图书(放上图片)

正文
1)将两个递增的有序链表合并为一个递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中不允许有重复的数据。
思路: 两个有序链表合并称为一个有序链表,而且使用原来的结点,要求是没有重复元素。这里就有三种思路
思路1: 在两个有序链表合并的时候,就同时检查放入链表的元素,在链表中有没有重复。也就是说每次放入1个元素,就要检查链表有没有重复元素。因为是有序表,所以只需要检查上一个元素是否相同,就可判断整个链表有无重复元素。时间复杂度为O(m+n)(链表L1的元素个数为m个,链表L2的元素个数为n个)
思路2: 将步骤分为两步:第一步,将两个有序单链表合成一个有序单链表,可以有重复元素。第二步,将合并的有序单链表元素去重,则就完成了对应的操作。时间复杂度同样为O(m+n),但是比思路1要稍微慢。该方法是先进行合并O(m+n),再遍历元素有无重复O(m+n)。但是思路2的优点是作用分工明显,写两个函数,链表合并函数和链表去重函数就可以完成。
思路3: 保证两个单链表元素没有相同的,也就是先对两个单链表元素去重,再进行合并,和思路2类似,时间复杂度同样为O(m+n),但是最坏的情况单链表L1和单链表L2没有相同元素,时间消耗了3(m+n),思路2比思路3更优。
由此可看,思路1要更快,但是思路2条理更清晰,因此选择思路2(这里思路1和思路2都可以),需要编写两个函数,两个有序单链表合并成有序单链表的函数,并且保证使用原结点;有序单链表去重函数。
//函数1. 两个有序单链表合并有序单链表函数
//两个正序单链表合称有序单链表(不生成新结点,将两个原来单链表生成新的单链表),允许有重复数据
LinkList MergeSort(LinkList L1, LinkList L2) //书本原方法
{
LinkList L = L1;
LNode* p1 = L1->next;
LNode* p2 = L2->next;
LNode* p = L;
while (p1 && p2)
{
if (p1->data < p2->data) //正序排布
{
p->next = p1;
p = p1;
p1 = p1->next;
}
else
{
p->next = p2;
p = p2;
p2 = p2->next;
}
}
p->next = p1 ? p1 : p2;
free(L2);
return L;
}
//函数2. 有序单链表去重函数
//删除链表重复元素,输入链表是有序表
LinkList ListDelSame(LinkList L)
{
LNode* prior = L->next;
LNode* p = L->next ? L->next->next : NULL; //防止单链表是空表
while (p)
{
if (prior->data == p->data) //如果有相同元素,删除p的结点,并且更改prior的next指向
{
LNode* temp = p->next; //暂存p的下一个结点
free(p);
p = temp;
prior->next = p;
}
else //如果不是相同元素,则移动指针
{
prior = p;
p = p->next;
}
}
return L;
}
//3. 终函数
//先将两个链表合成一个链表,再在链表中检查和删除元素
LinkList MergeSortNo(LinkList L1, LinkList L2)
{
MergeSort(L1, L2);
ListDelSame(L1);
return L1;
}2)将两个非递减的有序链表合并为一个非递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其他的存储空间。表中允许有重复的数据。
思路: 非递减的有序就是递增,非递增的有序也就是递减。也就是说,题目的意思是两个正序的链表合并为一个逆序的链表。实现逆序可以使用头插法,将正序的元素依次插入到末尾,也就实现了逆序的操作。因此编写一个使用头插法的思想,合并两个有序单链表。
//两个递增单链表合成一个递减单链表(不生成新节点,原来两个单链表合成)
//头插法合成链表,先将小的元素扔进来,再在头插进来,允许有重复的数据
LinkList MergeNSort(LinkList L1, LinkList L2)
{
LNode* p1 = L1->next;
LNode* p2 = L2->next;
L1->next = NULL;
while (p1 && p2) //比较p1和p2
{
if (p1->data < p2->data)
{
LNode* temp = p1->next; //暂时储存p1->next
p1->next = L1->next;
L1->next = p1;
p1 = temp;
}
else
{
LNode* temp = p2->next; //暂时储存p2的下一个结点
p2->next = L1->next;
L1->next = p2;
p2 = temp;
}
}
p1 = p1 ? p1 : p2; //如果p1 !=NULL ,则说明p1没有放完,而p2放完了
while (p1) //头插法放入p1
{
LNode* temp = p1->next;
p1->next = L1->next;
L1->next = p1;
p1 = temp;
}
free(L2);
return L1;
}3)已知两个链表A和B分别表示两个集合,其元素递增排列。请设计一个算法,用于求出A与B的交集,并存放在A链表中。
思路: 将有序链表A和B,求交集放入链表A中。利用原来结点,不开辟新的结点,并且将不是交集的元素结点释放掉,这是大体思路。求交集的过程,可以利用求并集相同的思路,因为是有序表,所以对进行遍历比对,如果相同则是交集的元素,如果链表A的该元素小于链表B的元素,则链表A的元素向后跳转,并且释放掉链表A的较小元素,链表B同理,因此可以求得交集。
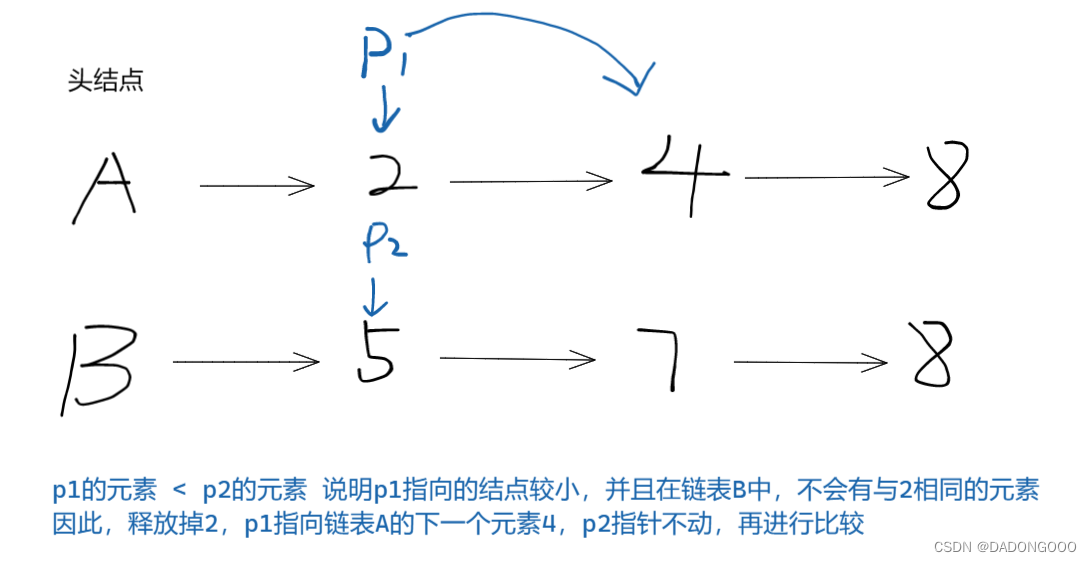
求交集思路由图可见,假设链表A有2,4,8三个元素,链表B有5,7,8三个元素。指针p1和指针p2分别遍历A和B的每个结点,如果p1元素小于p2说明p1指向的元素在链表B中不会有相同的元素(因为是顺序表)
//求AB的交集,将链表1和链表2求交集,放在链表1中
LinkList GetListIn(LinkList L1, LinkList L2)
{
LNode* p1 = L1->next;
LNode* p2 = L2->next;
LNode* p = L1;
p->next = NULL;
while (p1 && p2)
{
if (p1->data < p2->data) //如果p1的数据小于p2的数据,则p1要跳转下一个
{
LNode* temp = p1; //准备释放掉该节点
p1 = p1->next;
free(temp);
}
else if (p1->data > p2->data) //如果p2的数据小于p1的数据,则p2要跳转下一个
{
LNode* temp = p2; //释放掉多余结点
p2 = p2->next;
free(temp);
}
else
{
LNode* temp = p2; //准备释放掉结点p2
LNode* temp2 = p1->next; //暂存p1的下一个结点
p1->next = p->next; //连接结点p1,先将该结点下一个转为p的NULL
p->next = p1; //再将结点连接
p = p->next;
p1 = temp2;
p2 = p2->next;
free(temp);
}
}
free(L2);
return L1;
}4)已知两个链表A和B分别表示两个集合,其元素递增排列。请设计算法求出两个集合A和B的差集(即仅由在A中出现而不在B中出现的元素所构成的集合),并以同样的形式存储,同时返回该集合的元素个数。
思路: 将有序链表A和B,求差集放入链表A中。利用原来结点,不开辟新的结点,并且将不是差集的元素结点释放掉,和上面求交集是类似的,一样采用逐个比对法,将元素相同的放入链表A中。
//求链表A和B的差集,并且返回元素个数
int GetListSub(LinkList L1, LinkList L2)
{
LNode* p1 = L1->next;
LNode* p2 = L2->next;
LNode* p = L1;
p->next = NULL;
int num = 0; //统计共有多少个元素
while (p1&&p2) //遍历
{
if (p1->data < p2->data) //如果p1指向的结点小于p2指向的结点
{
LNode* temp = p1->next;
free(p1);
p1 = temp;
}
else if (p1->data > p2->data)//如果p1指向的结点数据大于p2指向的结点
{
LNode* temp = p2->next;
free(p2);
p2 = temp;
}
else //如果p1和p2数据相等
{
num++;
LNode* temp = p1->next; //暂存p1的下个结点,准备更改p1的结点
LNode* temp1 = p2->next; //暂存p2的下个结点,准备释放掉p2目前结点
p1->next = p->next;
p->next = p1;
p = p->next;
p1 = temp;
p2 = temp1;
}
}
return num;
}5)设计算法将一个带头结点的单链表A分解为两个具有相同结构的链表B和C,其中 B表的结点为A表中值小于零的结点,而C表的结点为A表中值大于零的结点(链表A中的元素为非零整数.要求B、C表利用A表的结点).
思路: 对A进行遍历,根据条件放入B和C中
//将链表A,分为链表B和链表C,不开新的结点,B中的结点为小于0,C的结点为大于0
void ListDivide(LinkList A, LinkList B, LinkList C)
{
LNode* pa = A->next;
LNode* pb = B;
LNode* pc = C;
while (pa)
{
LNode* temp = pa->next; //暂存pa的下一个结点
if (pa->data < '5') //如果pa的结点小于0,将结点放入B中
{
pa->next = pb->next;
pb->next = pa;
pb = pb->next;
}
else //如果pa的结点大于0
{
pa->next = pc->next;
pc->next = pa;
pc = pc->next;
}
pa = temp;
}
}6)设计一个算法,通过一趟遍历确定长度为n的单链表中值最大的结点。
思路: 对链表进行遍历,寻找最大的结点,时间复杂度为O(n)。
//返回单链表中的最大结点
LNode* ListGetMax(LinkList L)
{
LNode* pmax = L->next;
LNode* p = L->next? L->next->next:NULL; //防止L为空表
while (p)
{
if (pmax->data < p->data)
pmax = p;
p = p->next;
}
return pmax;
}7)设计一个算法,将链表中所有结点的链接方向“原地”逆转,即要求仅利用原表的存储空间,换句话说,要求算法的空间复杂度为O(1)。
思路: 将链表的链接方向逆转,实际上是对单链表实现逆序的操作,对单链表逆序的操作,可以采用头插法的方式,最为简单,时间复杂度O(n)。并且要求空间复杂度为O(1),也就是说不产生新的结点,用原来的结点。
//将单链表逆序,用头插法实现逆序
void ListReverse(LinkList L)
{
LNode* p = L->next;
L->next = NULL;
while (p)
{
LNode* temp = p->next;
p->next = L->next;
L->next = p;
p = temp;
}
}8)设计一个算法,删除递增有序链表中值大于mink且小于maxk的所有元素( mink和 maxk是给定的两个参数,其值可以和表中的元素相同,也可以不同)。
思路: 删除有序链表中在范围的指定元素,对表中每个元素进行遍历。另外,删除该结点的时候,需要将上一个结点的next链接到该结点的下一个结点,可以采用两个指针,1个指针指向前边,另外一个指向后一个。为了减少指针的使用,只用一个前结点的指针即可,检查指针的下一个结点是否要删除
//删除单链表中指定元素
void ListDelRange(LinkList L, int mink, int maxk)
{
LNode* p = L;
while (p->next)
{
if (p->next->data >= mink && p->next->data <= maxk) //如果p的下个结点满足,则删除
{
LNode* temp = p->next; //暂时存储待删除的结点
p->next = p->next->next; //连接结点
free(temp); //删除结点
}
else //如果下个结点数据不在范围内,则移动,保证检查到每个结点
p = p->next;
}
}9)已知p指向双向循环链表中的一个结点,其结点结构为data、prior、next三个域,写出算法 change(p),交换p所指向的结点及其前驱结点的顺序。
思路: 题目大意,是交换双向链表的前后结点指向
//双向链表交换结点前后
void DLChangePoint(DLNode* p)
{
DLNode* temp = p->next;
p->next = p->prior;
p->prior = temp;
}10)已知长度为n的线性表A采用顺序存储结构,请写一个时间复杂度为O(n),空间复杂度为O(1)的算法,该算法可删除线性表中所有值为item的数据元素。
思路: 删除顺序表的指定元素,因为是顺序表,如果检查的元素>删除的元素,则可以终止循环了。
//删除顺序单链表指定元素
void ListDelElem(LinkList L, int elem)
{
LNode* p = L;
while (p->next)
{
if (p->next->data > elem)
break;
if (p->next->data == elem)
{
LNode* temp = p->next; //暂时储存待删除的结点
p->next = p->next->next; //将p->next->next 放到 p->next中
free(temp); //释放结点
}
else
p = p->next;
}
}