仅通过在照片上训练模型,机器学习(ML)的最新技术就已经在许多计算机视觉任务中实现了卓越的准确性。基于这些成功和不断发展的3D对象理解,在增强现实,机器人技术,自主性和图像检索等广泛应用方面具有巨大潜力。例如,今年早些时候,Google发布了MediaPipe Objectron(一套针对移动设备设计的实时3D对象检测模型),它们在完全注释的真实3D数据集上进行了训练,可以预测对象的3D边界框。

3D模型
然而,由于与2D任务(例如ImageNet,COCO和Open Images)相比,缺少大型现实世界的数据集,因此了解3D对象仍然是一项具有挑战性的任务。为了使研究社区能够不断提高对3D对象的理解,迫切需要发布以对象为中心的视频数据集,该数据集可以捕获对象的更多3D结构,同时匹配用于许多视觉任务的数据格式( (例如视频或摄像机流),以帮助训练和确定机器学习模型的基准。
今天,Google发布Objectron数据集,这是一个短的,以对象为中心的视频剪辑的集合,可从不同的角度捕获更大的一组公共对象。每个视频剪辑都随附有AR会话元数据,其中包括相机姿势和稀疏点云。数据还包含每个对象的手动注释3D边界框,它们描述了对象的位置,方向和尺寸。数据集包括15K带注释的视频剪辑,并补充了从不同地理区域的样本中收集的超过4M带注释的图像。

3D模型检测
3D对象检测解决方案与数据集一起,我们还将共享针对四类对象的3D对象检测解决方案-鞋子,椅子,杯子和照相机。这些模型在MediaPipe中发布,MediaPipe是Google的用于实时和流媒体的跨平台可定制ML解决方案的开源框架,它还支持ML解决方案,例如设备上的实时手部,虹膜和身体姿势跟踪。
与以前发布的单阶段Objectron模型相反,这些最新版本使用两阶段体系结构。第一阶段采用TensorFlow对象检测模型来查找对象的2D裁剪。然后,第二阶段使用图像裁剪来估计3D边界框,同时为下一帧计算对象的2D裁剪,因此对象检测器不需要运行每个帧。第二阶段3D边界框预测器在Adreno 650移动GPU上以83 FPS运行。
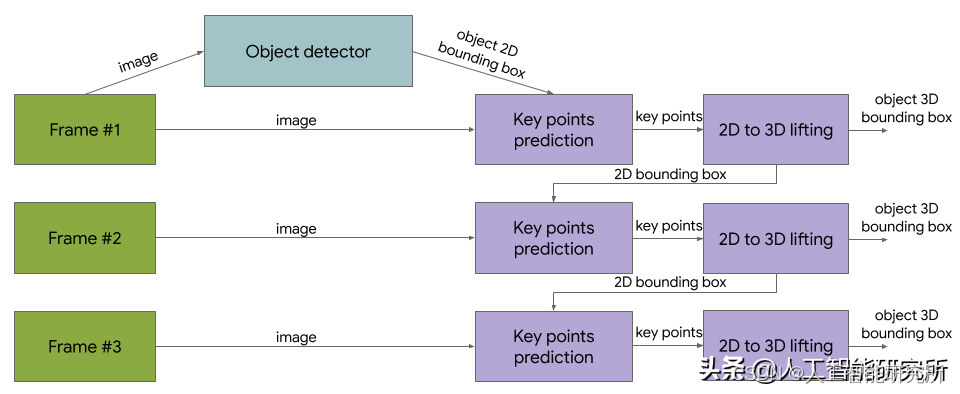
3D对象检测解决方案图
3D对象检测的评估指标借助地面真相注释,我们使用3D联合交叉点(IoU)相似度统计数据(用于计算机视觉任务的常用指标)评估3D对象检测模型的性能,该指标可测量边界框与目标之间的接近程度。基本事实。
Google提出了一种算法,可为通用的面向3D的盒子计算准确的3D IoU值。首先,我们使用Sutherland-Hodgman多边形裁剪算法计算两个盒子的面之间的交点。这类似于用于计算机图形学的视锥剔除技术。相交的体积由所有修剪的多边形的凸包计算。最后,根据两个框的交点的体积和并集的体积计算IoU。我们将与数据集一起发布评估指标源代码。
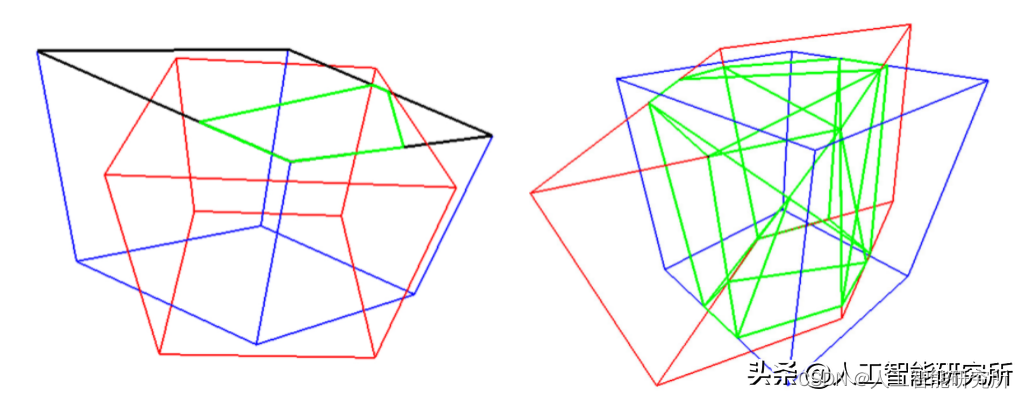
左:通过将多边形裁剪到框上来计算每个面的交点。右:通过计算所有相交点(绿色)的凸包来计算相交的体积。
数据集格式
有关Objectron数据集的技术细节,包括用法和教程,请访问数据集网站。数据集包括自行车,书籍,瓶子,照相机,谷物盒,椅子,杯子,笔记本电脑和鞋子,并存储在Google Cloud存储上的objectron存储桶中:
· 视频片段
· 注释标签(对象的3D边界框)
· AR元数据(例如照相机姿势,点云和平面)
· 已处理的数据集:带注释帧的改编版本,图像的格式为tf.example,视频的格式为SequenceExample。
· 支持脚本以基于上述指标运行评估
· 支持脚本以将数据加载到Tensorflow,PyTorch和 Jax并可视化数据集,包括" Hello World"示例
对于数据集,我们还将开放数据源管道,以在流行的Tensorflow,PyTorch和Jax框架中解析数据集。还提供了示例colab笔记本。
通过发布此Objectron数据集,我们希望使研究界能够突破3D对象几何理解的极限。我们还希望促进新的研究和应用,例如视图合成,改进的3D表示和无监督学习。
以上为Google官方介绍,后期我们分享如何代码实现