目录
0 需求
给定多个时间段,每个时间段分为开始时间、结束时间,将相互重叠的多个时间段合并为一个区间
--数据:id、开始时间、结束时间
1 12 15
2 57 58
3 29 32
4 30 31
5 17 19
6 44 44
7 56 57
8 16 18合并后结果如下;
--结果
flag start_time end_time
1 12 15
2 16 19
3 29 32
4 44 44
5 56 581 数据准备
create table test02 as
select 1 as id, 12 as start_time, 15 as end_time
union all
select 2 as id, 57 as start_time, 58 as end_time
union all
select 3 as id, 29 as start_time, 32 as end_time
union all
select 4 as id, 30 as start_time, 31 as end_time
union all
select 5 as id, 17 as start_time, 19 as end_time
union all
select 6 as id, 44 as start_time, 44 as end_time
union all
select 7 as id, 56 as start_time, 57 as end_time
union all
select 8 as id, 16 as start_time, 18 as end_time2 数据分析
解题要点:如何判断哪些区间是要合并的?
其实换个角度就是哪些区间是交叉的,哪些是重复的?
判断思路:如果将起始时间,和结束时间进行排序,当前行的起始时间小于等于上一行的结束时间,那么日期就存在交叉,存在重复的数据。根据该条件我们可以设置断点,然后用经典的思路sum() over()来获取分组id,问题便得到解决。
第一步:按照起始时间和结束时间进行降序排序,获取上一行的结束时间,目的是为了比较
select id,
start_time,
end_time,
lag(end_time, 1, end_time) over (order by start_time asc, end_time asc) as lga_end_time
from test02 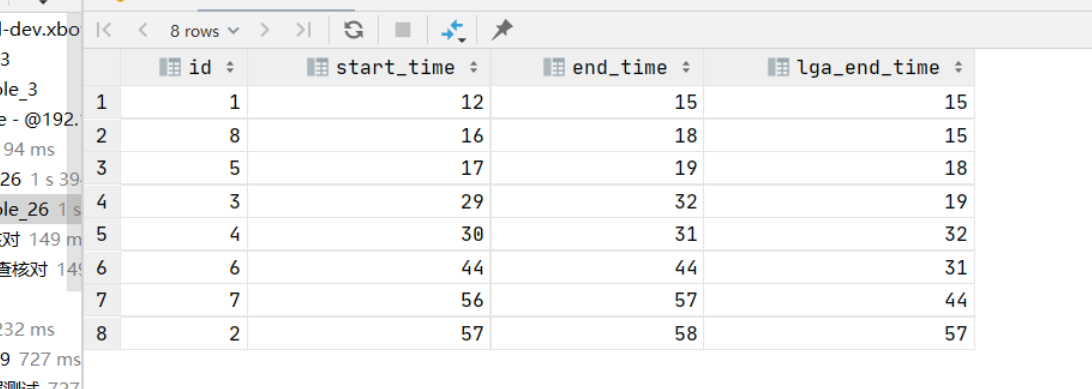
第二步:根据lag_end_time进行判断,当当前行的start_time <= lag_end_time时候设置标记值0,否则为1(经典的按条件变化后的分组思路,这里一定是满足条件的时候置为0,不满足条件的时候置为1)
select id
, start_time
, end_time
, case when start_time <= lga_end_time then 0 else 1 end as flg --条件成立的时候为0,不成立的时候为1
from (select id,
start_time,
end_time,
lag(end_time, 1, end_time) over (order by start_time asc, end_time asc) as lga_end_time
from test02
第三步:按照sum() over()的方法获取分组id
select id
, start_time
, end_time
, sum(flg) over (order by start_time, end_time ) as grp_id
from (select id
, start_time
, end_time
, case when start_time <= lga_end_time then 0 else 1 end as flg --条件成立的时候为0,不成立的时候为1
from (select id,
start_time,
end_time,
lag(end_time, 1, end_time) over (order by start_time asc, end_time asc) as lga_end_time
from test02
) t
) t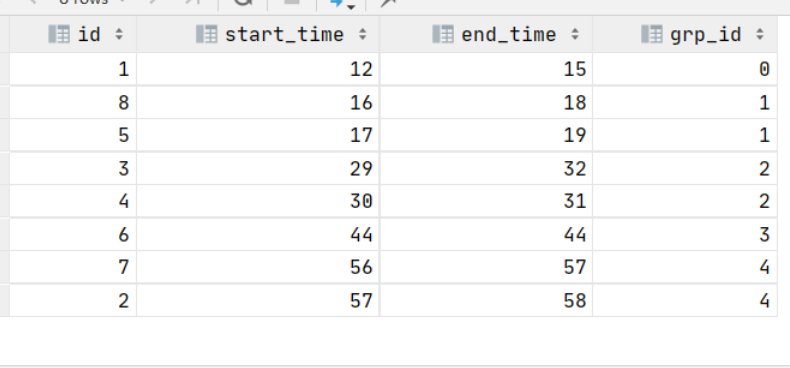
第四步:在分组里获取,最小值及最大值,最小值即为起始点,最大值即为结束点,分组id即为id
最终的SQL如下:
select grp_id + 1 as id
, min(start_time) as start_time
, max(end_time) as end_time
from (
select id
, start_time
, end_time
, sum(flg) over (order by start_time, end_time ) as grp_id
from (select id
, start_time
, end_time
, case when start_time <= lga_end_time then 0 else 1 end as flg --条件成立的时候为0,不成立的时候为1
from (select id,
start_time,
end_time,
lag(end_time, 1, end_time) over (order by start_time asc, end_time asc) as lga_end_time
from test02
) t
) t
) t
group by grp_id
2 小结
本题为区间合并问题,问题比较经典,判断的核心思路是构造条件:
当前行的起始时间<=上一行的结束时间(按照起始时间和结束时间降序排序)。
然后利用经典的分组思路,在一个分组中求最小、最大值即为所求。