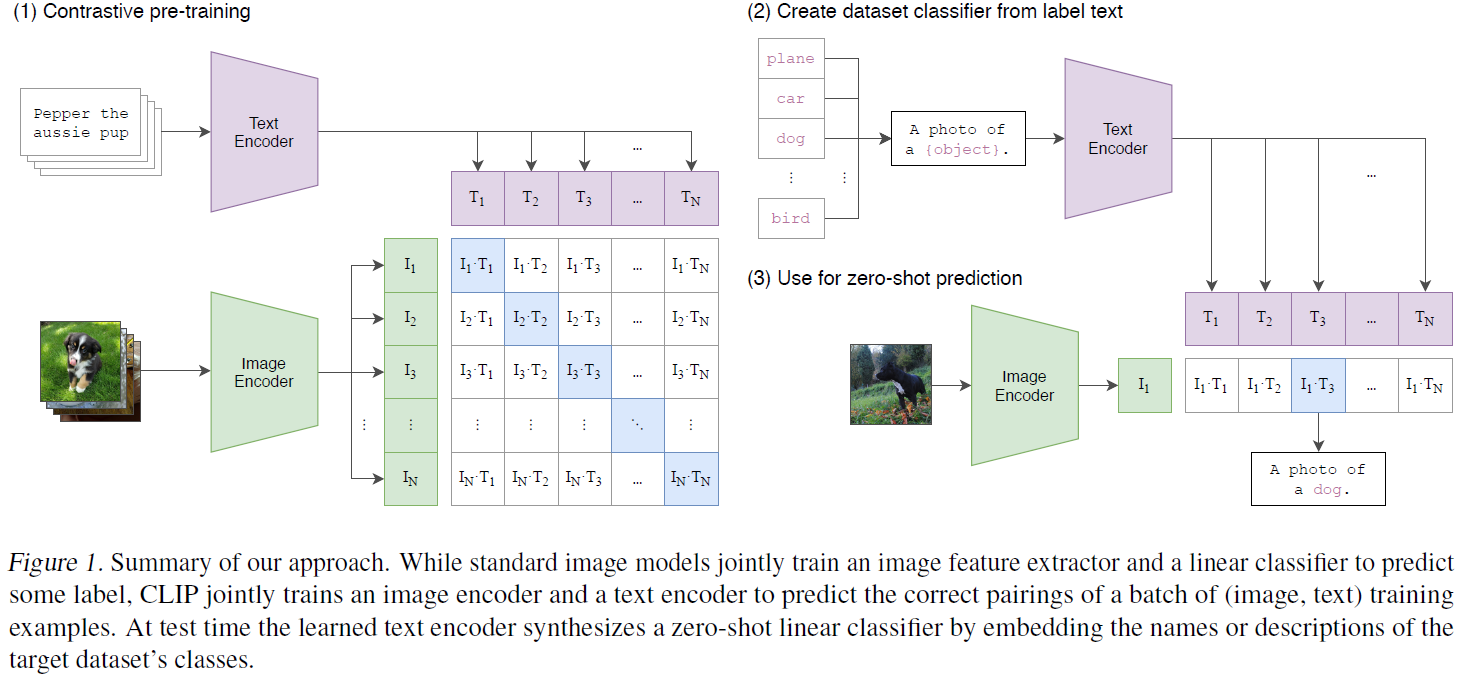
对比语言图像预训练模型(Contrastive-Language-Image-Pretraining (CLIP) models) 联合训练图像编码器和文本编码器来预测一批(图像、文本)训练示例的正确配对。 在测试时,学习的文本编码器编码目标数据集类别的名称或描述获得相应的 embedding,然后与需要分类的图像的 embedding 进行 zero-shot 匹配。
4.2 性能
实验结果证明,zero-shot CLIP 的性能要略优于 few-shot 逻辑回归,除非 few-shot 的样本数目超过某个门限(例如:16)。这可能是由于 zero-shot 和 few-shot 方法之间的区别。CLIP 的 zero-shot 分类器是通过自然语言(可直接描述指定属性)生成的,而监督学习必须间接地从训练数据中获取信息。基于样本的无上下文学习的缺点是,许多不同的假设要与数据一致,尤其是在 one-shot 情况下。而单个图像通常包含许多不同的视觉概念,从而无法确定哪一个才是用于预测的关键。
4.3 限制
基于自然语言提示的模型不能处理那些无法用语言描述的属性,所以可能需要一些对应的样本作为参考。正如前面所说,从 zero-shot 转为 few-shot 会面临性能下降的问题。虽然可以通过添加样本数目(超过门限)来提升性能,但对于某些类别,样本是非常稀缺的。
5. (2022)StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
StyleGAN-NADA:CLIP引导的非对抗域自适应(Domain Adaptation)图像生成器_EDPJ的博客-CSDN博客
5.1 非对抗域自适应(Non-Adversarial Domain Adaptation)
5.2 对比语言图像预训练模型(Contrastive-Language-Image-Pretraining (CLIP) models)
- 基于对比学习的目标,把图像和文本都映射到一个联合的多模态 embedding 空间(latent space,隐空间)
- 图像和文本在其中的 representation 称为隐编码(latent code)
- 通过对隐编码的优化,进行图像生成或修改
- 图片的年龄,性别等每个属性,在 latent space 是线性可分的,存在一个超平面将两者分开。故根据不同属性的超平面方向进行移动,可进行一个属性的编辑和多个属性互不干扰的编辑。
5.3 自适应层选择,或者叫自适应可训练权重选择
- 原理:模型训练时,深度网络中不同的层提取不同的特征;反过来,在图像生成时,不同的层生成不同的特征。
- 域迁移的本质:基于源域与目标域的差异,保留源域图像的部分关键信息,然后更改其余的信息,使生成图像保留源域关键信息的同时满足目标域的要求。
- 冻结与关键信息生成更相关的层,对剩余层进行训练。具体操作方式见 4.2 节层冻结
5.4 分割掩模(segmentation mask,附录 D)
- 与层选择有相似之处,不同点在于,mask是对图像直接进行操作
- 保留图像指定的区域(不需要改变的区域),mask剩余的区域,然后送入CLIP对mask区域进行转换
5.5 与上文类似,本文也提到了 few-shot 和 zero-shot。可能是由于框架的不同,从 zero-shot 转变为 few-shot(文本引导变为图像引导)并未出现性能下降的情况。此时使用 few-shot,就能处理那些无法用语言描述的属性。但这时又面临另一个问题:由于CLIP的embedding空间本质上是语义的,所以基于图像的引导不能保证向该风格的精确转换。